揭秘MongoDB数据模型设计:构建高效数据库架构
发布时间: 2024-07-16 21:31:00 阅读量: 41 订阅数: 21 

# 1. MongoDB数据模型基础**
MongoDB数据模型是一种非关系型数据模型,它基于文档结构,而不是传统的表格结构。文档由键值对组成,可以包含嵌套对象和数组。这种灵活的数据模型允许存储复杂和层次化的数据,使其非常适合处理大数据和半结构化数据。
MongoDB数据模型的另一个关键特性是其模式灵活性。与关系型数据库不同,MongoDB不需要预先定义严格的模式。文档可以包含任意数量的键和值,并且可以随着时间的推移而演变。这使得MongoDB非常适合处理不断变化的数据,并且易于适应新的需求。
# 2. MongoDB数据模型设计原则
### 2.1 数据规范化与非规范化
**数据规范化**
数据规范化是一种将数据分解成多个表或集合的过程,每个表或集合只存储特定类型的数据。这有助于减少数据冗余,提高数据一致性和完整性。
**优点:**
- 减少数据冗余,节省存储空间
- 提高数据一致性,避免数据更新冲突
- 优化查询性能,通过索引快速定位数据
**缺点:**
- 增加表或集合的数量,导致数据访问更加复杂
- 可能导致性能开销,因为需要在表或集合之间进行连接
**数据非规范化**
数据非规范化是一种将相关数据存储在同一个表或集合中的过程。这有助于提高查询性能,简化数据访问。
**优点:**
- 提高查询性能,通过减少表或集合之间的连接
- 简化数据访问,通过将相关数据存储在一起
- 减少数据冗余,避免数据更新冲突
**缺点:**
- 增加数据冗余,浪费存储空间
- 降低数据一致性,增加数据更新冲突的风险
- 降低可扩展性,难以添加或删除数据字段
**选择原则:**
选择数据规范化还是非规范化取决于应用程序的特定需求。一般来说,如果数据更新频繁,数据一致性至关重要,则选择数据规范化。如果查询性能至关重要,数据访问需要简化,则选择数据非规范化。
### 2.2 嵌入式文档与引用文档
**嵌入式文档**
嵌入式文档将相关数据存储在同一个文档中。这有助于简化数据访问,提高查询性能。
**优点:**
- 简化数据访问,通过将相关数据存储在一起
- 提高查询性能,通过减少表或集合之间的连接
- 减少数据冗余,避免数据更新冲突
**缺点:**
- 降低可扩展性,难以添加或删除数据字段
- 增加文档大小,影响查询性能
- 难以维护数据一致性,因为更新嵌套文档需要更新整个文档
**引用文档**
引用文档将相关数据存储在不同的文档中,并使用引用字段建立关系。这有助于提高可扩展性,简化数据维护。
**优点:**
- 提高可扩展性,易于添加或删除数据字段
- 简化数据维护,通过更新引用字段即可更新相关文档
- 提高查询性能,通过索引快速定位相关文档
**缺点:**
- 增加表或集合的数量,导致数据访问更加复杂
- 降低查询性能,因为需要在文档之间进行连接
- 可能导致数据冗余,因为相关数据存储在不同的文档中
**选择原则:**
选择嵌入式文档还是引用文档取决于应用程序的特定需求。一般来说,如果数据更新频繁,数据一致性至关重要,则选择嵌入式文档。如果可扩展性至关重要,数据维护需要简化,则选择引用文档。
### 2.3 索引设计与优化
**索引**
索引是一种数据结构,用于快速查找和检索数据。它通过在数据字段上创建排序列表来实现,从而减少查询时间。
**索引类型:**
- **单字段索引:**在单个字段上创建索引
- **复合索引:**在多个字段上创建索引
- **唯一索引:**确保字段值唯一
- **全文索引:**支持对文本字段进行全文搜索
**索引优化:**
- **选择合适的索引类型:**根据查询模式选择最合适的索引类型
- **创建复合索引:**对于经常一起查询的字段创建复合索引
- **使用唯一索引:**对于需要确保唯一性的字段创建唯一索引
- **删除未使用的索引:**定期删除不再使用的索引,以减少数据库开销
- **监控索引使用情况:**使用数据库工具监控索引的使用情况,并根据需要进行调整
**索引选择原则:**
选择索引时,需要考虑以下因素:
- **查询模式:**分析应用程序的查询模式,确定需要索引的字段
- **数据大小:**索引会占用存储空间,因此需要考虑数据大小
- **查询频率:**索引对经常查询的字段更有用
- **更新频率:**频繁更新的字段不适合创建索引,因为索引需要不断更新
# 3. MongoDB数据模型实践
### 3.1 用户数据模型设计
MongoDB的用户数据模型通常包含以下字段:
- **_id**:唯一标识符,可以是ObjectId或其他唯一值。
- **username**:用户名,用于登录。
- **password**:密码,通常以哈希形式存储。
- **email**:电子邮件地址,用于验证和找回密码。
- **role**:用户角色,用于权限控制。
- **profile**:嵌入式文档,包含用户个人信息,如姓名、地址和电话号码。
**代码块:**
```javascript
{
_id: new ObjectId(),
username: "admin",
password: "$2a$10$jZ0l3Q5aE8.X14579e06.e04H50n38x07s2m10l8J/fX",
email: "admin@example.com",
role: "admin",
profile: {
name: "John Doe",
address: "123 Main Street",
phone: "555-123-4567"
}
}
```
**逻辑分析:**
此文档定义了一个具有管理员角色的用户的用户数据模型。密码使用bcrypt哈希算法加密。profile字段是一个嵌入式文档,包含用户的个人信息。
### 3.2 订单数据模型设计
订单数据模型通常包含以下字段:
- **_id**:唯一标识符,可以是ObjectId或其他唯一值。
- **user_id**:下订单的用户ID。
- **product_id**:订购产品的ID。
- **quantity**:订购产品的数量。
- **price**:产品的单价。
- **total_price**:订单的总价。
- **status**:订单的状态,如“已下订单”、“已发货”、“已完成”。
**代码块:**
```javascript
{
_id: new ObjectId(),
user_id: "5e480c63c78a8132c0054b46",
product_id: "5e480c63c78a8132c0054b47",
quantity: 2,
price: 10.00,
total_price: 20.00,
status: "已下订单"
}
```
**逻辑分析:**
此文档定义了一个订单,其中包含用户ID、产品ID、订购数量、单价、总价和订单状态。
### 3.3 产品数据模型设计
产品数据模型通常包含以下字段:
- **_id**:唯一标识符,可以是ObjectId或其他唯一值。
- **name**:产品的名称。
- **description**:产品的描述。
- **category**:产品的类别。
- **price**:产品的价格。
- **stock**:产品的库存数量。
- **images**:产品的图片URL数组。
**代码块:**
```javascript
{
_id: new ObjectId(),
name: "iPhone 13 Pro",
description: "The latest iPhone with a powerful camera and long battery life.",
category: "Smartphones",
price: 999.00,
stock: 50,
images: ["https://example.com/iphone-13-pro-1.jpg", "https://example.com/iphone-13-pro-2.jpg"]
}
```
**逻辑分析:**
此文档定义了一个产品的模型,其中包含产品名称、描述、类别、价格、库存数量和图片URL数组。
# 4. MongoDB数据模型进阶
### 4.1 分片与副本集
#### 分片
分片是一种将大型数据集水平划分为多个较小部分的技术,每个部分称为分片。分片可以提高查询性能,因为查询仅针对相关分片执行,从而减少了需要扫描的数据量。
**分片过程:**
1. 将数据集划分为多个分片,每个分片包含数据集的一部分。
2. 将分片存储在不同的服务器上。
3. 使用分片键对数据进行分片,分片键是一个或多个字段,用于确定数据属于哪个分片。
**优点:**
* 提高查询性能
* 可扩展性:可以轻松地添加或删除分片以适应数据增长
* 高可用性:如果一个分片出现故障,其他分片仍然可用
**缺点:**
* 增加复杂性:需要管理多个分片和分片键
* 可能导致数据不一致性:如果分片之间的数据不一致,可能会导致查询结果不准确
#### 副本集
副本集是一组副本,其中每个副本都存储数据集的完整副本。副本集提供了数据冗余和高可用性,如果一个副本出现故障,其他副本仍然可用。
**副本集过程:**
1. 创建一个副本集,其中包含多个副本。
2. 将数据集复制到所有副本。
3. 指定一个副本为主副本,其他副本为次副本。
**优点:**
* 数据冗余:如果一个副本出现故障,其他副本仍然可用
* 高可用性:查询可以从任何副本执行,从而提高可用性
* 读扩展性:可以添加次副本以处理增加的读取负载
**缺点:**
* 增加存储成本:需要存储数据集的多个副本
* 增加写入延迟:写入操作需要复制到所有副本,这可能会导致写入延迟
### 4.2 数据加密与权限控制
#### 数据加密
数据加密是一种保护数据免遭未经授权访问的技术。MongoDB支持多种加密方法,包括:
* **客户端加密:**在客户端应用程序中加密数据,然后将其存储在MongoDB中。
* **服务器端加密:**在MongoDB服务器上加密数据。
* **透明数据加密 (TDE):**自动加密存储在MongoDB中的所有数据。
**权限控制**
权限控制是一种限制对MongoDB数据的访问的技术。MongoDB支持基于角色的访问控制 (RBAC),允许您创建角色并向用户分配这些角色。角色可以授予对特定数据库、集合或文档的读、写或管理权限。
### 4.3 MongoDB聚合框架
MongoDB聚合框架是一种用于对MongoDB数据执行复杂聚合操作的框架。聚合框架允许您对数据进行分组、过滤、排序和聚合。
**聚合管道:**
聚合框架使用管道来执行聚合操作。管道是一系列阶段,每个阶段都对数据执行一个操作。
**常见阶段:**
* **$match:**过滤数据
* **$group:**对数据进行分组
* **$sort:**对数据进行排序
* **$project:**选择要返回的字段
**示例:**
```javascript
db.collection.aggregate([
{
$match: {
age: { $gt: 18 }
}
},
{
$group: {
_id: "$gender",
count: { $sum: 1 }
}
},
{
$sort: {
count: -1
}
},
{
$project: {
_id: 0,
gender: "$_id",
count: 1
}
}
]);
```
这个管道将过滤出年龄大于18岁的数据,然后根据性别对数据进行分组,计算每个组的计数,并按计数降序对结果进行排序。最后,它将结果投影到只包含性别和计数的字段。
# 5. MongoDB数据模型案例分析
### 5.1 社交网络数据模型
社交网络平台需要存储大量用户数据,包括个人资料、社交关系、帖子和消息。MongoDB的文档模型非常适合存储这种复杂的数据结构。
#### 用户数据模型
```javascript
{
_id: ObjectId(),
username: "johndoe",
email: "johndoe@example.com",
password: "hashed_password",
profile: {
name: "John Doe",
location: "New York, NY",
bio: "Software Engineer"
},
friends: [
ObjectId("5e4283491c9d660001c00001"),
ObjectId("5e4283491c9d660001c00002")
]
}
```
#### 社交关系数据模型
```javascript
{
_id: ObjectId(),
user_id: ObjectId("5e4283491c9d660001c00001"),
friend_id: ObjectId("5e4283491c9d660001c00002"),
status: "accepted"
}
```
#### 帖子数据模型
```javascript
{
_id: ObjectId(),
user_id: ObjectId("5e4283491c9d660001c00001"),
content: "Hello world!",
likes: [
ObjectId("5e4283491c9d660001c00003"),
ObjectId("5e4283491c9d660001c00004")
],
comments: [
{
_id: ObjectId(),
user_id: ObjectId("5e4283491c9d660001c00005"),
content: "Great post!"
}
]
}
```
#### 消息数据模型
```javascript
{
_id: ObjectId(),
sender_id: ObjectId("5e4283491c9d660001c00001"),
receiver_id: ObjectId("5e4283491c9d660001c00002"),
content: "Hey, how are you?",
read: false
}
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏是 MongoDB 数据库入门到精通的综合指南。从基础概念到高级技术,它涵盖了广泛的主题,包括数据模型设计、查询优化、索引策略、事务管理、聚合管道、复制、高可用性、分片、备份、性能调优、运维监控、数据迁移、与其他数据库的对比、云环境中的应用以及数据建模技巧。通过深入的讲解和实际案例分析,本专栏旨在帮助读者掌握 MongoDB 的核心概念和最佳实践,从而构建高效、可扩展且可靠的数据库解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
R语言数据包安全使用指南:规避潜在风险的策略
# 1. R语言数据包基础知识
在R语言的世界里,数据包是构成整个生态系统的基本单元。它们为用户提供了一系列功能强大的工具和函数,用以执行统计分析、数据可视化、机器学习等复杂任务。理解数据包的基础知识是每个数据科学家和分析师的重要起点。本章旨在简明扼要地介绍R语言数据包的核心概念和基础知识,为
【数据挖掘应用案例】:alabama包在挖掘中的关键角色

# 1. 数据挖掘简介与alabama包概述
## 1.1 数据挖掘的定义和重要性
数据挖掘是一个从大量数据中提取或“挖掘”知识的过程。它使用统计、模式识别、机器学习和逻辑编程等技术,以发现数据中的有意义的信息和模式。在当今信息丰富的世界中,数据挖掘已成为各种业务决策的关键支撑技术。有效地挖掘数据可以帮助企业发现未知的关系,预测未来趋势,优化
模型验证的艺术:使用R语言SolveLP包进行模型评估
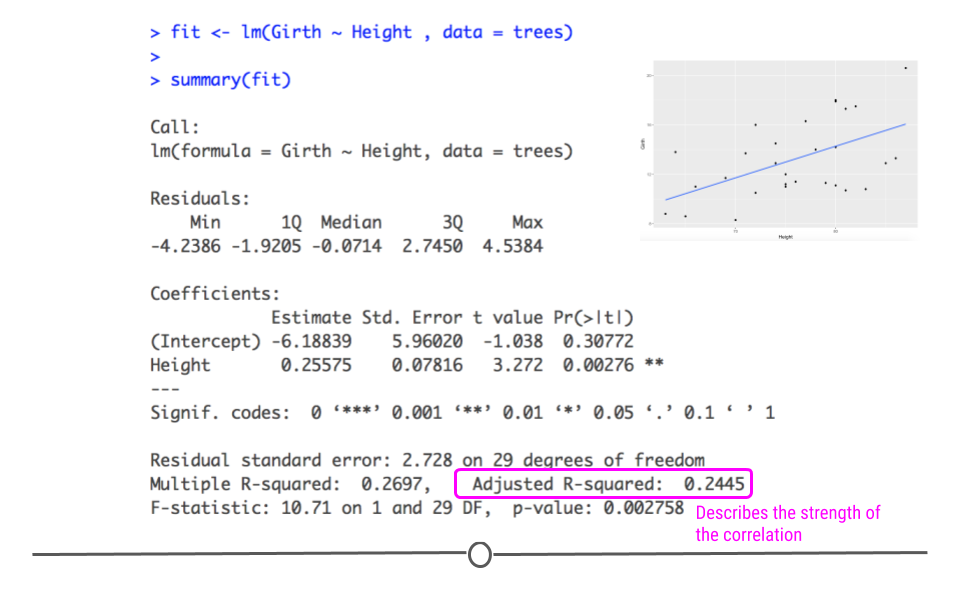
# 1. 线性规划与模型验证简介
## 1.1 线性规划的定义和重要性
线性规划是一种数学方法,用于在一系列线性不等式约束条件下,找到线性目标函数的最大值或最小值。它在资源分配、生产调度、物流和投资组合优化等众多领域中发挥着关键作用。
```mermaid
flowchart LR
A[问题定义] --> B[建立目标函数]
B --> C[确定约束条件]
C --> D[
R语言数据包多语言集成指南:与其他编程语言的数据交互(语言桥)

# 1. R语言数据包的基本概念与集成需求
## R语言数据包简介
R语言作为统计分析领域的佼佼者,其数据包(也称作包或库)是其强大功能的核心所在。每个数据包包含特定的函数集合、数据集、编译代码等,专门用于解决特定问题。在进行数据分析工作之前,了解如何选择合适的数据包,并集成到R的
质量控制中的Rsolnp应用:流程分析与改进的策略

# 1. 质量控制的基本概念
## 1.1 质量控制的定义与重要性
质量控制(Quality Control, QC)是确保产品或服务质量
R语言与SQL数据库交互秘籍:数据查询与分析的高级技巧
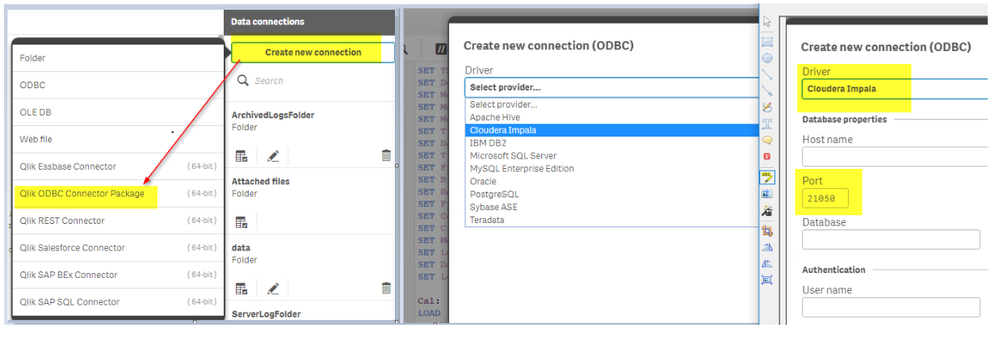
# 1. R语言与SQL数据库交互概述
在数据分析和数据科学领域,R语言与SQL数据库的交互是获取、处理和分析数据的重要环节。R语言擅长于统计分析、图形表示和数据处理,而SQL数据库则擅长存储和快速检索大量结构化数据。本章将概览R语言与SQL数据库交互的基础知识和应用场景,为读者搭建理解后续章节的框架。
## 1.
【R语言地理信息数据分析】:chinesemisc包的高级应用与技巧
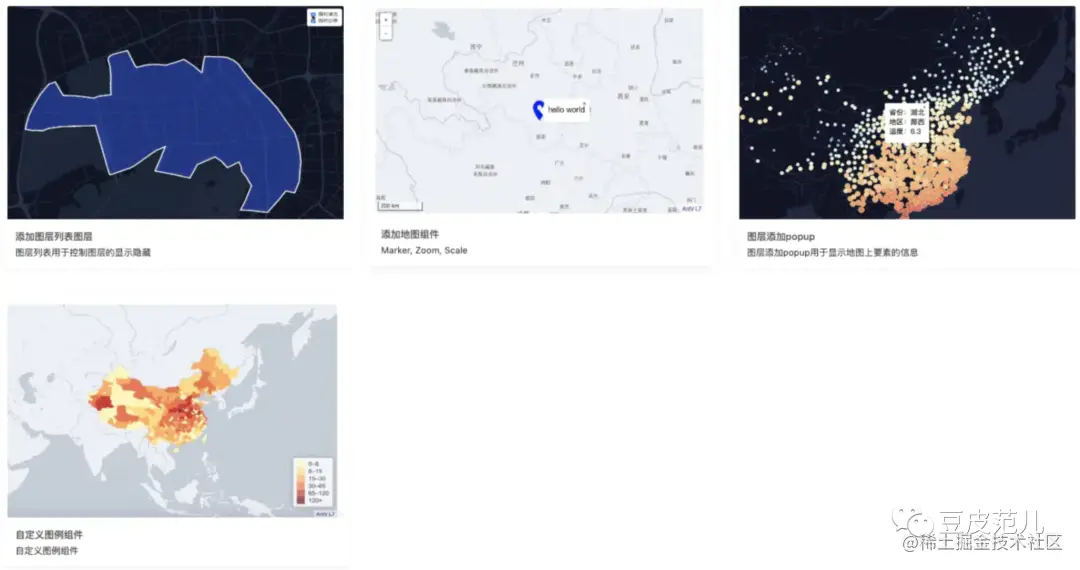
# 1. R语言与地理信息数据分析概述
R语言作为一种功能强大的编程语言和开源软件,非常适合于统计分析、数据挖掘、可视化以及地理信息数据的处理。它集成了众多的统计包和图形工具,为用户提供了一个灵活的工作环境以进行数据分析。地理信息数据分析是一个特定领域
【R语言Tau包高级技巧】:提升文本挖掘与金融数据分析的效率
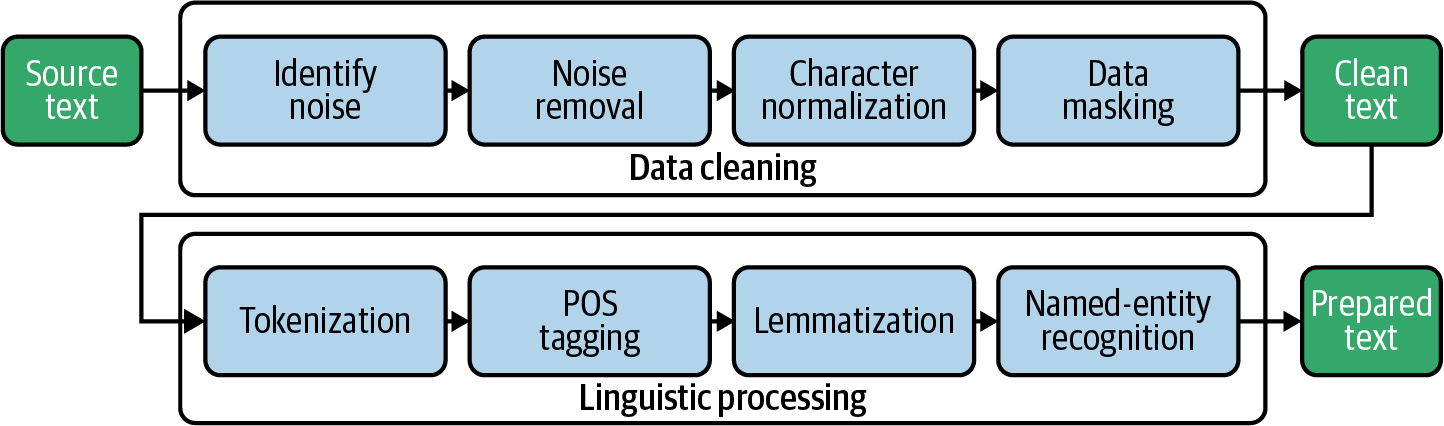
# 1. Tau包简介与安装配置
## Tau包简介
Tau包是一个功能强大的文本分析工具包,专为R语言设计,它提供了丰富的文本挖掘和自然语言处理功能。Tau包集成了多个预处理、分析和建模的工具,使得从文本中提取信息和洞察变得更加简单高效。
## 安装Tau包
Tau包的安装非常简单,您可以通
动态规划的R语言实现:solnp包的实用指南
# 1. 动态规划简介
## 1.1 动态规划的历史和概念
动态规划(Dynamic Programming,简称DP)是一种数学规划方法,由美国数学家理查德·贝尔曼(Richard Bellman)于20世纪50年代初提出。它用于求解多阶段决策过程问题,将复杂问题分解为一系列简单的子问题,通过解决子问题并存储其结果来避免重复计算,从而显著提高算法效率。DP适用于具有重叠子问题和最优子
【nlminb项目应用实战】:案例研究与最佳实践分享
# 1. nlminb项目概述
## 项目背景与目的
在当今高速发展的IT行业,如何优化性能、减少资源消耗并提高系统稳定性是每个项目都需要考虑的问题。nlminb项目应运而生,旨在开发一个高效的优化工具,以解决大规模非线性优化问题。项目的核心目的包括:
- 提供一个通用的非线性优化平台,支持多种算法以适应不同的应用场景。
- 为开发者提供一个易于扩展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )