Python数据写入Excel:自动化数据写入流程,解放双手,提高效率
发布时间: 2024-06-23 23:57:55 阅读量: 84 订阅数: 48 

使用Python把数据写入Excel

# 1. Excel数据写入基础**
数据写入Excel是使用Python自动化数据处理流程中常见且重要的任务。本章将介绍Excel数据写入的基础知识,为后续的Python数据写入操作奠定基础。
Excel数据写入涉及两个关键概念:工作簿和工作表。工作簿是一个包含一个或多个工作表的容器,而工作表是存储数据的网格状结构。Python可以通过第三方库(如Openpyxl和Xlsxwriter)与Excel交互,从而实现数据写入操作。这些库提供了丰富的API,允许开发者创建、打开、编辑和保存Excel工作簿和工作表。
# 2. Python数据写入Excel
### 2.1 Python与Excel的交互方式
Python提供了多种库来实现与Excel的交互,其中最常用的有:
#### 2.1.1 Openpyxl库
Openpyxl是一个开源库,支持读写Excel文件。它提供了一个类似于Excel工作簿和工作表的API,便于操作Excel文件。
```python
import openpyxl
# 创建一个新的工作簿
wb = openpyxl.Workbook()
# 创建一个新的工作表
sheet = wb.create_sheet("Sheet1")
# 写入单元格数据
sheet["A1"] = "Hello World"
# 保存工作簿
wb.save("test.xlsx")
```
**代码逻辑分析:**
* 导入openpyxl库。
* 创建一个新的工作簿。
* 创建一个新的工作表。
* 写入单元格数据。
* 保存工作簿。
#### 2.1.2 Xlsxwriter库
Xlsxwriter是一个另一个流行的Python库,用于创建和写入Excel文件。它以其快速高效而闻名。
```python
import xlsxwriter
# 创建一个新的工作簿
workbook = xlsxwriter.Workbook("test.xlsx")
# 创建一个新的工作表
worksheet = workbook.add_worksheet()
# 写入单元格数据
worksheet.write("A1", "Hello World")
# 保存工作簿
workbook.close()
```
**代码逻辑分析:**
* 导入xlsxwriter库。
* 创建一个新的工作簿。
* 创建一个新的工作表。
* 写入单元格数据。
* 保存工作簿。
### 2.2 数据写入基本操作
#### 2.2.1 创建和打开工作簿
要创建和打开一个Excel工作簿,可以使用以下代码:
```python
# 创建一个新的工作簿
wb = openpyxl.Workbook()
# 打开一个现有的工作簿
wb = openpyxl.load_workbook("test.xlsx")
```
**代码逻辑分析:**
* 创建一个新的工作簿:openpyxl.Workbook()创建一个新的工作簿对象。
* 打开一个现有的工作簿:openpyxl.load_workbook("test.xlsx")打开一个名为"test.xlsx"的现有工作簿。
#### 2.2.2 写入单元格数据
要写入单元格数据,可以使用以下代码:
```python
# 写入单元格数据
sheet["A1"] = "Hello World"
```
**代码逻辑分析:**
* sheet["A1"]:表示A1单元格。
* "Hello World":要写入单元格的值。
#### 2.2.3 保存和关闭工作簿
要保存和关闭工作簿,可以使用以下代码:
```python
# 保存工作簿
wb.save("test.xlsx")
# 关闭工作簿
wb.close()
```
**代码逻辑分析:**
* wb.save("test.xlsx"):将工作簿保存为"test.xlsx"文件。
* wb.close():关闭工作簿。
### 2.3 数据写入高级操作
#### 2.3.1 设置单元格格式
要设置单元格格式,可以使用以下代码:
```python
# 设置单元格格式
sheet["A1"].number_format = "0.00"
```
**代码逻辑分析:**
* sheet["A1"].number_format:表示A1单元格的数字格式。
* "0.00":设置单元格格式为两位小数。
#### 2.3.2 插入图表和图片
要插入图表和图片,可以使用以下代码:
```python
# 插入图表
chart = openpyxl.chart.BarChart()
sheet.add_chart(chart, "E1")
# 插入图片
img = openpyxl.drawing.image.Image("logo.png")
sheet.add_image(img, "A1")
```
**代码逻辑分析:**
* openpyxl.chart.BarChart():创建一个条形图对象。
* sheet.add_chart(chart, "E1"):将条形图添加到E1单元格。
* openpyxl.drawing.image.Image("logo.png"):创建一个图像对象。
* sheet.add_image(img, "A1"):将图像添加到A1单元格。
#### 2.3.3 使用公式和函数
要使用公式和函数,可以使用以下代码:
```python
# 使用公式
sheet["A1"] = "=SUM(B1:B10)"
# 使用函数
sheet["A1"] = "=AVERAGE(B1:B10)"
```
**代码逻辑分析:**
* "=SUM(B1:B10)":求取B1到B10单元格的和。
* "=AVERAGE(B1:B10)":求取B1到B10单元格的平均值。
# 3. 数据写入实践应用**
### 3.1 从数据库写入Excel
#### 3.1.1 连接数据库
```python
import mysql.connector
# 连接数据库
connection = mysql.connector.connect(
host="localhost",
user="root",
password="p
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 Python 将数据写入 Excel 文件的各种技术和最佳实践。从新手到专家,专栏提供了一系列秘诀,帮助读者掌握 pandas 和 openpyxl 库,提升数据写入效率。此外,还介绍了优化性能的关键技巧,处理大数据量的解决方案,以及应对不同文件格式的策略。通过动态写入、自定义单元格格式和自动化流程,读者可以创建专业报告并提高工作效率。专栏还涵盖了错误处理和调试技巧,帮助读者快速解决问题,确保数据写入过程顺利无忧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IBM Power AIX系统安装新手指南】:0基础到英雄的完美升级之路

# 摘要
本文详细介绍了IBM Power AIX系统的安装、基础管理操作以及高级管理技巧。首先概述了AIX系统的特点及安装前的准备工作,随后深入解析了系统的安装步骤和初始化配置流程。文章进一步探讨了文件系统管理、用户权限管理、进程监控等基础管理任务,并介绍了性能监控、
【H3C-CAS-Converter深度剖析】:核心组件与功能的专家解析

# 摘要
本文详细介绍了H3C-CAS-Converter的设计和功能,重点解析了其核心组件,包括架构总览、功能定位和交互关系,以及关键组件如数据转换引擎、格式解析器和数据验证模块的实现。进一步探讨了 Converter 的功能,例如支持的转换格式、高级特性、用户交互和配置管理。通过实际部署案例分析,阐述了 Converter 在数据迁移、同步备
风险管理高级应用:德勤智能地图案例深度剖析,提升风险管理效能

# 摘要
本文旨在探讨智能地图技术在企业风险管理中的应用与效能。首先,概述了风险管理的理论基础及智能地图技术的发展,然后重点分析了智能地图在风险识别、评估、应对与监控中的具体作用,结合德勤智能地图的案例,详细说明了其在理论与实践
【环境优化】Lumion 12 Pro场景环境调整与优化最佳实践
# 摘要
本文详细介绍了Lumion 12 Pro软件的基础设置与高级技巧,着重探讨了场景环境构建、渲染与动画调整、以及性能优化与系统管理等方面。通过具体操作技巧的阐述,如场景元素的导入与编辑、环境效果的精细控制、渲染质量的提升和粒子系统的优化应用,本文意在为用户提供高效创建真实感场景和动画的方法。同时,针对硬件资源分配、文件管理和稳定性提升的讨论,为Lumion使用
图像恢复技术精讲:期末复习噪声与失真处理术(噪声失真解决速成)

# 摘要
图像恢复技术是数字图像处理中的一个关键领域,它致力于从噪声和失真中恢复原始图像的清晰度和完整性。本文首先概述了图像恢复技术的基本概念,随后深入探讨了图像噪声和失真的分类、特性、以及其对图像质量的影响。紧接着,文章详细介绍了图像去噪和复原技术的原理和实践,包括空间域和频域去噪方法、图像复原的策略和高级技术。此外,本文还审视了当前常用的图像处理工具,并通过案
【Excel公式高级运用】:揭秘如何自动从身份证号码提取年龄
# 摘要
本文系统回顾了Excel公式的基础知识,并深入探讨了如何从身份证号码中提取和解读关键信息。通过详细分析身份证号码的结构及关键信息的定位方法,本文进一步介绍了提取关键信息的常用Excel函数,如LEFT、RIGHT和MID函数,以及文本与数字转换的技巧。接着,文章集中于构建基于身份证号码提取出生年份和计算年龄的公式,同时提供了逻辑实现和实例应用场
iSecure Center深度解读:掌握这5大新趋势,企业安全升级立见成效

# 摘要
随着数字化转型的加速,企业安全面临前所未有的挑战和新的技术趋势。iSecure Center作为一个全面的安全解决方案,扮演着帮助企业应对信息安全威胁、提升安
【单片机编程必备】:掌握10个关键函数,提升你的编程效率

# 摘要
单片机编程作为嵌入式系统开发的重要组成部分,对提升硬件控制能力有着举足轻重的作用。本文首先介绍了单片机编程的基础知识与关键函数的理论基础,详细探讨了函数定义、参数传递机制、返回值以及函数的分类和选择标准。随后,文章深入实践技巧部分,讨论了输入输出、定时器及中断处理函数的使用和优化。在关键函数的应用章节中,本文解释了
CRC校验故障排除手册:Modbus_RTU协议下的常见问题深度解析
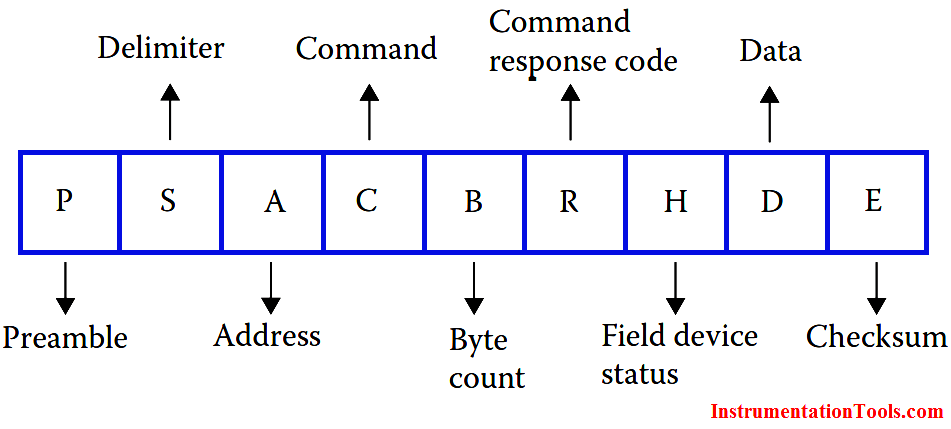
# 摘要
本文对CRC校验和Modbus_RTU协议进行了全面的介绍和分析,探讨了CRC校验的基本原理及其在Modbus_RTU协议中的应用,以确保数据传输的完整性。同时,本文详细分析了CRC校验可能出现的常见故障,并提供了故障诊断和解决的方法。此外,文章通过实践案例深入
【FPGA时序分析】:input延迟影响及输出延迟调优策略

# 摘要
本文深入探讨了FPGA时序分析的基础知识、输入输出延迟的理论与实践、以及时序分析工具与方法。通过对输入延迟的概念解析,分析了时钟域交叉与时钟偏斜对系统性能的影响,并探讨了输入延迟的测量方法及优化实例。输出延迟调优章节介绍了输出延迟的理论基础、技术手段及其在高速
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )