双链表的Java实现细节:从基础到高级应用的全面解析
发布时间: 2024-09-11 09:33:48 阅读量: 49 订阅数: 21 

Java中高级核心知识全面解析

# 1. 双链表的基本概念与结构
双链表是一种高级的线性数据结构,它由一系列节点组成,每个节点都包含数据部分和两个指针,分别指向前一个节点和后一个节点。这种结构允许数据在两个方向上进行遍历,为双链表的操作提供了灵活性和多样性。
## 1.1 双链表的定义
在双链表中,每个节点的结构通常包含三个主要部分:存储数据的值,以及两个用于指向前驱节点(previous)和后继节点(next)的引用。这种结构允许我们轻松地实现双向遍历。
```java
class ListNode {
int val;
ListNode prev;
ListNode next;
ListNode(int x) { val = x; }
}
```
## 1.2 双链表与单链表的比较
相较于单链表,双链表的优势在于可以双向遍历。这在某些应用场景中非常有用,比如需要高效地在链表头部或尾部插入和删除元素时。然而,这种额外的灵活性是以牺牲内存为代价的,因为每个节点都需要维护额外的指针信息。
## 1.3 双链表的应用场景
双链表适用于实现缓存机制(如LRU缓存),因为它能够有效地支持快速的元素查找和删除操作。在实现复杂的数据结构如优先队列时,双链表也非常有用,因为其双向链接的特性可以方便地访问前后元素。
# 2. 双链表的Java基础实现
双链表是一种复杂的线性数据结构,与单链表相比,它在每个节点上都额外包含了指向前驱节点的引用。这种结构使得双链表在某些操作上更加高效,如反向遍历和在节点前插入新节点等。接下来,我们将探索如何使用Java实现一个基础的双链表。
## 2.1 节点类的设计与实现
### 2.1.1 节点类的基本结构
在Java中,双链表的实现首先需要定义一个节点类,该类包含三个属性:节点值、指向下一个节点的引用以及指向前一个节点的引用。
```java
class Node<T> {
private T data;
private Node<T> next;
private Node<T> prev;
public Node(T data) {
this.data = data;
this.next = null;
this.prev = null;
}
// Getters and setters for data, next, and prev
}
```
在这个基础的节点类实现中,我们定义了一个泛型方法,这允许双链表存储任何类型的数据。每个节点都有三个方法来获取或设置其值、后继节点或前驱节点。
### 2.1.2 节点间的链接方法
节点间的链接是双链表能够正常工作的重要部分。我们将创建方法来设置节点的`next`和`prev`引用:
```java
public void setNext(Node<T> nextNode) {
this.next = nextNode;
}
public void setPrev(Node<T> prevNode) {
this.prev = prevNode;
}
```
通过这种方式,我们可以在双链表中任意添加或删除节点,而不会造成链表的断裂。
## 2.2 双链表的核心操作
### 2.2.1 添加和删除节点
添加和删除节点是双链表的基本操作。以下是添加节点和删除节点的方法实现:
```java
public void addNode(Node<T> node) {
// Add node at the end of the list
// 1. Find the last node
// 2. Link the last node and the new node
// 3. Update the last node reference
}
public void deleteNode(Node<T> node) {
// Delete the given node from the list
// 1. Find the node before the given node
// 2. Update the references for the nodes before and after the given node
// 3. Handle special cases (list empty or node not found)
}
```
这些方法需要仔细设计以确保不会破坏链表的完整性。
### 2.2.2 搜索和遍历算法
搜索和遍历是双链表操作中常见的需求。对于搜索,我们需要遍历链表并比较每个节点的数据值:
```java
public Node<T> searchNode(T data) {
// Iterate through the list and compare the data with the given data
// Return the node or null if not found
}
```
遍历可以是双向的(向前或向后),取决于具体的需求。
## 2.3 双链表的异常处理和边界情况
### 2.3.1 空指针和越界异常处理
在操作双链表时,空指针和越界异常是常见的问题。我们需要在代码中妥善处理这些潜在异常:
```java
try {
// Code that may throw NullPointerException or IndexOutOfBoundsException
} catch (NullPointerException e) {
// Handle the case where a null pointer is encountered
} catch (IndexOutOfBoundsException e) {
// Handle the case where an index is out of bounds
}
```
通过捕获并处理这些异常,我们的代码可以更加健壮,减少运行时错误的可能性。
### 2.3.2 双链表的边界情况讨论
双链表在特定条件下会出现边界情况,如删除仅有的一个节点、在空链表上进行操作等。我们需要在实现中考虑这些情况,并给出明确的处理方法:
```java
if (isEmpty()) {
// Handle the case where the list is empty
} else if (size() == 1) {
// Handle the case where only one node is present
}
```
通过详细处理这些边界情况,双链表的实现更加可靠和健壮。
# 3. 双链表的高级操作和特性
在本章中,我们将深入探讨双链表的高级操作和特性,这些内容将扩展我们对双链表结构的理解,并揭示其在复杂数据结构场景下的应用潜力。我们将详细分析双链表的排序和合并技术、复制与克隆方法,以及与其他数据结构之间的转换策略。
## 3.1 双链表的排序和合并
### 3.1.1 排序算法在双链表中的应用
双链表作为一个灵活的数据结构,其在排序操作上的应用与数组或其他线性结构略有不同。双链表的排序往往需要调整节点间的指针链接,而不是像数组那样进行元素交换。一个常见且高效的排序算法是归并排序,它非常适用于双链表结构,因为归并排序在递归合并阶段能够很好地利用链表的非连续存储特性。
### 3.1.2 双链表的合并操作
合并两个有序的双链表是双链表操作中的一个经典问题。该操作利用了双链表已经排序的特性,通过比较头节点的值来决定哪个链表的头节点应该作为合并后链表的下一个节点。这样,我们就可以保持整个合并过程的有序性,同时仅通过调整指针来完成整个链表的合并,这对于内存使用和时间效率来说都是有利的。
```java
class ListNode {
int val;
ListNode prev;
ListNode next;
ListNode(int val) {
this.val = val;
}
}
public class LinkedListMerge {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(0);
ListNode current = dummy;
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
current.next = l1;
l1.prev = current;
l1 = l1.next;
} else {
current.next = l2;
l2.prev = current;
l2 = l2.next;
}
current = current.next;
}
if (l1 == null) current.next = l2;
if (l2 == null) current.next = l1;
return dummy.next;
}
}
```
在上述代码中,我们创建了一个辅助节点 `dummy` 来简化边界情况的处理。我们将 `l1` 和 `l2` 两个链表中较小的节点依次连接到 `current` 后面,直到其中一条链表为空。最后,我们将非空的链表连接到 `current` 的后面。这样,我们就得到了一个合并后的有序双链表。
## 3.2 双链表的复制与克隆
### 3.2.1 深拷贝与浅拷贝的区别
在进行双链表的复制操作时,我们需要区分深拷贝和浅拷贝两种不同的方式。浅拷贝仅复制了节点对象的引用,而深拷贝则会复制节点对象本身,创建一个全新的双链表副本。深拷贝要求双链表的节点对象必须是可复制的,也就是说,节点类需要实现 `Cloneable` 接口并重写 `clone()` 方法。
### 3.2.2 双链表对象克隆的实现
要在 Java 中实现双链表的深拷贝,我们需要在 `ListNode` 类中重写 `clone()` 方法。实现时,我们首先调用 `super.clone()` 获取当前节点的一个浅拷贝,然后递归地对节点的 `next` 和 `prev` 指针指向的节点进行克隆,直到所有节点都被复制。
```java
class ListNode implements Cloneable {
int val;
ListNode prev;
ListNode next;
ListNode(int val) {
this.val = val;
}
@Override
public ListNode clone() throws CloneNotSupportedException {
ListNode cloned = (ListNode) super.clone();
if (this.next != null) {
cloned.next = this.next.clone();
cloned.next.prev = cloned;
}
if (this.prev != null) {
cloned.prev = this.prev.clone();
cloned.prev.next = cloned;
}
return cloned;
}
}
public class LinkedListClone {
public ListNode deepClone(ListNode head) {
if (head == null) return null;
try {
return head.clone();
} catch (CloneNotSupportedException e) {
throw new AssertionError(); // Cannot happen
}
}
}
```
在这个实现中,我们对 `ListNode` 类进行了扩展,增加了深拷贝的支持。`deepClone` 方法用于复制整个双链表,递归调用节点的 `clone()` 方法。需要注意的是,克隆后的节点的 `prev` 和 `next` 需要重新指向它们的新实例,因为它们是克隆过程中新创建的节点。
## 3.3 双链表与其他数据结构的转换
### 3.3.1 双链表与数组的转换方法
在某些情况下,我们需要将双链表数据转移到数组结构中,或者相反。转换的关键在于理解数据的线性遍历,特别是当双链表是有序的时候。数组转双链表相对简单,只需要从数组的两端开始,交替插入新节点到双链表头部即可。
双链表转数组则需要顺序遍历双链表,将每个节点的值依次添加到数组中。对于双向链表,我们可以选择从头节点或尾节点开始遍历。
### 3.3.2 双链表与栈、队列的接口设计
虽然栈和队列具有不同的数据存取规则,但它们都可以使用双链表实现。栈通常实现为后进先出(LIFO),因此我们仅需要一个双链表的头部或尾部作为栈顶。队列实现为先进先出(FIFO),我们可以将双链表的头部作为队首,尾部作为队尾,从而实现队列的操作。
双链表与栈、队列的接口设计依赖于对应的数据结构操作规范,如栈的 `push()`、`pop()`、`peek()` 方法,以及队列的 `enqueue()`、`dequeue()`、`peek()` 方法。这些方法的实现将依赖于双链表的基本操作,如节点的插入和删除。
在双链表与其他数据结构的转换及接口设计中,我们探讨了如何利用双链表的灵活性来适应不同数据结构的需求。通过高级操作和特性,双链表能更好地适应复杂的应用场景,提供更加丰富和强大的数据管理功能。
在下一章节中,我们将研究双链表在实际项目中的应用,特别是其在缓存系统、多线程环境以及游戏开发中的关键作用。
# 4. 双链表在实际项目中的应用
## 4.1 双链表在缓存系统中的应用
### 4.1.1 LRU缓存与双链表
在缓存系统中,双链表的使用尤为显著,特别是在实现最近最少使用(LRU)缓存机制时。LRU缓存通过淘汰最长时间未被访问的数据项来维持缓存数据的新鲜度,这种算法需要快速访问数据项和有序管理数据项。
双链表在这种场景下扮演了关键角色,因为它能够在常数时间内完成从列表的两端插入和删除操作。在双链表的两端,我们可以维护两个指针:`head` 指向最近最少被访问的节点,`tail` 指向最近被访问的节点。当访问某个节点时,它会被移动到`tail`端,表示最近被访问。当需要淘汰一个节点时,位于`head`端的节点就是被淘汰的对象。
在Java中,我们可以实现一个双向链表的LRU缓存结构如下:
```java
public class LRUCache {
private Map<Integer, Node> cache;
private Node head;
private Node tail;
private int size;
private int capacity;
public LRUCache(int capacity) {
this.capacity = capacity;
this.size = 0;
this.cache = new HashMap<>();
// 初始化一个哨兵节点,不存储数据,只用于辅助操作
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
}
public int get(int key) {
Node node = cache.get(key);
if (node == null) {
return -1;
}
// 访问节点后,将其移动到链表尾部
moveToTail(node);
return node.value;
}
public void put(int key, int value) {
Node node = cache.get(key);
if (node == null) {
Node newNode = new Node(key, value);
cache.put(key, newNode);
addNode(newNode);
size++;
if (size > capacity) {
Node lru = popHead();
cache.remove(lru.key);
size--;
}
} else {
// 更新节点值,并将其移动到链表尾部
node.value = value;
moveToTail(node);
}
}
private void addNode(Node node) {
// 插入节点到链表尾部
// ...
}
private void removeNode(Node node) {
// 从链表中删除节点
// ...
}
private void moveToTail(Node node) {
// 移动节点到链表尾部
// ...
}
private Node popHead() {
// 移除并返回链表头部节点
// ...
}
}
```
在这个类中,我们使用`Node`类来表示双链表中的节点。双链表的操作包括将节点添加到尾部、从头部移除节点等,这些操作帮助我们维护LRU缓存的顺序。
### 4.1.2 实际应用中的性能优化
在实际应用中,双链表结合哈希表(如上例中的`cache`映射)可以显著提高LRU缓存的性能。哈希表提供了O(1)时间复杂度的键值查找,而双链表则提供了有序访问。当需要访问或者插入数据时,我们首先通过哈希表定位到双链表中的节点,然后根据需要进行链表操作。
LRU缓存的性能优化主要包括两个方面:
1. **内存利用率**:使用双链表可以有效管理内存的使用,因为它允许快速淘汰旧数据,保持数据的新鲜度。
2. **访问效率**:结合哈希表可以实现快速的数据访问,使得整个缓存系统的响应时间维持在较低水平。
在实际系统中,这种结构往往需要进一步优化,例如利用分页技术减少内存占用,或者使用并发集合(如`ConcurrentHashMap`)来支持多线程环境。
## 4.2 双链表在多线程环境中的应用
### 4.2.1 同步双链表的实现
在多线程环境中,双链表的实现需要特别考虑线程安全问题。当多个线程需要访问和修改双链表时,不恰当的实现可能会导致数据不一致或者性能下降。因此,同步双链表的实现通常需要使用锁机制来保证线程安全。
例如,我们可以在双链表的每个操作方法中添加同步关键字`synchronized`,以确保任何时刻只有一个线程能够执行这些操作。
```java
public synchronized void addNode(Node node) {
// ...
}
public synchronized void removeNode(Node node) {
// ...
}
public synchronized int get(int key) {
// ...
}
public synchronized void put(int key, int value) {
// ...
}
```
然而,这种粗粒度的锁策略可能会导致较大的性能开销,因为即使是对链表的不同部分的访问也会导致等待。为了提高性能,可以使用读写锁(如`ReentrantReadWriteLock`)来区分读写操作,允许多个读操作同时进行,而写操作则需要独占锁。
### 4.2.2 线程安全问题与解决方案
使用锁机制来实现线程安全的双链表虽然有效,但可能会引入死锁和活锁的问题。例如,在极端情况下,两个线程可能会分别持有不同部分的锁,同时等待对方释放锁,导致死锁。
为了解决这些问题,通常可以采取以下措施:
1. **避免嵌套锁**:确保所有线程按照相同的顺序获取锁,可以减少死锁的风险。
2. **锁分离**:使用读写锁可以提高并发性能,但要确保写操作之间不会发生冲突。
3. **锁粗化**:如果一系列的操作总是被一起执行,那么可以将它们合并为一个大的同步块,减少锁的开销。
4. **锁细粒度化**:如果可以的话,将数据结构切分成更小的部分,每个部分使用独立的锁。
对于双链表,这些措施可以帮助我们在保证线程安全的同时,尽可能地提高多线程操作的性能。当然,合理的设计和权衡也非常关键,这通常需要对应用场景有深入的理解。
## 4.3 双链表在游戏开发中的应用
### 4.3.1 游戏中的资源管理
在游戏开发中,双链表可以用来高效管理游戏资源。例如,在一个游戏中,我们可能需要频繁地加载和卸载游戏场景、模型、纹理等资源。由于这些资源的使用存在复杂的依赖关系和生命周期管理,使用双链表可以帮助我们更加灵活地处理这些资源的加载和卸载顺序。
在资源的加载过程中,我们可以在双链表中创建资源节点,并按照加载顺序连接这些节点。当需要卸载资源时,可以从链表尾部开始,按照先加载先卸载的原则,逐个清理节点。这种后进先出(LIFO)的方式非常适合游戏场景中资源的管理和更新。
### 4.3.2 动态数据结构与游戏逻辑
除了资源管理之外,双链表在游戏逻辑中也扮演着重要角色。例如,许多游戏中的元素需要动态地在不同的列表中移动,比如敌人的移动、地图的切换、玩家的状态管理等。
在实现这些功能时,双链表可以提供一种快速调整数据项顺序的手段。通过在双链表中移动节点,我们可以有效地管理这些动态变化的数据,而不必每次都复制整个数据结构。这对于实时性要求高的游戏来说至关重要。
例如,我们可以使用双链表来跟踪所有活跃的敌人实体。当新的敌人实体被创建时,它被添加到链表的尾部;当敌人被击败时,它从链表中移除。这种结构让我们可以快速地遍历所有活跃的敌人,并执行相应的游戏逻辑。
```java
class Enemy {
int id;
Node node; // 双链表节点引用
// 其他属性和方法
}
class EnemyManager {
private Map<Integer, Enemy> enemies;
private Node head;
public EnemyManager() {
enemies = new HashMap<>();
head = new Node(0, null, null);
}
public void addEnemy(Enemy enemy) {
enemies.put(enemy.id, enemy);
// 将enemy节点添加到双链表中
// ...
}
public void removeEnemy(Enemy enemy) {
enemies.remove(enemy.id);
// 从双链表中移除enemy节点
// ...
}
public void updateEnemies() {
Node current = head.next;
while (current != head) {
Enemy enemy = current.data;
// 更新enemy状态
// ...
current = current.next;
}
}
}
```
在这个例子中,`EnemyManager`类使用双链表来管理所有活跃的敌人。通过`addEnemy`和`removeEnemy`方法,我们可以快速地在链表中添加或移除敌人节点。此外,`updateEnemies`方法允许我们在不影响其他敌人的情况下,对所有活跃的敌人进行批量状态更新。
通过这种方式,双链表提供了灵活的数据管理能力,使得游戏开发更加高效和动态。
# 5. 双链表的性能分析与优化策略
## 5.1 时间复杂度和空间复杂度分析
### 5.1.1 双链表操作的时间复杂度评估
双链表作为一种数据结构,其性能主要通过时间复杂度来评估各种操作的效率。具体地,双链表支持的操作包括插入、删除和查找等,其时间复杂度如下:
- **插入操作**:在双链表的头部或尾部插入元素的时间复杂度为 O(1),因为它仅需修改相邻节点的指针。然而,在双链表中间任意位置插入元素的时间复杂度为 O(n),因为需要先遍历找到指定位置。
- **删除操作**:与插入类似,删除双链表头部或尾部元素的时间复杂度为 O(1),而删除中间元素则需要 O(n) 时间复杂度,因为要先定位到该元素。
- **查找操作**:查找指定值的元素的时间复杂度为 O(n),因为双链表不支持直接通过索引访问,需要从头节点开始遍历,直到找到匹配的节点或遍历完链表。
- **遍历操作**:遍历双链表的时间复杂度为 O(n),遍历是访问链表中每一个节点一次的过程。
### 5.1.2 双链表内存占用的分析
双链表相比于单链表,增加了节点的前驱指针,因此内存占用更大。一个节点由数据域、指向前一个节点的指针和指向后一个节点的指针组成。具体内存占用取决于节点的数据类型和系统架构。通常,每个节点的内存占用可以使用以下公式进行计算:
```
内存占用 = 数据域内存占用 + 指针内存占用 * 2
```
此外,双链表的内存占用还和其容量有关。随着节点数量的增加,总内存占用线性增长。这比数组数据结构的内存占用更加灵活,因为数组的内存占用在初始化时就已经固定。
## 5.2 优化策略和最佳实践
### 5.2.1 算法层面的优化
在双链表的使用过程中,算法层面的优化是非常关键的。以下是一些常见的优化策略:
- **懒惰删除**:删除节点时,并不立即从链表中移除,而是将其标记为“删除状态”,并只有在下一次遍历到该节点时才进行实际的删除操作。这样可以优化连续删除操作,减少内存占用并提高效率。
- **缓存最近使用的节点**:在实现缓存系统时,可以缓存最近访问或添加的节点,这样可以在访问频率高的节点时减少遍历时间,提高访问速度。
- **双向遍历**:双链表天然支持双向遍历,我们可以利用这一点来优化算法。例如,如果我们要频繁地从尾部向前查找,可以将尾节点作为起始节点来遍历。
### 5.2.2 设计模式在双链表优化中的应用
设计模式是解决特定问题的最佳实践。在双链表的设计和优化中,可以应用多种设计模式,如:
- **工厂模式**:可以为双链表及其节点的创建提供工厂方法,隐藏具体的创建逻辑,便于后续的扩展和维护。
- **迭代器模式**:实现一个迭代器,来顺序访问双链表的元素。这样可以独立于双链表的具体实现,提供统一的访问方式。
- **享元模式**:如果双链表中存储的对象是可共享的,可以使用享元模式来减少内存占用。例如,对同一个数据的多个引用可以共享相同的节点。
```java
// 示例代码:迭代器模式在双链表中的应用
public class DoublyLinkedListIterator<T> implements Iterator<T> {
private DoublyLinkedList<T>.Node current;
public DoublyLinkedListIterator(DoublyLinkedList<T>.Node head) {
this.current = head;
}
@Override
public boolean hasNext() {
return current != null;
}
@Override
public T next() {
T data = current.data;
current = current.next;
return data;
}
}
```
以上代码展示了一个简单的迭代器类,用于遍历双链表。它包含了基本的`hasNext`和`next`方法,可以对双链表进行遍历而不需要了解其内部细节。
通过以上优化策略和设计模式的应用,可以显著地提升双链表的性能和使用灵活性。在实际的应用开发中,开发者应根据具体场景选择合适的优化方案。
# 6. 双链表的测试与案例研究
## 6.* 单元测试与双链表的稳定性
双链表作为一种复杂的数据结构,其稳定性对于整个系统的可靠性至关重要。单元测试是保障双链表稳定性的关键环节。在本章节中,我们将探讨单元测试策略和方法,并讨论测试驱动开发(TDD)在双链表开发中的应用。
### 6.1.* 单元测试策略和方法
单元测试是指在软件开发过程中,对代码的最小可测试单元进行检查和验证。对于双链表来说,这意味着需要对每一个方法进行测试,包括添加节点、删除节点、遍历等操作。我们可以采用以下策略:
- **边界值测试**:确保双链表的操作在边界条件下也能正确执行。例如,测试在空链表和只包含一个节点的链表上进行删除操作。
- **等价类划分**:将输入数据的集合划分为若干等价类,每个等价类中的数据被认为是等效的。这样可以减少测试用例的数量,同时保证测试的全面性。
- **状态检查**:在每次操作后,检查双链表的状态是否符合预期。例如,添加节点后检查链表的长度是否增加了1,删除节点后检查是否确实从链表中移除了目标节点。
以下是使用JUnit进行双链表节点添加操作的单元测试示例:
```java
@Test
public void testAddNode() {
DoublyLinkedList<Integer> list = new DoublyLinkedList<>();
list.add(1);
list.add(2);
list.add(3);
// 测试添加节点后的链表大小
assertEquals(3, list.size());
// 测试添加节点后链表的具体值
assertEquals(Integer.valueOf(1), list.get(0));
assertEquals(Integer.valueOf(3), list.get(list.size() - 1));
}
```
### 6.1.2 测试驱动开发(TDD)在双链表开发中的应用
测试驱动开发(TDD)是一种软件开发方法,它要求在编写功能代码之前先编写测试代码。这种方法强调先测试再编码,有助于提高代码质量,并且能够保证测试用例覆盖了所有的功能点。
当应用TDD来开发双链表时,开发过程将遵循以下步骤:
1. **编写测试用例**:先编写测试用例,描述双链表应该如何响应各种输入。
2. **运行测试**:运行测试用例,此时所有测试都会失败,因为功能代码尚未编写。
3. **编写最小功能代码**:编写能够使测试通过的最小量代码。
4. **重构代码**:在确保测试通过的情况下,重构代码以提高其质量和可维护性。
5. **重复上述步骤**:继续编写更多的测试用例,并重复上述开发和重构过程。
通过这种方式,双链表的每个功能点都经过了详尽的测试,确保了其稳定性。
## 6.2 双链表的案例研究和实战分析
在本节中,我们将通过具体案例来分析双链表在复杂系统中的实际应用,并对遇到的问题和解决方案进行剖析。
### 6.2.1 双链表在复杂系统中的应用案例
在大型系统中,双链表可以用于多种场景。例如,在一个任务调度系统中,双链表可以用来管理任务的执行队列。每个节点代表一个任务,节点之间的双向链接表示任务之间的依赖关系。
在这个案例中,双链表允许我们快速地在队列的任何位置添加或删除任务。特别是,如果系统需要按照优先级顺序来调度任务,双链表的排序功能可以让任务按照优先级从高到低排列,从而提高任务执行效率。
### 6.2.2 从问题到解决方案的案例剖析
接下来,我们将探讨一个具体的问题及其解决方案。假设在任务调度系统中,任务依赖关系经常发生变化,这导致双链表需要频繁地调整节点顺序,从而影响了性能。
#### 问题分析
在任务频繁添加和删除的场景中,每次调整任务顺序都需要遍历双链表来重新定位节点,这成为了性能瓶颈。
#### 解决方案
为了解决这个问题,可以采取以下优化措施:
- **使用优先级队列**:结合优先级队列和双链表,可以利用优先级队列来维护任务的优先级顺序,而双链表负责任务的执行顺序。
- **节点缓存机制**:对于频繁变动的任务,可以在内部使用一个缓存机制来临时存储这些节点,当任务依赖关系稳定后,再一次性地更新双链表。
以下是采用优先级队列和缓存机制的伪代码示例:
```java
PriorityQueue<Task> priorityQueue = new PriorityQueue<>();
DoublyLinkedList<Task> executionQueue = new DoublyLinkedList<>();
// 添加任务到优先级队列
priorityQueue.add(new Task(10, "Task 1"));
priorityQueue.add(new Task(5, "Task 2"));
// 缓存中存储依赖关系变化的任务
Map<Task, List<Task>> dependencyCache = new HashMap<>();
// 当依赖关系稳定后,一次性更新执行队列
dependencyCache.forEach((key, value) -> {
// 在双链表中找到合适的位置插入任务
// 可以利用双链表的二分查找或者排序算法来快速定位
executionQueue.insertAt(key, position);
});
// 执行任务队列
while (!executionQueue.isEmpty()) {
Task task = executionQueue.poll();
// 执行任务逻辑...
}
```
通过这样的优化,双链表的性能得到了显著提升,同时系统整体的响应速度也得到了优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了双链表在 Java 中的实现、操作、性能分析和应用。从基础概念到高级应用,它涵盖了双链表的各个方面。通过全面解析增删查改操作、比较双链表与集合框架、构建高效缓存系统以及在并发编程中的应用,专栏提供了全面的指南,帮助读者提升数据结构操作效率和构建健壮的应用程序。此外,它还深入探讨了双链表的技巧和窍门、问题诊断和解决方法,以及在 Java 中的内存管理和序列化/反序列化策略。通过结合理论和实践,本专栏旨在帮助读者掌握双链表在 Java 中的应用,并将其有效地用于各种场景,包括缓存系统、并发编程和数据处理。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
降噪与抗干扰:传声入密技术挑战的解决之道

# 摘要
传声入密技术在近年来受到广泛关注,该技术能够确保在复杂的噪声环境下实现高质量的语音通信。本文首先概述了传声入密技术的基础知识,随后深入探讨了噪声与干扰的理论基础,涵盖声学噪声分类、信号处理中的噪声控制理论以及抗干扰理论框架。在实践应用部分,文中讨论了降噪算法的实现、优化及抗干扰技术案例分析,并提出了综合降噪与抗干扰系统的设计要点。最后,文章分析了该技术面临的挑战,并展望了其发展趋势,包括人工智能及
Rsoft仿真案例精选:光学系统设计与性能分析的秘密武器
# 摘要
本文全面探讨了光学系统设计与仿真在现代光学工程中的应用,首先介绍了光学系统设计与仿真基础知识,接着详细说明了Rsoft仿真软件的使用方法,包括界面操作、项目配置、材料及光源库使用等。随后,本文通过不同案例分析了光学系统的设计与仿真,包括透镜系统、光纤通信以及测量系统。第四章深入讨论了光学系统性能的评估与分析,包括成像质量、光路追踪和敏感性分析。第五章探讨了基于Rsoft的系统优化策略和创新型设计案例。最后,第六章探索了Rsoft仿真软件的高级功能,如自定义脚本、并行仿真以及高级分析工具。这些内容为光学工程师提供了全面的理论和实践指南,旨在提升光学设计和仿真的效率及质量。
# 关键字
sampleDict自动化脚本编写:提高关键词处理效率
# 摘要
自动化脚本编写和关键词处理是现代信息技术领域的重要组成部分,它们对于提升数据处理效率和检索准确性具有关键作用。本文首先介绍自动化脚本编写的基本概念和重要性,随后深入探讨关键词在网络搜索和数据检索中的作用,以及关键词提取的不同方法论。接着,文章分析了sampleDict脚本的功能架构、输入输出设计及扩展性,并通过实际案例展示了脚本在自动化关键词处理中的应用。进一步地,本文探讨了将深度学习技术与s
【网络分析新手必学】:MapInfo寻找最短路径和最佳路径的实战技巧
# 摘要
随着地理信息系统(GIS)和网络分析技术的发展,MapInfo等专业软件在路径规划和空间数据分析方面扮演着越来越重要的角色。本文系统介绍了MapInfo的基础知识和空间数据分析方法,深入探讨了寻找最短路径的理论与实践,包括经典算法如Dijkstra和A*算法的应用。同时
【Vue项目安全加固】:Nginx中防御XSS和CSRF攻击的策略

# 摘要
随着Web应用的普及和复杂性增加,Vue项目面临的安全挑战日益严峻,尤其是XSS和CSRF攻击对用户安全构成威胁。本文首先概述了Vue
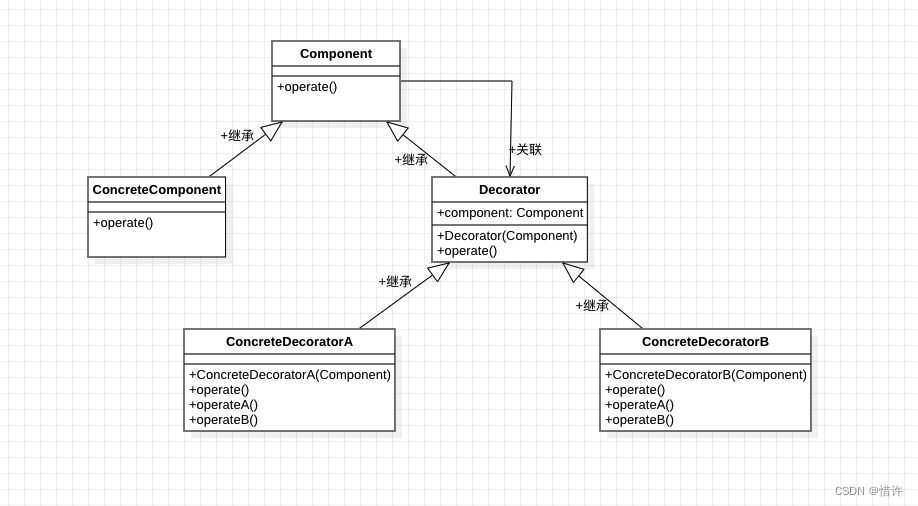
装饰者模式:构建灵活类体系的高级技巧
# 摘要
装饰者模式是一种结构型设计模式,旨在通过动态地给对象添加额外的责任来扩展其功能,同时保持类的透明性和灵活性。本文首先介绍了装饰者模式的定义与原理,并探讨了其理论基础,包括设计模式的历史、分类及其设计原则,如开闭原则和单一职责原则。随后,文章详细阐述了装饰者模式在不同编程语言中的实践应用,例如Java I/O库和Python中的实现。文章还讨论了装饰者模式的高级技巧,包括装饰者链的优化和与其他设计模式的结合,并
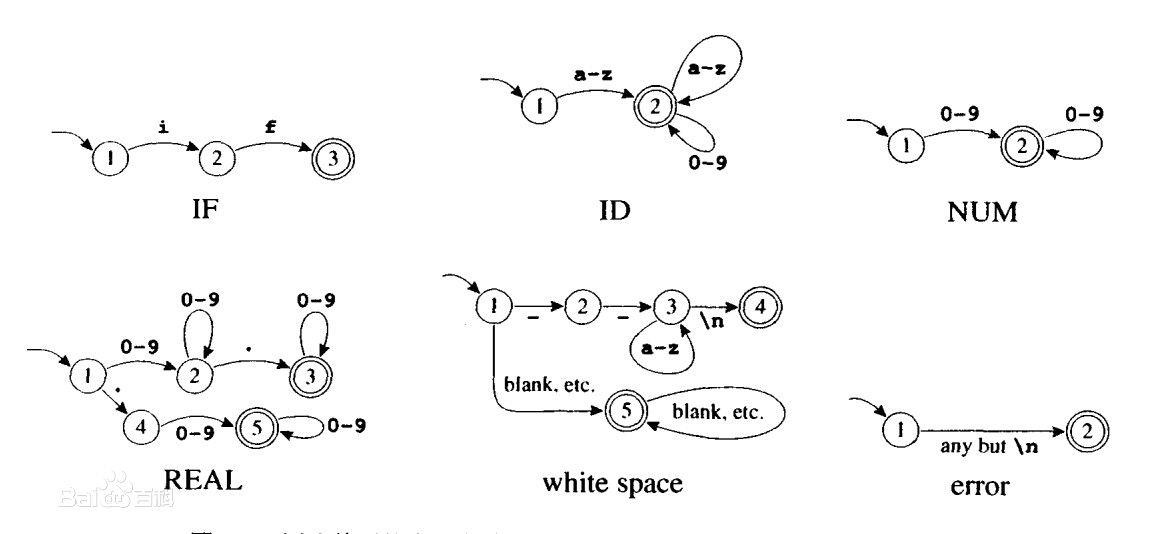
编译原理词法分析性能优化:揭秘高效的秘诀
# 摘要
词法分析作为编译原理中的基础环节,对于整个编译过程的效率和准确性起着至关重要的作用。本文首先探讨了词法分析的作用和面临的挑战,并介绍了词法分析的基础理论,包括词法单元的生成、有限自动机(FA)的使用,以及正则表达式与NFA的对应关系和DFA的构造与优化。接着,本文研究了性能优化的理论基础,包括算法的时间和空间复杂度分析、分而治之策略、动态规划与记忆化搜索。在实践层面,文章分析了优化
i2 Analyst's Notebook网络分析深度探索:揭示隐藏模式

# 摘要
本文全面介绍了i2 Analyst's Notebook的功能、操作技巧及其在网络分析领域的应用。首先,文中对网络分析的基础理论进行了阐述,包括网络分析的定义、目的与应用场景,以及关系图构建与解读、时间序列分析等核心概念。接着,详述了i2 Analyst's Notebook的实战技巧,如数据处理、关
揭秘和积算法:15个案例深度剖析与应用技巧

# 摘要
和积算法作为一种结合加法和乘法运算的数学工具,在统计学、工程计算、金融和机器学习领域中扮演了重要角色。本文旨在详细解释和积算法的基本概念、理论基础及其在不同领域的应用案例。通过分析算法的定义、数学属性以及优化技术,本文探讨了和积算法在处理大数据集时的效率提升方法。同时,结合编程实践,本文提供了和积算法在不同编程语言环境中的实现策略,并讨论了性能
剪映与云服务的完美融合
# 摘要
本文探讨了剪映软件与云服务融合的趋势、功能及其在不同领域的应用实践。首先概述了剪映软件的核心功能和界面设计,强调了其视频编辑技术、智能功能和与云服务的紧密结合。接着,详细分析了云服务在视频编辑过程中的作用,包括云存储、协同工作、云渲染技术、数据备份与恢复机制。文章还提供了剪映与云服务融合在个人视频制作、企业级视频项目管理以及教育培训中的具体实践案例。最后,展望了剪
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )