并行计算神器Dask:如何在Anaconda中处理大规模数据集
发布时间: 2024-12-09 23:49:08 阅读量: 5 订阅数: 12 
# 1. Dask简介及并行计算基础
## 1.1 Dask简介
Dask是一个灵活的并行计算库,用于数据分析和科学计算。它能够轻松扩展到多核心CPU或大型计算集群,并与现有的Python工具如NumPy、Pandas等无缝集成。Dask允许用户编写并行代码,而无需改变现有的代码结构,大大提高了数据处理的效率和规模。
## 1.2 并行计算基础
并行计算涉及同时使用多个计算资源来解决计算问题。在数据科学和分析领域,数据往往庞大到无法被单个计算机在合理的时间内处理。通过并行计算,可以将数据拆分成更小的部分,分发到不同的计算节点,然后并行处理,最后将结果整合起来。这样不仅提高了计算速度,还能够处理更大的数据集。
## 1.3 并行计算与Dask的优势
使用Dask进行并行计算的优势在于其设计的灵活性和扩展性。Dask可以运行在一台笔记本电脑上,也可以扩展到多台机器的集群。它通过抽象地表示计算任务,并动态地管理任务的执行,从而有效地调度工作负载,优化性能。此外,Dask还能够处理复杂的数据依赖性,并且能够恢复计算,这是在大规模数据处理中非常重要的特性。
# 2. 安装和配置Dask环境
## 2.1 Anaconda环境的准备工作
### 2.1.1 安装Anaconda和管理包
Anaconda是目前广泛使用的数据科学和机器学习环境,它内置了包括Dask在内的众多科学计算和数据处理包。安装Anaconda是开始使用Dask前的重要步骤。
首先,需要下载Anaconda的安装包。访问[Anaconda官网](https://www.anaconda.com/products/distribution)下载适合您操作系统的安装包。下载完成后,根据您的操作系统执行相应的安装程序。
以Windows系统为例,双击安装包后按照提示选择安装路径以及是否加入系统PATH环境变量,安装过程中一般建议选择“Add Anaconda to my PATH environment variable”以方便后续使用。安装完成后,打开Anaconda Prompt,可以通过命令`conda --version`来验证安装是否成功。
接下来是包管理,`conda`命令是Anaconda的核心,可以用来搜索、安装、更新和管理包。例如,更新Anaconda至最新版本可以使用:
```shell
conda update conda
```
安装特定包时,比如pandas,使用:
```shell
conda install pandas
```
包安装完成后,可以通过`conda list`来查看已安装的包。
### 2.1.2 环境创建与配置
为了保持项目环境的干净和独立,Anaconda允许我们创建多个环境。不同的项目可以运行在不同的环境中,互不干扰。
创建新环境使用`conda create`命令,例如创建一个名为`dask_env`的环境,并安装Dask和Pandas:
```shell
conda create -n dask_env dask pandas
```
创建环境后,需要激活该环境才能使用其中的包。在Windows下激活命令是:
```shell
conda activate dask_env
```
在激活的环境中运行Python,此时Python环境中已经安装了Dask和Pandas:
```python
python
import dask.dataframe as dd
```
如果导入没有问题,则说明Dask环境配置成功。
## 2.2 安装Dask及其依赖
### 2.2.1 使用conda进行安装
虽然在创建环境时已经安装了Dask,但有时可能需要单独安装或更新Dask。继续使用conda命令:
```shell
conda install dask
```
此命令将会下载并安装最新版本的Dask及其依赖项。如果需要安装特定版本,可以指定版本号:
```shell
conda install dask=2021.07.0
```
安装完成后,可以在Python环境中导入Dask来检查安装是否成功。
### 2.2.2 检查Dask安装与环境验证
验证安装的最好方式是在Python交互式环境中尝试导入Dask:
```python
import dask
# 如果Dask正确安装,则无任何输出
# 如果有问题,会抛出ImportError异常
```
此外,为了确保Dask环境配置正确,可以运行一些简单的Dask函数,例如,创建一个Dask DataFrame并打印其内容:
```python
import dask.dataframe as dd
# 创建一个空的Dask DataFrame作为示例
df = dd.from_pandas(pd.DataFrame(), npartitions=3)
# 尝试打印Dask DataFrame的内容
print(df.head())
```
如果没有错误发生,则说明Dask安装和环境配置成功。
## 2.3 Dask的基本概念与结构
### 2.3.1 了解Dask的核心组件
Dask的核心组件包括:
- **Dask Collection**:集合如DataFrame、Array、Bag和Delayed,它们允许并行处理大型数据集和复杂算法。
- **Dask schedulers**:调度器,如自动调度器(默认)和手动调度器,负责计算任务的执行计划并执行。
- **Dask Workers**:工作进程,负责实际的计算任务。
### 2.3.2 数据结构:Delayed和DataFrames
Dask的**Delayed**是对Python函数调用的延迟表示,它不会立即执行函数,而是构建一个任务图。这个功能特别有用,因为它允许Dask优化和并行化执行。
例如,计算两个数的和可以写为:
```python
from dask import delayed
def inc(x):
return x + 1
def add(x, y):
return x + y
# 使用delayed来延迟计算
d1 = delayed(inc)(1)
d2 = delayed(inc)(2)
d3 = delayed(add)(d1, d2)
# 计算最终结果
result = d3.compute()
print(result)
```
而**Dask DataFrame**则是为大规模数据集而设计的,它是Pandas DataFrame的一个并行化扩展。Dask DataFrame可以轻松地并行化Pandas的常见操作。
```python
import dask.dataframe as dd
import pandas as pd
# 创建Pandas DataFrame
pdf = pd.DataFrame({'x': range(1000000)})
# 将Pandas DataFrame转换为Dask DataFrame
ddf = dd.from_pandas(pdf, npartitions=10)
# 查看Dask DataFrame的信息
ddf.info()
```
通过将数据分块为多个分区,Dask DataFrame能够并行地处理数据,避免内存溢出,并充分利用多核处理器。
# 3. Dask在大规模数据集上的应用
## 3.1 Dask的并行计算原理
### 3.1.1 任务调度和执行
Dask 通过其计算图(Task Graphs)来管理任务调度和执行。每个计算图代表了一系列的依赖关系和操作,这些操作需要在数据上执行。Dask 在内部构建任务图时会创建任务的依赖关系,从而使得图中的每个节点(任务)仅在前驱任务完成后才开始执行。这种依赖跟踪确保了任务的执行顺序性,同时也允许并行化。
下面是Dask任务调度的一个基本示例:
```python
import dask
from dask import delayed
@delayed
def inc(x):
return x + 1
@delayed
def add(x, y):
return x + y
# 构建任务图
x = inc(1)
y = inc(2)
z = add(x, y)
# 执行任务图
result = dask.compute(z)
print(result)
```
在此示例中,`inc` 函数的两个实例 `x` 和 `y` 并不依赖彼此,因此它们可以并行执行。`add` 函数依赖于 `x` 和 `y` 的计算结果,因此 `add` 将在 `x` 和 `y` 都计算完毕之后执行。
### 3.1.2 内存管理和优化
Dask 的内存管理是高度优化的,它在本地内存中高效地移动数据,但也会涉及磁盘和网络内存,以便处理超出单台机器内存限制的大规模数据集。Dask 使用了称为“持久化数据结构”的概念,允许它在不同操作之间存储中间结果而不消耗额外的内存。
Dask 支持以下类型的内存管理技术:
- **内存溢出(Spilling to disk)**:当内存不足以存储所有中间数据时,Dask 可以将数据溢出到磁盘上。
- **数据压缩**:Dask 允许对存储在内存和磁盘上的数据进行压缩,以减少内存使用。
- **垃圾收集(Garbage Collection)**:Dask 实现了智能垃圾收集策略,它能够回收未使用的中间结果所占用的内存。
## 3.2 Dask处理大规模数据集的方法
### 3.2.1 Dask Array的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到《Anaconda科学计算库的安装与使用》专栏!本专栏将深入探讨Anaconda,一个用于科学计算和数据分析的强大平台。从快速入门指南到高级技巧,您将掌握Anaconda的各个方面。我们将涵盖conda命令行工具、Jupyter Notebook、SciPy和NumPy、Pandas、Matplotlib、Seaborn、Scikit-learn、TensorFlow和Keras,以及版本控制。无论是初学者还是经验丰富的专业人士,本专栏都将为您提供所需的知识和技能,以充分利用Anaconda在科学计算和数据分析中的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从零开始学Arduino:中文手册中的初学者30天速成指南

参考资源链接:[Arduino中文入门指南:从基础到高级教程](https://wenku.csdn.net/doc/6470036fd12cbe7ec3f619d6?spm=1055.2635.3001.10343)
# 1. Arduino基础入门
## 1.1 Arduino简介与应用场景
Arduino是一种简单易用的开源电子原型平台,旨在为艺术家、设计师、爱好者和任何
【进纸系统无忧维护】:施乐C5575打印流畅性保证秘籍
参考资源链接:[施乐C5575系列维修手册:版本1.0技术指南](https://wenku.csdn.net/doc/6412b768be7fbd1778d4a312?spm=1055.2635.3001.10343)
# 1. 施乐C5575打印机概述
## 1.1 设备定位与使用场景
施乐C5575打印机是施乐公司推出的彩色激光打印机,主要面向中高端商业打印需求。它以其高速打印、高质量输出和稳定性能在众多用户中赢得了良好的口碑。它适用于需要大量文档输出的办公室环境,能够满足日常工作中的打印、复印、扫描以及传真等多种功能需求。
## 1.2 设备特性概述
C5575搭载了先进的打印技术
六轴传感器ICM40607工作原理深度解读:关键知识点全覆盖
.png)
参考资源链接:[ICM40607六轴传感器中文资料翻译:无人机应用与特性详解](https://wenku.csdn.net/doc/6412b73ebe7fbd1778d499ae?spm=1055.2635.3001.10343)
# 1. 六轴传感器ICM40607概览
在现代的智能设备中,传感器扮演着至关重要的角色。六轴传感器ICM40607作为一款高精度、低功耗
【易语言爬虫进阶攻略】:网页数据处理,从抓取到清洗的全攻略

参考资源链接:[易语言爬取网页内容方法](https://wenku.csdn.net/doc/6412b6e7be7fbd1778
【C#统计学精髓】:标准偏差STDEV计算速成大法
参考资源链接:[C#计算标准偏差STDEV与CPK实战指南](https://wenku.csdn.net/doc/6412b70dbe7fbd1778d48ea1?spm=1055.2635.3001.10343)
# 1. C#中的统计学基础
在当今世界,无论是数据分析、机器学习还是人工智能,统计学的方法论始终贯穿其应用的核心。C#作为一种高级编程语言,不仅能够执行复杂的逻辑运算,还可以用来实现统计学的各种方法。理解C#中的统计学基础,是构建更高级数据处理和分析应用的前提。本章将先带你回顾统计学的一些基本原则,并解释在C#中如何应用这些原则。
## 1.1 统计学概念的C#实现
C#提
【CK803S处理器全方位攻略】:提升效率、性能与安全性的终极指南
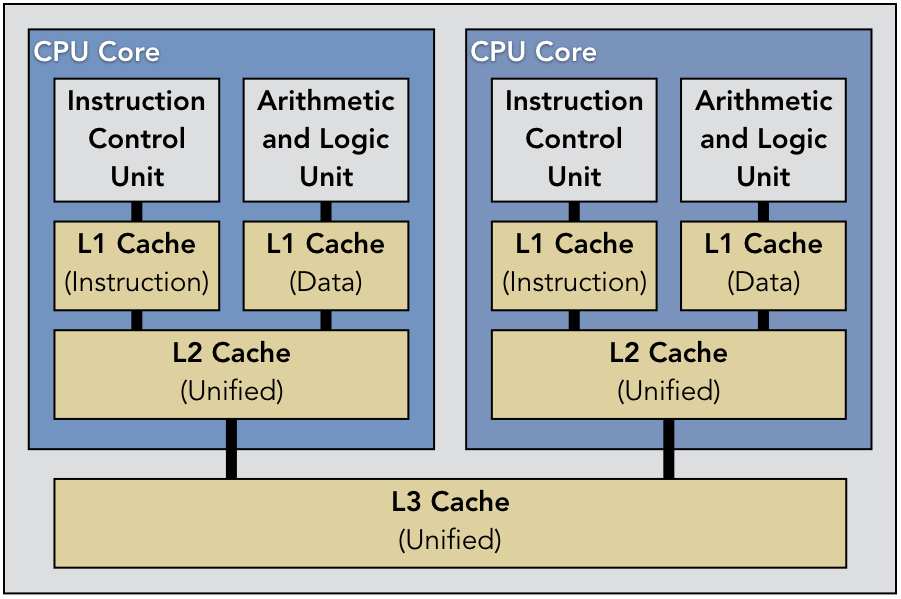
参考资源链接:[CK803S处理器用户手册:CPU架构与特性详解](https://wenku.csdn.net/doc/6uk2wn2huj?spm=1055.2635.3001.10343)
# 1. CK803S处理器概述
CK803S处理器是市场上备受瞩目的高性能解决方案,它结合了先进的工艺技术和创新的架构设计理念,旨在满足日益增长的计算需求。本章
STM32F407内存管理秘籍:内存映射与配置的终极指南

参考资源链接:[STM32F407 Cortex-M4 MCU 数据手册:高性能、低功耗特性](https://wenku.csdn.net/doc/64604c48543f8444888dcfb2?spm=1055.2635.3001.10343)
# 1. STM32F407微控制器简介与内存架构
STM32F407微控制器是ST公司生产的高性能ARM Cortex-M4核心系列之一,广泛应用
【性能调优的秘诀】:VPULSE参数如何决定你的系统表现?
参考资源链接:[Cadence IC5.1.41入门教程:vpulse参数解析](https://wenku.csdn.net/doc/220duveobq?spm=1055.2635.3001.10343)
# 1. VPULSE参数概述
VPULSE参数是影响系统性能的关键因素,它在IT和计算机科学领域扮演着重要角色。理解VPULSE的基本概念是进行系统优化、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )