OpenCV角点检测与特征匹配:图像检索与目标追踪的秘密武器
发布时间: 2024-08-10 19:43:59 阅读量: 64 订阅数: 21 

# 1. OpenCV角点检测:图像中的关键点**
角点是图像中具有显著变化的点,它们是图像中重要的特征,可以用来描述图像的内容。OpenCV提供了多种角点检测算法,如Harris角点检测器和Shi-Tomasi角点检测器。这些算法通过计算图像梯度和Hessian矩阵来检测角点。
角点检测在计算机视觉中有着广泛的应用,例如:
- 特征匹配:角点可以作为图像中关键点的代表,用于匹配不同图像中的对应点。
- 运动估计:角点可以用来跟踪图像序列中的运动,从而估计物体或相机的运动。
- 图像检索:角点可以用来构建图像数据库,并通过查询图像的角点来检索相似的图像。
# 2. 寻找图像中的对应点
### 2.1 特征描述符:从角点提取信息
特征描述符是一种数学函数,它将角点周围的图像区域转换为一个唯一的向量。该向量包含有关角点及其周围环境的信息,可用于匹配不同的图像中的角点。
#### 2.1.1 SIFT描述符:尺度不变特征变换
SIFT描述符是一种广泛使用的特征描述符,它对图像的尺度和旋转变化具有鲁棒性。SIFT描述符的计算步骤如下:
1. **高斯金字塔构建:**将图像缩小到不同尺度,形成高斯金字塔。
2. **差分高斯(DoG)金字塔构建:**计算相邻高斯金字塔层之间的差值,形成DoG金字塔。
3. **关键点检测:**在DoG金字塔中寻找极值点(局部最大值和最小值)。
4. **关键点定位:**使用插值精确定位关键点的亚像素位置。
5. **方向分配:**计算关键点周围的梯度方向直方图,并分配一个主方向。
6. **描述符计算:**在关键点周围的一个窗口内,计算梯度幅值和方向的直方图,形成SIFT描述符。
#### 2.1.2 SURF描述符:加速鲁棒特征
SURF描述符是一种比SIFT描述符更快的特征描述符,同时仍具有较高的鲁棒性。SURF描述符的计算步骤如下:
1. **积分图像构建:**计算图像的积分图像,以便快速计算矩形区域的和。
2. **关键点检测:**使用Hessian矩阵近似检测关键点。
3. **关键点定位:**使用插值精确定位关键点的亚像素位置。
4. **方向分配:**计算关键点周围的Haar小波响应,并分配一个主方向。
5. **描述符计算:**在关键点周围的一个窗口内,计算Haar小波响应的和,形成SURF描述符。
### 2.2 特征匹配算法:寻找相似点
特征匹配算法用于在不同的图像中找到具有相似特征描述符的角点。这些算法通常基于距离度量,例如欧几里得距离或余弦相似度。
#### 2.2.1 暴力匹配:逐一比较
暴力匹配是最简单的特征匹配算法,它逐一对两个图像中的所有特征描述符进行比较。匹配的特征描述符是具有最小距离度量的特征描述符。
#### 2.2.2 近似最近邻匹配:快速有效
近似最近邻匹配(ANN)算法是一种更快的特征匹配算法,它使用近似最近邻搜索数据结构(例如KD树或FLANN)。ANN算法通过限制搜索空间来提高匹配速度,同时保持较高的匹配精度。
#### 2.2.3 鲁棒匹配:处理遮挡和噪声
鲁棒匹配算法旨在处理遮挡和噪声等图像匹配中的挑战。这些算法使用启发式方法或统计模型来识别和排除错误匹配。一种常见的鲁棒匹配算法是RANSAC(随机样本一致性),它通过迭代地拟合模型来估计正确的匹配。
# 3. 图像检索:利用角点和特征匹配
### 3.1 基于内容的图像检索:以图像查找图像
**3.1.1 特征数据库的构建**
基于内容的图像检索(CBIR)是一种利用图像的视觉内容进行图像搜索的技术。在CBIR系统中,首先需要建立一个特征数据库,其中包含已知图像的特征。
**步骤:**
1. **图像预处理:**对图像进行预处理,如调整大小、灰度化和降噪。
2. **角点检测:**使用OpenCV中的角点检测算法(如Harris角点检测或SIFT)检测图像中的关键点。
3. **特征提取:**从每个角点提取特征描述符,如SIFT或SURF描述符。
4. **特征存储:**将提取的特征存储在数据库中,每个图像对应一个特征向量。
### 3.1.2 查询图像的特征提取和匹配**
当用户提供查询图像时,系统会提取其特征并将其与数据库中的特征进行匹配。
**步骤:**
1. **查询图像预处理:**对查询图像进行预处理。
2. **特征提取:**从查询图像中提取特征描述符。
3. **特征匹配:**使用特征匹配算法(如暴力匹配或近似最近邻匹配)将查询图像的特征与数据库中的特征进行匹配。
4. **相似度计算:**计算查询图像特征与数据库中每个图像特征之间的相似度,如欧氏距离或余弦相似度。
5. **图像检索:**根据相似度对数据库中的图像进行排序,并返回最相似的图像。
### 3.2 图像分类:将图像归类到不同类别
图像分类是将图像分配到预定义类别(如动物、风景、人脸)的任务。
### 3.2.1 特征的聚类和分类**
图像分类通常涉及以下步骤:
1. **特征提取:**从图像中提取特征描述符。
2. **特征聚类:**使用聚类算法(如k均值或层次聚类)将特征分组到不同的簇。
3. **分类器训练:**使用分类算法(如支持向量机或决策树)训练分类器,将图像分配到不同的类别。
4. **分类器评估:**使用测试集评估分类器的性能。
### 3.2.2 分类器的训练和评估**
分类器的训练和评估过程如下:
1. **训练集:**将已标记的图像数据集分为训练集和测试集。
2. **训练:**使用训练集训练分类器,学习图像和类别的关系。
3. **评估:**使用测试集评估分类器的性能,计算准确率、召回率和F1分数等指标。
# 4. 目标追踪:使用角点和特征匹配
### 4.1 目标初始化
目标追踪的第一步是确定目标的初始位置。这可以通过两种方式实现:
#### 4.1.1 手动选择
最简单的方法是手动选择目标的边界框。这通常适用于目标在图像中清晰可见且易于定位的情况。
#### 4.1.2 自动检测
对于更具挑战性的场景,可以使用自动检测算法来初始化目标。这些算法通常基于角点检测和特征匹配。
例如,可以使用以下步骤自动检测目标:
1. 在第一帧中检测角点。
2. 从角点中提取特征。
3. 在后续帧中匹配特征。
4. 使用匹配的特征计算目标的边界框。
### 4.2 目标跟踪
一旦目标被初始化,就可以在连续帧中对其进行跟踪。有两种主要的方法:
#### 4.2.1 基于角点的跟踪
基于角点的跟踪算法利用角点的运动来估计目标的位置。这些算法通常使用卡尔曼滤波器来预测目标的运动并更新其位置。
#### 4.2.2 基于特征的跟踪
基于特征的跟踪算法使用目标的特征来估计其位置。这些算法通常使用特征匹配算法来在后续帧中找到目标的特征。
#### 4.2.3 鲁棒跟踪
在实际应用中,目标可能会变形、遮挡或受到其他干扰。为了处理这些挑战,可以使用鲁棒跟踪算法。这些算法通常使用多个特征匹配算法并结合其他技术,如光流法,来提高跟踪的准确性和鲁棒性。
### 4.2.4 目标追踪算法流程图
下图展示了目标追踪算法的一般流程:
```mermaid
graph LR
subgraph 初始化
A[手动选择] --> B[自动检测]
end
subgraph 跟踪
C[基于角点的跟踪] --> D[基于特征的跟踪]
D --> E[鲁棒跟踪]
end
A --> C
A --> D
B --> C
B --> D
```
### 4.2.5 目标追踪算法比较
下表比较了不同目标追踪算法的优缺点:
| 算法类型 | 优点 | 缺点 |
|---|---|---|
| 基于角点的跟踪 | 快速、鲁棒 | 容易受到噪声和遮挡的影响 |
| 基于特征的跟踪 | 准确、鲁棒 | 计算量大 |
| 鲁棒跟踪 | 鲁棒、准确 | 计算量大 |
# 5. OpenCV角点检测和特征匹配的应用
### 5.1 3D重建:从图像中创建3D模型
**5.1.1 特征匹配用于图像配准**
3D重建涉及从一组图像中创建3D模型。关键步骤之一是图像配准,其中将不同图像中的对应点对齐。OpenCV的角点检测和特征匹配算法在这一过程中发挥着至关重要的作用。
**代码块:**
```python
import cv2
# 加载图像
img1 = cv2.imread('image1.jpg')
img2 = cv2.imread('image2.jpg')
# 角点检测
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
# 特征匹配
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
# 排序匹配点
matches = sorted(matches, key=lambda x: x.distance)
# 图像配准
H, _ = cv2.findHomography(np.array([kp1[m.queryIdx].pt for m in matches]),
np.array([kp2[m.trainIdx].pt for m in matches]), cv2.RANSAC, 5.0)
```
**逻辑分析:**
此代码块演示了使用OpenCV进行图像配准的步骤:
1. 加载两幅图像。
2. 使用ORB算法检测角点和提取特征描述符。
3. 使用暴力匹配算法匹配特征。
4. 根据匹配距离对匹配点进行排序。
5. 使用RANSAC算法计算图像之间的单应性矩阵H,用于图像配准。
**5.1.2 结构从运动中恢复**
结构从运动(SfM)是一种从图像序列重建3D模型的技术。它利用角点检测和特征匹配来跟踪图像序列中的特征点,并从这些点的位置估计相机运动和场景结构。
**代码块:**
```python
import cv2
import numpy as np
# 加载图像序列
images = ['image1.jpg', 'image2.jpg', 'image3.jpg']
# 角点检测和特征提取
orb = cv2.ORB_create()
kps = []
descs = []
for img in images:
kp, des = orb.detectAndCompute(cv2.imread(img), None)
kps.append(kp)
descs.append(des)
# 特征匹配
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = []
for i in range(len(images) - 1):
matches.append(bf.match(descs[i], descs[i+1]))
# 相机运动和场景结构估计
camera_matrices = []
point_clouds = []
for i in range(len(images) - 1):
H, _ = cv2.findHomography(np.array([kps[i][m.queryIdx].pt for m in matches[i]]),
np.array([kps[i+1][m.trainIdx].pt for m in matches[i]]), cv2.RANSAC, 5.0)
camera_matrices.append(H)
point_clouds.append(cv2.triangulatePoints(camera_matrices[i], camera_matrices[i+1],
np.array([kps[i][m.queryIdx].pt for m in matches[i]]),
np.array([kps[i+1][m.trainIdx].pt for m in matches[i]])))
```
**逻辑分析:**
此代码块展示了SfM的基本步骤:
1. 加载图像序列。
2. 使用ORB算法检测角点并提取特征描述符。
3. 使用暴力匹配算法匹配特征。
4. 使用单应性矩阵估计相机运动。
5. 使用三角测量估计场景结构。
### 5.2 运动估计:计算图像序列中的运动
**5.2.1 光流法**
光流法是一种估计图像序列中像素运动的技术。它利用OpenCV的角点检测和特征匹配算法来跟踪图像中的特征点,并从这些点的运动估计图像序列中的运动。
**代码块:**
```python
import cv2
# 加载图像序列
images = ['image1.jpg', 'image2.jpg', 'image3.jpg']
# 角点检测和特征提取
orb = cv2.ORB_create()
kps = []
descs = []
for img in images:
kp, des = orb.detectAndCompute(cv2.imread(img), None)
kps.append(kp)
descs.append(des)
# 特征匹配
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = []
for i in range(len(images) - 1):
matches.append(bf.match(descs[i], descs[i+1]))
# 光流估计
flow = cv2.calcOpticalFlowPyrLK(cv2.cvtColor(cv2.imread(images[0]), cv2.COLOR_BGR2GRAY),
cv2.cvtColor(cv2.imread(images[1]), cv2.COLOR_BGR2GRAY),
np.array([kp[m.queryIdx].pt for m in matches[0]]), None)
```
**逻辑分析:**
此代码块演示了使用光流法估计图像序列中运动的步骤:
1. 加载图像序列。
2. 使用ORB算法检测角点并提取特征描述符。
3. 使用暴力匹配算法匹配特征。
4. 使用Lucas-Kanade光流算法估计特征点的运动。
**5.2.2 特征跟踪法**
特征跟踪法是一种通过跟踪图像序列中的特征点来估计运动的技术。它利用OpenCV的角点检测和特征匹配算法来识别和跟踪图像中的特征点,并从这些点的运动估计图像序列中的运动。
**代码块:**
```python
import cv2
# 加载图像序列
images = ['image1.jpg', 'image2.jpg', 'image3.jpg']
# 角点检测和特征提取
orb = cv2.ORB_create()
kps = []
descs = []
for img in images:
kp, des = orb.detectAndCompute(cv2.imread(img), None)
kps.append(kp)
descs.append(des)
# 特征跟踪
tracker = cv2.TrackerKCF_create()
tracker.init(cv2.imread(images[0]), np.array([kp[0].pt for kp in kps[0]]))
for img in images[1:]:
tracker.update(cv2.imread(img))
```
**逻辑分析:**
此代码块展示了使用特征跟踪法估计图像序列中运动的步骤:
1. 加载图像序列。
2. 使用ORB算法检测角点并提取特征描述符。
3. 初始化跟踪器。
4. 使用跟踪器跟踪特征点。
# 6. OpenCV角点检测和特征匹配的未来发展**
**6.1 深度学习在角点检测和特征匹配中的应用**
深度学习技术在计算机视觉领域取得了显著进展,为角点检测和特征匹配带来了新的机遇。
**6.1.1 卷积神经网络(CNN)用于特征提取**
CNN以其强大的特征提取能力而闻名。它们可以从图像中学习层次化的特征表示,这些表示对于角点检测和特征匹配至关重要。使用CNN提取的特征比传统方法(如SIFT和SURF)更鲁棒且具有辨别力。
**6.1.2 深度学习模型在匹配算法中的应用**
深度学习模型还可以用于改进匹配算法。例如,研究人员已经开发了基于CNN的匹配算法,这些算法可以处理遮挡、噪声和变形等挑战。这些算法在性能和鲁棒性方面优于传统方法。
**6.2 实时处理和嵌入式系统中的角点检测和特征匹配**
角点检测和特征匹配在实时应用和嵌入式系统中变得越来越重要。这些应用要求算法在低功耗和低延迟条件下高效运行。
**6.2.1 优化算法和数据结构**
为了满足实时处理的需求,研究人员正在优化角点检测和特征匹配算法。这些优化包括使用并行处理、改进的数据结构和减少计算复杂度。
**6.2.2 低功耗和低延迟实现**
在嵌入式系统中,低功耗和低延迟至关重要。研究人员正在探索硬件加速和低功耗算法,以在这些系统中实现角点检测和特征匹配。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
OpenCV角点检测专栏提供全面的角点检测指南,从入门到精通。它涵盖了角点检测的各个方面,包括性能优化、特征匹配、三维重建、增强现实、自动驾驶、医疗影像、工业检测、机器人视觉、遥感影像、无人机航拍、卫星图像处理、生物识别、安防监控、虚拟现实和游戏开发。该专栏旨在帮助读者深入了解角点检测技术,并将其应用于各种图像处理、计算机视觉和人工智能任务中。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据子集可视化】:lattice包高效展示数据子集的秘密武器

# 1. 数据子集可视化简介
在数据分析的探索阶段,数据子集的可视化是一个不可或缺的步骤。通过图形化的展示,可以直观地理解数据的分布情况、趋势、异常点以及子集之间的关系。数据子集可视化不仅帮助分析师更快地发现数据中的模式,而且便于将分析结果向非专业观众展示。
数据子集的可视化可以采用多种工具和方法,其中基于R语言的`la
R语言与SQL数据库交互秘籍:数据查询与分析的高级技巧
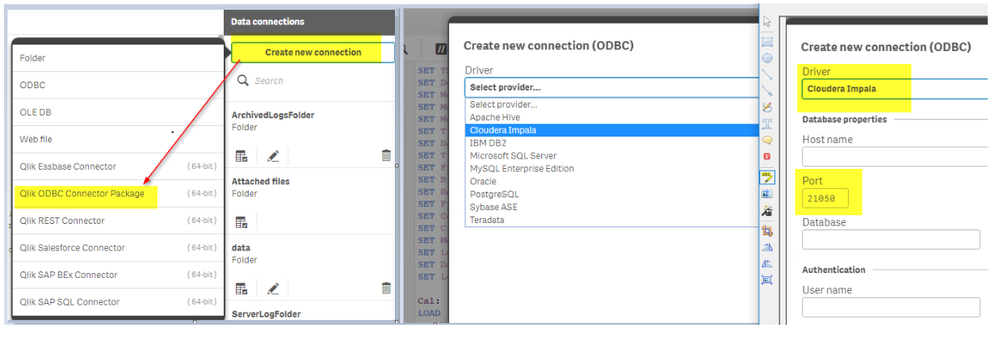
# 1. R语言与SQL数据库交互概述
在数据分析和数据科学领域,R语言与SQL数据库的交互是获取、处理和分析数据的重要环节。R语言擅长于统计分析、图形表示和数据处理,而SQL数据库则擅长存储和快速检索大量结构化数据。本章将概览R语言与SQL数据库交互的基础知识和应用场景,为读者搭建理解后续章节的框架。
## 1.
【R语言qplot深度解析】:图表元素自定义,探索绘图细节的艺术(附专家级建议)

# 1. R语言qplot简介和基础使用
## qplot简介
`qplot` 是 R 语言中 `ggplot2` 包的一个简单绘图接口,它允许用户快速生成多种图形。`qplot`(快速绘图)是为那些喜欢使用传统的基础 R 图形函数,但又想体验 `ggplot2` 绘图能力的用户设
模型结果可视化呈现:ggplot2与机器学习的结合
# 1. ggplot2与机器学习结合的理论基础
ggplot2是R语言中最受欢迎的数据可视化包之一,它以Wilkinson的图形语法为基础,提供了一种强大的方式来创建图形。机器学习作为一种分析大量数据以发现模式并建立预测模型的技术,其结果和过程往往需要通过图形化的方式来解释和展示。结合ggplot2与机器学习,可以将复杂的数据结构和模型结果以视觉友好的形式展现
【R语言地理信息数据分析】:chinesemisc包的高级应用与技巧
# 1. R语言与地理信息数据分析概述
R语言作为一种功能强大的编程语言和开源软件,非常适合于统计分析、数据挖掘、可视化以及地理信息数据的处理。它集成了众多的统计包和图形工具,为用户提供了一个灵活的工作环境以进行数据分析。地理信息数据分析是一个特定领域
模型验证的艺术:使用R语言SolveLP包进行模型评估
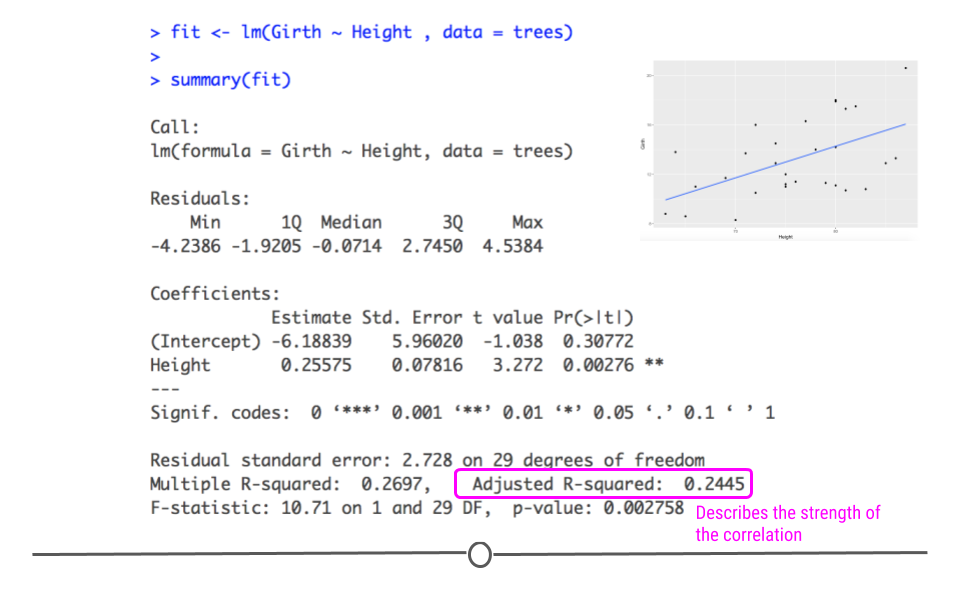
# 1. 线性规划与模型验证简介
## 1.1 线性规划的定义和重要性
线性规划是一种数学方法,用于在一系列线性不等式约束条件下,找到线性目标函数的最大值或最小值。它在资源分配、生产调度、物流和投资组合优化等众多领域中发挥着关键作用。
```mermaid
flowchart LR
A[问题定义] --> B[建立目标函数]
B --> C[确定约束条件]
C --> D[
R语言数据包安全使用指南:规避潜在风险的策略
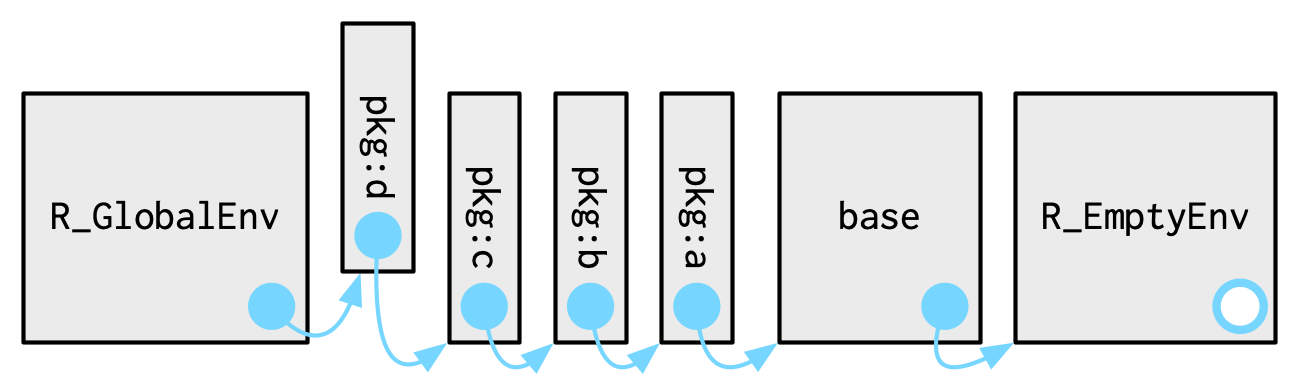
# 1. R语言数据包基础知识
在R语言的世界里,数据包是构成整个生态系统的基本单元。它们为用户提供了一系列功能强大的工具和函数,用以执行统计分析、数据可视化、机器学习等复杂任务。理解数据包的基础知识是每个数据科学家和分析师的重要起点。本章旨在简明扼要地介绍R语言数据包的核心概念和基础知识,为
R语言tm包中的文本聚类分析方法:发现数据背后的故事

# 1. 文本聚类分析的理论基础
## 1.1 文本聚类分析概述
文本聚类分析是无监督机器学习的一个分支,它旨在将文本数据根据内容的相似性进行分组。文本数据的无结构特性导致聚类分析在处理时面临独特挑战。聚类算法试图通过发现数据中的自然分布来形成数据的“簇”,这样同一簇内的文本具有更高的相似性。
## 1.2 聚类分
R语言数据包性能监控:实时跟踪使用情况的高效方法
# 1. R语言数据包性能监控概述
在当今数据驱动的时代,对R语言数据包的性能进行监控已经变得越来越重要。本章节旨在为读者提供一个关于R语言性能监控的概述,为后续章节的深入讨论打下基础。
## 1.1 数据包监控的必要性
随着数据科学和统计分析在商业决策中的作用日益增强,R语言作为一款强大的统计分析工具,其性能监控成为确保数据处理效率和准确性的重要环节。性能监控能够帮助我们识别潜在的瓶颈,及时优化数据包的使用效率,提
【Tau包社交网络分析】:掌握R语言中的网络数据处理与可视化
# 1. Tau包社交网络分析基础
社交网络分析是研究个体间互动关系的科学领域,而Tau包作为R语言的一个扩展包,专门用于处理和分析网络数据。本章节将介绍Tau包的基本概念、功能和使用场景,为读者提供一个Tau包的入门级了解。
## 1.1 Tau包简介
Tau包提供了丰富的社交网络分析工具,包括网络的创建、分析、可视化等,特别适合用于研究各种复杂网络的结构和动态。它能够处理有向或无向网络,支持图形的导入和导出,使得研究者能够有效地展示和分析网络数据。
## 1.2 Tau与其他网络分析包的比较
Tau包与其他网络分析包(如igraph、network等)相比,具备一些独特的功能和优势。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )