大数据量下的性能提升:掌握GROUP BY的有效使用技巧
发布时间: 2024-11-14 16:33:15 阅读量: 8 订阅数: 15 
# 1. GROUP BY的SQL基础和原理
## 1.1 SQL中GROUP BY的基本概念
SQL中的`GROUP BY`子句是用于结合聚合函数,按照一个或多个列对结果集进行分组的语句。基本形式是将一列或多列的值进行分组,使得在`SELECT`列表中的聚合函数能在每个组上分别计算。例如,计算每个部门的平均薪水时,`GROUP BY`可以将员工按部门进行分组。
## 1.2 GROUP BY的工作原理
当执行包含`GROUP BY`的SQL查询时,数据库管理系统(DBMS)首先会对结果集中的行进行排序,将相同的值放在一起形成一个分组。然后,对每个分组应用聚合函数,如`COUNT`, `SUM`, `AVG`, `MIN`, `MAX`等。这一过程保证了聚合函数能对每个组的行进行操作,而不是所有行作为一个整体。
## 1.3 GROUP BY的实际应用
在实际应用中,`GROUP BY`常用于生成报告和汇总信息。例如,使用`GROUP BY`和`COUNT()`函数可以快速统计出某个表中某类数据的总数。通过`GROUP BY`结合`SUM()`函数,可以计算出特定列的总和,例如查询每个部门的销售总额。这种分组聚合的能力,使得`GROUP BY`成为数据分析和报表生成不可或缺的一部分。
```sql
SELECT department_id, COUNT(*) AS num_employees, SUM(salary) AS total_salary
FROM employees
GROUP BY department_id;
```
在上述SQL示例中,我们按照`department_id`分组,统计每个部门的员工数(`num_employees`)和薪资总额(`total_salary`)。
# 2. GROUP BY在大数据量环境中的挑战
## 2.1 大数据量对GROUP BY性能的影响
### 2.1.1 数据集的规模如何影响GROUP BY操作
随着数据量的增长,数据库执行GROUP BY操作的挑战也成倍增加。这是因为GROUP BY操作在本质上要求数据库对数据进行分组和聚合计算,这本身就涉及到大量的数据处理工作。当数据集规模较小时,数据库服务器可以通过内存处理大部分数据,效率较高。但是当数据量增长到一定规模,数据无法完全加载进内存,数据库就需要频繁地进行磁盘读写操作,这将大大降低查询速度。
为更深入了解这一点,我们可以模拟一个大数据集的环境,通过实际的数据分析来观察GROUP BY操作性能的变化。在实验中,我们可以使用不同的数据集大小(例如1GB、10GB、100GB)进行GROUP BY操作,记录每次操作的时间消耗和资源占用情况。
### 2.1.2 索引在GROUP BY操作中的作用
索引作为一种数据结构,对于提升GROUP BY操作的性能至关重要。索引可以加速数据库在执行聚合操作时的查找速度,因为索引通常存储了数据的有序排列信息,能够快速定位到需要的行。在大数据量环境中,合理构建和使用索引可以大幅减少数据库扫描的行数,提高查询效率。
索引的类型和设计直接影响GROUP BY操作的性能。例如,B-tree索引适用于单列的范围查询,而哈希索引适用于快速查找和等值比较。在设计索引时,我们通常需要考虑到GROUP BY语句中的GROUP BY子句和WHERE子句,确保索引能够覆盖到这些关键字段。
## 2.2 GROUP BY性能优化的基础知识
### 2.2.1 理解执行计划和成本估算
数据库执行任何查询操作前,都会生成一个执行计划。执行计划详细描述了数据库如何访问、处理数据以响应查询。对于GROUP BY操作,执行计划将显示数据库是如何将数据分组、如何使用索引、以及执行分组操作的具体方式。
理解执行计划对于性能优化至关重要。通过分析执行计划,开发者可以发现查询中可能存在的瓶颈,例如全表扫描、不必要的数据排序等。我们可以使用数据库提供的工具,如MySQL的`EXPLAIN`命令,来查看特定SQL语句的执行计划。
成本估算则是数据库根据统计信息和算法估算出来的查询执行成本。优化的目标是减少查询的总成本。因此,通过对比不同查询语句的成本估算,我们可以找到性价比最高的查询方案。
### 2.2.2 优化查询语句的基本技巧
优化GROUP BY查询语句的基本技巧包括但不限于:
- 使用`GROUP BY`子句时,尽量减少参与分组的列,以减少分组操作的工作量。
- 如果可能,将`WHERE`子句放在`GROUP BY`之前,这样数据库就可以先过滤掉不需要处理的数据。
- 合理利用`HAVING`子句进行数据过滤,尤其是当过滤条件不能写在`WHERE`子句中时。
在实际操作中,优化不仅限于SQL语句的编写,还包括数据表的设计、索引的使用等。总之,性能优化需要全方位考虑数据库的架构和工作方式。
## 2.3 GROUP BY的高级优化技术
### 2.3.1 分区表在GROUP BY中的应用
分区表是将数据分布存储在不同的物理区域中,每个区域称为一个分区。分区表在处理大数据集时非常有用,因为它可以将大表划分为多个小表,查询时只需要扫描相关分区,而不是整个表,从而提升性能。
分区可以基于范围、列表、哈希等多种策略。在应用GROUP BY时,若数据可以按照某个逻辑进行分区(如按日期、地区等),则可以极大地提高查询效率。例如,如果一个销售数据表按照年份分区,当执行当年的销售数据聚合分析时,数据库只需要扫描当前年份的分区,而不需要处理整个表。
分区表的创建和维护有一定的复杂性,需要根据具体的业务场景和查询模式来精心设计。
### 2.3.2 使用WITH ROLLUP进行层次化分组
`WITH ROLLUP`是SQL标准的一部分,用于在结果集上提供一种层次化分组的能力。在进行多级汇总分析时,`WITH ROLLUP`可以生成额外的汇总行,从而简化了多级分组的复杂性。
例如,如果你有一个按季度和年份分组的销售数据表,使用`WITH ROLLUP`可以得到每个季度的销售总和以及年度的总和。这可以显著减少所需执行的GROUP BY语句数量,从而提高查询性能。
然而,使用`WITH ROLLUP`可能会增加结果集的复杂性,因为每一行可能表示不同级别的汇总。在设计使用`WITH ROLLUP`的查询时,需要仔细考虑如何解读额外的汇总行,并确保报告或分析逻辑可以正确处理这些汇总数据。
以下是使用`WITH ROLLUP`的SQL示例:
```sql
SELECT year, quarter, SUM(sales) AS total_sales
FROM sales_data
GROUP BY year, quarter WITH ROLLUP;
```
在该查询中,`WITH ROLLUP`将会为每个季度提供销售总和,并且还会为每个年份提供一个额外

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 中强大的分组功能,提供了一系列技巧、最佳实践和高级技术,帮助您掌握 GROUP BY 和聚合函数。从基础概念到复杂查询的优化,您将了解如何高效地分组数据、过滤结果、排序数据并处理 NULL 值。专栏还涵盖了多表连接、窗口函数、子查询和动态报告生成等高级主题。通过深入的案例分析和实用技巧,您将学会编写高效且可维护的 SQL 代码,最大限度地利用 MySQL 的分组功能,并从大量数据中提取有意义的见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
移动优先与响应式设计:中南大学课程设计的新时代趋势

# 1. 移动优先与响应式设计的兴起
随着智能手机和平板电脑的普及,移动互联网已成为人们获取信息和沟通的主要方式。移动优先(Mobile First)与响应式设计(Responsive Design)的概念应运而生,迅速成为了现代Web设计的标准。移动优先强调优先考虑移动用户的体验和需求,而响应式设计则注重网站在不同屏幕尺寸和设
Rhapsody 7.0消息队列管理:确保消息传递的高可靠性

# 1. Rhapsody 7.0消息队列的基本概念
消息队列是应用程序之间异步通信的一种机制,它允许多个进程或系统通过预先定义的消息格式,将数据或者任务加入队列,供其他进程按顺序处理。Rhapsody 7.0作为一个企业级的消息队列解决方案,提供了可靠的消息传递、消息持久化和容错能力。开发者和系统管理员依赖于Rhapsody 7.0的消息队
Java药店系统国际化与本地化:多语言支持的实现与优化
# 1. Java药店系统国际化与本地化的概念
## 1.1 概述
在开发面向全球市场的Java药店系统时,国际化(Internationalization,简称i18n)与本地化(Localization,简称l10n)是关键的技术挑战之一。国际化允许应用程序支持多种语言和区域设置,而本地化则是将应用程序具体适配到特定文化或地区的过程。理解这两个概念的区别和联系,对于创建一个既能满足
【数据分片技术】:实现在线音乐系统数据库的负载均衡
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
大数据量下的性能提升:掌握GROUP BY的有效使用技巧

# 1. GROUP BY的SQL基础和原理
## 1.1 SQL中GROUP BY的基本概念
SQL中的`GROUP BY`子句是用于结合聚合函数,按照一个或多个列对结果集进行分组的语句。基本形式是将一列或多列的值进行分组,使得在`SELECT`列表中的聚合函数能在每个组上分别计算。例如,计算每个部门的平均薪水时,`GROUP BY`可以将员工按部门进行分组。
## 1.2 GROUP BY的工作原理
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
【多线程编程】:指针使用指南,确保线程安全与效率
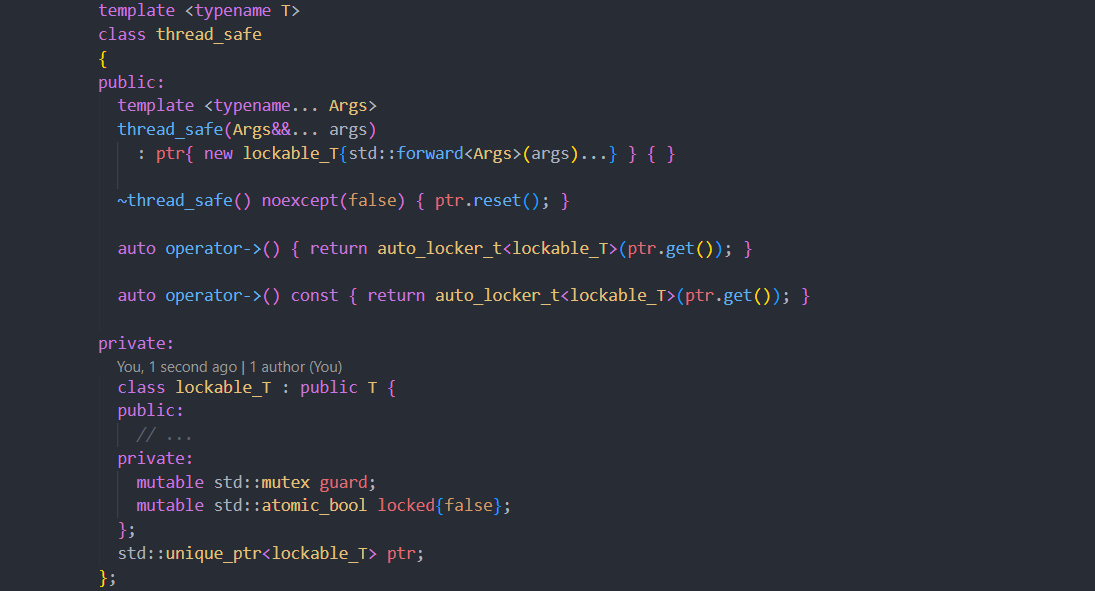
# 1. 多线程编程基础
## 1.1 多线程编程的必要性
在现代软件开发中,为了提升程序性能和响应速度,越来越多的应用需要同时处理多个任务。多线程编程便是实现这一目标的重要技术之一。通过合理地将程序分解为多个独立运行的线程,可以让CPU资源得到有效利用,并提高程序的并发处理能力。
## 1.2 多线程与操作系统
多线程是在操作系统层面上实现的,操作系统通过线程调度算法来分配CPU时
Java开发者必备:JsonPath在REST API测试中的运用

# 1. JsonPath的简介及其在API测试中的重要性
API测试是软件开发周期中确保数据准确性和接口稳定性的重要环节。随着API的广泛应用,如何高效准确地提取和验证JSON格式的响应数据成为了测试人员关注的焦点。 JsonPath,作为一种轻量级的查询语言,能够方便地从JSON
Java中间件服务治理实践:Dubbo在大规模服务治理中的应用与技巧
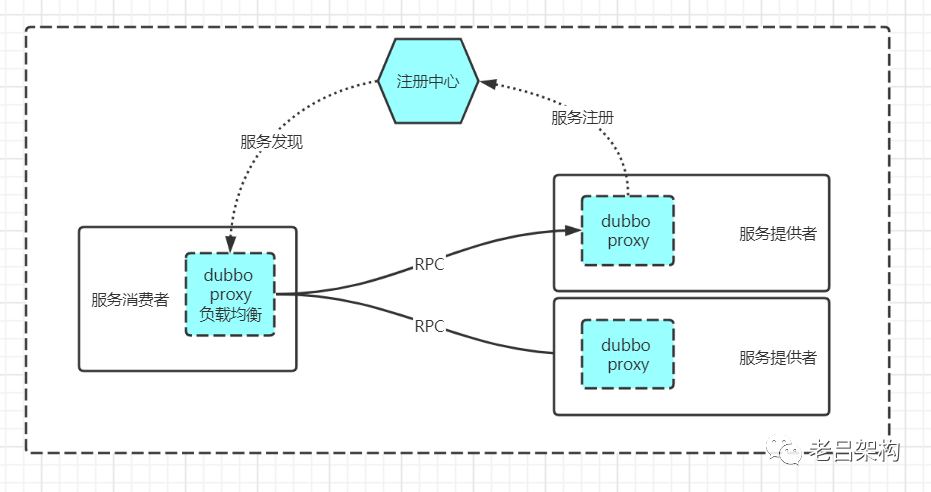
# 1. Dubbo框架概述及服务治理基础
## Dubbo框架的前世今生
Apache Dubbo 是一个高性能的Java RPC框架,起源于阿里巴巴的内部项目Dubbo。在2011年被捐赠给Apache,随后成为了Apache的顶级项目。它的设计目标是高性能、轻量级、基于Java语言开发的SOA服务框架,使得应用可以在不同服务间实现远程方法调用。随着微服务架构
【MySQL大数据集成:融入大数据生态】
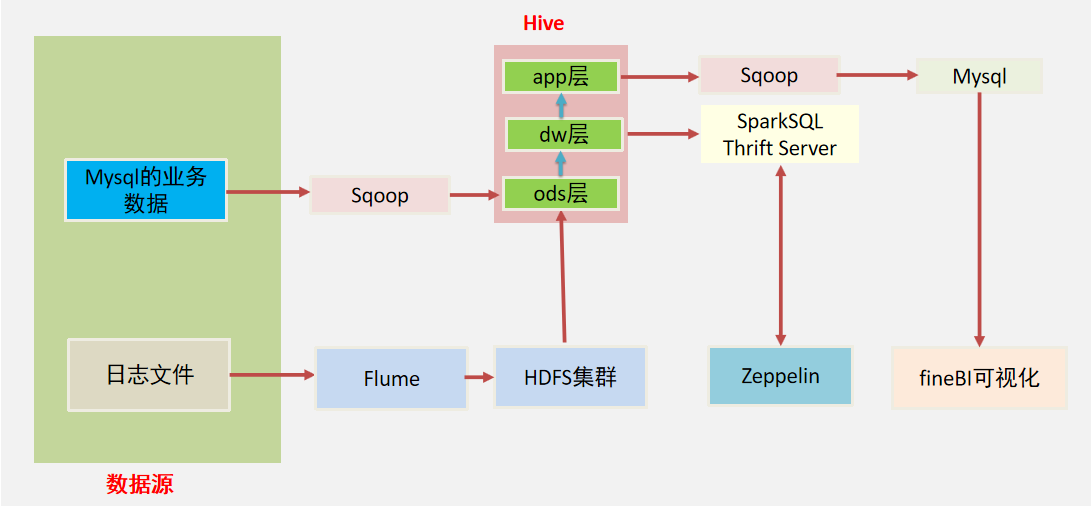
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )