




ResNet模型压缩与加速方法综述


深度学习模型压缩与加速综述
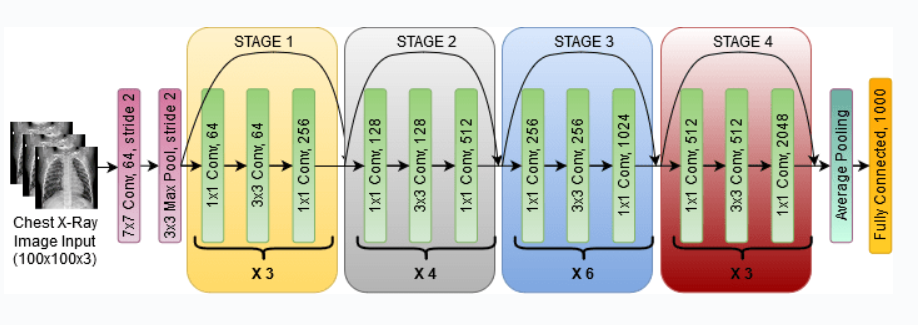
1. ResNet模型简介**
ResNet(残差网络)是一种深度卷积神经网络,因其在图像分类、目标检测和语义分割等计算机视觉任务上的出色表现而闻名。ResNet的创新之处在于引入了残差连接,它允许梯度在网络中更有效地传播,从而缓解了梯度消失问题,并使网络能够达到更大的深度。ResNet模型通常由多个残差块组成,每个残差块都包含两个或三个卷积层和一个残差连接。残差连接将输入特征图与卷积层的输出相加,从而创建了更丰富的特征表示。
2. ResNet模型压缩方法
2.1 模型剪枝
模型剪枝是一种通过移除不重要的权重和激活来压缩模型的方法。它可以显著减少模型的大小,同时保持其准确性。
2.1.1 权重剪枝
权重剪枝通过移除不重要的权重来压缩模型。这些权重通常是接近零或对模型的输出影响很小的权重。
- import numpy as np
- def weight_pruning(model, pruning_ratio):
- for layer in model.layers:
- if isinstance(layer, keras.layers.Dense):
- weights = layer.get_weights()
- mask = np.abs(weights[0]) > pruning_ratio
- weights[0] = np.multiply(weights[0], mask)
- layer.set_weights(weights)
参数说明:
model: 要修剪的模型。pruning_ratio: 修剪权重的比例。
代码逻辑分析:
该代码逐层遍历模型,对于每个密集层,它获取权重并创建一个掩码,该掩码将权重值大于修剪比例的权重标记为 True。然后,它将权重与掩码相乘,将不重要的权重设置为零。
2.1.2 激活剪枝
激活剪枝通过移除不重要的激活来压缩模型。这些激活通常是接近零或对模型的输出影响很小的激活。
- import tensorflow as tf
- def activation_pruning(model, pruning_ratio):
- for layer in model.layers:
- if isinstance(layer, keras.layers.Dense):
- activations = layer.get_output()
- mask = tf.math.greater(tf.abs(activations), pruning_ratio)
- activations = tf.multiply(activations, mask)
- layer.set_output(activations)
参数说明:
model: 要修剪的模型。pruning_ratio: 修剪激活的比例。
代码逻辑分析:
该代码逐层遍历模型,对于每个密集层,它获取激活并创建一个掩码,该掩码将激活值大于修剪比例的激活标记为 True。然后,它将激活与掩码相乘,将不重要的激活设置为零。
2.2 模型量化
模型量化是一种通过将模型中的浮点权重和激活转换为低精度格式来压缩模型的方法。这可以显著减少模型的大小,同时保持其准确性。
2.2.1 浮点量化
浮点量化将浮点权重和激活转换为低精度浮点格式,例如 FP16 或 FP8。这可以减少模型的大小,同时保持其准确性。
- import tensorflow as tf
- def float_quantization(model):
- converter = tf.lite.TFLiteConverter.from_keras_model(model)
- converter.optimizations = [tf.lite.Optimize.DEFAULT]
- converter.target_spec.supported_types = [tf.float16]
- quantized_model = converter.convert()
参数说明:
model: 要量化的模型。
代码逻辑分析:
该代码使用 TensorFlow Lite 转换器将模型转换为浮点 16 位量化模型。转换器应用默认优化,并将支持的类型设置为 FP16。
2.2.2 整数量化
整数量化将浮点权重和激活转换为整数格式。这可以进一步减少模型的大小,但可能会降低模型的准确性。
- import tensorflow as tf
- def int_quantization(model):
- converter = tf.lite.TFLiteConverter.from_keras_model(model)
- converter.optimizations = [tf.lite.Optimize.DEFAULT]
- converter.target_spec.supported_types = [tf.int8]
- quantized_model = converter.convert()
参数说明:
model: 要量化的模型。
代码逻辑分析:
该代码使用 TensorFlow Lite 转换器将模型转换为整数 8 位量化模型。转换器应用默认优化,并将支持的类型设置为 INT8。
2.3 模型蒸馏
模型蒸馏是一种通过将大型教师模型的知识转移到较小学生模型来压缩模型的方法。这可以创建具有与教师模型相当的准确性的较小模型。
2.3.1 知识蒸馏
知识蒸馏通过最小化学生模型和教师模型输出之间的差异来转移知识。
- import tensorflow as tf
- def knowledge_distillation(teacher_model, student_model, data):
- optimizer = tf.keras.optimizers.Adam()
- for batch in data:
- x, y = batch
- teacher_logits = teacher_model(x, training=False)
- student_logits = student_model(x, training=True)
- loss = tf.keras.losses.categorical_crossentropy(teacher_logits, student_logits)
- optimizer.minimize(loss, student_model.trainable_variables)
参数说明:
teacher_model: 教师模型。student_model: 学生模型。data: 用于训练的训练数据。
代码逻辑分析:
该代码使用 Adam 优化器最小化学生模型和教师模型输出之间的交叉熵损失。它遍历训练数据,对于每个批次,它获取教师模型和学生模型的输出,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
4线触摸屏抗干扰设计秘籍:HR2046技术手册中的高效策略
【PDF新手成长指南】:从创建到优化,全面提升文档处理技能
【系统稳定性提升指南】:精通PSRR测试技巧与LDO性能分析
【俄罗斯方块项目实战全纪录】:构建游戏的完整旅程
快手 DID 设备注册流程详解:基础指南及常见问题解答
编程实践指南:用代码实现二维图形变换与动画
【TRL校准理论基础深度剖析】:原理清晰,实现步骤一步到位
CISCO项目实战:构建响应速度极快的数据监控系统
整合CDP到灾难恢复计划:5步走策略揭秘


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )




















