JSON数据转换与大数据处理:海量数据转换,探索数据价值
发布时间: 2024-08-05 00:45:39 阅读量: 12 订阅数: 12 

# 1. JSON数据基础**
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,广泛用于Web开发和数据存储。它基于JavaScript对象,使用键值对表示数据,格式清晰易读。
JSON数据通常以文本形式存储,其语法规则如下:
- 数据以键值对的形式组织,键为字符串,值可以是字符串、数字、布尔值、数组或对象。
- 键和值之间用冒号分隔,键值对之间用逗号分隔。
- 对象用花括号括起来,数组用方括号括起来。
- JSON数据必须以花括号或方括号开头和结尾。
# 2. JSON数据转换技术
### 2.1 数据转换框架与工具
#### 2.1.1 Apache Spark SQL
Apache Spark SQL是一个用于大规模数据处理的分布式查询引擎。它基于Apache Spark核心引擎,提供了一个类似于SQL的接口,用于查询和转换数据。
**代码块:**
```scala
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("Spark SQL Example")
.master("local[*]")
.getOrCreate()
val df = spark.read.json("data.json")
df.show()
```
**逻辑分析:**
* 创建SparkSession对象,用于初始化Spark SQL环境。
* 读取JSON文件"data.json"并创建DataFrame。
* 使用`show()`方法显示DataFrame的前几行数据。
**参数说明:**
* `appName`:Spark应用程序的名称。
* `master`:Spark集群的模式,"local[*]"表示在本地运行。
* `read.json()`:读取JSON文件并创建DataFrame。
#### 2.1.2 Apache Flink
Apache Flink是一个用于大规模数据处理的分布式流处理引擎。它提供了对流式和批处理数据的高吞吐量和低延迟处理。
**代码块:**
```java
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.streaming.api.datastream.DataStream
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val stream = env.readTextFile("data.json")
stream.print()
```
**逻辑分析:**
* 创建StreamExecutionEnvironment对象,用于初始化Flink环境。
* 读取JSON文件"data.json"并创建DataStream。
* 使用`print()`方法打印DataStream中的数据。
**参数说明:**
* `getExecutionEnvironment()`:获取StreamExecutionEnvironment对象。
* `readTextFile()`:读取JSON文件并创建DataStream。
### 2.2 数据转换方法
#### 2.2.1 数据类型转换
数据类型转换是将数据从一种数据类型转换为另一种数据类型。Spark SQL和Flink都提供了丰富的类型转换函数。
**表格:数据类型转换函数**
| Spark SQL | Flink |
|---|---|
| `cast()` | `cast()` |
| `to_date()` | `to_date()` |
| `to_timestamp()` | `to_timestamp()` |
#### 2.2.2 数据结构转换
数据结构转换是将数据从一种结构转换为另一种结构。Spark SQL和Flink支持各种数据结构转换操作。
**代码块:**
```scala
import org.apache.spark.sql.functions._
val df = spark.read.json("data.json")
df.withColumn("nested", explode(col("nested")))
```
**逻辑分析:**
* 使用`explode()`函数将嵌套的JSON数组"nested"转换为多个行。
* `withColumn()`函数将新列"nested"添加到DataFrame中。
**代码块:**
```java
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
val stream = env.readTextFile("data.json")
val tuples = stream.map(line -> {
val json = new JSONObject(line);
new Tuple2<>(json.getString("id"), json.getInt("value"));
})
``
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“JSON数据库转换”专栏,您的数据转换指南!从入门到精通,我们将深入探讨 JSON 数据转换的艺术,揭示其技巧和精髓。我们将揭示常见的转换陷阱并提供解决方案,帮助您避免雷区。此外,我们将分享提速秘籍,优化性能并提升转换效率。
我们还将探索 JSON 数据转换与 NoSQL 和关系型数据库、数据集成、数据分析、机器学习、云计算、API 设计、数据治理、数据安全、数据可视化、数据科学、数据挖掘、数据仓库和数据湖之间的强大联系。通过了解这些连接,您可以解锁数据潜力,为洞察力赋能,驱动业务决策,并构建一个可靠、安全且可扩展的数据生态系统。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
The Status and Role of Tsinghua Mirror Source Address in the Development of Container Technology
# Introduction
The rapid advancement of container technology is transforming the ways software is developed and deployed, making applications more portable, deployable, and scalable. Amidst this technological wave, the image source plays an indispensable role in containers. This chapter will first
The Prospects of YOLOv8 in Intelligent Transportation Systems: Vehicle Recognition and Traffic Optimization
# 1. Overview of YOLOv8 Target Detection Algorithm**
YOLOv8 is the latest iteration of the You Only Look Once (YOLO) target detection algorithm, released by the Ultralytics team in 2022. It is renowned for its speed, accuracy, and efficiency, making it an ideal choice for vehicle identification and
希尔排序的并行潜力:多核处理器优化的终极指南
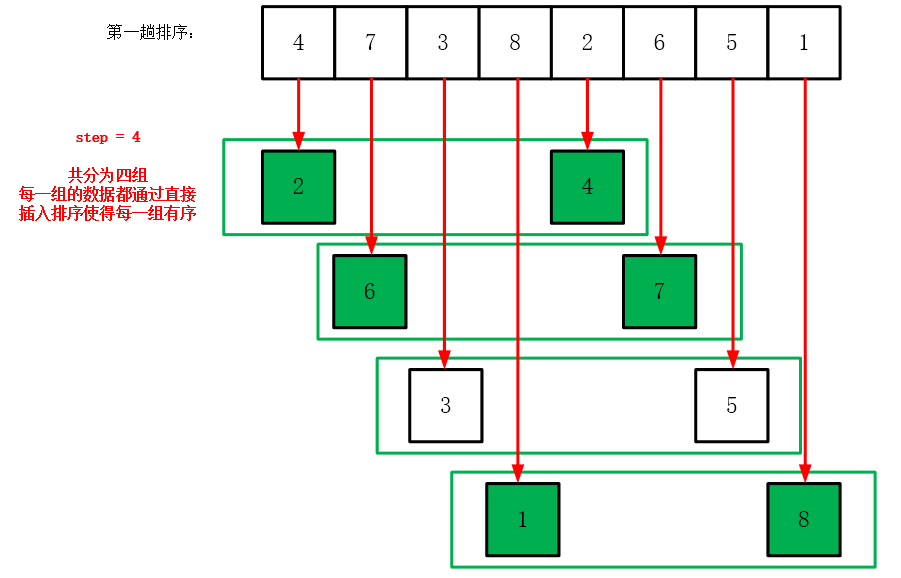
# 1. 希尔排序算法概述
希尔排序算法,作为插入排序的一种更高效的改进版本,它是由数学家Donald Shell在1959年提出的。希尔排序的核心思想在于先将整个待排序的记录序列分割成若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行一次直接插入排序。这样的方式大大减少了记录的移动次数,从而提升了算法的效率。
## 1.1 希尔排序的起源与发展
希尔排序算法的提出,旨在解决当时插入排序在处理大数据量
【数据库索引优化】:倒插法排序在数据库索引中的高效应用
# 1. 数据库索引优化概述
数据库索引优化是提升数据库查询效率的关键技术。良好的索引设计不仅可以加快数据检索速度,还能减少数据存储空间,提高系统的整体性能。本章节将对数据库索引优化进行基础介绍,探讨索引的工作原理、优化目的以及常见的优化策略。
## 1.1 索引与查询效率
数据库索引相当于图书的目录,它通过特定的数据结构(如B树、B+树)加快数据检索。一个良好的索引可以
The Application and Challenges of SPI Protocol in the Internet of Things
# Application and Challenges of SPI Protocol in the Internet of Things
The Internet of Things (IoT), as a product of the deep integration of information technology and the physical world, is gradually transforming our lifestyle and work patterns. In IoT systems, each physical device can achieve int
MATLAB Versions and Deep Learning: Model Development Training, Version Compatibility Guide
# 1. Introduction to MATLAB Deep Learning
MATLAB is a programming environment widely used for technical computation and data analysis. In recent years, MATLAB has become a popular platform for developing and training deep learning models. Its deep learning toolbox offers a wide range of functions a
Advanced Network Configuration and Port Forwarding Techniques in MobaXterm
# 1. Introduction to MobaXterm
MobaXterm is a powerful remote connection tool that integrates terminal, X11 server, network utilities, and file transfer tools, making remote work more efficient and convenient.
### 1.1 What is MobaXterm?
MobaXterm is a full-featured terminal software designed spec
Clock Management in Verilog and Precise Synchronization with 1PPS Signal
# 1. Introduction to Verilog
Verilog is a hardware description language (HDL) used for modeling, simulating, and synthesizing digital circuits. It provides a convenient way to describe the structure and behavior of digital circuits and is widely used in the design and verification of digital system
【Basic】Detailed Explanation of MATLAB Toolbox: Simulink
## 2.1 Structure and Elements of Simulink Models
Simulink models consist of various elements that work together to create and simulate systems. These elements include:
- **Subsystems:** Encapsulate complex parts of the model into smaller, manageable units. Subsystems can be nested within other sub
【JS树结构转换最佳实践】:专家建议与实战案例

# 1. JS树结构转换基础概述
在现代Web开发中,树结构的转换是一种常见的数据处理方式,特别是在涉及大量嵌套数据和DOM操作的场景。JavaScript (JS) 作为一种灵活的脚本语言,提供了处理树结构的便捷方式
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )