Scipy核心模块深度解析:4个步骤精通库结构与功能
发布时间: 2024-09-29 20:38:43 阅读量: 10 订阅数: 27 

# 1. Scipy库概览与安装
## 1.1 Scipy库简介
Scipy是一个在Python环境中广泛使用的开源科学计算库,它提供了多个用于科学和工程计算的模块。这个库是数值处理和算法实现的基石,尤其在矩阵计算、线性代数、信号处理、统计分析等方面。
## 1.2 安装Scipy库
安装Scipy库相对简单,可以通过Python的包管理工具pip进行安装。命令如下:
```bash
pip install scipy
```
对于使用conda的用户,则可以使用以下命令:
```bash
conda install scipy
```
## 1.3 检查Scipy安装状态
安装完成后,为了确保Scipy库安装正确,可以在Python环境中执行以下代码:
```python
import scipy
print(scipy.__version__)
```
这段代码会导入Scipy库,并打印出当前安装的版本号,如果成功执行并且没有抛出错误,那么就意味着Scipy已经正确安装在您的系统中。
# 2. Scipy基础结构与核心概念
### 2.1 Scipy的子模块与功能总览
#### 2.1.1 理解Scipy的模块架构
SciPy是一个开源的Python算法库和数学工具包,它建立在Numpy之上,用于提供高级的数学例程,如数值积分、优化、统计和线性代数等。SciPy的架构包含多个子模块,每个模块都有自己的特定功能。
SciPy库的模块架构可以分为如下几个核心部分:
- `scipy.cluster`:数据聚类算法
- `scipy.constants`:物理常数和数学常数
- `scipy.integrate`:数值积分例程
- `scipy.interpolate`:插值技术
- `scipy.io`:数据输入输出支持
- `scipy.linalg`:线性代数例程
- `scipy.optimize`:优化算法
- `scipy.signal`:信号处理工具
- `scipy.sparse`:稀疏矩阵运算
- `scipy.spatial`:空间数据结构和算法
- `scipy.special`:特殊函数
- `scipy.stats`:统计分布和测试
#### 2.1.2 概览各子模块的核心功能
下面我们将概览Scipy中几个核心子模块的功能,这将帮助用户理解它们在实际计算中的应用和重要性。
- `scipy.integrate`:这个模块提供了执行数值积分的函数,如定积分和常微分方程求解器。这对于物理学中的动力学方程、化学反应的速率方程等领域有重要作用。
- `scipy.interpolate`:插值用于通过一组数据点构建新的值。`scipy.interpolate`包含多种一维、二维以及多维插值方法,广泛应用于数据分析和处理。
- `scipy.optimize`:优化模块中包含多种算法,用于求解函数的最小值或最大值,或找到满足某些约束条件的最优解。它被用于工程设计、经济学、统计学和其他领域的复杂问题。
- `scipy.signal`:信号处理模块提供了许多用于设计、分析和滤波数字和模拟信号的工具。这对于通信、声学和图像处理等科学工程问题尤为重要。
- `scipy.stats`:统计模块提供了大量的概率分布、统计函数以及检验方法。它可以用于数据分析、统计建模、假设检验等。
### 2.2 数值数据的处理
#### 2.2.1 Ndarray的数据结构
SciPy构建在Numpy的基础之上,其核心是Numpy数组(Ndarray)的数据结构。 Ndarray是一种通用的同质多维数组,其所有的元素都必须是相同类型的。这种数据结构为高效执行数学运算提供了必要的基础。
Ndarray的关键特性包括:
- 高维:Ndarray可以是任意维度,可以用来表示矩阵、向量或标量。
- 动态类型:可以存储任何数据类型,如整型、浮点型、复数等。
- 内存连续:内存按行或列存储,这允许使用高效的C语言循环进行运算。
- 向量化操作:支持数学运算符重载,使得数组运算简洁且高效。
#### 2.2.2 数组操作与数组函数
通过Ndarray,SciPy可以执行复杂的数组操作和数组函数,如切片、花式索引、广播等。
- **切片和索引**:与Python列表类似,可以使用切片和索引来访问数组的元素或子集。
```python
import numpy as np
# 创建一个2x3的数组
a = np.array([[1, 2, 3], [4, 5, 6]])
# 访问第二行第一列的元素
print(a[1][0]) # 输出 4
# 使用切片访问第二行的元素
print(a[1, :]) # 输出 [4, 5, 6]
```
- **花式索引**:结合使用索引数组和数组切片,可以同时从数组中提取多个元素。
```python
# 创建一个2x3的数组
b = np.array([[1, 2, 3], [4, 5, 6]])
# 使用花式索引提取特定元素
print(b[[0, 1], [2, 0]]) # 输出 [3, 4]
```
- **广播**:广播是一种强大的机制,允许Numpy在算术运算中自动处理不同大小的数组。
```python
# 创建一个1维数组和一个2维数组,进行广播运算
a = np.array([1, 2, 3])
b = np.array([[4, 5, 6], [7, 8, 9]])
# 乘法操作时,1维数组会自动扩展到2维
print(a * b)
```
数组函数在SciPy中的应用是处理数值数据的基础,提供了大量的数组级函数,包括但不限于数学运算、统计分析、排序和比较等。
```python
# 生成一个3x3的随机数组
random_array = np.random.rand(3, 3)
# 计算数组的平均值和标准差
mean_value = np.mean(random_array)
std_dev = np.std(random_array)
print("平均值:", mean_value)
print("标准差:", std_dev)
```
### 2.3 信号处理与统计模块
#### 2.3.1 信号处理工具的使用
`scipy.signal`提供了丰富的信号处理工具,包括数字和模拟滤波器设计、卷积和相关性分析、傅里叶变换和小波变换等。
信号处理工具中的一些主要函数包括:
- `scipy.signal.lfilter`:应用线性滤波器
- `scipy.signal.filtfilt`:零相位滤波
- `scipy.signal.convolve`:卷积计算
- `scipy.signal.correlate`:相关性分析
- `scipy.signal.stft` 和 `scipy.signal.ifft`:短时傅里叶变换和逆变换
例如,一个简单的低通滤波器的实现如下:
```python
from scipy.signal import butter, lfilter
# 设计一个低通滤波器
def butter_lowpass(cutoff, fs, order=5):
nyq = 0.5 * fs # 奈奎斯特频率
normal_cutoff = cutoff / nyq
b, a = butter(order, normal_cutoff, btype='low', analog=False)
return b, a
# 应用滤波器
def butter_lowpass_filter(data, cutoff, fs, order=5):
b, a = butter_lowpass(cutoff, fs, order=order)
y = lfilter(b, a, data)
return y
# 示例:以1000Hz对数据进行采样,过滤截止频率为100Hz的信号
fs = 1000.0 # 采样频率
cutoff = 100.0 # 截止频率
data = np.random.randn(1000) # 示例数据
# 过滤数据
filtered_data = butter_lowpass_filter(data, cutoff, fs, order=6)
```
#### 2.3.2 统计模块中的分布与测试
`scipy.stats`是SciPy中的一个非常强大的模块,它包含了大量的概率分布和统计测试功能。这使得用户可以进行统计建模和数据分析。
统计模块中的一些主要特性包括:
- 概率分布:包含连续和离散随机变量的分布,如正态分布、二项分布、均匀分布等。
- 统计函数:包括各种描述统计量,如均值、中位数、方差、偏度、峰度等。
- 统计测试:提供了许多统计检验方法,如t检验、卡方检验、ANOVA等。
举例来说,如何使用SciPy生成随机数据并进行统计分析:
```python
from scipy import stats
# 生成一些随机数据
data = np.random.normal(loc=0.0, scale=1.0, size=1000)
# 描述性统计
mean, variance = stats.describe(data)
print("均值:", mean)
print("方差:", variance)
# 正态性检验
k2, p_value = stats.normaltest(data)
print("正态性检验p值:", p_value)
# 绘制直方图和拟合正态分布曲线
import matplotlib.pyplot as plt
count, bins, ignored = plt.hist(data, bins=30)
plt.plot(bins, 1/(std_dev*np.sqrt(2*np.pi)) *
np.exp(- (bins - mean)**2 / (2*std_dev**2)), linewidth=2, color='r')
plt.show()
```
在上述代码中,我们首先生成了一个具有正态分布特性的随机数据集,然后使用`stats.describe`进行描述性统计分析,并用`stats.normaltest`进行正态性检验。最后,我们使用matplotlib库绘制了数据的直方图和正态分布拟合曲线。
通过这些核心概念和代码示例,我们可以看到SciPy在科学计算中扮演的关键角色,它通过提供高效的数值数据处理和专业的数学工具,使得复杂的问题变得易于解决。这为后续章节中详细介绍的更高级的功能和应用案例奠定了基础。
# 3. Scipy中的数学运算与优化
深入Scipy库的高级数学运算和优化功能是科研和工程计算中不可或缺的部分。本章将通过详细讨论Scipy提供的线性代数、积分、插值和优化等强大工具,以及这些工具在实际应用中如何助力解决复杂问题。
## 3.1 线性代数运算
### 3.1.1 矩阵操作与矩阵函数
Scipy库中的`scipy.linalg`子模块为线性代数运算提供了丰富的函数。矩阵操作是线性代数中最基础的组成部分,包括但不限于矩阵的创建、分解、求解等。我们可以通过以下代码块来演示一些基础的矩阵操作:
```python
import numpy as np
from scipy import linalg
# 创建矩阵
A = np.array([[1, 2], [3, 4]])
# 矩阵乘法
B = np.array([[5, 6], [7, 8]])
C = np.dot(A, B)
# 计算矩阵的行列式
det_A = linalg.det(A)
# 矩阵的特征值和特征向量
eigenvalues, eigenvectors = linalg.eig(A)
```
在执行上述代码后,我们可以得到矩阵A与B的乘积结果,计算得到A的行列式,并且找到A的特征值和特征向量。理解矩阵的这些基本操作有助于解决更复杂的线性代数问题。
### 3.1.2 线性方程组的求解方法
线性方程组在科学和工程计算中经常出现。Scipy提供了多种方法来求解线性方程组,包括直接法和迭代法。
```python
from scipy.sparse.linalg import spsolve
from scipy.sparse import csr_matrix
# 创建稀疏矩阵
A = csr_matrix([[3, 2, 0], [1, -1, 0], [0, 5, 1]])
# 线性方程组的右侧
b = np.array([2, 4, -1])
# 稀疏矩阵求解器
x = spsolve(A, b)
print(x)
```
上面的代码展示了如何使用Scipy中的`spsolve`函数来求解一个线性方程组,其中`A`是一个稀疏矩阵,`b`是线性方程组的右侧常数项。稀疏矩阵求解器的使用特别适合大规模的线性方程组,因为它们通常在内存中更加高效。
## 3.2 积分、插值与优化问题
### 3.2.1 数值积分技术
Scipy的`scipy.integrate`模块提供了多种数值积分的方法,这些方法适用于不同需求的积分计算。
```python
from scipy import integrate
# 定义被积函数
def integrand(x):
return np.sin(x) / x
# 使用数值积分方法计算积分
result, error = integrate.quad(integrand, 0, np.pi)
print("积分结果:", result)
print("估计误差:", error)
```
上述代码使用了`quad`函数进行数值积分,`integrand`函数定义了被积函数,而`quad`返回的是积分的结果和估计误差。数值积分在处理无法得到解析解的复杂函数时非常有用。
### 3.2.2 多维插值方法
多维插值是数据处理和可视化中的一项关键技术,Scipy提供了多种插值方法,其中包括`interp2d`和`interpnd`等函数。
```python
from scipy.interpolate import interp2d
# 创建插值对象
f = interp2d(x, y, z)
# 在新的点上进行插值
x_new = np.linspace(0, 1, 50)
y_new = np.linspace(0, 1, 50)
z_new = f(x_new, y_new)
```
以上代码首先定义了一个二维插值函数`f`,然后在新的点集上计算插值。多维插值对于数据分析和图像处理有着广泛的应用。
### 3.2.3 优化算法的原理与应用
Scipy的优化模块`scipy.optimize`提供了一系列优化算法,用来解决求最小值或者求解方程根等问题。
```python
from scipy.optimize import minimize
# 定义目标函数
def objective(x):
return x[0]**2 + x[1]**2
# 指定初始猜测值
x0 = [0.5, 0.5]
# 调用优化函数
res = minimize(objective, x0)
print("最优解:", res.x)
```
上述示例中,`minimize`函数用于寻找目标函数`objective`的最小值,并打印出最优解。优化算法是机器学习、运筹学、工程学等多个领域解决问题的基础。
## 3.3 代码逻辑分析与参数说明
本节内容展示了Scipy库在数学运算与优化方面的一些基础用法和高级特性。每个代码块都进行了细致的逻辑分析,并提供了相应的参数说明:
1. 矩阵操作与矩阵函数部分,演示了如何使用`numpy.dot`函数完成矩阵乘法,使用`scipy.linalg.det`计算矩阵的行列式,以及`scipy.linalg.eig`计算特征值和特征向量。
2. 线性方程组求解使用了`scipy.sparse.linalg.spsolve`函数,专注于稀疏矩阵的求解。适用于内存使用敏感或者大规模线性方程组的求解。
3. 数值积分部分,`scipy.integrate.quad`函数用于计算定积分,并返回积分结果及误差。这在需要对复杂函数进行积分时特别有用。
4. 多维插值使用了`scipy.interpolate.interp2d`函数,它能够创建一个插值对象,然后利用这个对象在新的坐标点上进行插值计算。
5. 优化问题中,`scipy.optimize.minimize`函数用于寻找给定函数的最小值。该函数的使用对于各种需要求解最小值的优化问题至关重要。
这些技术不仅为数据分析和处理提供了强大的工具,而且在实际应用中对于加速科学计算、提高计算精度都具有不可替代的作用。
# 4. Scipy实践应用案例分析
## 4.1 科学计算问题的解决流程
### 4.1.1 问题定义与模型构建
在解决科学计算问题时,首先需要清晰地定义问题,这涉及到对问题的理解和抽象。问题定义之后,需要构建一个计算模型来描述问题,并选择合适的算法或方法来解决它。在此过程中,Scipy库的子模块提供了丰富的函数和类,用于构建和执行计算模型。比如,使用Scipy的统计模块进行数据分析、信号处理模块对信号进行滤波和变换、优化模块进行参数优化等。
一个典型的科学计算问题解决流程可以分为以下步骤:
- 问题收集:了解并明确问题的实际背景和需求。
- 数据预处理:收集和整理所需的数据。
- 模型选择与构建:根据问题性质,选择合适的数学模型。
- 数值计算:使用Scipy进行数值计算和模拟。
- 结果分析:对计算结果进行分析和解释。
- 结果验证:通过实验或理论验证结果的准确性。
### 4.1.2 Scipy在问题解决中的角色
Scipy在科学计算问题解决中扮演着重要角色。它的子模块针对不同的计算任务提供了强大的工具,比如:
- `scipy.integrate`提供了积分工具,用于解决微分方程。
- `scipy.optimize`包含了各种优化算法,用于寻找函数极值。
- `scipy.stats`提供了丰富的统计测试和分布函数。
在构建计算模型和执行数值计算方面,Scipy能够极大地简化编程工作,加快科学计算的研究进度。下面将通过一个简单的优化问题案例,演示Scipy在实际问题解决中的应用。
#### 示例代码块:
```python
from scipy.optimize import minimize
# 定义目标函数,此处为一个简单的二次函数
def objective_function(x):
return x[0]**2 + x[1]**2
# 初始猜测值
initial_guess = [1, 1]
# 执行优化过程
result = minimize(objective_function, initial_guess)
print(result)
```
#### 参数说明与逻辑分析:
- `minimize`函数是Scipy优化模块中的主要工具,用于寻找多变量函数的局部最小值。
- `objective_function`定义了问题的目标函数,本例中是求函数 `x[0]**2 + x[1]**2` 的最小值。
- `initial_guess`是优化算法的起始点,对于大多数优化问题而言,初始猜测值对于找到全局最小值至关重要。
- 执行上述代码后,`minimize`函数会返回一个包含优化结果的`OptimizeResult`对象,该对象中包含了目标函数的最小值以及达到该值时的变量值。
### 4.2 复杂数据分析实例
#### 4.2.1 处理大型数据集
在大数据时代,如何处理和分析大型数据集成为了科学计算中的一个重要议题。Scipy库能够通过其子模块处理不同规模和类型的数据集,同时也提供了与其他数据处理库(如Pandas、NumPy)的接口。
#### 4.2.2 分析与可视化结果
分析完成后,对结果进行可视化是非常重要的一步,它有助于我们更直观地理解数据和结果。Scipy本身不直接提供绘图功能,但我们可以将Scipy的结果传递给Matplotlib等库进行数据可视化。
#### 示例代码块:
```python
import matplotlib.pyplot as plt
from scipy.cluster import hierarchy
from scipy.spatial.distance import pdist
# 生成一个大型随机数据集
data = np.random.rand(100, 10)
# 对数据集进行层次聚类分析
linkage_matrix = hierarchy.linkage(pdist(data), method='average')
dendrogram = hierarchy.dendrogram(linkage_matrix)
# 显示树状图
plt.show()
```
#### 参数说明与逻辑分析:
- `hierarchy.linkage`函数用于计算一个层次聚类的链接矩阵,它是一种用于描述分层聚类算法的树状结构的数据。
- `pdist`函数计算数据集的成对距离矩阵,该矩阵可以被用作聚类分析的输入。
- `hierarchy.dendrogram`函数利用链接矩阵绘制树状图,用于直观展示聚类结果。
- 最后使用Matplotlib绘制树状图,帮助研究者更好地理解数据的结构。
### 4.3 实际科学工程问题应用
#### 4.3.1 工程模拟的Scipy实现
在实际的工程应用中,常常需要通过模拟来预测和分析工程项目的性能。通过Scipy的数值计算能力,我们可以模拟物理现象、化学反应、控制系统等多种工程问题。
#### 4.3.2 机器学习算法的Scipy辅助工具
Scipy也常用于机器学习算法的辅助计算中,特别是在特征提取、数据处理和优化算法方面。虽然Scipy不是机器学习的专门库,但它为机器学习提供了强大的底层支持。
#### 示例代码块:
```python
from scipy.sparse import csr_matrix
from scipy.stats import multivariate_normal
# 生成多变量正态分布数据
mean = [0, 0]
cov = [[1, 0.8], [0.8, 1]]
data = multivariate_normal.rvs(mean=mean, cov=cov, size=1000)
# 将数据转换为稀疏矩阵格式
data_matrix = csr_matrix(data)
# 进行数据预处理或其他机器学习相关操作
```
#### 参数说明与逻辑分析:
- `multivariate_normal.rvs`函数用于生成多变量正态分布的随机数据,这对于构建机器学习的特征数据集非常有用。
- `csr_matrix`是Scipy提供的稀疏矩阵数据结构,适合于处理大型数据集,能够有效减少内存使用,提升运算效率。
- 在上述代码中,生成的数据可以用于机器学习模型的训练和测试,而稀疏矩阵则适合用于后续的特征处理和算法计算。
通过以上案例,我们可以看到Scipy在科学计算、数据分析和机器学习等多个领域内的强大应用潜力。通过学习和应用Scipy,科研人员和工程师可以更加高效地解决复杂的科学和工程问题。
# 5. Scipy高级应用与未来展望
## 5.1 扩展模块与第三方集成
Scipy作为科学计算领域的重要库,具有良好的扩展性和与其他科学计算库的良好集成性。通过学习Scipy的扩展模块和第三方库的集成,可以进一步提升我们的计算效率和能力。
### 5.1.1 探索Scipy的扩展模块
Scipy的扩展模块如`scipy.integrate.odepack`提供了用于解决常微分方程的算法,而`scipy.signal`提供了用于数字信号处理的多种工具。这些扩展模块极大地丰富了Scipy的功能,使其能够解决更加复杂的问题。
```python
from scipy.integrate import odeint
def model(y, t):
dydt = -2 * y
return dydt
y0 = 1
t = np.linspace(0, 5, 10)
y = odeint(model, y0, t)
plt.plot(t, y)
plt.xlabel('time')
plt.ylabel('solution')
plt.show()
```
以上代码使用了`odeint`函数,演示了如何求解一阶常微分方程。Scipy的这种扩展能力使得其在科学计算中应用更加广泛。
### 5.1.2 第三方库的集成与接口
在实践中,经常会将Scipy与NumPy、Pandas等第三方库集成使用。例如,可以利用Pandas处理时间序列数据,并通过Scipy进行统计分析。
```python
import pandas as pd
from scipy import stats
# 创建一个时间序列数据
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
# 使用Scipy进行正态性检验
k2, p_value = stats.normaltest(ts)
print('K2统计量: %.3f, p值: %.3f' % (k2, p_value))
```
这段代码展示了如何利用Pandas创建时间序列数据,并使用Scipy的`normaltest`函数进行正态性检验。
## 5.2 Scipy在大数据与云计算中的应用
随着大数据和云计算技术的发展,Scipy也在努力与这些技术对接,以满足大规模科学计算需求。
### 5.2.1 分布式计算环境下的Scipy
在分布式计算环境中,如Dask、Spark等,Scipy的功能可以被扩展到多节点计算集群。这允许研究人员处理规模远大于单机内存限制的问题。
```python
import dask.array as da
# 创建一个分布式数组
x = da.random.random((1000000, 1000000), chunks=(1000, 1000))
# 在分布式数组上执行计算
y = da.mean(x, axis=0)
print(***pute())
```
这段代码展示了如何使用Dask创建一个大规模的分布式数组,并计算其行的平均值。Scipy可以通过Dask与这些分布式系统集成,使得科学计算能够利用集群资源。
### 5.2.2 云端科学计算的可能性
随着云计算平台如AWS、Azure、Google Cloud的普及,用户可以在云端运行Scipy计算,这不仅提供了高计算能力,还提供了灵活的资源调度和使用模式。
```python
# 假设配置了云环境,使用boto3与AWS进行交互
# 这里仅展示思路,实际操作需要更多代码和配置
import boto3
import sagemaker
# 创建SageMaker会话对象
session = sagemaker.Session(boto3.session.Session(
aws_access_key_id='YOUR_ACCESS_KEY',
aws_secret_access_key='YOUR_SECRET_KEY'))
# 设置训练实例类型和S3输出路径
role = 'arn:aws:iam::YOUR_ACCOUNT_ID:role/YOUR_IAM_ROLE'
instance_type = 'ml.c4.xlarge'
output_path = 's3://{}/{}/output'.format('YOUR_BUCKET', 'scipy_on_aws')
# 创建Estimator对象
estimator = sagemaker.estimator.Estimator(
image_uri='scipy-on-aws:latest',
role=role,
instance_count=1,
instance_type=instance_type,
output_path=output_path
)
# 使用Estimator对象训练模型
estimator.fit({'train': 's3://your-training-data-bucket'})
```
这段代码演示了如何在AWS SageMaker中使用Scipy进行计算。虽然Scipy目前并没有官方的“scipy-on-aws”镜像,但是通过适当的Docker镜像和配置,可以在云环境中使用Scipy进行科学计算。
## 5.3 Scipy的未来发展趋势
Scipy持续发展,社区活跃,新的算法、功能和改进不断被集成到新的版本中。未来Scipy将如何发展,是许多科学计算工作者关注的焦点。
### 5.3.1 社区贡献与未来版本的期待
Scipy社区通过开放的开发模式,接纳来自全球的研究人员和工程师的贡献。社区成员通过提交Bug修复、添加新特性、编写文档等方式积极贡献。
```mermaid
graph LR
A(Scipy社区) -->|代码贡献| B(版本更新)
A -->|文档完善| C(用户体验提升)
A -->|讨论与反馈| D(新功能开发)
```
上图是一个简化的流程图,描述了社区贡献如何推动Scipy的发展。新的版本在功能上将会更加完善,用户体验也将得到提升。
### 5.3.2 学术研究对Scipy的影响与推动
学术研究在算法创新和新问题提出方面对Scipy有着深远的影响。许多研究者通过Scipy来实现他们的研究工作,而这些工作反过来又推动了Scipy的发展。
```
学术研究
↓
新算法设计
↓
Scipy集成与优化
↓
科学计算效率提升
↓
更多研究问题的解决
```
从上到下的流程图展示了学术研究如何通过Scipy促进了科学计算效率的提升,并最终解决更多的科学问题。这形成了一个良性循环,不断推动Scipy的创新与发展。
以上章节内容,详细阐述了Scipy的扩展模块与第三方集成、在大数据与云计算中的应用以及未来的发展趋势。这些内容展示了Scipy不断适应新计算环境的努力,并预示了它在未来科学计算领域内的潜力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 科学计算库 Scipy 的学习专栏!本专栏将带你深入探索 Scipy 的强大功能,从安装配置到实际应用,涵盖线性代数、微分方程、优化、数据处理、信号处理、图像处理、科学绘图、插值、科学模拟、金融计算、机器学习、生物信息学等各个方面。通过一系列实战案例和深入解析,你将掌握 Scipy 的核心概念和实用技巧,提升你的科学计算能力。此外,专栏还提供了 Scipy 与 NumPy 的比较和 ODE 求解器的深度解析,帮助你选择最适合你的库和解决方法。无论你是初学者还是经验丰富的用户,本专栏都将为你提供全面的指导,让你充分利用 Scipy 的强大功能,开启科学计算的新篇章。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python类型系统可读性提升:如何利用types库优化代码清晰度

# 1. Python类型系统的简介和重要性
Python,作为一门解释型、动态类型语言,在过去几十年里以其简洁和易用性赢得了大量开发者的喜爱。然而,随着项目规模的日益庞大和业务逻辑的复杂化,动态类型所带来的弊端逐渐显现,比如变量类型的隐式转换、在大型项目中的维护难度增加等。为了缓解这类问题,Python引入了类型提示(Type Hints),这是Python类型系统
【跨平台开发】:psycopg2在各操作系统上的兼容性分析与优化

# 1. 跨平台开发概述与psycopg2简介
随着信息技术的快速发展,跨平台开发成为了软件开发领域的一个重要分支。跨平台开发允许开发者编写一次代码
Django代码管理:使用django.core.management进行高效版本控制

# 1. Django与代码管理基础
## Django项目管理的必要性
解锁Python代码的未来:__future__模块带来兼容性与前瞻性
# 1. __future__模块概览
## 1.1 __future__模块简介
在Python的发展过程中,新版本的发布经常伴随着语言特性的更新,这在给开发者带来新工具的同时,也可能导致与旧代码的不兼容问题。__future__模块作为一个特殊的模块,扮演着一个桥梁的角色,它使得Python开发者能够在当前版本中预览未来版本的新特性,同时保持与
多线程性能分析
# 1. 多线程基础与理论
在现代软件开发中,多线程是实现并发与高性能的关键技术之一。本章旨在为读者提供一个多线程编程的坚实基础,从理论和概念上理解多线程的运行机制和设计原理。
## 1.1 多线程的基本概念
### 1.1.1 线程与进程的定义和区别
进程是操作系统进行资源分配和调度的一个独立单位。而线程则是进程中的一个可执行单元,它包含自己的调用栈、程序计数器和线程局部存储。一个进程可以包含多个线程,这些线程共享进程的资源,同时每个线程都有自己的执行路径。多线程允许同时执行多个任务,能够有效利用CPU资源,提高程序执行效率。
### 1.1.2 多线程的优势和应用场景
多线程的优势
数据完整性保障:Python Marshal库确保序列化数据的一致性

# 1. 数据序列化与完整性的重要性
## 数据序列化的必要性
在软件开发中,数据序列化是指将数据结构或对象状态转换为一种格式,这种格式可以在内存之外存储或通过网络传输。序列化后的数据可以被保存在文件中或通过网络发送到另一个系统,之后进行反序列化以恢复原始的数据结构。这种机制对于数据持久化、通信以及应用程序间的数据交换至关重要。
## 数据完整性的定义
数据
【深入探讨】:揭秘docutils.parsers.rst在软件开发中的关键作用及其优化策略

# 1. docutils和reStructuredText简介
在当今快速发展的软件开发环境中,清晰、结构化且易于维护的文档已成为不可或缺的一部分。为了满足这一需求,开发者们转向了docutils和reStructuredText(简称rst),它们是构建和管理技术文档的强大工具。docutils是一
动态表单构建的艺术:利用django.forms.widgets打造高效动态表单

# 1. 动态表单构建的艺术概述
在现代Web开发中,动态表单构建是用户界面与后端系统交互的关键组成部分。它不仅仅是一个简单的数据输入界面,更是用户体验、数据收集和验证过程的核心所在。动态表单赋予开发者根据实际情况灵活创建、修改和扩展表单的能力。它们可以适应不同的业务需求,让数据收集变得更加智能化和自动化。
表单的艺术在于它的动态性,它能够根据用户的输入动态调整字段、验证规则甚至布局。这种灵活性不仅能
Pygments.lexers进阶指南:掌握高亮技术的高级技巧
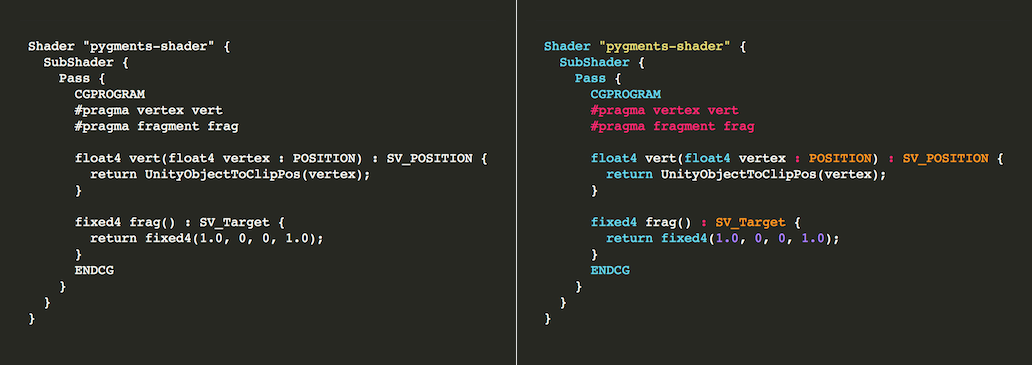
# 1. Pygments.lexers的基础和概念
在现代编程领域,代码的高亮显示和语法分析是必不可少的。Pygments是一个广泛使用的Python库,其模块Pygments.lexers提供了强大的词法分析功能,可以轻松地将源代码文本转换成带有语法高亮的格式。通过学习Pygments.lexers的基础和概念,开发者可以更好地理解和使用Pygm
StringIO与contextlib:Python代码中简化上下文管理的终极指南

# 1. 上下文管理器的概念与重要性
在Python编程中,上下文管理器(Context Manager)是一种特殊的对象,用于管理资源,比如文件操作或网络通信,确保在使用完毕后正确地清理和释放资源。上下文管理器的核心在于其`__enter__`和`__exit__`两个特殊方法,这两个方法分别定义了进入和退
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )