MySQL数据导入实战指南:从文件到数据库的无缝衔接
发布时间: 2024-07-23 18:40:14 阅读量: 55 订阅数: 26 

数据库管理与优化:MySQL从入门到精通的实战指南
# 1. MySQL数据导入概述
MySQL数据导入是指将数据从外部源(如文件、数据库或应用程序)加载到MySQL数据库中的过程。数据导入对于各种场景至关重要,例如初始化数据库、更新现有数据或迁移数据。
数据导入通常涉及以下步骤:
- 准备数据源:确保数据源中的数据格式与MySQL数据库兼容。
- 选择导入方法:根据数据源和导入要求,选择合适的导入方法,例如使用LOAD DATA INFILE命令或mysqlimport工具。
- 执行导入操作:使用指定的导入方法将数据加载到MySQL数据库中。
# 2. 数据导入的理论基础
### 2.1 数据导入的原理和方法
数据导入是指将外部数据源中的数据加载到MySQL数据库中的过程。其原理是将外部数据源中的数据转换为MySQL兼容的格式,然后通过特定的命令或工具将数据写入数据库。
数据导入的方法主要有以下两种:
- **基于文件的导入:**从文件(如CSV、JSON、XML等)中导入数据。
- **基于数据库的导入:**从另一个数据库(如Oracle、PostgreSQL等)中导入数据。
### 2.2 数据导入的常见问题和解决方案
在数据导入过程中,可能会遇到以下常见问题:
- **数据格式不兼容:**外部数据源中的数据格式与MySQL数据库不兼容。
- **解决方案:**使用转换工具或脚本将数据转换为MySQL兼容的格式。
- **数据类型不匹配:**外部数据源中的数据类型与MySQL数据库中的数据类型不匹配。
- **解决方案:**使用CAST()函数或ALTER TABLE语句转换数据类型。
- **主键冲突:**导入的数据中包含与数据库中现有数据冲突的主键。
- **解决方案:**使用REPLACE INTO或ON DUPLICATE KEY UPDATE语句处理冲突。
- **数据完整性问题:**导入的数据中包含不完整或无效的数据。
- **解决方案:**使用数据验证和清理工具检查和修复数据。
- **性能问题:**导入大量数据时,性能可能会下降。
- **解决方案:**优化导入过程,例如调整缓冲区大小、使用多线程导入。
# 3. 数据导入的实践操作
### 3.1 从文件导入数据
#### 3.1.1 使用LOAD DATA INFILE命令
**原理:**
`LOAD DATA INFILE` 命令直接从文本文件中读取数据并将其加载到表中。它是一种高效且常用的数据导入方法,尤其适用于大数据集。
**语法:**
```
LOAD DATA INFILE '文件路径'
INTO TABLE 表名
[FIELDS TERMINATED BY 分隔符]
[LINES TERMINATED BY 行分隔符]
[IGNORE 忽略行数]
[COLUMNS 列名 (列名, ...)]
```
**参数说明:**
- `文件路径`:要导入的数据文件路径。
- `表名`:要导入数据的目标表。
- `FIELDS TERMINATED BY 分隔符`:指定字段分隔符。
- `LINES TERMINATED BY 行分隔符`:指定行分隔符。
- `IGNORE 忽略行数`:指定要忽略的文件开头行数。
- `COLUMNS 列名 (列名, ...)`:指定要导入的列名。
**代码示例:**
```sql
LOAD DATA INFILE 'data.csv'
INTO TABLE users
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1
COLUMNS (id, name, email);
```
**逻辑分析:**
该命令将 `data.csv` 文件中的数据加载到 `users` 表中。字段分隔符为 `,`,行分隔符为 `\n`。忽略文件开头一行,并导入 `id`、`name` 和 `email` 三列数据。
#### 3.1.2 使用mysqlimport工具
**原理:**
`mysqlimport` 工具是一个命令行工具,用于从文本文件、XML 文件或其他数据库导入数据。它支持多种数据格式,包括 CSV、JSON 和 XML。
**语法:**
```
mysqlimport -u 用户名 -p 密码 -h 主机名 -D 数据库名 表名 文件路径
```
**参数说明:**
- `-u 用户名`:数据库用户名。
- `-p 密码`:数据库密码。
- `-h 主机名`:数据库主机名。
- `-D 数据库名`:要导入数据的数据库名。
- `表名`:要导入数据的目标表。
- `文件路径`:要导入的数据文件路径。
**代码示例:**
```
mysqlimport -u root -p123456 -h localhost -D test users data.csv
```
**逻辑分析:**
该命令将 `data.csv` 文件中的数据导入到 `test` 数据库的 `users` 表中。用户名为 `root`,密码为 `123456`,主机名为 `localhost`。
### 3.2 从数据库导入数据
#### 3.2.1 使用INSERT INTO命令
**原理:**
`INSERT INTO` 命令可以将数据从一个表插入到另一个表中。它支持一次插入多行数据。
**语法:**
```
INSERT INTO 表名 (列名, ...)
VALUES (值1, 值2, ...), (值1, 值2, ...), ...
```
**参数说明:**
- `表名`:要插入数据的目标表。
- `列名`:要插入数据的列名。
- `值`:要插入的数据值。
**代码示例:**
```sql
INSERT INTO users (id, name, email)
VALUES (1, 'John Doe', 'john.doe@example.com'),
(2, 'Jane Smith', 'jane.smith@example.com'),
(3, 'Peter Parker', 'peter.parker@example.com');
```
**逻辑分析:**
该命令将三行数据插入到 `users` 表中。每行数据包含 `id`、`name` 和 `email` 三列。
#### 3.2.2 使用mysqldump和mysqlimport工具
**原理:**
`mysqldump` 工具可以将数据库中的数据导出为文本文件。`mysqlimport` 工具可以将文本文件中的数据导入到另一个数据库中。通过结合使用这两个工具,可以实现数据库之间的跨库数据导入。
**步骤:**
1. 使用 `mysqldump` 导出数据。
2. 使用 `mysqlimport` 导入数据。
**代码示例:**
**导出数据:**
```
mysqldump -u root -p123456 -h localhost -D source_db > data.sql
```
**导入数据:**
```
mysqlimport -u root -p123456 -h target_host -D target_db data.sql
```
**逻辑分析:**
该过程将 `source_db` 数据库中的数据导出到 `data.sql` 文件中,然后将该文件中的数据导入到 `target_db` 数据库中。
# 4. 数据导入的优化技巧
### 4.1 优化数据导入性能
#### 4.1.1 调整缓冲区大小
**原理:**
缓冲区是MySQL用来存储待处理数据的临时区域。调整缓冲区大小可以优化数据导入性能,因为较大的缓冲区可以容纳更多的数据,从而减少磁盘I/O操作。
**操作步骤:**
1. 确定当前缓冲区大小:`SHOW VARIABLES LIKE 'innodb_buffer_pool_size';`
2. 根据系统内存和数据量调整缓冲区大小:`SET GLOBAL innodb_buffer_pool_size = <new_size>;`
**参数说明:**
* `innodb_buffer_pool_size`:缓冲区大小,单位为字节。
**代码块:**
```sql
SET GLOBAL innodb_buffer_pool_size = 1024 * 1024 * 1024;
```
**逻辑分析:**
该代码将缓冲区大小设置为1GB。这将允许MySQL在导入数据时缓存更多的数据,从而提高性能。
#### 4.1.2 使用多线程导入
**原理:**
多线程导入可以并行执行多个导入任务,从而提高数据导入速度。
**操作步骤:**
1. 启用多线程导入:`SET GLOBAL innodb_import_parallel = 1;`
2. 指定导入线程数:`SET GLOBAL innodb_import_parallel_threads = <num_threads>;`
**参数说明:**
* `innodb_import_parallel`:是否启用多线程导入,1为启用,0为禁用。
* `innodb_import_parallel_threads`:导入线程数。
**代码块:**
```sql
SET GLOBAL innodb_import_parallel = 1;
SET GLOBAL innodb_import_parallel_threads = 4;
```
**逻辑分析:**
该代码启用多线程导入并指定使用4个导入线程。这将允许MySQL同时执行4个导入任务,从而加快数据导入速度。
### 4.2 确保数据导入的完整性和准确性
#### 4.2.1 使用事务处理
**原理:**
事务处理可以确保数据导入的原子性、一致性、隔离性和持久性(ACID)。如果导入过程中发生错误,事务可以回滚,防止数据损坏。
**操作步骤:**
1. 开始事务:`START TRANSACTION;`
2. 执行数据导入操作;
3. 提交事务:`COMMIT;`
**代码块:**
```sql
START TRANSACTION;
LOAD DATA INFILE 'data.csv' INTO TABLE my_table;
COMMIT;
```
**逻辑分析:**
该代码使用事务处理来保护数据导入操作。如果导入过程中发生任何错误,事务将回滚,防止数据损坏。
#### 4.2.2 进行数据验证和清理
**原理:**
数据验证和清理可以确保导入的数据完整准确。可以通过约束、触发器或外部工具来实现。
**操作步骤:**
1. 定义约束:`ALTER TABLE my_table ADD CONSTRAINT <constraint_name> <constraint_definition>;`
2. 创建触发器:`CREATE TRIGGER <trigger_name> BEFORE/AFTER INSERT/UPDATE/DELETE ON <table_name> FOR EACH ROW <trigger_body>;`
3. 使用外部工具进行数据验证和清理。
**代码块:**
```sql
ALTER TABLE my_table ADD CONSTRAINT unique_key UNIQUE (column1, column2);
CREATE TRIGGER check_data_integrity BEFORE INSERT ON my_table
FOR EACH ROW
IF (column1 IS NULL OR column2 IS NULL) THEN
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Invalid data';
END IF;
```
**逻辑分析:**
该代码使用约束和触发器来确保导入数据的完整性。约束定义了唯一键,防止重复数据。触发器在插入数据之前检查数据是否有效,并阻止无效数据插入。
# 5. 数据导入的常见应用场景
数据导入在实际应用中有着广泛的应用场景,以下列举一些常见的应用场景:
### 5.1 批量数据导入
批量数据导入是指一次性导入大量数据到数据库中。这种场景通常出现在以下情况:
- **新系统上线:**当新系统上线时,需要将旧系统中的数据导入到新系统中。
- **数据迁移:**当需要将数据从一个数据库迁移到另一个数据库时,需要进行批量数据导入。
- **数据备份和恢复:**当需要对数据库进行备份时,可以通过批量数据导入将数据导出到文件中。当需要恢复数据库时,可以通过批量数据导入将数据从文件中导入到数据库中。
### 5.2 数据迁移
数据迁移是指将数据从一个数据库迁移到另一个数据库。这种场景通常出现在以下情况:
- **数据库升级:**当数据库版本升级时,需要将数据从旧版本迁移到新版本。
- **数据库合并:**当需要将多个数据库合并为一个数据库时,需要将数据从多个数据库迁移到一个数据库。
- **数据库拆分:**当需要将一个数据库拆分为多个数据库时,需要将数据从一个数据库迁移到多个数据库。
### 5.3 数据备份和恢复
数据备份是指将数据库中的数据复制到其他存储介质中,以防数据丢失。数据恢复是指将备份的数据恢复到数据库中。这种场景通常出现在以下情况:
- **数据库故障:**当数据库发生故障时,可以通过数据恢复将数据恢复到数据库中。
- **误操作:**当对数据库进行误操作时,可以通过数据恢复将数据恢复到误操作前的状态。
- **数据丢失:**当数据被意外删除或损坏时,可以通过数据恢复将数据恢复到数据库中。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 数据导入的方方面面,从基础入门到高级技巧,涵盖了从 SQL 文件导入到数据迁移的各个方面。通过一系列详细的指南和深入的分析,该专栏旨在帮助读者掌握 MySQL 数据导入的秘诀,提高导入效率,解决常见问题,并确保数据传输的安全性和完整性。此外,该专栏还提供了各种工具和资源,帮助读者优化数据导入性能,自动化流程,并监控传输状态,从而实现数据传输的无缝衔接和高效管理。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【掌握Packet Tracer】:网络工程师必备的10个实践技巧与案例分析
# 摘要
本论文详细介绍了Packet Tracer在网络技术教育和实践中的应用,从基础操作到网络安全管理技巧,系统地阐述了网络拓扑构建、网络协议模拟、以及故障排除的策略和方法。文章还讨论了如何通过Packet Tracer进行高级网络协议的模拟实践,包括数据链路层、网络层和应用层协议的深入分析,以及使用AAA服务和网络监控工具进行身份认证与网络性能分析。本文旨在提供给网
【一步到位】解决cannot import name 'abs':彻底排查与预防秘籍
# 摘要
导入错误在软件开发中经常出现,它们可能导致程序无法正常执行。本文旨在分析导入错误的根本原因,并提供排查和预防这些错误的有效方法。通过深入研究错误追踪、代码审查、版本控制、环境与依赖管理等技术手段,本文提出了具体且实用的解决方案。文章还强调了编写良好编码规范、自动化检查、持续集成以及知识共享等预防策略的重要性,并通过实战案例分析来展示这些策略的应用效果。最后,本
【联想RD450X鸡血BIOS深度解析】:系统性能的幕后推手
# 摘要
本文详细探讨了联想RD450X服务器及其中的鸡血BIOS技术,旨在阐述BIOS在服务器中的核心作用、重要性以及性能优化潜力。通过对BIOS基本功能和组成的介绍,分析了鸡血BIOS相对于传统BIOS在性能提升方面的理论基础和技术手段。文中进一步讨论了BIOS更新、配置与优化的实践应用,并通过案例分析了鸡血BIOS在实际环境中的应用效果及常见问题的解决方案。最后,本
【打印机适配与调试的艺术】:掌握ESC-POS指令集在各打印机上的应用

# 摘要
本文深入探讨了打印机适配与调试的全面流程,涵盖了ESC-POS指令集的基础知识、编程实践、优化调整、高级调试技巧以及针对不同行业的需求解决方案。文章首先介绍了ESC-POS指令集的结构、核心指令和在不同打印机上的应用差异。随后,通过具体案例分析,展现了如何在
【RTEMS入门指南】:新手必读!30分钟掌握实时操作系统核心

# 摘要
本文详细介绍了RTEMS实时操作系统的架构、理论基础及其在嵌入式系统开发中的应用。首先概述了RTEMS的实时性和多任务调度策略,接着深入探讨了其核心组件、内核功能和编程模型。文中还指导了如何搭建RTEMS开发环境,包括工具链和开发板的配置,以及提供了一系列编程实践案例,涵盖任务管理、系统服务
【OpenMeetings界面革新】:打造个性化用户界面的实战教程
# 摘要
随着用户需求的多样化,对OpenMeetings这样的在线协作平台的界面提出了更高的要求。本文着重分析了界面革新的必要性,阐述了用户体验的重要性与界面设计原则。在实践开发章节中,详细探讨了界面开发的工具选择、技术栈、以及开发流程。此外,本文还强调了个性化界
【PSNR实战手册】:10个案例教你如何在项目中高效运用PSNR(附代码解析)

# 摘要
峰值信噪比(PSNR)是一种常用的衡量信号和图像质量的客观评估标准,它通过计算误差功率与最大可能信号功率的比值来量化质量。本文详细介绍了PSNR的理论基础、计算方法和评估标准,并探讨了其在视频压缩、图像处理、实时传输监测等不同领域的应用。文章进一步通过实战案例分析,深入研究PSNR在具体项目中的应用效果和性能监测。尽管PSNR具有局限性,但通过与其他评估
博通ETC OBU Transceiver:技术亮点与故障排查实用指南
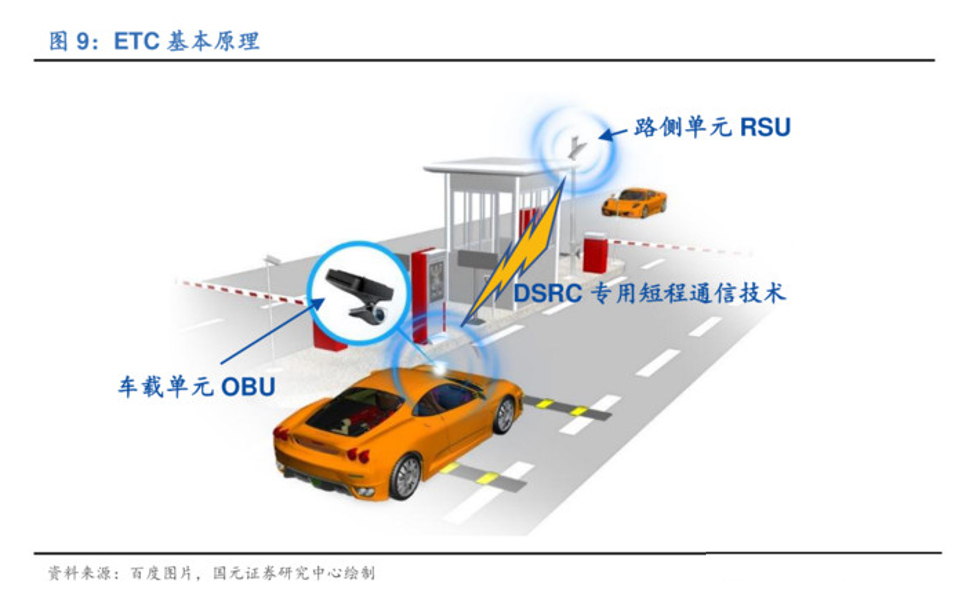
# 摘要
博通ETC OBU Transceiver作为电子收费系统的关键设备,其性能直接影响通信的稳定性和系统的可靠性。本文首先概述了OBU Transceiver的基本概念和功能架构,接着详细解析了其核心的技术亮点,包括先进的通信协议标准、数据加密技术,以及创新特性和实际应用案例。之后,本文深入探讨了故障排查的基础知识和高级技术,旨在为技术
【低频数字频率计软件界面创新】:打造用户友好交互体验

# 摘要
随着科技的不断进步,低频数字频率计的软件界面设计变得更加重要,它直接影响着用户的使用体验和设备的性能表现。本文首先概述了低频数字频率计软件界面设计的基本概念,接着深入探讨了用户交互理论基础,包括用户体验原则、交互设计模式和用户研究方法。随后,文章详细介绍了界面创新实践方法,其中包括创新设计流程
【企业实践中的成功故事】:ARXML序列化规则的应用案例剖析

# 摘要
随着汽车行业的快速发展,ARXML序列化规则已成为数据管理和业务流程中不可或缺的技术标准。本文首先概述了ARXML序列化规则的基础知识,包括其定义、应用范围及其在企业中的重要性。接着,文章详细分析了ARXML序列化规则的构成,以及如何在数据管理中实现数据导入导出和校验清洗,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )