




深度学习项目实战:Anaconda中的从理论到应用完整流程

1. 深度学习与Anaconda入门
深度学习是人工智能领域中一个重要的研究方向,它模拟了人脑的神经网络结构和功能,通过大规模的数据训练来实现复杂任务的自动学习和决策。然而,深度学习项目往往需要复杂的数据预处理、模型设计、参数调优和计算资源管理,这就要求我们掌握一些专业工具来辅助开发。Anaconda就是这样一个强大的工具,它不仅是一个Python包管理器,还是一个集成开发环境,为深度学习开发者提供了便捷的解决方案。
2.1 Anaconda的基础知识
Anaconda通过其包管理功能,能够让我们轻松安装和管理大量的Python包和依赖,从而让开发环境的搭建变得快捷。同时,Anaconda环境管理工具Conda可以让我们在不同的项目间切换不同的依赖版本,保证了项目的隔离性。
2.1.1 Anaconda的安装与配置
安装Anaconda相对简单,只需从官网下载对应操作系统的安装包,然后按照提示完成安装即可。安装完成后,通过命令行输入conda --version来检查是否安装成功。接下来,设置conda镜像源以加速包的下载速度。
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- conda config --set show_channel_urls yes
2.1.2 环境管理与版本控制
在进行深度学习项目时,往往需要针对不同项目设置独立的环境,这可以通过Conda创建和管理。例如,创建一个新的环境命名为dl_env并安装特定版本的Python和库。
- conda create -n dl_env python=3.8
- conda activate dl_env
通过以上步骤,我们就完成了一个针对深度学习项目的Anaconda基础配置,为后续的项目开发奠定了基础。
2. 搭建深度学习环境
2.1 Anaconda的基础知识
2.1.1 Anaconda的安装与配置
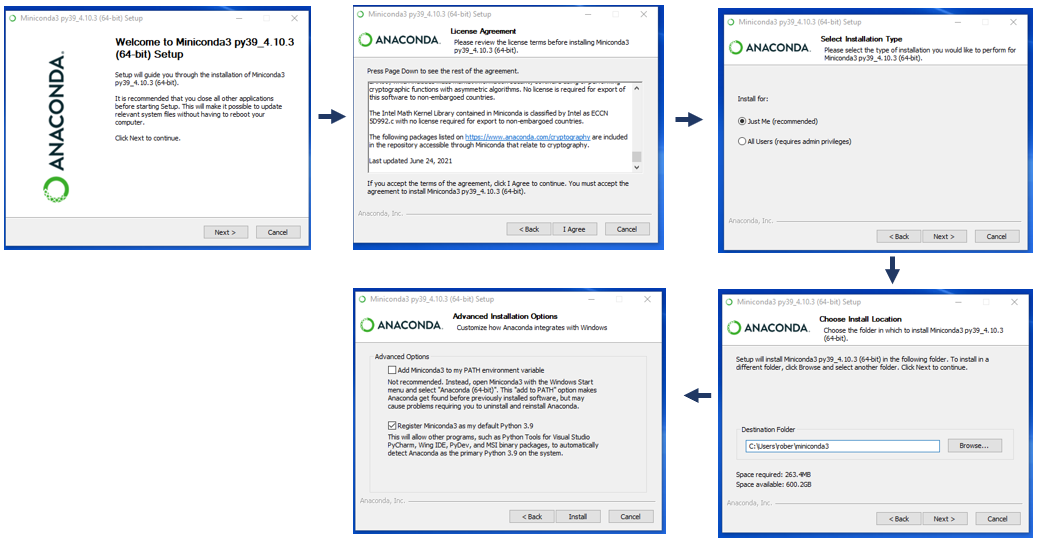
Anaconda是一个强大的包管理和环境管理工具,它使用起来简单方便,尤其适合在数据科学和机器学习领域的应用。首先需要从Anaconda官方网站下载与操作系统相匹配的安装包。接下来我们以Windows系统为例来说明Anaconda的安装与配置步骤。
-
安装Anaconda
- 打开下载的安装文件,双击运行,出现安装向导。
- 在安装向导中选择“Install for me only”以避免管理员权限问题。
- 选择安装路径,建议安装在非系统盘,以避免可能的权限问题。
- 在安装过程中选择“Add Anaconda to my PATH environment variable”并勾选“Register Anaconda as my default Python”选项。这样安装完成后可以直接使用Anaconda的命令行工具。
-
验证安装
- 打开一个新的命令提示符窗口,输入
conda --version。如果安装成功,系统将显示出当前安装的conda版本号。
- 打开一个新的命令提示符窗口,输入
2.1.2 环境管理与版本控制
Anaconda环境管理功能允许用户在同一台机器上安装多个版本的Python和包,而不影响彼此。这对于同时进行多个项目的开发者来说是一个非常实用的功能。
-
创建新环境
- 使用命令
conda create --name myenv python=3.8来创建一个名为myenv的环境,并指定Python版本为3.8。 - 激活新环境:在命令提示符输入
conda activate myenv。
- 使用命令
-
环境列表和管理
- 查看所有环境列表:
conda env list。 - 删除环境:
conda env remove --name myenv。
- 查看所有环境列表:
-
版本控制
- 安装包到当前环境:
conda install numpy。 - 指定版本安装包:
conda install numpy=1.19.2。 - 更新包:
conda update numpy。 - 搜索包:
conda search numpy。
- 安装包到当前环境:
2.1.2 环境管理与版本控制 - 示例
假设我们有一个使用Python 3.7开发的深度学习模型,现在需要在一个新项目中使用Python 3.8,并且希望两个项目互不影响。以下是如何使用conda进行环境的管理。
- # 创建一个Python 3.8的环境
- conda create --name mynewproject python=3.8
- # 激活新创建的环境
- conda activate mynewproject
- # 安装项目所需的包
- conda install tensorflow=2.3 numpy pandas
- # 检查当前环境中安装的包
- conda list
- # 在不离开当前环境的情况下,切换到主环境
- conda deactivate mynewproject
- conda activate base
2.2 深度学习项目的目录结构
2.2.1 数据集的组织与管理
在深度学习项目中,数据集的组织与管理是一项重要的任务。良好的数据管理可以提高数据处理和模型训练的效率。通常建议将数据集存放在项目的data子目录下。
下面是一个简单的数据集组织结构:
- myproject/
- |-- data/
- | |-- train/
- | | |-- class1/
- | | |-- class2/
- | | |-- ...
- | |-- validation/
- | |-- test/
- | |-- README.md
在这个结构中,train、validation和test分别代表训练集、验证集和测试集目录。每个类别的数据集存放在单独的子目录下,这样方便管理和使用。README.md文件包含了数据集的元信息,例如数据来源、数据量、类别说明等。
2.2.2 代码和文档的存放规范
良好的代码组织可以使得项目更加清晰易懂,便于维护。下面是一个推荐的项目代码存放结构:
- myproject/
- |-- src/
- | |-- models/
- | | |-- __init__.py
- | | |-- model1.py
- | | |-- model2.py
- | |-- utils/
- | | |-- __init__.py
- | | |-- helper1.py
- | | |-- helper2.py
- | |-- main.py
- |-- tests/
- | |-- test_model1.py
- |-- requirements.txt
- |-- README.md
- |-- setup.py
在这个结构中,src目录存放源代码,包含models和utils子目录,分别用于存放模型定义和工具函数。main.py是项目的主要执行脚本。tests目录包含单元测试。requirements.txt记录项目依赖,通过运行pip install -r requirements.txt来安装依赖。setup.py用于将项目打包,方便其他用户安装使用。
2.2.2 代码和文档的存放规范 - mermaid流程图示例
利用mermaid流程图,可以清晰展示项目代码和文档结构的组织关系:
这个流程图清晰地描绘出了项目源代码、测试、依赖管理和文档的组织结构。
2.3 深度学习框架的选择与安装
2.3.1 TensorFlow和PyTorch的对比
TensorFlow和PyTorch是目前最受欢迎的深度学习框架,两者各有优劣。
TensorFlow由Google开发,具有以下特点:
- 它强调生产环境的可扩展性。
- 支持多种平台和硬件。
- 强大的社区和生态系统支持。
- 初始学习曲线相对较陡峭。
PyTorch由Facebook的AI研究团队开发,它注重灵活性和易用性:
- 它使用动态计算图,有助于实验和快速原型开发。
- 代码可读性好,易于调试。
- 社区和生态系统增长迅速。
选择哪个框架取决于项目需求、团队熟悉度以及未来扩展计划。
2.3.2 框架的安装及验证
安装TensorFlow或PyT

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入揭秘:构建稳定Socket连接的六大关键要素
【Linux系统入门者指南】:RedHat下的KDE桌面环境安装速成
【GTZAN音频分析秘籍】:20个实用技巧提升你的音频分类技能(入门到精通)
云原生应用性能调优:深度解析与优化技巧
确保航天器姿态控制系统安全与可靠:4大保障措施
【算法对决:二维装箱问题的传统与现代技术对比】
SC16IS752_SC16IS762驱动开发实战:编写稳定高效的驱动程序
帝国时代3-CS版数据修改与网络安全:防护策略与应对措施
QCRIL初始化过程深度解读:Android通信起点的权威指南
结构方程模型案例精研:Amos解决实际问题的策略与技巧


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















