Python数据写入Excel:深度解析pandas和openpyxl库,提升效率
发布时间: 2024-06-23 23:42:52 阅读量: 184 订阅数: 48 

java计算器源码.zip

# 1. Python数据写入Excel概述**
Python提供了一系列强大的库,用于将数据写入Excel文件中。其中,pandas和openpyxl是两个最受欢迎的库。本章将概述使用Python将数据写入Excel的流程,并介绍pandas和openpyxl库的基本功能。
pandas是一个用于数据处理和分析的库。它提供了DataFrame和Series等数据结构,用于存储和操作表格数据。pandas还提供了各种数据处理和分析功能,如数据清洗、转换、聚合和可视化。
openpyxl是一个用于操作Excel文件的库。它允许您创建、打开和修改工作簿和工作表。openpyxl还提供了数据写入和读取功能,使您可以轻松地将数据导入和导出到Excel文件中。
# 2. pandas库:数据处理与分析**
**2.1 pandas数据结构与操作**
**2.1.1 DataFrame和Series**
pandas库提供了两种主要的数据结构:DataFrame和Series。DataFrame是一个二维表状结构,类似于Excel工作表,由行和列组成。Series则是一维数组,类似于Excel中的单列。
**2.1.2 数据读取和写入**
pandas提供了便捷的方法来读取和写入各种数据源,包括CSV、Excel、SQL数据库等。
```python
# 从CSV文件读取数据
df = pd.read_csv('data.csv')
# 将DataFrame写入Excel文件
df.to_excel('data.xlsx')
```
**2.2 pandas数据处理与分析**
**2.2.1 数据清洗与转换**
pandas提供了丰富的函数和方法来清洗和转换数据,包括删除重复项、处理缺失值、转换数据类型等。
```python
# 删除重复项
df.drop_duplicates(inplace=True)
# 处理缺失值
df.fillna(0, inplace=True)
# 转换数据类型
df['column_name'] = df['column_name'].astype(int)
```
**2.2.2 数据聚合与分组**
pandas支持对数据进行聚合和分组操作,如求和、求平均值、按列分组等。
```python
# 求和
df['total_sales'] = df['sales'].sum()
# 求平均值
df['avg_sales'] = df['sales'].mean()
# 按列分组
grouped_df = df.groupby('product_category')
```
**2.2.3 数据可视化**
pandas提供了便捷的绘图函数,可以快速生成各种类型的图表,如折线图、柱状图、散点图等。
```python
# 生成折线图
df.plot(x='date', y='sales')
# 生成柱状图
df['product_category'].value_counts().plot(kind='bar')
# 生成散点图
df.plot(x='x_value', y='y_value', kind='scatter')
```
# 3. openpyxl库:Excel文件操作
### 3.1 openpyxl工作簿与工作表
#### 3.1.1 创建和打开工作簿
```python
import openpyxl
# 创建一个新的工作簿
wb = openpyxl.Workbook()
# 打开一个现有的工作簿
wb = openpyxl.load_workbook('workbook.xlsx')
```
**参数说明:**
* `Workbook()`:创建新的工作簿。
* `load_workbook(filename)`:打开指定文件名的工作簿。
#### 3.1.2 工作表操作与管理
```python
# 获取工作簿中的工作表
ws = wb.active
ws = wb.get_sheet_by_name('Sheet1')
# 创建一个新的工作表
ws = wb.create_sheet('NewSheet')
# 删除一个工作表
wb.remove(ws)
```
**参数说明:**
* `active`:获取当前激活的工作表。
* `get_sheet_by_name(name)`:根据名称获取工作表。
* `create_sheet(name)`:创建新的工作表。
* `remove(worksheet)`:删除工作表。
### 3.2 openpyxl数据写入与读取
#### 3.2.1 数据写入工作表
```python
# 在单元格中写入值
ws['A1'] = 'Hello World'
# 写入多个值
ws['A2:C4'] = [['Name', 'Age', 'Gender'], ['John', 25, 'Male'], ['Jane', 30, 'Female'], ['Tom', 35, 'Male']]
# 写入公式
ws['D1'] = '=SUM(A1:C1)'
```
**参数说明:**
* `'A1'`:单元格地址。
* `[['Name', 'Age', 'Gender'], ['John', 25, 'Male'], ['Jane', 30, 'Female'], ['Tom', 35, 'Male']]`:写入多个值的列表。
* `'=SUM(A1:C1)'`:公式字符串。
#### 3.2.2 数据读取与提取
```python
# 读取单元格值
value = ws['A1'].value
# 读取多个单元格值
values = ws['A2:C4'].values
# 读取公式结果
value = ws['D1'].value
```
**参数说明:**
* `value`:单元格值。
* `values`:多个单元格值的列表。
# 4. pandas与openpyxl联合应用
### 4.1 pandas数据写入openpyxl工作表
#### 4.1.1 DataFrame写入工作表
```python
import pandas as pd
from openpyxl import Workbook
# 创建一个DataFrame
df = pd.DataFrame({
'Name': ['John', 'Mary', 'Bob'],
'Age': [20, 25, 30],
'City': ['New York', 'London', 'Paris']
})
# 创建一个工作簿
wb = Workbook()
# 获取第一个工作表
ws = wb.active
# 将DataFrame写入工作表
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)
```
**代码逻辑分析:**
* 首先,我们导入必要的库。
* 然后,我们创建一个包含姓名、年龄和城市信息的DataFrame。
* 接下来,我们创建一个工作簿并获取第一个工作表。
* 最后,我们使用`to_excel()`方法将DataFrame写入工作表,指定工作表名称和是否包含索引。
#### 4.1.2 数据格式化与样式设置
```python
import pandas as pd
from openpyxl import Workbook, styles
# 创建一个DataFrame
df = pd.DataFrame({
'Name': ['John', 'Mary', 'Bob'],
'Age': [20, 25, 30],
'City': ['New York', 'London', 'Paris']
})
# 创建一个工作簿
wb = Workbook()
# 获取第一个工作表
ws = wb.active
# 将DataFrame写入工作表
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)
# 设置单元格格式
for row in range(2, df.shape[0] + 2):
for col in range(1, df.shape[1] + 1):
ws.cell(row, col).number_format = '0.00'
# 设置标题样式
title_font = styles.Font(bold=True, size=14)
title_style = styles.Alignment(horizontal='center')
for row in range(1, 2):
for col in range(1, df.shape[1] + 1):
ws.cell(row, col).font = title_font
ws.cell(row, col).alignment = title_style
```
**代码逻辑分析:**
* 在前面的代码基础上,我们增加了数据格式化和样式设置。
* 首先,我们遍历DataFrame中的所有单元格,并设置其数字格式为两位小数。
* 然后,我们设置标题行的字体为加粗,大小为14,并居中对齐。
### 4.2 openpyxl数据读取到pandas DataFrame
#### 4.2.1 工作表数据读取
```python
import pandas as pd
from openpyxl import load_workbook
# 加载工作簿
wb = load_workbook('output.xlsx')
# 获取第一个工作表
ws = wb.active
# 将工作表数据读取到DataFrame
df = pd.read_excel('output.xlsx', sheet_name='Sheet1')
```
**代码逻辑分析:**
* 首先,我们导入必要的库。
* 然后,我们加载工作簿并获取第一个工作表。
* 最后,我们使用`read_excel()`方法将工作表数据读取到DataFrame。
#### 4.2.2 数据处理与分析
```python
import pandas as pd
from openpyxl import load_workbook
# 加载工作簿
wb = load_workbook('output.xlsx')
# 获取第一个工作表
ws = wb.active
# 将工作表数据读取到DataFrame
df = pd.read_excel('output.xlsx', sheet_name='Sheet1')
# 数据处理与分析
df['Age'] = df['Age'] + 1 # 增加年龄
df['City'] = df['City'].str.upper() # 将城市名称转换为大写
```
**代码逻辑分析:**
* 在前面的代码基础上,我们增加了数据处理与分析。
* 首先,我们增加DataFrame中年龄列的值。
* 然后,我们将城市名称列的值转换为大写。
# 5. 数据写入Excel最佳实践**
**5.1 性能优化与效率提升**
**5.1.1 数据分块写入**
当需要写入大量数据时,将数据分块写入可以显著提高性能。pandas提供了`to_excel()`函数的`chunksize`参数,用于指定每次写入的数据块大小。通过将数据分块写入,可以避免内存溢出和提高写入速度。
```python
import pandas as pd
df = pd.DataFrame({'name': ['John', 'Jane', 'Peter'], 'age': [20, 25, 30]})
# 将数据分块写入,每次写入1000行
df.to_excel('data.xlsx', chunksize=1000)
```
**5.1.2 多线程并行写入**
对于大型数据集,可以使用多线程并行写入来进一步提高性能。pandas提供了`multithread`参数,用于指定写入时使用的线程数。通过并行写入,可以充分利用多核CPU的优势。
```python
import pandas as pd
from concurrent.futures import ThreadPoolExecutor
def write_chunk(df, chunksize):
df.to_excel('data.xlsx', chunksize=chunksize)
# 使用4个线程并行写入
with ThreadPoolExecutor(4) as executor:
executor.map(write_chunk, [df, df, df, df], [1000, 1000, 1000, 1000])
```
**5.2 数据完整性与安全性**
**5.2.1 数据验证与错误处理**
在写入数据之前,应进行数据验证以确保数据完整性和准确性。pandas提供了`errors`参数,用于指定在遇到错误时的处理方式。例如,可以忽略错误、引发异常或尝试修复错误。
```python
import pandas as pd
df = pd.DataFrame({'name': ['John', 'Jane', 'Peter'], 'age': [20, 25, 'invalid']})
# 忽略错误并继续写入
df.to_excel('data.xlsx', errors='ignore')
# 引发异常
df.to_excel('data.xlsx', errors='raise')
# 尝试修复错误
df.to_excel('data.xlsx', errors='coerce')
```
**5.2.2 数据加密与保护**
对于敏感数据,应考虑使用加密和保护措施来确保数据安全。openpyxl提供了`encrypt_cell`方法,用于加密特定单元格或范围。此外,还可以使用第三方库(如xlwings)对整个工作簿进行加密。
```python
import openpyxl
wb = openpyxl.Workbook()
ws = wb.active
# 加密特定单元格
ws['A1'].encrypt_cell(password='secret')
# 加密整个工作簿
wb.security = openpyxl.worksheet.protection.WorkbookProtection(password='secret')
wb.save('data.xlsx')
```
# 6. 案例实战与应用场景
### 6.1 数据分析与可视化
#### 6.1.1 数据统计与分析
```python
import pandas as pd
# 读取数据
df = pd.read_excel('data.xlsx')
# 数据统计
print(df.describe())
```
#### 6.1.2 图表与仪表盘制作
```python
import matplotlib.pyplot as plt
import plotly.express as px
# 创建柱状图
plt.bar(df['category'], df['value'])
plt.xlabel('Category')
plt.ylabel('Value')
plt.show()
# 创建仪表盘
fig = px.bar(df, x='category', y='value', color='category')
fig.show()
```
### 6.2 数据管理与自动化
#### 6.2.1 数据提取与合并
```python
import pandas as pd
# 从多个文件提取数据
dfs = [pd.read_excel(f'data{i}.xlsx') for i in range(1, 4)]
# 合并数据
df_merged = pd.concat(dfs, ignore_index=True)
```
#### 6.2.2 定时任务与自动化流程
```python
import schedule
import pandas as pd
# 定时任务:每小时从数据库提取数据并写入 Excel
def job():
df = pd.read_sql_query('SELECT * FROM table', con)
df.to_excel('data.xlsx', index=False)
# 设置定时任务
schedule.every().hour.do(job)
# 运行定时任务
while True:
schedule.run_pending()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 Python 将数据写入 Excel 文件的各种技术和最佳实践。从新手到专家,专栏提供了一系列秘诀,帮助读者掌握 pandas 和 openpyxl 库,提升数据写入效率。此外,还介绍了优化性能的关键技巧,处理大数据量的解决方案,以及应对不同文件格式的策略。通过动态写入、自定义单元格格式和自动化流程,读者可以创建专业报告并提高工作效率。专栏还涵盖了错误处理和调试技巧,帮助读者快速解决问题,确保数据写入过程顺利无忧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WinRAR CVE-2023-38831漏洞快速修复解决方案

# 摘要
本文详细阐述了WinRAR CVE-2023-38831漏洞的技术细节、影响范围及利用原理,并探讨了系统安全防护理论,包括安全防护层次结构和防御策略。重点介绍了漏洞快速检测与响应方法,包括使用扫描工具、风险评估、优先级划分和建立应急响应流程。文章进一步提供了WinRAR漏洞快速修复的实践
【QWS数据集实战案例】:深入分析数据集在实际项目中的应用
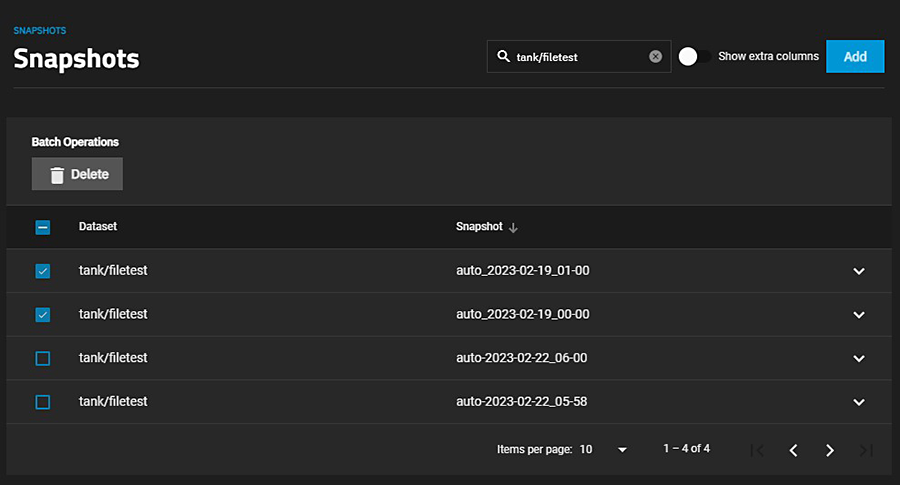
# 摘要
数据集是数据科学项目的基石,它在项目中的基础角色和重要性不可小觑。本文首先讨论了数据集的选择标准和预处理技术,包括数据清洗、标准化、特征工程等,为数据分析打下坚实基础。通过对QWS数据集进行探索性数据分析,文章深入探讨了统计分析、模式挖掘和时间序列分析,揭示了数据集内在的统计特性、关联规则以及时间依赖性。随后,本文分析了QWS数据集在金融、医疗健康和网络安全等特定领域的应用案例,展现了其在现实世界问题中
【跨平台远程管理解决方案】:源码视角下的挑战与应对
# 摘要
随着信息技术的发展,跨平台远程管理成为企业维护系统、提升效率的重要手段。本文首先介绍了跨平台远程管理的基础概念,随后探讨了在实施过程中面临的技术挑战,包括网络协议的兼容性、安全性问题及跨平台兼容性。通过实际案例分析,文章阐述了部署远程管理的前期准备、最佳实践以及性能优化和故障排查的重要性。进阶技术章节涵盖自动化运维、集群管理与基于云服务的远程管理。最后
边缘检测技术大揭秘:成像轮廓识别的科学与艺术

# 摘要
边缘检测技术是图像处理和计算机视觉领域的重要分支,对于识别图像中的物体边界、特征点以及进行场景解析至关重要。本文旨在概述边缘检测技术的理论基础,包括其数学模型和图像处理相关概念,并对各种边缘检测方法进行分类与对比。通过对Sobel算法和Canny边缘检测器等经典技术的实战技巧进行分析,探讨在实际应用中如何选择合适的边缘检测算法。同时,本文还将关注边缘检测技术的
Odroid XU4性能基准测试

# 摘要
Odroid XU4作为一款性能强大且成本效益高的单板计算机,其性能基准测试成为开发者和用户关注的焦点。本文首先对Odroid XU4硬件规格和测试环境进行详细介绍,随后深入探讨了性能基准测试的方法论和工具。通过实践测试,本文对CPU、内存与存储性能进行了全面分析,并解读了测试
TriCore工具使用手册:链接器基本概念及应用的权威指南

# 摘要
本文深入探讨了TriCore工具与链接器的原理和应用。首先介绍了链接器的基本概念、作用以及其与编译器的区别,然后详细解析了链接器的输入输出、链接脚本的基础知识,以及链接过程中的符号解析和内存布局控制。接着,本文着重于TriCore链接器的配置、优化、高级链
【硬件性能革命】:揭秘液态金属冷却技术对硬件性能的提升

# 摘要
液态金属冷却技术作为一种高效的热管理方案,近年来受到了广泛关注。本文首先介绍了液态金属冷却的基本概念及其理论基础,包括热传导和热交换原理,并分析了其与传统冷却技术相比的优势。接着,探讨了硬件性能与冷却技术之间的关系,以及液态金属冷却技术在实践应用中的设计、实现、挑战和对策。最后,本文展望了液态金属冷却技术的未来,包括新型材料的研究和技术创新的
【企业级测试解决方案】:C# Selenium自动化框架的搭建与最佳实践
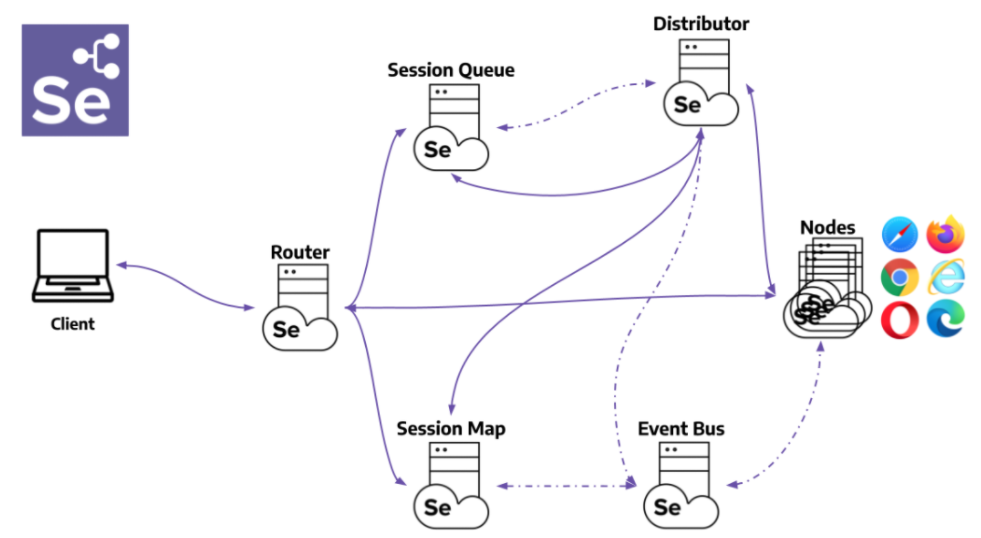
# 摘要
随着软件开发与测试需求的不断增长,企业级测试解决方案的需求也在逐步提升。本文首先概述了企业级测试解决方案的基本概念,随后深入介绍了C#与Selenium自动化测试框架的基础知识及搭建方法。第三章详细探讨了Selenium自动化测试框架的实践应用,包括测试用例设计、跨浏览器测试的实现以及测试数据的管理和参数化测试。第四章则聚焦于测试框架的进阶技术与优化,包括高级操作技巧、测试结果的分析与报告生成以及性能和负
三菱PLC-FX3U-4LC高级模块应用:详解与技巧

# 摘要
本论文全面介绍了三菱PLC-FX3U-4LC模块的技术细节与应用实践。首先概述了模块的基本组成和功能特点,接着详细解析了其硬件结构、接线技巧以及编程基础,包括端口功能、
【CAN总线通信协议】:构建高效能系统的5大关键要素

# 摘要
CAN总线作为一种高可靠性、抗干扰能力强的通信协议,在汽车、工业自动化、医疗设备等领域得到广泛应用。本文首先对CAN总线通信协议进行了概述,随后深入分析了CAN协议的理论基础,包括数据链路层与物理层的功能、CAN消息的传输机制及错误检测与处理机制。在实践应用方面,讨论了CAN网络的搭建、消息过滤策略及系统集成和实时性优化。同时,本文还探讨了CAN协议在不同行业的具体应用案例,及其在安全性和故障诊断方面的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )