Python count()函数在推荐系统中的神奇应用:个性化推荐与用户画像,提升用户体验
发布时间: 2024-06-25 06:01:45 阅读量: 6 订阅数: 13 

# 1. Python count() 函数基础**
count() 函数是 Python 中一个内置函数,用于计算一个序列中指定元素出现的次数。其语法如下:
```python
count(element)
```
其中,element 为要查找的元素。count() 函数返回一个整数,表示 element 在序列中出现的次数。
count() 函数可以用于各种序列,包括列表、元组、字符串和字典。对于字典,count() 函数返回指定键出现的次数。例如:
```python
my_list = [1, 2, 3, 4, 5, 1, 2, 3]
print(my_list.count(2)) # 输出:2
```
# 2. count() 函数在推荐系统中的应用
**2.1 个性化推荐中的应用**
count() 函数在个性化推荐系统中扮演着至关重要的角色,它可以帮助系统理解用户行为,并根据这些行为提供个性化的推荐。
**2.1.1 基于用户行为的推荐**
基于用户行为的推荐系统通过跟踪用户的历史行为(例如,观看过的电影、购买过的商品)来了解用户的兴趣。count() 函数可以用来计算用户对特定项目(例如,电影、商品)的交互次数,从而识别出用户最喜欢的项目。这些信息可以用来向用户推荐与他们过去喜欢的项目类似的项目。
**代码块:**
```python
def recommend_movies_based_on_user_behavior(user_id):
"""
基于用户行为推荐电影。
参数:
user_id: 用户 ID。
返回:
推荐的电影列表。
"""
# 获取用户观看过的电影列表。
watched_movies = get_user_watched_movies(user_id)
# 统计用户观看每部电影的次数。
movie_counts = {}
for movie in watched_movies:
if movie not in movie_counts:
movie_counts[movie] = 0
movie_counts[movie] += 1
# 根据观看次数对电影进行排序。
sorted_movies = sorted(movie_counts.items(), key=lambda x: x[1], reverse=True)
# 推荐前 10 部电影。
recommended_movies = [movie for movie, count in sorted_movies[:10]]
return recommended_movies
```
**逻辑分析:**
* `get_user_watched_movies()` 函数获取用户观看过的电影列表。
* 循环遍历观看过的电影列表,并使用 `count()` 函数统计用户观看每部电影的次数。
* 将电影及其观看次数存储在 `movie_counts` 字典中。
* 使用 `sorted()` 函数根据观看次数对电影进行排序。
* 返回前 10 部观看次数最多的电影作为推荐结果。
**2.1.2 基于协同过滤的推荐**
基于协同过滤的推荐系统通过分析用户之间的相似性来推荐项目。count() 函数可以用来计算用户之间对特定项目的共同交互次数,从而识别出相似的用户。这些信息可以用来向用户推荐与他们相似用户喜欢的项目。
**代码块:**
```python
def recommend_movies_based_on_collaborative_filtering(user_id):
"""
基于协同过滤推荐电影。
参数:
user_id: 用户 ID。
返回:
推荐的电影列表。
"""
# 获取与用户相似的用户列表。
similar_users = get_similar_users(user_id)
# 统计相似用户观看每部电影的次数。
movie_counts = {}
for similar_user in similar_users:
watched_movies = get_user_watched_movies(similar_user)
for movie in watched_movies:
if movie not in movie_counts:
movie_counts[movie] = 0
movie_counts[movie] += 1
# 根据观看次数对电影进行排序。
sorted_movies = sorted(movie_counts.items(), key=lambda x: x[1], reverse=True)
# 推荐前 10 部电影。
recommended_movies = [movie for movie, count in sorted_movies[:10]]
return recommended_movies
```
**逻辑分析:**
* `get_similar_users()` 函数获取与用户相似的用户列表。
* 循环遍历相似的用户列表,并获取每个用户观看过的电影列表。
* 使用 `count()` 函数统计相似用户观看每部电影的次数。
* 将电影及其观看次数存储在 `movie_counts` 字典中。
* 使用 `sorted()` 函数根据观看次数对电影进行排序。
* 返回前 10 部观看次数最多的电影作为推荐结果。
**2.2 用户画像中的应用**
count() 函数在用户画像中也发挥着重要作用,它可以帮助系统分析用户的兴趣和行为模式。
**2.2.1 用户兴趣分析**
用户兴趣分析可以帮助系统了解用户的兴趣领域。count() 函数可以用来计算用户对特定类别(例如,电影类型、新闻类别)的交互次数,从而识别出用户的兴趣领域。这些信息可以用来向用户推荐与他们兴趣领域相关的项目。
**代码块:**
```python
def analyze_user_interests(user_id):
"""
分析用户兴趣。
参数:
user_id: 用户 ID。
返回:
用户兴趣列表。
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Python 中的 count() 函数是一个强大的工具,可用于各种计数任务。本专栏深入探讨了 count() 函数的方方面面,从基本用法到高级技巧,再到性能优化和常见错误。通过 10 个经典案例和深入的分析,专栏揭示了 count() 函数在数据分析、机器学习、Web 开发、系统运维、科学计算、图像处理、自然语言处理、生物信息学、金融分析、社交网络分析、推荐系统、云计算和移动开发等领域的广泛应用。通过掌握 count() 函数的奥秘,读者可以提升编程效率,解决复杂的计数难题,并从数据中挖掘有价值的见解。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】通过强化学习优化能源管理系统实战
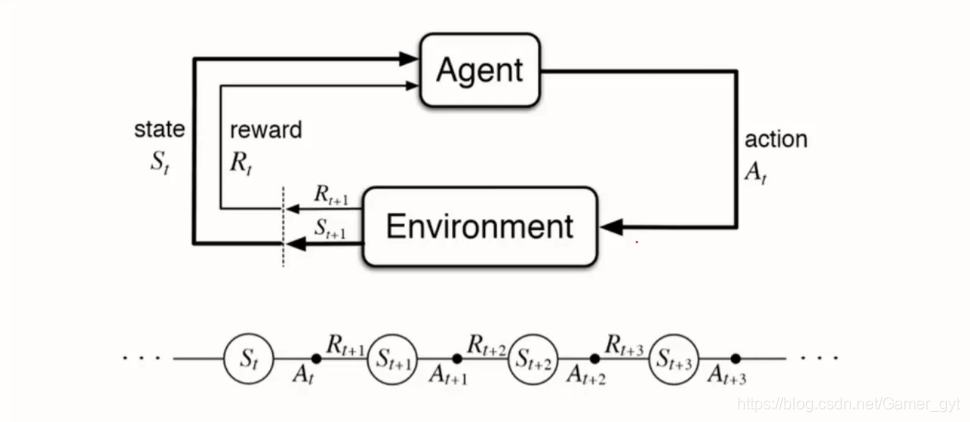
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】python云数据库部署:从选择到实施
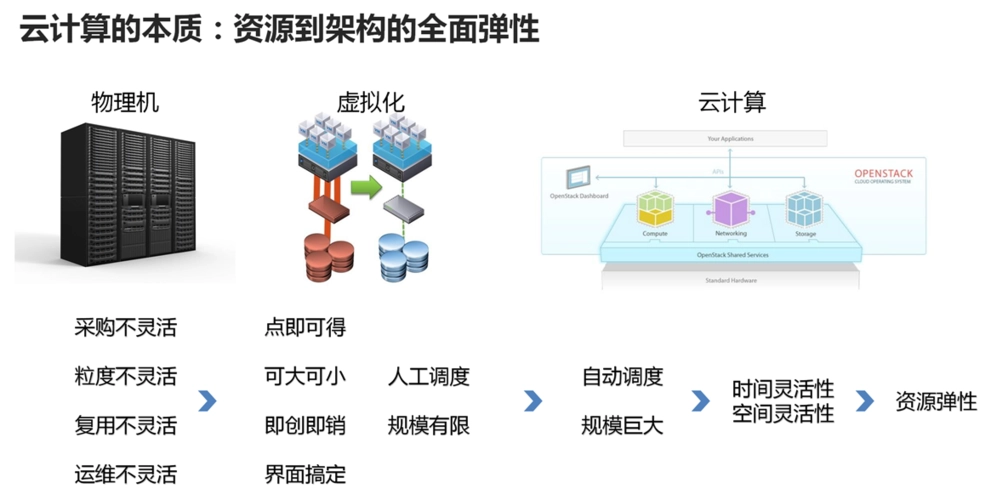
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】python远程工具包paramiko使用
# 1. Python远程工具包Paramiko简介**
Paramiko是一个用于Python的SSH2协议的库,它提供了对远程服务器的连接、命令执行和文件传输等功能。Paramiko可以广泛应用于自动化任务、系统管理和网络安全等领域。
# 2. Paramiko基础
### 2.1 Paramiko的安装和配置
**安装 Paramiko**
```python
pip install
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】使用Docker与Kubernetes进行容器化管理
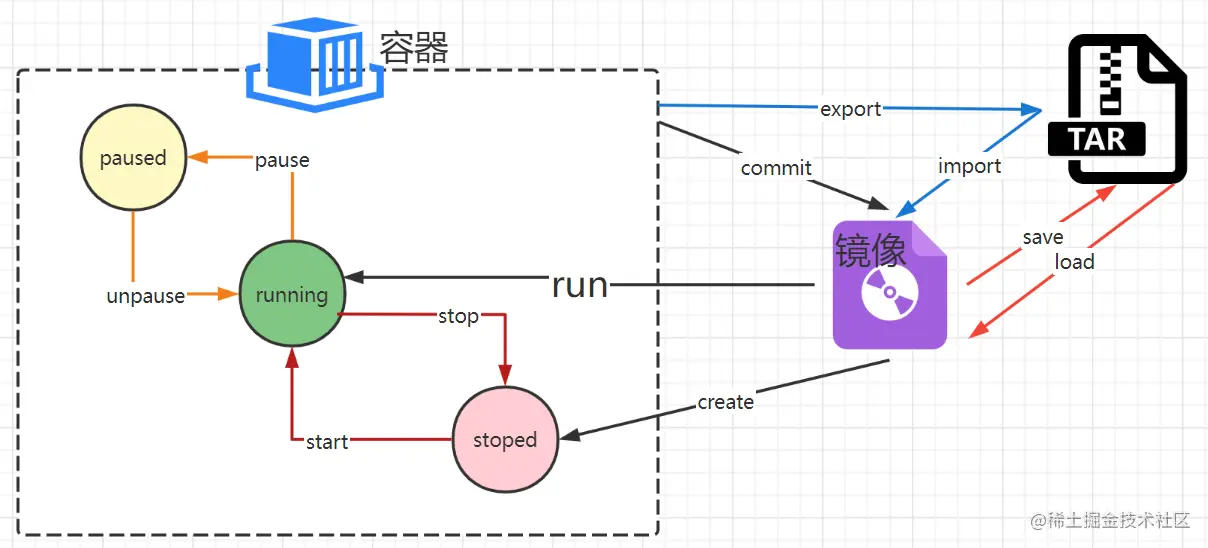
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】使用Python和Tweepy开发Twitter自动化机器人

# 1. Twitter自动化机器人概述**
Twitter自动化机器人是一种软件程序,可自动执行在Twitter平台上的任务,例如发布推文、回复提及和关注用户。它们被广泛用于营销、客户服务和研究等各种目的。
自动化机器人可以帮助企业和个人节省时间和精力,同时提高其Twitter活动的效率。它们还可以用于执行复杂的任务,例如分析推文情绪或
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )