【NLP应用探讨】:逻辑回归在自然语言处理中的应用探讨
发布时间: 2024-04-19 18:53:19 阅读量: 84 订阅数: 90 

# 1. 介绍逻辑回归在自然语言处理中的应用
逻辑回归是一种常见的分类算法,在自然语言处理中有着广泛的应用。通过逻辑回归模型,我们可以对文本数据进行情感分析、文本分类、命名实体识别等任务。其简单且高效的特性使其成为NLP领域中不可或缺的一部分。逻辑回归通过对文本特征进行建模,能够快速地对文本进行分类和预测,为后续深入学习和其他机器学习算法打下坚实基础。在本章中,我们将深入探讨逻辑回归在NLP中的原理和具体应用,帮助读者更好地理解其作用和意义。
# 2. 自然语言处理基础知识
自然语言处理(Natural Language Processing, NLP)是人工智能领域中的一个重要分支,旨在让机器能够理解、解释和生成人类语言。在理解逻辑回归在自然语言处理中的应用前,我们有必要先了解一些NLP的基础知识。
### 2.1 语言模型
语言模型是NLP中的重要概念,用于描述语言中词汇序列的概率分布。常见的语言模型包括n-gram模型、神经语言模型和序列标注模型。
#### 2.1.1 n-gram模型
n-gram模型是基于n个词组成的序列来预测下一个词的概率模型。例如,当n取2时,称为bigram模型;n取3时,称为trigram模型。
在实际应用中,n-gram模型被广泛用于语言建模、自动文本纠错等任务。
```python
# 以bigram模型为例
from nltk import bigrams
sentence = 'This is a sample sentence for n-gram model.'
tokens = sentence.split()
bi_grams = list(bigrams(tokens))
print(bi_grams)
```
打印结果:
```
[('This', 'is'), ('is', 'a'), ('a', 'sample'), ('sample', 'sentence'), ('sentence', 'for'), ('for', 'n-gram'), ('n-gram', 'model.')]
```
#### 2.1.2 神经语言模型
神经语言模型是利用神经网络来建模语言的概率分布,能够更准确地捕捉词与词之间的语义关系。常见的神经语言模型包括循环神经网络(RNN)和Transformer模型。
神经语言模型的发展使得在NLP任务中取得了显著的进展,如机器翻译、情感分析等。
### 2.2 文本表示与处理
文本表示与处理是NLP中另一个核心概念,涉及将文本转化为计算机能够理解和处理的形式,常见的方法包括词袋模型、TF-IDF和Word2Vec。
#### 2.2.1 词袋模型
词袋模型将文本表示为词汇的集合,忽略了词汇顺序,只关注词汇出现的频率。在文本分类、信息检索等任务中得到广泛应用。
```python
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
```
打印结果:
```
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
```
#### 2.2.2 TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用于信息检索与文本挖掘的加权技术,可以衡量词的重要性。
```python
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(corpus)
print(X_tfidf.toarray())
```
打印结果:
```
[[0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524]
[0. 0.6876236 0. 0.28108867 0. 0.53864762 0.28108867 0. 0.28108867]
[0.51184851 0. 0. 0.26710379 0.51184851 0. 0.26710379 0.51184851 0.26710379]
[0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524]]
```
#### 2.2.3 Word2Vec
Word2Vec是一种将词语嵌入高维空间的技术,通过训练方式使得语义相近的词在空间中距离较近。这种表示方法在自然语言处理任务中被广泛应用,如文本聚类、自动摘要等。
```python
from gensim.models import Word2Vec
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
model
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《逻辑回归常见问题与详细解决操作》专栏深入探讨了逻辑回归模型的原理、参数估计、特征选择、评估指标、数据预处理、过拟合和欠拟合问题、样本不平衡处理等关键方面。此外,专栏还提供了逻辑回归与线性回归、支持向量机、神经网络等模型的对比分析,并展示了逻辑回归在金融、医疗健康、市场营销、社交网络分析、自然语言处理、推荐系统、图像识别等领域的应用案例。通过对常见问题的全面解析和详细的解决方案指导,本专栏旨在帮助读者全面掌握逻辑回归模型,解决实际应用中遇到的各种问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【硬件实现】:如何构建性能卓越的PRBS生成器

# 摘要
本文全面探讨了伪随机二进制序列(PRBS)生成器的设计、实现与性能优化。首先,介绍了PRBS生成器的基本概念和理论基础,重点讲解了其工作原理以及相关的关键参数,如序列长度、生成多项式和统计特性。接着,分析了PRBS生成器的硬件实现基础,包括数字逻辑设计、FPGA与ASIC实现方法及其各自的优缺点。第四章详细讨论了基于FPGA和ASIC的PRBS设计与实现过程,包括设计方法和验
NUMECA并行计算核心解码:掌握多节点协同工作原理
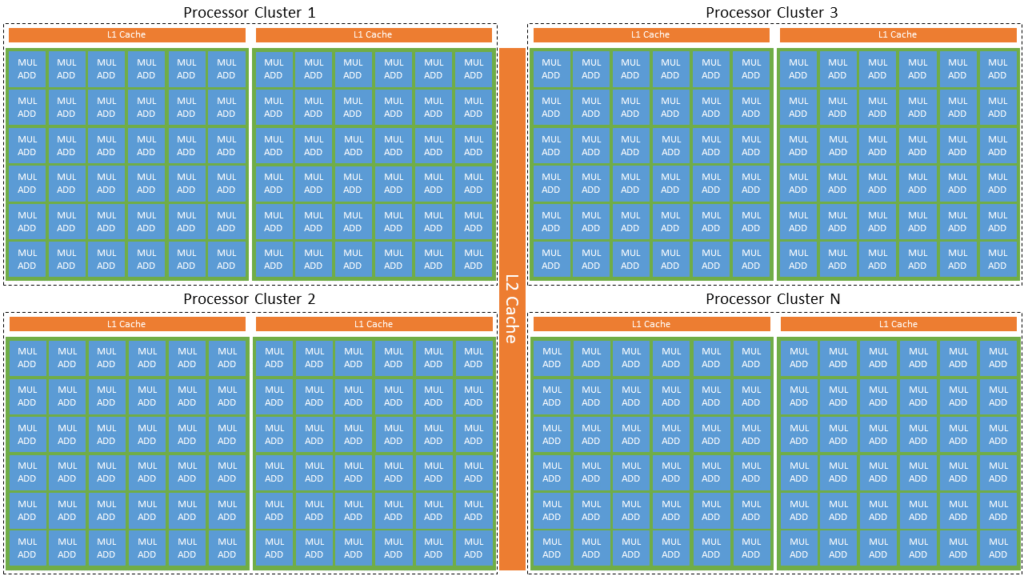
# 摘要
NUMECA并行计算是处理复杂计算问题的高效技术,本文首先概述了其基础概念及并行计算的理论基础,随后深入探讨了多节点协同工作原理,包括节点间通信模式以及负载平衡策略。通过详细说明并行计算环境搭建和核心解码的实践步骤,本文进一步分析了性能评估与优化的重要性。文章还介绍了高级并行计算技巧,并通过案例研究展示了NUMECA并行计算的应用。最后,本文展望了并行计
提升逆变器性能监控:华为SUN2000 MODBUS数据优化策略

# 摘要
逆变器作为可再生能源系统中的关键设备,其性能监控对于确保系统稳定运行至关重要。本文首先强调了逆变器性能监控的重要性,并对MODBUS协议进行了基础介绍。随后,详细解析了华为SUN2000逆变器的MODBUS数据结构,阐述了数据包基础、逆变器的注册地址以及数据的解析与处理方法。文章进一步探讨了性能数据的采集与分析优化策略,包括采集频率设定、异常处理和高级分析技术。
小红书企业号认证必看:15个常见问题的解决方案

# 摘要
本文系统地介绍了小红书企业号的认证流程、准备工作、认证过程中的常见问题及其解决方案,以及认证后的运营和维护策略。通过对认证前准备工作的详细探讨,包括企业资质确认和认证材料
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
【UML类图与图书馆管理系统】:掌握面向对象设计的核心技巧
# 摘要
本文旨在探讨面向对象设计中UML类图的应用,并通过图书馆管理系统的需求分析、设计、实现与测试,深入理解UML类图的构建方法和实践。文章首先介绍了UML类图基础,包括类图元素、关系类型以及符号规范,并详细讨论了高级特性如接口、依赖、泛化以及关联等。随后,文章通过图书馆管理系统的案例,展示了如何将UML类图应用于需求分析、系统设计和代码实现。在此过程中,本文强调了面向对象设计原则,评价了UML类图在设计阶段
【虚拟化环境中的SPC-5】:迎接虚拟存储的新挑战与机遇
# 摘要
本文旨在全面介绍虚拟化环境与SPC-5标准,深入探讨虚拟化存储的基础理论、存储协议与技术、实践应用案例,以及SPC-5标准在虚拟化环境中的应用挑战。文章首先概述了虚拟化技术的分类、作用和优势,并分析了不同架构模式及SPC-5标准的发展背景。随后
硬件设计验证中的OBDD:故障模拟与测试的7大突破
# 摘要
OBDD(有序二元决策图)技术在故障模拟、测试生成策略、故障覆盖率分析、硬件设计验证以及未来发展方面展现出了强大的优势和潜力。本文首先概述了OBDD技术的基础知识,然后深入探讨了其在数字逻辑故障模型分析和故障检测中的应用。进一步地,本文详细介绍了基于OBDD的测试方法,并分析了提高故障覆盖率的策略。在硬件设计验证章节中,本文通过案例分析,展示了OBDD的构建过程、优化技巧及在工业级验证中的应用。最后,本文展望了OBDD技术与机器学习等先进技术的融合,以及OBDD工具和资源的未来发展趋势,强调了OBDD在AI硬件验证中的应用前景。
# 关键字
OBDD技术;故障模拟;自动测试图案生成
海康威视VisionMaster SDK故障排除:8大常见问题及解决方案速查
# 摘要
本文全面介绍了海康威视VisionMaster SDK的使用和故障排查。首先概述了SDK的特点和系统需求,接着详细探讨了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )