掌握grep进阶技巧:提升文本搜索效率的秘诀
发布时间: 2024-12-12 05:02:59 阅读量: 11 订阅数: 14 

grep for Windows:grep 是用于搜索纯文本数据的命令行实用程序-开源
# 1. grep基础与文本搜索原理
文本搜索是IT行业中不可或缺的日常工作,而`grep`作为一款强大的文本搜索工具,其基础与原理的理解对于高效地完成任务至关重要。本章节将带你入门`grep`,并深入探讨其背后的文本搜索原理。
## 1.1 grep的起源与功能概述
`grep`(Global Regular Expression Print)是一种在Linux和Unix系统中广泛使用的命令行工具,它通过正则表达式匹配文本,并将匹配行打印出来。无论是在代码审查、日志分析还是在处理各种文本文件时,`grep`都能迅速定位我们需要的信息。
## 1.2 文本搜索原理简述
在开始使用`grep`之前,理解文本搜索的基本原理是十分必要的。文本搜索通常涉及读取文件中的每一行,并将其与预设的模式或正则表达式进行匹配。当找到匹配项时,`grep`就会输出这一行。搜索过程可以是区分大小写的,也可以忽略大小写,这一切都取决于我们如何使用`grep`的参数和选项。
## 1.3 grep的工作流程
使用`grep`进行搜索时,大致流程如下:
1. 用户输入`grep`命令及其参数(如正则表达式)和要搜索的文件路径。
2. `grep`读取指定的文件,并对文件中的每一行执行正则表达式匹配。
3. 如果某一行符合正则表达式定义的模式,`grep`会将这一行输出到终端。
掌握这些基础知识后,我们将进一步探索`grep`的高级用法,包括正则表达式的使用、多文件搜索、结果整理以及性能优化等,以提高文本搜索的效率和准确性。
# 2. 深入grep的正则表达式
正则表达式是文本处理的灵魂,而grep作为强大的文本搜索工具,在利用正则表达式方面更是游刃有余。本章节将深入探讨grep中的正则表达式,涵盖其构成、匹配模式、以及一些实战技巧。
## 2.1 正则表达式的构成
### 2.1.1 元字符的基础应用
正则表达式由一系列特殊字符构成,它们被称作元字符,拥有特别的含义和功能。例如,点号"."可匹配任意单个字符,星号"*"则表示匹配前一个字符零次或多次。来看看一些基础但极为重要的元字符:
```regex
^ # 匹配行的开始
$ # 匹配行的结束
. # 匹配除换行符之外的任意单个字符
* # 匹配前一个字符零次或多次
+ # 匹配前一个字符一次或多次
? # 匹配前一个字符零次或一次
[abc] # 匹配方括号内的任意单个字符
```
- `^` 和 `$` 用于确认匹配必须在行的开始或结束,分别对应行首和行尾位置。
- `.` 则是一个非常实用的元字符,它几乎出现在所有的正则表达式中,用于匹配任何单个字符。
- `*`, `+`, `?` 分别表示对前一个字符出现次数的限制,`*` 表示“前一个字符可以出现0次或多次”,`+` 表示“前一个字符至少出现1次”,而`?` 表示“前一个字符出现0次或1次”。
让我们看一个简单的例子来理解它们的使用:
```bash
echo "grep is powerful" | grep "^grep"
```
上面的命令仅当文本以"grep"开头时才会匹配成功。
### 2.1.2 字符类与量词的高级使用
高级的正则表达式使用涉及字符类和量词,它们提供了更复杂的匹配模式:
```regex
[abc] # 匹配a、b或c中的任意一个字符
[^abc] # 匹配除a、b、c之外的任意字符
[a-z] # 匹配从a到z之间的任意字符
[0-9] # 匹配从0到9之间的任意数字
{m,n} # 前一个字符至少出现m次,最多出现n次
```
- 字符类`[abc]`匹配在括号内的任何一个字符,可以用来简化范围匹配。
- 排除字符类`[^abc]`用于匹配不在括号内的字符,这在需要排除一组字符时非常有用。
- 范围表达式如`[a-z]`表示匹配从`a`到`z`的任意字符,这在匹配字母时尤其方便。
- 量词`{m,n}`允许指定一个范围来匹配前一个字符出现的次数。例如,`a{1,3}`将匹配"aa"或"aaa"。
举个例子:
```bash
echo "123, 456, 789" | grep "[0-9]\{3\}"
```
此命令将匹配连续的三个数字。
## 2.2 正则表达式的匹配模式
### 2.2.1 基本正则表达式与扩展正则表达式
grep支持两种类型的正则表达式模式:基本正则表达式(BRE)和扩展正则表达式(ERE)。通过`-E`选项,可以使用扩展正则表达式,其特性之一就是支持更复杂的模式匹配。
- 在BRE中,需要对特殊字符如`?`, `+`, `()`, `|`进行转义才能被识别为特殊意义。
- ERE不需要对上述特殊字符转义,可以直接使用。
例如,在基本正则表达式模式下:
```bash
echo "abcde" | grep -P 'a?'
# 该命令实际上不会按预期工作,因为问号需要转义为 '\?' 来表示前面的字符 'a' 出现零次或一次。
```
改为扩展正则表达式模式:
```bash
echo "abcde" | grep -E 'a?'
# 现在命令将正确匹配 'a' 出现零次或一次的情况。
```
### 2.2.2 非贪婪匹配与回溯引用
- **非贪婪匹配**:在匹配时尽可能少地匹配字符。
- **回溯引用**:在正则表达式中引用之前匹配到的组。
非贪婪匹配使用`?`后缀,使得量词在默认的贪婪模式下变得非贪婪。例如,表达式`a.*?b`将匹配"ab",而不是"axyzb"。
```regex
a.*?b # 非贪婪地匹配从a到b之间的任意字符
```
回溯引用通过`\数字`的方式,引用之前已匹配的一个组。组是由括号包围的模式部分。例如:
```regex
([a-z])\1 # 匹配连续重复的字母
```
上面的例子中,`([a-z])`匹配任意一个小写字母并将其捕获到一个组中,`\1`则引用这个组,仅匹配重复出现的字母。
## 2.3 正则表达式的实战技巧
### 2.3.1 正则表达式的分组和捕获
分组使得正则表达式可以将复杂的匹配分解为可管理的部分,并且让回溯引用成为可能。分组的语法是将匹配模式用括号`()`包围起来。
例如:
```regex
(\d{3})-(\d{2})-(\d{4}) # 分组匹配日期格式
```
在上面的例子中,我们匹配了类似于"123-45-6789"的日期格式,并将其分为三个组:前三位数字、中间的破折号、接下来的两位数字以及最后的四位数字。
### 2.3.2 反向引用与条件判断
反向引用(也称为回溯引用)是正则表达式中的一个高级功能,允许我们在正则表达式中引用之前匹配到的某个部分。
反向引用通常用在替换操作中,如在`sed`命令中:
```bash
echo "The cat caught the rat" | sed 's/The \(cat\)/A \1/'
```
上面的命令将输出 "A cat caught the rat",其中`\1`引用了匹配到的"cat"。
条件判断在正则表达式中相对复杂,不在grep的常规使用范围内,但是像Perl这样的语言支持这种模式。条件判断允许进行复杂的匹配,并且根据某些条件进行分支选择。
本章节内容的介绍为基于Markdown格式的二级章节内容。在接下来的内容中,我们将深入探讨grep在不同场景下的应用,通过实例来展示如何在日志分析、文件搜索、以及与其他文本处理工具组合等场景下高效使用grep。
# 3. grep在不同场景下的应用
## 3.1 日志文件分析与grep
### 3.1.1 快速定位日志错误信息
在IT运维和开发领域,快速定位日志中的错误信息是日常工作的必备技能。利用grep的强大文本搜索能力,我们可以迅速找到错误日志的痕迹。例如,如果我们需要定位系统日志中出现的“error”关键字,可以使用以下命令:
```bash
grep "error" /var/log/syslog
```
这条命令会在`/var/log/syslog`文件中搜索包含“error”字符串的行。若要增加搜索的上下文,可以使用`-A`、`-B`、`-C`选项来显示匹配行之后、之前或前后指定数量的行。假设我们想要查看包含“error”的行及其后两行,我们可以这样写:
```bash
grep -A 2 "error" /var/log/syslog
```
### 3.1.2 日志中数据的提取与统计
除定位错误外,我们常常需要从日志中提取特定的数据进行统计分析。例如,要统计过去一小时内访问量最多的页面,可以通过以下方式:
```bash
grep "Page view:" /var/log/apache2/access.log | grep -i -m 10 "today" | sort | uniq -c | sort -nr
```
这条命令首先过滤出包含“Page view:”的行,然后从这些行中提取包含“today”字符串的行(大小写不敏感),接着按出现次数进行排序,最后使用`uniq -c`统计每个页面被访问的次数,并按照访问次数降序排序。
### 表格展示:不同选项对grep命令结果的影响
| 选项 | 功能描述 | 适用场景 |
| --- | --- | --- |
| `-A num` | 显示匹配行之后的num行 | 查看错误上下文 |
| `-B num` | 显示匹配行之前的num行 | 查看错误上下文 |
| `-C num` | 显示匹配行前后各num行 | 查看错误上下文 |
| `-i` | 忽略字符大小写 | 多样化日志文本搜索 |
| `-m num` | 最多显示匹配的num行 | 在大量数据中限制输出 |
| `-v` | 显示不匹配的行 | 排除特定日志行 |
| `-c` | 显示匹配行的数量 | 统计特定模式出现的次数 |
## 3.2 多文件搜索与结果整理
### 3.2.1 同时搜索多个文件中的内容
有时,我们需要在多个文件中搜索相同的模式,这可以通过grep的文件列表功能来实现。例如,我们要在当前目录下所有`.log`文件中搜索“ERROR”字符串:
```bash
grep "ERROR" *.log
```
此命令会搜索所有扩展名为`.log`的文件,将包含“ERROR”的行输出。我们也可以用`-l`选项仅列出包含匹配字符串的文件名:
```bash
grep -l "ERROR" *.log
```
### 3.2.2 使用grep进行文件内容的比较
在软件开发中,比较文件内容的差异是常见任务之一。通过管道将一个文件的内容传递给grep,并与另一个文件进行比较可以做到这一点:
```bash
grep -Fxv -f file1.txt file2.txt
```
在这个例子中,`-F`选项用于将模式视为固定字符串,`-x`表示整个行必须匹配,`-v`表示反转匹配结果,而`-f`选项后跟文件名表示从该文件读取模式。该命令将输出`file2.txt`中有而`file1.txt`中没有的行。
### Mermaid图表:多文件搜索流程图
```mermaid
graph TD
A[开始] --> B[定义搜索模式]
B --> C[指定文件列表]
C --> D[grep命令执行]
D --> E[输出匹配结果]
E --> F[结束]
```
该流程图展示了使用grep进行多文件搜索的基本步骤,从定义搜索模式到输出匹配结果的整个过程。
## 3.3 grep与其他文本处理工具的结合
### 3.3.1 grep与awk、sed的协作
文本处理是Unix/Linux世界中的核心内容之一,grep、awk和sed是三个非常强大的文本处理工具。它们可以各自独立工作,也可以相互协作,以实现复杂的文本搜索和数据处理任务。
例如,如果我们想要提取日志文件中所有IP地址,并进行统计,可以这样结合使用grep、awk和sort:
```bash
grep -oE "\b([0-9]{1,3}\.){3}[0-9]{1,3}\b" access.log | awk '{print $1}' | sort | uniq -c | sort -nr
```
这里的`grep -oE`选项使用扩展正则表达式匹配IP地址,`awk`用于打印每行的第一个字段(即IP地址),`sort`和`uniq`则用于统计和排序IP出现的次数。
### 3.3.2 利用管道和重定向优化搜索流程
在文本处理中,管道(`|`)和重定向(`>`)是常用的工具,它们可以用来连接不同的命令,以优化搜索流程或数据输出。
例如,将搜索结果直接保存到文件中以便后续分析:
```bash
grep "ERROR" *.log > errors.txt
```
这条命令会将所有匹配到的“ERROR”行输出到`errors.txt`文件中,而不直接显示在终端上。这可以方便我们对这些数据进行进一步的处理或分析。
此外,我们可以使用重定向将多个独立的grep命令的输出合并到同一个文件:
```bash
(grep "ERROR" file1.log; grep "WARNING" file2.log) > combined.txt
```
上述命令会将`file1.log`中的“ERROR”行和`file2.log`中的“WARNING”行合并到`combined.txt`文件中。使用括号`()`创建了一个子shell,这在需要同时执行多个命令并合并它们的输出时非常有用。
# 4. 高级grep选项和技巧
在日常的文本搜索任务中,简单的grep命令使用已经不能满足我们的需求。掌握一些高级技巧和选项,能让我们在进行复杂的搜索时更加游刃有余。本章节将深入探讨一些高级的grep选项,提供上下文控制技巧,并分享一些优化grep性能的方法。
## 4.1 grep的高级选项深入解析
### 4.1.1 开启或关闭特定的匹配模式
在某些情况下,我们可能需要对标准的grep行为进行一些定制。这可以通过开启或关闭特定的匹配模式来实现。例如,通过使用`-E`选项,可以使用扩展的正则表达式,支持更复杂的模式匹配,如使用`?`, `+`, `|`等操作符。
```bash
grep -E '^(start|end)' file.txt
```
上述命令使用扩展正则表达式,搜索以"start"或"end"开始的行。使用`-E`选项开启了扩展正则表达式模式。
### 4.1.2 颜色高亮输出匹配内容
长时间处理搜索结果时,高亮显示匹配的内容可以提高工作效率。使用`--color=auto`选项,grep会在匹配到的内容上添加颜色标记。
```bash
grep --color=auto 'error' file.log
```
这个命令将在所有包含"error"的行上,自动为匹配到的"error"文字添加颜色,使得查找错误信息变得更为直观。
## 4.2 grep的上下文控制技巧
### 4.2.1 通过上下文行数来定位匹配信息
在处理日志文件或调试信息时,我们通常需要查看匹配行的上下文信息。grep允许我们通过`-A`, `-B`和`-C`选项来指定在匹配行前后显示的行数。
```bash
grep -A 2 'error' file.log
```
该命令会输出所有包含"error"的行以及其后的两行。如果要同时输出匹配行前的两行和匹配行本身,可以使用`-C`选项。
### 4.2.2 忽略二进制文件的搜索
在搜索文件时,有时会不小心包含了二进制文件,这可能导致搜索进程异常终止。我们可以使用`--binary-files=text`选项,强制grep将所有文件作为文本文件处理。
```bash
grep --binary-files=text 'pattern' *
```
使用`--binary-files=text`选项确保即使文件是二进制的,搜索进程也会将其作为普通文本处理,并报告未找到匹配项。
## 4.3 grep的性能优化
### 4.3.1 优化grep搜索速度的方法
使用`-F`选项可以将模式当作固定字符串来处理,这通常比解释正则表达式要快。特别是在搜索固定字符串时,使用`-F`选项可以提升性能。
```bash
grep -F 'exactstring' file.txt
```
上述命令在`file.txt`文件中搜索精确字符串"exactstring"。由于不涉及正则表达式的计算,性能上会有所提升。
### 4.3.2 针对大数据文件的搜索策略
当面对大型文件时,我们可以使用`-m`选项来限制grep搜索的次数。这对于大型日志文件的错误查找非常有用,可以避免grep长时间运行。
```bash
grep -m 10 'error' large.log
```
此命令搜索`large.log`文件中的"error"字符串,但是只返回找到的前10行匹配内容。
| 选项 | 含义 |
| --- | --- |
| -E | 使用扩展正则表达式 |
| --color=auto | 高亮显示匹配内容 |
| -A/B/C | 显示匹配行的后/前/前后N行 |
| --binary-files=text | 将二进制文件当作文本处理 |
| -F | 将模式视为固定字符串 |
| -m | 搜索最多N次匹配后停止 |
在使用grep时,我们可以结合这些高级选项和技巧,以便更高效地进行文本搜索。根据文件的大小、内容的复杂性和特定的搜索需求,选择合适的grep命令来优化搜索过程,可大大提高工作效率和满意度。在下一章节,我们将探讨grep的扩展工具以及如何将grep与其他文本处理工具结合使用,以进一步提升我们的文本处理能力。
# 5. grep的扩展工具和替代方案
## 5.1 基于grep的文本处理工具
### 5.1.1 ack和ag:grep的高效替代品
ack(Another Code Searcher)和ag(The Silver Searcher)是两个专门为代码搜索设计的工具,它们在很多方面改进了传统的grep,提供了更加快速和智能的搜索体验。ack专注于搜索代码,它默认排除了一些常见的非代码文件,如图片和编译生成的文件,这使得搜索结果更加干净,避免了不相关文件的干扰。
另一方面,ag不仅搜索代码,而且提供比grep更快的搜索速度和更好的用户体验。它通过并行处理和优化的搜索算法来实现这一点,同时它还提供了颜色高亮和更好的文件名匹配。
```shell
# 使用ack搜索特定的模式
ack 'error handling'
```
这段代码会在当前目录及其子目录下搜索包含"error handling"的代码文件。ack支持多种grep的选项,并且提供了很多自己特有的功能,比如递归搜索时不遍历.gitignore文件指定的目录。
### 5.1.2 ripgrep (rg):现代grep的替代者
ripgrep,简称rg,是另一款强大的grep替代工具,它的设计目标是比传统的grep更快,并且功能更加丰富。rg使用了许多现代搜索技术,比如更快的文件遍历和有效的grep正则表达式引擎,这让它在搜索速度上往往超过传统的grep和它的竞争者。
```shell
# 使用ripgrep搜索特定的模式
rg '\berror\b'
```
上述命令展示了ripgrep在搜索字符串时的精确匹配能力。在正则表达式中,`\b`表示单词边界,确保我们匹配的是"error"作为独立单词的情况。
ripgrep不仅仅在速度上有优势,在搜索过程中还能够进行智能的忽略,自动排除.gitignore和.hgignore中指定的目录和文件。
## 5.2 编写脚本增强grep功能
### 5.2.1 shell脚本中封装grep搜索逻辑
在很多情况下,我们可能会希望将grep的搜索逻辑封装到一个shell脚本中,以便于复用和自动化处理。这使得我们能够组合多个grep命令以及利用shell的其他功能,如循环、条件判断和管道等,来处理更复杂的搜索需求。
```shell
#!/bin/bash
# 封装的grep搜索逻辑脚本
search_content() {
echo "搜索包含特定文本的文件:"
grep -rn "$1" *
echo "---------------------------"
}
search_content '特定文本'
```
在上面的脚本中,`search_content`函数封装了搜索包含"特定文本"的命令。`-r`选项告诉grep进行递归搜索,`-n`则显示匹配行的行号。这个脚本可以对当前目录下的所有文件执行搜索,并打印出匹配的行号和内容。
### 5.2.2 通过Python等脚本语言扩展搜索能力
对于更复杂的搜索需求,shell脚本可能无法满足。此时,我们可以利用Python、Perl等语言强大的字符串处理能力和丰富的库来进行扩展。
```python
#!/usr/bin/env python3
import subprocess
import sys
def search_content(query):
try:
# 使用subprocess调用grep命令
result = subprocess.check_output(['grep', '-r', query, '.'])
print(result.decode())
except subprocess.CalledProcessError as e:
print(f"Error: {e}")
if __name__ == '__main__':
query = sys.argv[1]
search_content(query)
```
这个简单的Python脚本可以执行和shell脚本类似的搜索操作,但它允许我们通过Python的异常处理机制来增强错误处理。同时,Python的丰富库和数据处理能力允许我们进行更复杂的文本处理和分析。
## 5.3 处理grep不支持的复杂模式
### 5.3.1 使用Perl、Python正则表达式处理复杂模式
对于那些超出grep处理能力的复杂文本处理需求,比如复杂的多行模式匹配,我们可以转向Perl或Python这样的语言,它们提供了更为强大的正则表达式支持。
```python
import re
text = """多行字符串
跨越
多行的
文本"""
# Python中使用多行模式匹配
pattern = r'^.*\n.*\n.*$'
match = re.match(pattern, text, re.MULTILINE)
if match:
print("匹配成功:", match.group())
else:
print("没有匹配")
```
这段Python代码利用了re模块的`MULTILINE`标志来进行多行匹配。多行模式(`^`和`$`)可以匹配每一行的开始和结束位置。
### 5.3.2 高级文本处理工具的探索
最后,对于需要更高级文本处理能力的需求,可以探索一些专用工具如sed、awk等。这些工具虽然学习曲线较为陡峭,但是它们提供了灵活的文本处理能力,可以进行复杂的文本转换和报告生成。
```awk
#!/usr/bin/awk -f
# Awk脚本示例:对输入的文本进行格式化
BEGIN {
FS = ","; # 设置字段分隔符为逗号
}
{
for (i = 1; i <= NF; i++) {
printf("%s%s", $i, (i < NF ? ", " : "\n"));
}
}
```
在上述awk脚本中,我们定义了字段分隔符为逗号,并对每一行的每个字段进行了迭代,然后输出。Awk同样支持复杂的文本处理,包括条件语句、循环以及自定义的函数等高级功能。
# 6. 案例分析与实践建议
在这一章节中,我们将深入探讨如何应用grep在实际场景中的案例,同时提供一些针对使用中可能遇到问题的解决方案。最后,我们会讨论推荐的grep使用习惯,以提高工作效率。
## 6.1 常见文本搜索需求的案例分析
### 6.1.1 源代码中的搜索与维护
在软件开发过程中,源代码的管理和维护是一个持续不断的工作。使用grep可以快速找到代码中的特定模式,例如变量声明、函数调用等,这对于代码审查、重构或调试都至关重要。
#### 示例操作
假设我们想要查找所有在项目中使用了特定函数`processData()`的文件:
```bash
grep -rl "processData()" /path/to/project
```
这里,`-r`选项表示递归搜索整个目录,`-l`选项表示只列出包含匹配模式的文件名。
#### 案例分析
如果函数的使用非常广泛,简单的grep搜索可能会返回大量的结果。为了避免这种情况,可以结合使用`--exclude`选项排除特定目录,或者使用正则表达式更精确地限定搜索条件。
### 6.1.2 系统配置文件的批量修改
在系统管理中,经常需要对配置文件进行批量修改。grep配合其他工具,如sed或awk,可以实现高效准确的批量编辑。
#### 示例操作
假设我们需要更改`/etc`目录下所有配置文件中的`user=oldname`为`user=newname`:
```bash
grep -rl "user=oldname" /etc/ | xargs sed -i 's/user=oldname/user=newname/g'
```
这里,`xargs`接受grep的输出,并为每个文件执行sed命令,`-i`选项告诉sed直接修改文件内容。
## 6.2 grep使用中的常见问题与解决
### 6.2.1 正则表达式的坑点和注意事项
在使用grep进行搜索时,必须小心正则表达式的复杂性和潜在的问题。特殊字符可能会被误解释,而量词的使用也会导致不期望的匹配行为。
#### 注意事项
- 避免使用非转义的特殊字符,如`*`, `+`, `?`, `{`, `(`, `|`, `]`等,除非你确切知道它们的含义和用途。
- 在shell命令行中,需要对某些字符进行转义,比如反斜杠(`\`)。
- 确保正确匹配行的开始(`^`)和结束(`$`)。
### 6.2.2 避免grep在搜索中出现的性能问题
当搜索非常大的文件或者复杂的模式时,grep可能会运行得非常缓慢。
#### 性能优化建议
- 使用`--max-count`选项限制grep返回的结果数量,减少不必要的处理。
- 对于非常大的文本文件,可以先使用`split`命令将其分割成小文件,再进行搜索。
- 使用`--mmap`选项可以让grep利用内存映射技术来加速文件处理。
## 6.3 推荐的grep使用习惯和工作流
### 6.3.1 高效利用grep的技巧和快捷键
为了提高工作效率,应该记住一些grep的技巧和快捷键。
#### 技巧和快捷键
- 使用`egrep`或`grep -E`启用扩展正则表达式,简化复杂的表达式编写。
- 学会使用`grep -w`确保只匹配整个单词,避免部分匹配。
- 利用`grep -n`显示匹配行的行号,方便定位。
- 结合`Ctrl-R`在shell中快速回溯之前使用过的grep命令。
### 6.3.2 构建适合自己的文本搜索工作流
创建一个符合个人习惯的文本搜索工作流可以大大提高搜索效率。
#### 工作流构建
- 定义常用的grep命令别名,以便快速调用。
- 根据项目类型创建自定义的grep搜索模板,以适应不同需求。
- 利用shell脚本自动完成复杂的搜索任务,减少重复劳动。
通过本章的案例分析、问题解决以及工作流建议,你可以获得更深层次的grep使用知识,有效解决实际工作中的文本搜索问题,并提升工作效率。下一章节将介绍基于grep的扩展工具和替代方案,提供更多的搜索选项和工具选择。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Linux 中强大的文本搜索工具 grep,提供了从基本用法到高级技巧的全面指南。它涵盖了快速定位信息、提升搜索效率、使用正则表达式进行复杂匹配、跨文件搜索、优化模式、避免常见错误、扩展工具比较、性能优化、脚本编写、数据提取和转换等主题。此外,还提供了 grep 在数据处理、系统日志分析、真实世界问题解决、与其他文本工具协同以及代码审查中的应用案例,帮助读者掌握 grep 的方方面面,提升文本搜索和处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CPCI规范中文版避坑指南:解决常见问题,提升实施成功率

# 摘要
CPCI(CompactPCI)规范作为一种国际标准,已被广泛应用于工业和通信领域的系统集成中。本文首先概述了CPCI规范中文版的关键概念、定义及重要性,并比较了其与传统PCI技术的差异。接着,文章深入分析了中文版实施过程中的常见误区、挑战及成功与失败的案例。此外,本文还探讨了如何提升CPCI规范中文版实施成功率的策略,包括规范的深入理解和系统化管理。最后,文章对未来CPCI技术的发展趋势以及在
电池散热技术革新:高效解决方案的最新进展

# 摘要
电池散热技术对于保障电池性能和延长使用寿命至关重要,同时也面临诸多挑战。本文首先探讨了电池散热的理论基础,包括电池热产生的机理以及散热技术的分类和特性。接着,通过多个实践案例分析了创新散热技术的应用,如相变材料、热管技术和热界面材料,以及散热系统集成与优化的策略。最后,本文展望了未来电池散热技术的发展方向,包括可持续与环境友好型散热技术的探索、智能散热管理系统的设计以及跨学科技术融合的
【深入剖析Cadence波形功能】:提升电路设计效率与仿真精度的终极技巧

# 摘要
本文对Cadence波形功能进行了全面介绍,从基础操作到进阶开发,深入探讨了波形查看器的使用、波形信号的分析理论、仿真精度的优化实践、系统级波形分析以及用户定制化波形工具的开发。文中不仅详细解析了波形查看器的主要组件、基本操作方法和波形分析技巧,还着重讲解了仿真精度设置对波形数据精度的影
【数据库系统原理及应用教程第五版习题答案】:权威解读与实践应用指南
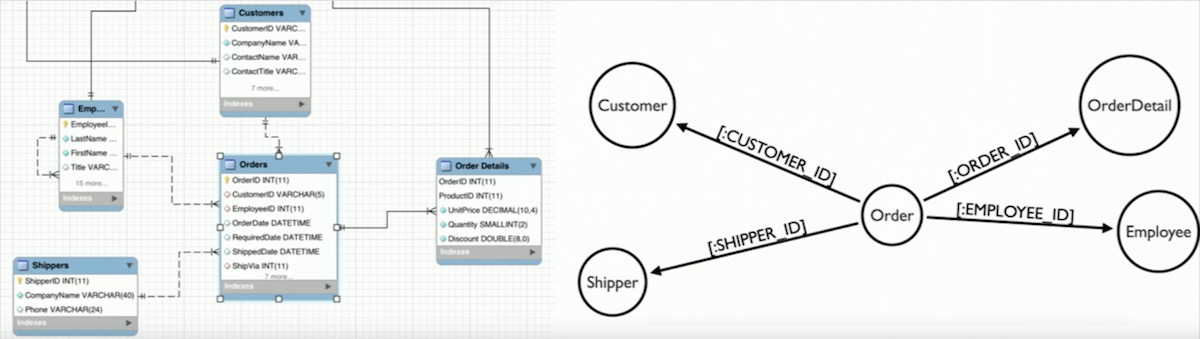
# 摘要
数据库系统是现代信息系统的核心,它在组织、存储、检索和管理数据方面发挥着至关重要的作用。本文首先概述了数据库系统的基本概念,随后深入探讨了关系数据库的理论基础,包括其数据结构、完整性约束、关系代数与演算以及SQL语言的详细解释。接着,文章着重讲述了数据库设计与规范化的过程,涵盖了需求分析、逻辑设计、规范化过程以及物理设计和性能优化。本文进一步分析了数据库管理系统的关键实现技术,例如存储引擎、事务处理、并发控制、备份与恢复技术。实践应用章
系统稳定运行秘诀:CS3000维护与监控指南

# 摘要
本文全面介绍CS3000系统的日常维护操作、性能监控与优化、故障诊断与应急响应以及安全防护与合规性。文章首先概述了CS3000系统的基本架构和功能,随后详述了系统维护的关键环节,包括健康检查、软件升级、备份与灾难恢复计划。在性能监控与优化章节中,讨论了有效监控工具的使用、性能数据的分析以及系统调优的实践案例。故障诊断与应急响应章节
HiGale数据压缩秘籍:如何节省存储成本并提高效率
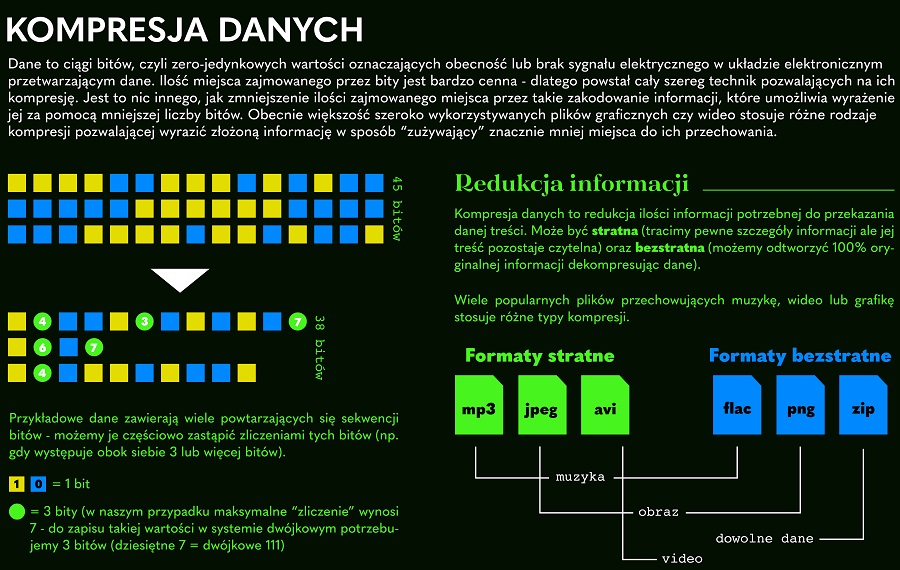
# 摘要
随着数据量的激增,数据压缩技术显得日益重要。HiGale数据压缩技术通过深入探讨数据压缩的理论基础和实践操作,提供了优化数据存储和传输的方法。本论文概述了数据冗余、压缩算法原理、压缩比和存储成本的关系,以及HiGale平台压缩工具的使用和压缩效果评估。文中还分析了数据压缩技术在
WMS功能扩展:适应变化业务需求的必备技能(业务敏捷,系统灵活)
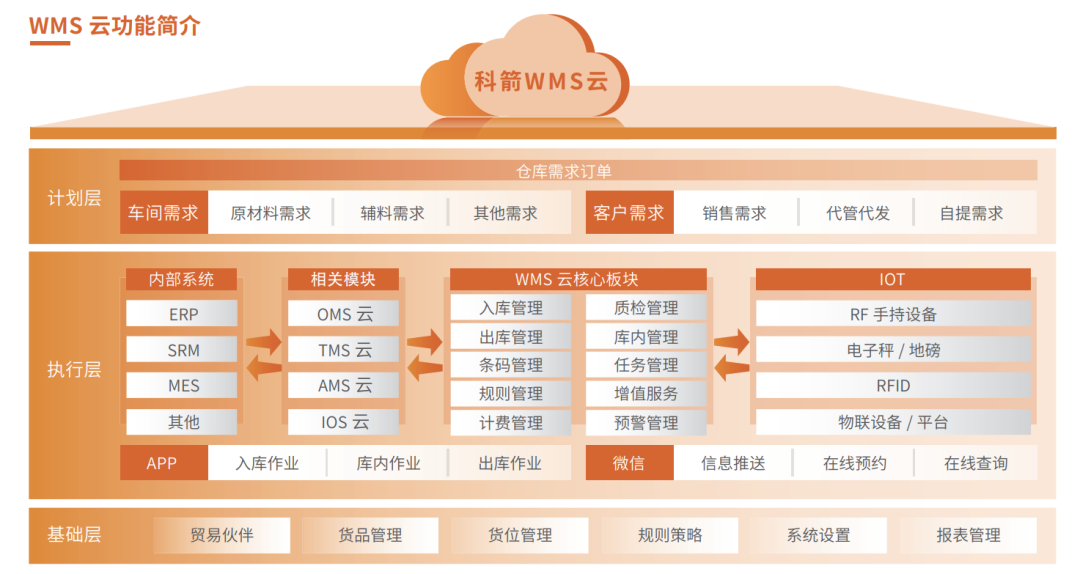
# 摘要
本文详细介绍了WMS系统的业务需求适应性及其对业务敏捷性的理论基础和实践策略。首先概述了WMS系统的基本概念及其与业务需求的匹配度。接着探讨了业务敏捷性的核心理念,并分析了提升敏捷性的方法,如灵活的工作流程设计和适应性管理。进一步,文章深入阐述了系统灵活性的关键技术实现,包括模块化设计、动态配置与扩展以及数据管理和服务化架构。在功能扩展方面,本文提供
【数据结构实例分析】:清华题中的应用案例,你也能成为专家
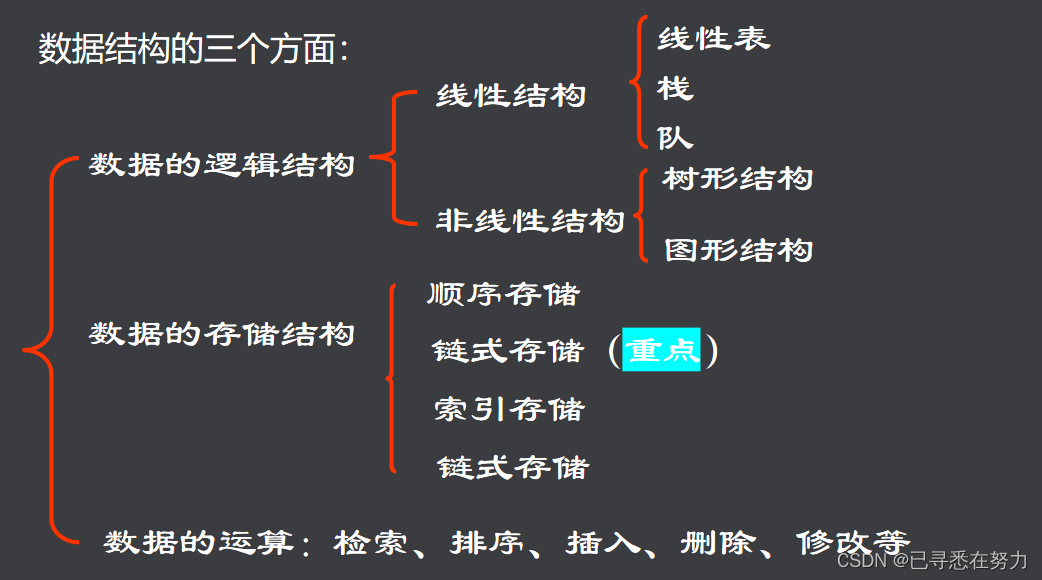
# 摘要
本文全面探讨了数据结构在解决复杂问题中的应用,特别是线性结构、树结构、图结构、散列表和字符串的综合应用。文章首先介绍了数据结构的基础知识,然后分别探讨了线性结构、树结构和图结构在处理特定问题中的理论基础和实战案例。特别地,针对线性结构,文中详细阐述了数组和链表的原理及其在清华题中的应用;树结构的分析深入到二叉树及其变种;图结构则涵盖了图的基本理论、算法和高级应用案例。在散列表和字符串综合应用章节,文章讨论了散列表设计原理、
【精密工程案例】:ASME Y14.5-2018在精密设计中的成功实施
# 摘要
ASME Y14.5-2018标准作为机械设计领域内的重要文件,为几何尺寸与公差(GD&T)提供了详细指导。本文首先概述了ASME Y14.5-2018标准,并从理论上对其进行了深入解析,包括GD&T的基本概念、术语定义及其在设计中的应用。接着,文章讨论了ASME Y14.5-2018在机械设计实际应用中的实施,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )