【Tidy库复杂数据转换】:揭秘数据结构转换的最佳实践
发布时间: 2024-10-14 04:52:42 阅读量: 5 订阅数: 6 

# 1. Tidy库简介与数据转换基础
## 简介
在数据分析和处理的世界中,Tidy库是一个强大的工具,它提供了一系列函数来帮助我们以一种整洁、一致的方式操作数据。Tidy库是基于R语言开发的,其核心概念是将数据框(DataFrame)转换为整洁数据(Tidy Data),这种格式对于数据操作和分析来说更加直观和有效。
## 数据转换基础
在深入探讨数据清洗和预处理之前,我们需要了解数据转换的基础知识。数据转换是指将数据从一种结构转换为另一种结构的过程。在Tidy库中,这通常意味着从宽格式(Wide Format)转换为长格式(Long Format),反之亦然。这种转换对于数据的聚合、分组和可视化分析至关重要。
### 宽格式与长格式
- **宽格式**:每一行代表一个观测,而每个变量则分布在不同的列中。这种格式适合于展示。
- **长格式**:每个观测的所有变量都在同一列中,通常包含一个变量名和一个值。这种格式适合于分析和绘图。
### 转换函数
Tidy库提供了两个基本函数来处理数据格式的转换:
- `gather(data, key, value, ...)`:将宽格式数据框转换为长格式。
- `spread(data, key, value)`:将长格式数据框转换为宽格式。
这些函数不仅能够帮助我们转换数据格式,还能够帮助我们清洗和预处理数据,为进一步的数据分析打下坚实的基础。在后续章节中,我们将深入探讨如何使用Tidy库进行更复杂的数据转换和预处理任务。
# 2. 数据清洗与预处理
在本章节中,我们将深入探讨数据清洗与预处理的重要性,并详细介绍如何使用Tidy库中的数据清洗函数来处理常见的数据清洗任务。我们将通过实例分析和代码实践,展示如何有效地识别和处理缺失值、异常值以及重复数据。
## 2.1 数据清洗的基本概念
### 2.1.1 数据清洗的目的和重要性
数据清洗是数据分析过程中不可或缺的一步,其主要目的是确保数据的质量,提高数据的准确性、一致性和完整性。在一个数据驱动的项目中,数据清洗的重要性体现在以下几个方面:
1. **提高数据分析的准确性**:清洗后的数据能更真实地反映实际情况,减少因数据质量问题导致的分析误差。
2. **减少后续处理的复杂性**:高质量的数据可以简化数据建模和分析过程,提高工作效率。
3. **提升数据的可用性**:清洗后的数据更容易被用于报告、可视化和机器学习模型训练。
4. **增强决策的有效性**:基于清洁数据做出的决策更可靠,有助于企业或组织做出正确的战略选择。
### 2.1.2 常见的数据清洗任务
在数据清洗过程中,我们通常会遇到以下几种常见的任务:
1. **缺失值处理**:识别并处理数据集中缺失的数据值,这包括删除含有缺失值的记录、填充缺失值或预测缺失值。
2. **异常值检测与处理**:识别并处理数据中的异常值,这些值可能是由于错误输入、噪声或其他因素造成的。
3. **重复数据的识别与删除**:识别并删除数据集中的重复记录,以避免对分析结果的影响。
## 2.2 Tidy库中的数据清洗函数
### 2.2.1 缺失值处理
在Tidy库中,我们通常使用`drop_na()`和`fill()`函数来处理缺失值。`drop_na()`函数用于删除含有缺失值的记录,而`fill()`函数用于填充缺失值。
```r
# 示例代码:使用drop_na()和fill()处理缺失值
library(tidyverse)
# 创建一个含有缺失值的数据框
df <- tibble(
id = 1:5,
value = c(10, NA, 12, NA, 14)
)
# 删除含有缺失值的记录
df_clean <- df %>%
drop_na()
# 填充缺失值
df_filled <- df %>%
fill(value)
# 输出结果
print(df_clean)
print(df_filled)
```
### 2.2.2 异常值检测与处理
异常值的检测和处理可以通过多种方法进行,例如统计方法或可视化方法。在Tidy库中,我们可以使用`filter()`函数结合条件表达式来检测异常值,并使用`mutate()`和`ifelse()`函数进行条件替换。
```r
# 示例代码:使用filter()和mutate()处理异常值
# 假设我们有一个数据框df,其中包含了一个数值列value
# 我们将value的正常范围定义为平均值的±2倍标准差
df <- tibble(
id = 1:100,
value = rnorm(100)
)
# 检测并替换异常值
df_clean <- df %>%
mutate(
value = ifelse(value < (mean(value) - 2 * sd(value)) | value > (mean(value) + 2 * sd(value)), NA, value)
)
# 输出结果
print(df_clean)
```
### 2.2.3 重复数据的识别与删除
重复数据的识别和删除可以通过`distinct()`函数实现。这个函数会保留唯一记录,删除重复的行。
```r
# 示例代码:使用distinct()删除重复数据
df <- tibble(
id = c(1, 2, 1, 3, 3),
value = c(10, 20, 10, 30, 30)
)
# 删除重复数据
df_unique <- df %>%
distinct()
# 输出结果
print(df_unique)
```
## 2.3 实践:使用Tidy库进行数据预处理
### 2.3.1 实例分析
假设我们有一个包含员工信息的数据集,其中包含员工的ID、姓名、部门和薪水。我们需要进行数据清洗,包括处理缺失值、异常值和重复记录。
```r
# 创建员工数据集
employees <- tibble(
id = 1:10,
name = c("Alice", "Bob", NA, "Charlie", "David", "Eve", "Frank", "Grace", "Helen", "Ivy"),
department = c("HR", "IT", "Finance", "HR", "IT", "Finance", "IT", "HR", "Finance", "IT"),
salary = c(50000, 60000, 55000, NA, 52000, 51000, 58000, 56000, 59000, 61000)
)
# 处理缺失值:删除含有缺失值的记录
employees_clean <- employees %>%
drop_na()
# 处理重复数据:删除重复记录
employees_unique <- employees_clean %>%
distinct()
# 输出结果
print(employees_unique)
```
### 2.3.2 代码实践与结果分析
通过上述代码实践,我们成功地清洗了数据集,删除了包含缺失值和重复记录的行。这样的数据清洗工作对于后续的数据分析和建模至关重要,可以显著提高数据分析的准确性和效率。
在本章节中,我们介绍了数据清洗的基本概念、Tidy库中的数据清洗函数以及如何通过实际案例进行数据预处理。通过这些内容,我们希望读者能够理解数据清洗的重要性,并掌握使用Tidy库进行数据清洗的基本技能。接下来的章节将深入探讨数据结构转换技术,继续扩展我们对数据处理的理解。
# 3. 数据结构转换技术
## 3.1 数据重构的基本原理
### 3.1.1 数据重构的定义
数据重构是数据科学中的一项重要技术,它涉及到对数据集中的数据进行重新排列和组织的过程,以便更好地适应分析或报告的需求。在Tidy库的上下文中,数据重构通常指的是将数据从宽格式(wide format)转换为长格式(long format),或反之。这种转换在数据清洗、聚合、可视化等多个阶段都至关重要。
### 3.1.2 数据重构的重要性
数据重构之所以重要,是因为不同的数据结构对数据分析有不同的影响。例如,在宽格式中,每个变量都是一个列,这使得某些类型的分析更为直观。而在长格式中,每个观察都是一行,这在进行时间序列分析或分组比较时更为方便。通过重构数据,分析师可以更容易地将数据映射到特定的分析框架中,比如使用ggplot2进行可视化时,长格式数据通常是首选。
## 3.2 Tidy库中的数据转换工具
### 3.2.1 gather和spread函数
`gather()` 和 `spread()` 函数是Tidy库中用于数据重构的基本工具。`gather()` 函数用于将宽格式数据转换为长格式数据,而 `spread()` 函数则执行相反的操作。
#### 代码块示例:
```r
library(tidyr)
# gather() 示例
long_data
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python邮件库学习之路】:email.mime.text的基本使用与案例分析

# 1. Python邮件库概述
Python作为一种编程语言,因其简洁易学、功能强大,在邮件处理方面也有着广泛的应用。其中,`email`库是Python标准库中的一个重要组件,它提供了丰富的工具来构建和解析邮件消息,包括文本邮件、HTML邮件以及附件等。`email.mime.text`作为`email`库中的一个子库,专门用于处理邮件文本内
【Tornado.options合并策略】:多环境配置管理的高级技巧

# 1. Tornado.options概览
在本章节中,我们将对Tornado.options进行一个初步的介绍,让读者了解这个模块的基本功能和应用场景。Tornado.options是一个用于处理配置的Python库,它提供了一种简单而强大的方式来定义和
【Lxml.html在网络安全中的应用】:网页内容监控与分析,专家教你保障网络安全
# 1. Lxml.html概述与安装
## 简介
Lxml.html是一个强大的库,用于解析和处理HTML和XML文档。它建立在libxml2和libxslt库之上,提供了一个简洁的API,使得HTML和XML的解析变得简单且高效。
## 安装
要开始使用Lxml.html,您需要先确保安装了Python和pip工具。接下来,使用pip安装lxml库:
【Django Signals与数据备份】:post_delete事件触发数据备份的策略和实现
# 1. Django Signals概述
在Web开发中,Django框架以其强大的功能和高效率而广受欢迎。Django Sig
【Mercurial代码审查实战】:Python库文件管理的变更集审查

# 1. Mercurial代码审查概述
## 1.1 代码审查的重要性
代码审查是一种质量保证手段,它涉及对源代码的系统性检查,旨在发现并修复错误、提高代码质量以及促进知识共享。通过审查,团队成员可以相互学习最佳实践,保持代码库的整洁和一致性。
## 1.
【Django GIS最佳实践】:提升GIS应用响应速度的5大技巧

# 1. Django GIS概述
## 1.1 Django GIS简介
Django GIS是一个集成地理信息系统(GIS)功能的Python框架,它允许开发者在Django项目中处理和展示地理数据。GIS技术的加入使得Web应用能够处理地图、空间查询和各种地理计算,从而扩展了其应用场景,比如
Genshi.Template性能测试:如何评估模板引擎的性能

# 1. 模板引擎性能测试概述
## 1.1 为什么进行性能测试?
在现代的Web开发中,模板引擎作为将数据与界面分离的重要工具,其性能直接影响到Web应用的响应速度和用户体验。随着业务的扩展和用户量的增加,模板引擎的性能问题会变得更加突出。因此,对模板引擎进行性能测
【win32process的内存管理】:Python中的内存优化与进程内存分析的秘籍
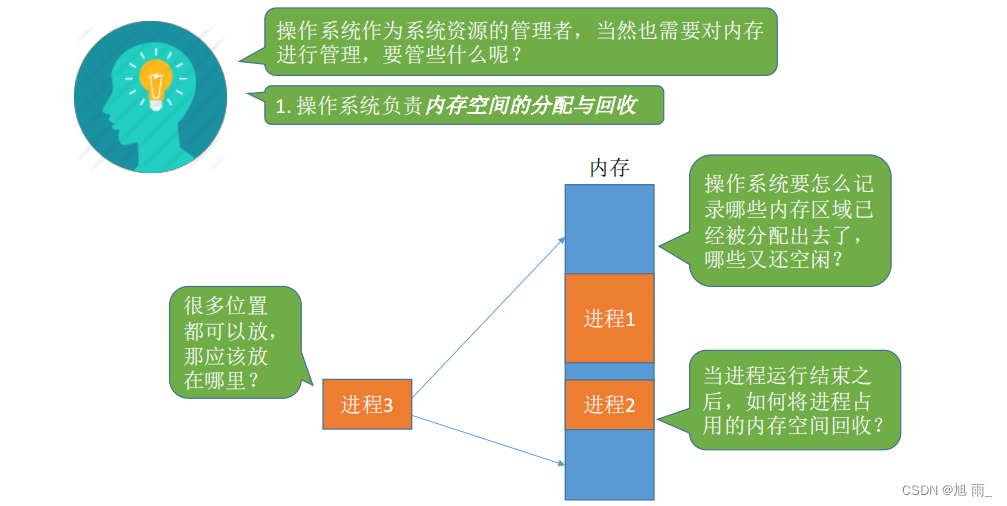
# 1. Win32Process内存管理概述
## 内存管理的重要性
在现代操作系统中,内存管理是确保系统稳定运行的关键因素之一。Win32Process,作为Windows操作系统的核心组成部分,提供了丰富的API来管理内存资源。对于开发者而言,理解内存管理的基本原理和方法,不仅能够帮助提高程序的性能,还能有效地预防内存泄漏等问题。
## 内存管理的基本概念
内
【Twisted并发编程技巧】:线程与进程协同工作的高级技巧
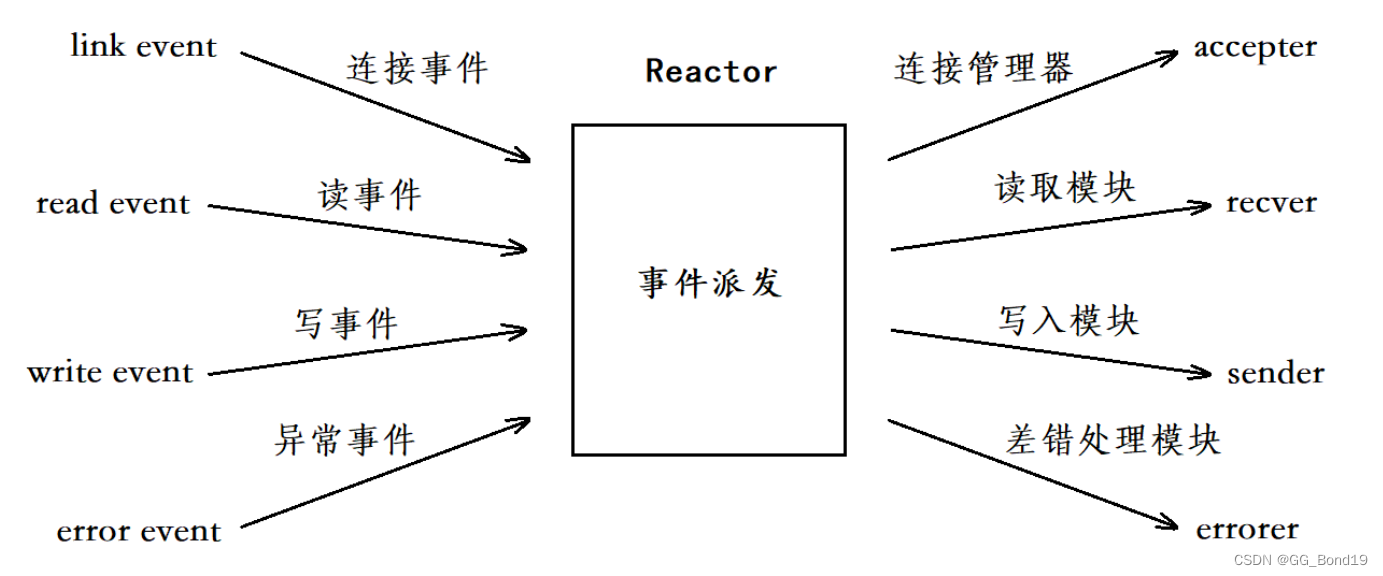
# 1. Twisted框架概述
## 1.1 Twisted框架简介
Twisted是一个开源的Python网络框架,专门用于构建网络应用程序。它采用了异步事件驱动模型,可以有效地处理大量并发连接,是构建高性能网络服务器的理想选择。
## 1.2 Twisted框架的历史和发展
Twisted起源于1999年,经过多年的迭代和发展,已经成为一个成熟稳定的网络框架。它支持多种网络协议,如TCP
Python Serial库与加密通信:保证数据传输安全性的最佳实践
# 1. Python Serial库基础
## 1.1 Serial库简介
Python Serial库是一个用于处理串口通信的库,它允许用户轻松地与串行端口设备进行交互。Serial库提供了简单易用的接口,可以实现串口数据的发送和接收,以及对串口设备进行配置等功能。
## 1.2 安装Serial库
在开始使用Serial库之前,需要先安装这个库。可以通过Python的包
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )