解决常见问题,畅通数据传输:MySQL数据导入导出疑难解答
发布时间: 2024-07-23 20:05:02 阅读量: 26 订阅数: 42 
# 1. MySQL数据导入导出简介
MySQL数据导入导出是将数据从外部系统或文件导入到MySQL数据库,或将MySQL数据库中的数据导出到外部系统或文件的过程。数据导入导出在数据库管理中至关重要,用于数据备份、数据迁移、数据交换和数据分析等场景。
MySQL提供了多种数据导入导出工具和方法,包括LOAD DATA INFILE命令、INSERT INTO ... SELECT ... 语句、SELECT INTO OUTFILE命令和mysqldump命令。这些工具和方法具有不同的语法、选项和适用场景,可以根据具体需求选择使用。
数据导入导出过程中可能遇到各种问题,如数据类型不匹配、外键约束问题、数据丢失或损坏等。了解这些常见问题并掌握相应的解决方法,可以确保数据导入导出操作的顺利进行。
# 2. MySQL数据导入的实践技巧
### 2.1 数据导入命令的语法和选项
#### 2.1.1 LOAD DATA INFILE命令
**语法:**
```sql
LOAD DATA INFILE '<文件名>' INTO TABLE <表名>
[FIELDS TERMINATED BY '<分隔符>']
[LINES TERMINATED BY '<换行符>']
[IGNORE <行数>]
[<字段列表>]
```
**参数说明:**
- `<文件名>`:要导入的数据文件路径。
- `<表名>`:要导入数据的目标表。
- `<分隔符>`:用于分隔字段的字符,默认为制表符。
- `<换行符>`:用于分隔行的字符,默认为换行符。
- `<行数>`:指定要忽略的数据文件中的前几行。
- `<字段列表>`:指定要导入的字段列表,如果不指定,则导入所有字段。
**示例:**
```sql
LOAD DATA INFILE 'data.csv' INTO TABLE users
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1
(id, name, email);
```
此命令将从名为 `data.csv` 的文件中导入数据,其中字段以逗号分隔,行以换行符分隔,忽略第一行,并导入 `id`、`name` 和 `email` 字段。
#### 2.1.2 INSERT INTO ... SELECT ... 语句
**语法:**
```sql
INSERT INTO <表名> (<字段列表>)
SELECT <字段列表>
FROM <数据源表>;
```
**参数说明:**
- `<表名>`:要导入数据的目标表。
- `<字段列表>`:指定要导入的字段列表,如果不指定,则导入所有字段。
- `<数据源表>`:要从其导入数据的源表。
**示例:**
```sql
INSERT INTO users (id, name, email)
SELECT id, name, email
FROM temp_users;
```
此命令将从名为 `temp_users` 的临时表中导入数据,并将其插入到 `users` 表中。
### 2.2 数据导入的常见问题及解决方法
#### 2.2.1 数据类型不匹配问题
**问题:**导入的数据类型与目标表中的字段类型不匹配。
**解决方法:**
- 确保数据文件中的数据类型与目标表中的字段类型一致。
- 使用 `CAST()` 函数将数据类型转换为目标表中所需的类型。
**示例:**
```sql
LOAD DATA INFILE 'data.csv' INTO TABLE users
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
(id, name, email)
SET email = CAST(email AS VARCHAR(255));
```
此命令将将 `email` 字段中的数据类型转换为 `VARCHAR(255)`。
#### 2.2.2 外键约束问题
**问题:**导入的数据违反了目标表中的外键约束。
**解决方法:**
- 确保导入的数据满足外键约束。
- 使用 `ON DELETE CASCADE` 或 `ON UPDATE CASCADE` 选项来级联删除或更新相关记录。
**示例:**
```sql
LO
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 数据导入的方方面面,从基础入门到高级技巧,涵盖了从 SQL 文件导入到数据迁移的各个方面。通过一系列详细的指南和深入的分析,该专栏旨在帮助读者掌握 MySQL 数据导入的秘诀,提高导入效率,解决常见问题,并确保数据传输的安全性和完整性。此外,该专栏还提供了各种工具和资源,帮助读者优化数据导入性能,自动化流程,并监控传输状态,从而实现数据传输的无缝衔接和高效管理。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据仓库Join优化】:构建高效数据处理流程的策略

# 1. 数据仓库Join操作的基础理解
## 数据库中的Join操作简介
在数据仓库中,Join操作是连接不同表之间数据的核心机制。它允许我们根据特定的字段,合并两个或多个表中的数据,为数据分析和决策支持提供整合后的视图。Join的类型决定了数据如何组合,常用的SQL Join类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
## SQL Joi
【数据访问速度优化】:分片大小与数据局部性策略揭秘
# 1. 数据访问速度优化概论
在当今信息化高速发展的时代,数据访问速度在IT行业中扮演着至关重要的角色。数据访问速度的优化,不仅仅是提升系统性能,它还可以直接影响用户体验和企业的经济效益。本章将带你初步了解数据访问速度优化的重要性,并从宏观角度对优化技术进行概括性介绍。
## 1.1 为什么要优化数据访问速度?
优化数据访问速度是确保高效系统性能的关键因素之一
MapReduce与大数据:挑战PB级别数据的处理策略
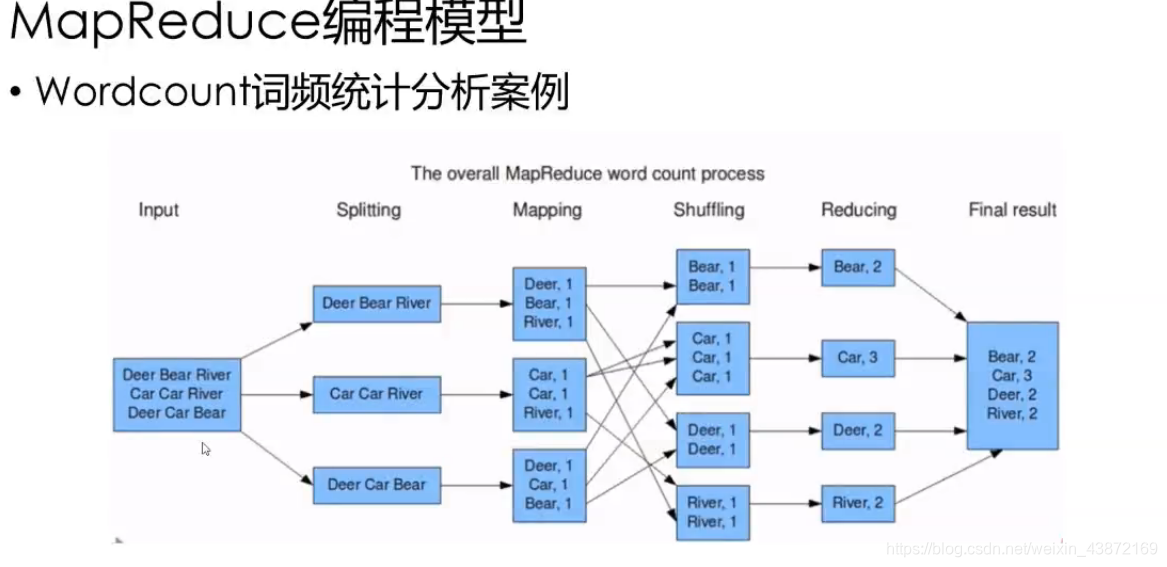
# 1. MapReduce简介与大数据背景
## 1.1 大数据的定义与特性
大数据(Big Data)是指传统数据处理应用软件难以处
MapReduce小文件处理:数据预处理与批处理的最佳实践

# 1. MapReduce小文件处理概述
## 1.1 MapReduce小文件问题的普遍性
在大规模数据处理领域,MapReduce小文件问题普遍存在,严重影响
MapReduce自定义分区:规避陷阱与错误的终极指导

# 1. MapReduce自定义分区的理论基础
MapReduce作为一种广泛应用于大数据处理的编程模型,其核心思想在于将计算任务拆分为Map(映射)和Reduce(归约)两个阶段。在MapReduce中,数据通过键值对(Key-Value Pair)的方式被处理,分区器(Partitioner)的角色是决定哪些键值对应该发送到哪一个Reducer。这种机制至关
【大数据精细化管理】:掌握ReduceTask与分区数量的精准调优技巧

# 1. 大数据精细化管理概述
在当今的信息时代,企业与组织面临着数据量激增的挑战,这要求我们对大数据进行精细化管理。大数据精细化管理不仅关系到数据的存储、处理和分析的效率,还直接关联到数据价值的最大化。本章节将概述大数据精细化管理的概念、重要性及其在业务中的应用。
大数据精细化管理涵盖从数据
【异常管理】:MapReduce Join操作的错误处理与异常控制
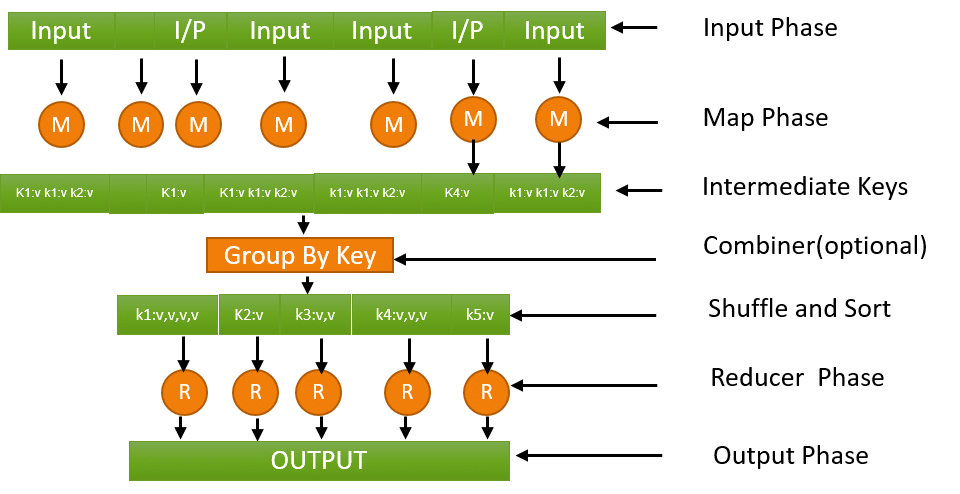
# 1. MapReduce Join操作基础
MapReduce是一种广泛使用的编程模型,用于在分布式系统上处理和生成大数据集。在MapReduce的场景中,Join操作是一个重要的数据处理手段,它将多个数据集的相关信息通过键值连接起来。本章将从MapReduce Join操作的基本概念入手,讨论在分布式环境中进行数据连接的必要条件,并探索适用于各种数据集规模的Join策略。
## 1.1 MapR
MapReduce中的Combiner与Reducer选择策略:如何判断何时使用Combiner

# 1. MapReduce框架基础
MapReduce 是一种编程模型,用于处理大规模数据集
项目中的Map Join策略选择
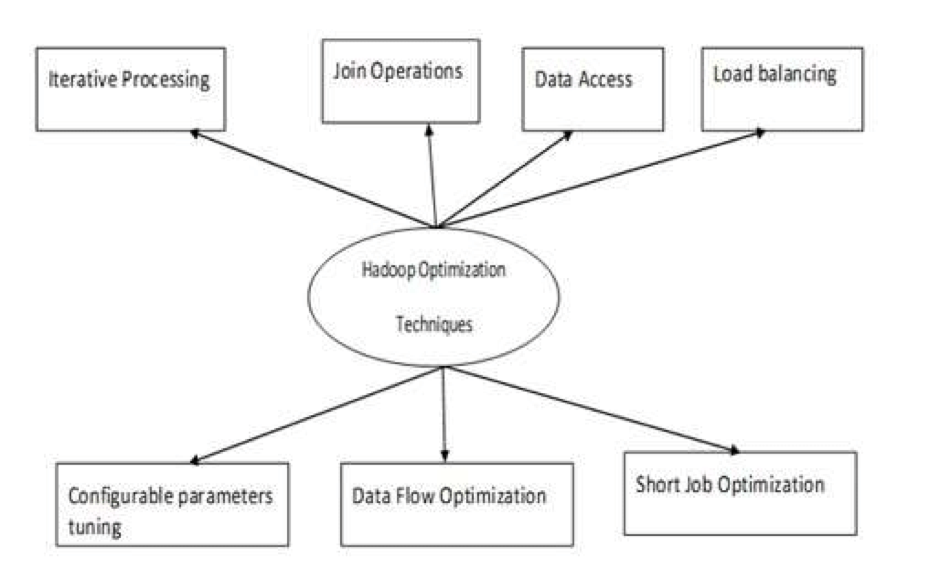
# 1. Map Join策略概述
Map Join策略是现代大数据处理和数据仓库设计中经常使用的一种技术,用于提高Join操作的效率。它主要依赖于MapReduce模型,特别是当一个较小的数据集需要与一个较大的数据集进行Join时。本章将介绍Map Join策略的基本概念,以及它在数据处理中的重要性。
Map Join背后的核心思想是预先将小数据集加载到每个Map任
Map Side Join参数调优:经验分享与故障排除技巧
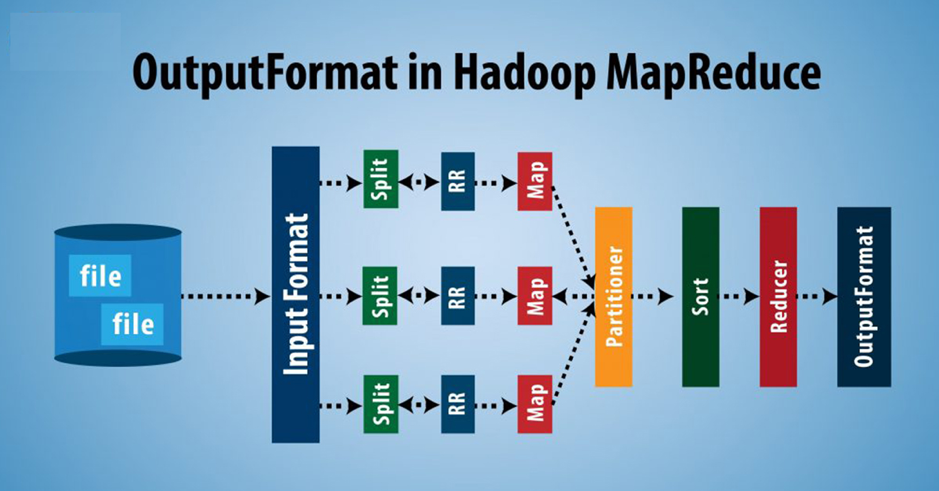
# 1. Map Side Join简介
Map Side Join是大数据处理中常用的一种优化技术,尤其适用于某些特定的使用场景,比如当一个较大数据集需要和一个非常小的数据集进行Join操作时。这一技术的主要优势在于能够显著减少数据在网络中的传输,提高Join操作的效率。通过对Map Side Join的深入分析,可以发现它在保证数据处理性能的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )