基于ResNet的一阶优化算法优缺点对比
发布时间: 2024-05-02 21:09:07 阅读量: 14 订阅数: 16 

# 1. 基于ResNet的一阶优化算法概述**
一阶优化算法是深度学习中常用的优化方法,它们通过迭代更新模型参数来最小化损失函数。基于ResNet的图像分类任务中,一阶优化算法的性能至关重要。本文将深入探讨一阶优化算法的原理、实践和在ResNet中的应用。
# 2.1 梯度下降法
### 2.1.1 梯度下降法的基本原理
梯度下降法是一种一阶优化算法,它通过迭代的方式更新模型参数,以最小化损失函数。在每次迭代中,梯度下降法都会计算损失函数关于模型参数的梯度,并沿着梯度负方向更新参数。
**具体步骤如下:**
1. 初始化模型参数 $\theta$
2. 计算损失函数 $L(\theta)$ 的梯度 $\nabla L(\theta)$
3. 更新模型参数:$\theta = \theta - \alpha \nabla L(\theta)$
4. 重复步骤 2-3,直到满足终止条件
其中,$\alpha$ 为学习率,控制着更新步长的大小。
### 2.1.2 梯度下降法的变种
为了提高梯度下降法的收敛速度和鲁棒性,提出了多种变种算法,包括:
- **动量法:**动量法在更新参数时加入了动量项,可以加速收敛并减少振荡。
- **RMSprop算法:**RMSprop算法通过自适应调整学习率,可以提高在非凸优化问题中的收敛速度。
- **Adam算法:**Adam算法结合了动量法和RMSprop算法的优点,具有更快的收敛速度和更好的鲁棒性。
**代码块:**
```python
import numpy as np
def gradient_descent(loss_fn, gradient_fn, theta0, learning_rate, num_iters):
"""
梯度下降法
Args:
loss_fn: 损失函数
gradient_fn: 损失函数的梯度函数
theta0: 初始参数
learning_rate: 学习率
num_iters: 迭代次数
Returns:
theta: 最优参数
"""
theta = theta0
for _ in range(num_iters):
gradient = gradient_fn(theta)
theta -= learning_rate * gradient
return theta
```
**逻辑分析:**
该代码实现了梯度下降法。首先,它初始化模型参数 `theta`。然后,它进入一个循环,在循环中,它计算损失函数的梯度,并使用梯度更新参数。循环在指定的最大迭代次数后停止。
**参数说明:**
- `loss_fn`:损失函数
- `gradient_fn`:损失函数的梯度函数
- `theta0`:初始参数
- `learning_rate`:学习率
- `num_iters`:迭代次数
# 3. 基于ResNet的一阶优化算法实践
### 3.1 不同一阶优化算法的实现
#### 3.1.1 梯度下降法的实现
梯度下降法的实现相对简单,其伪代码如下:
```python
def gradient_descent(model, loss_fn, optimizer, epochs, batch_size):
for epoch in range(epochs):
for batch in data_loader:
optimizer.zero_grad()
loss = loss_fn(model(batch))
loss.backward()
optimizer.step()
```
在该实现中,`model`为ResNet模型,`loss_fn`为损失函数,`optimizer`为梯度下降优化器,`epochs`为训练轮数,`batch_size`为批次大小。
##
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**专栏简介**
该专栏深入探索了 ResNet 深度学习模型的方方面面,包括其残差连接的工作原理、不同版本及其适用场景、TensorFlow 中的迁移学习应用、训练技巧和调优策略。它还探讨了 ResNet 在目标检测、梯度消失问题、残差块设计、模型压缩和加速、自然语言处理、轻量级模型设计、过拟合解决方法、与注意力机制的结合、在生成对抗网络中的作用、多标签图像分类、与注意力机制在自然语言处理中的结合、端到端推理系统中的角色、梯度回传机制、一阶优化算法、一致性和收敛性,以及图像超分辨率重建中的应用。通过深入的分析和示例,该专栏为读者提供了对 ResNet 模型及其广泛应用的全面理解。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
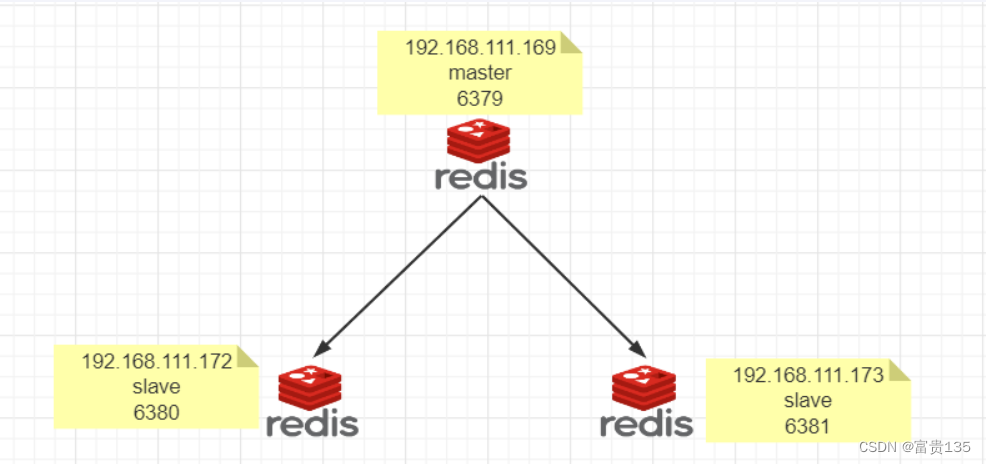
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
MATLAB散点图:使用散点图进行信号处理的5个步骤
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )