【Python栅格数据分析高级技术】:案例研究与技术应用
发布时间: 2024-09-12 07:10:11 阅读量: 183 订阅数: 98 

java计算器源码.zip

# 1. Python在栅格数据分析中的角色与应用
## 简介
Python语言在数据科学领域的广泛应用使其成为栅格数据分析的理想工具。借助于强大的库支持,Python在处理遥感数据、地理信息系统(GIS)和空间分析方面表现出了巨大的潜力。本章将探讨Python在栅格数据分析中的角色,并介绍其应用范围和优势。
## Python在栅格数据处理中的优势
Python的流行得益于它的简单性和强大的数据处理能力。通过集成GDAL、Rasterio、NumPy等库,Python能够高效读取、处理和分析大规模栅格数据集。Python易于上手,对于非专业人士,如农业科学家、环境监测者等,利用Python进行栅格数据分析变得更加可行。
## 栅格数据分析的应用场景
从农业产量预估到气候模型分析,再到城市规划,栅格数据分析在诸多领域都有其不可替代的作用。Python凭借其灵活性和众多的第三方库,可以为不同领域的数据分析提供量身定制的解决方案,使得复杂的空间数据分析任务变得更加高效和直观。
通过本章,读者将了解到Python在栅格数据分析领域的巨大潜力,以及如何根据不同的应用场景选择合适的技术栈。接下来的章节将会详细介绍栅格数据的处理基础、高级分析技术以及实际案例。
# 2. 栅格数据处理基础
## 2.1 栅格数据的概念与特点
### 2.1.1 栅格数据模型简介
栅格数据模型是一种表达空间信息的数字化方式,它将地理空间划分为规则的网格单元(称为像素或单元格),每个单元格存储对应地理实体在某一属性上的数值信息。这种模型特别适合于表达连续变化的数据,如卫星遥感影像、地形高程数据等。栅格数据通过这些数值的集合,可以直观地展示出地形变化、温度分布、降雨量等信息。栅格数据的一个显著特点是分辨率,它由栅格单元的大小决定,直接影响着数据的详细程度和分析的精度。
### 2.1.2 栅格数据与矢量数据的对比
栅格数据和矢量数据是空间数据的两种基本表达方式。它们在存储形式、分析方法和应用场景上有明显的差异:
- 存储形式:栅格数据以规则的网格形式存储,每个网格包含了一个或多个属性值。矢量数据则通过点、线、面的几何图形来表示空间信息。
- 分析方法:栅格数据适合进行局部区域的统计分析和空间插值,而矢量数据更适合用于网络分析、拓扑关系的建立。
- 应用场景:栅格数据适用于遥感影像处理、气象预报、环境监测等。矢量数据则广泛应用于地理信息系统、城市规划、资源管理等领域。
## 2.2 Python处理栅格数据的库
### 2.2.1 GDAL/OGR库概述与安装
GDAL(Geospatial Data Abstraction Library)是一个用于栅格数据读写的开源库,它提供了一系列数据格式的抽象层和转换功能。OGR(Open GIS Simple Features for C++)是GDAL中处理矢量数据的子库。GDAL/OGR因其跨平台、高效、功能强大的特性而被广泛用于地理信息系统(GIS)和遥感数据处理领域。
安装GDAL/OGR库可以通过以下步骤进行:
1. 访问GDAL官方网站下载对应的安装包。
2. 解压安装包,并根据操作系统环境运行安装脚本。
3. 配置系统环境变量,以确保GDAL/OGR命令行工具和Python绑定在任何位置都可以被调用。
在Python环境中,GDAL/OGR可以通过pip工具安装对应的Python绑定库:
```shell
pip install GDAL
```
### 2.2.2 栅格数据读取与写入
使用GDAL库,可以读取栅格数据的元数据信息,并加载栅格数据集中的特定波段。下面的代码展示了如何使用GDAL读取栅格数据集:
```python
from osgeo import gdal
# 打开栅格数据集
dataset = gdal.Open("path_to_raster_dataset.tif")
# 获取栅格数据集的元数据信息
print(dataset.GetMetadata())
# 读取数据集的特定波段
band = dataset.GetRasterBand(1)
print(band.ReadAsArray())
# 关闭数据集
dataset = None
```
此外,GDAL也支持栅格数据的写入操作。写入栅格数据需要先创建一个新的栅格数据集,并为其定义必要的参数,如尺寸、数据类型、地理变换等。下面是一个创建栅格数据并写入数据的示例:
```python
driver = gdal.GetDriverByName('GTiff')
out_dataset = driver.Create('output_raster.tif', cols, rows, 1, gdal.GDT_Float32)
out_band = out_dataset.GetRasterBand(1)
out_band.WriteArray(output_array) # output_array 是已创建的二维numpy数组
out_band.FlushCache()
out_dataset = None
```
### 2.2.3 栅格数据的格式转换
栅格数据格式转换是处理地理数据中常见的需求。利用GDAL库可以轻松地将一种栅格格式转换为另一种格式。下面的代码演示了如何使用GDAL进行栅格数据的格式转换:
```python
from osgeo import gdal
input_raster = 'input_raster.tif'
output_raster = 'output_raster.jp2'
# 打开原始栅格数据集
src_dataset = gdal.Open(input_raster)
# 创建新的栅格数据集
driver = gdal.GetDriverByName('JP2OpenJPEG')
dst_dataset = driver.CreateCopy(output_raster, src_dataset)
# 关闭数据集
src_dataset = None
dst_dataset = None
```
## 2.3 栅格数据的基础操作
### 2.3.1 数据重采样与重投影
数据重采样是指改变栅格数据的空间分辨率,而数据重投影则是改变栅格数据的空间参考系统。以下是如何使用GDAL进行数据重采样和重投影操作的示例:
```python
from osgeo import gdal
input_raster = 'input_raster.tif'
output_raster = 'resampled_raster.tif'
# 打开原始栅格数据集
dataset = gdal.Open(input_raster)
# 设置输出栅格数据的空间分辨率
xres = dataset.RasterXSize / 100
yres = dataset.RasterYSize / 100
# 进行重采样操作
resampled_band = dataset.GetRasterBand(1).Resample(gdal.GDT_Float32, xres, yres)
# 重投影栅格数据
wkt = '投影系统的WKT代码'
transform = [/* 新的仿射变换矩阵 */]
dst_dataset = gdal.Warp(output_raster, dataset, format='GTiff', dstSRS=wkt, xRes=xres, yRes=yres, outputType=gdal.GDT_Float32, outputTransform=transform)
# 关闭数据集
dataset = None
dst_dataset = None
```
### 2.3.2 栅格数据裁剪与拼接
裁剪是指将栅格数据集中的一部分提取出来,形成新的栅格数据。拼接则是将多个栅格数据集合并为一个大的栅格数据集。以下是如何使用GDAL进行栅格数据的裁剪和拼接操作的示例:
```python
from osgeo import gdal
# 裁剪
input_raster = 'input_raster.tif'
clipped_raster = 'clipped_raster.tif'
geo_transform = [/* 原始仿射变换参数 */]
x_min, x_max, y_min, y_max = /* 裁剪区域的坐标范围 */
dataset = gdal.Open(input_raster)
band = dataset.GetRasterBand(1)
driver = gdal.GetDriverByName('GTiff')
out_dataset = driver.Create(clipped_raster, x_max - x_min, y_max - y_min, 1, band.DataType)
out_band = out_dataset.GetRasterBand(1)
out_band.WriteArray(band.ReadAsArray(x_min, y_min, x_max - x_min, y_max - y_min))
out_band.FlushCache()
out_band.SetNoDataValue(0)
out_dataset.SetGeoTransform(geo_transform)
out_dataset.SetProjection(dataset.GetProjection())
out_dataset = None
dataset = None
# 拼接
raster1 = 'raster1.tif'
raster2 = 'raster2.tif'
clipped_raster = 'clipped_raster.tif'
clipped_raster2 = 'clipped_raster2.tif'
output_raster = 'output_raster.tif'
dataset1 = gdal.Open(raster1)
dataset2 = gdal.Open(raster2)
clipped_dataset = gdal.Open(clipped_raster)
clipped_dataset2 = gdal.Open(clipped_raster2)
# 假设裁剪后的栅格数据大小和分辨率是一致的
cols = clipped_dataset.RasterXSize
rows = clipped_dataset.RasterYSize
driver = gdal.GetDriverByName('GTiff')
out_datas
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 栅格数据处理专栏!本专栏旨在为数据科学家、地理空间分析师和 GIS 专业人士提供全面的指南,了解如何使用 Python 高效处理栅格数据。我们将深入探讨栅格数据结构、实战案例分析、进阶指南、工具箱选择、数据融合技术、可视化技术、地理空间分析、面向对象编程、并行计算、数据压缩、交互式分析和高级技术。通过一系列深入的文章和示例,我们将帮助您掌握 Python 栅格数据处理的方方面面,并提升您的算法效率和性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB中MSK调制的艺术】:差分编码技术的优化与应用

# 摘要
MSK调制技术作为现代通信系统中的一种关键调制方式,与差分编码相结合能够提升信号传输的效率和抗干扰能力。本文首先介绍了MSK调制技术和差分编码的基础理论,然后详细探讨了差分编码在MSK调制中的应用,包括MSK调制器设计与差分编码
从零开始学习RLE-8:一文读懂BMP图像解码的技术细节

# 摘要
本文从编码基础与图像格式出发,深入探讨了RLE-8编码技术在图像处理领域的应用。首先介绍了RLE-8编码机制及其在BMP图像格式中的应用,然后详细阐述了RLE-8的编码原理、解码算法,包括其基本概念、规则、算法实现及性能优化策略。接着,本文提供了BMP图像的解码实践指南,解析了文件结构,并指导了RLE-8解码器的开发流程。文章进一步分析了RLE-8在图像压缩中的优势和适用场景,以及其在高级图像处
Linux系统管理新手入门:0基础快速掌握RoseMirrorHA部署
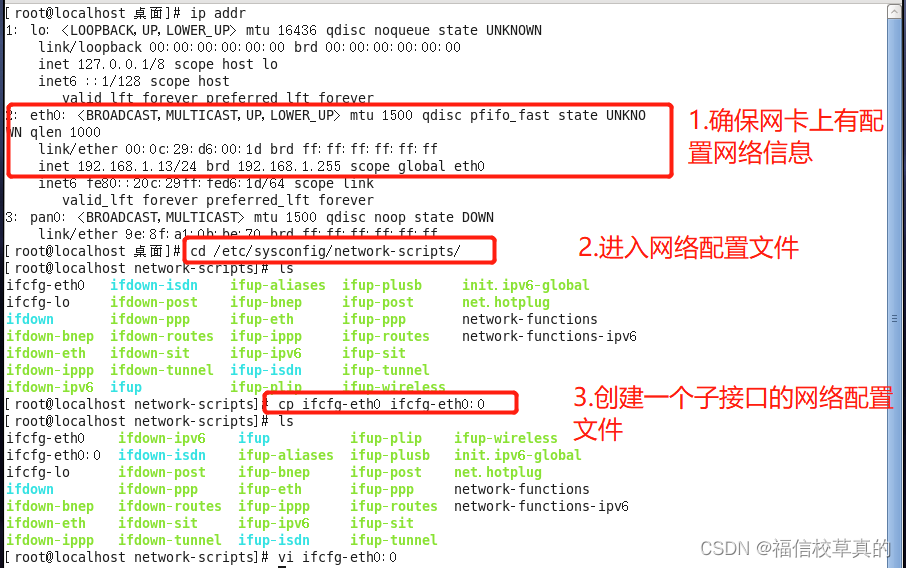
# 摘要
本文首先介绍了Linux系统管理的基础知识,随后详细阐述了RoseMirrorHA的理论基础及其关键功能。通过逐步讲解Linux环境下RoseMirrorHA的部署流程,包括系统要求、安装、配置和启动,本文为系统管理员提供了一套完整的实施指南。此外,本文还探讨了监控、日常管理和故障排查等关键维护任务,以及高可用场景下的实践和性能优化策略。最后,文章展望了Linux系统管理和R
用户体验:华为以用户为中心的设计思考方式与实践
# 摘要
用户体验在当今产品的设计和开发中占据核心地位,对产品成功有着决定性影响。本文首先探讨了用户体验的重要性及其基本理念,强调以用户为中心的设计流程,涵盖用户研究、设计原则、原型设计与用户测试。接着,通过华为的设计实践案例分析,揭示了用户研究的实施、用户体验的改进措施以及界面设计创新的重要性。此外,本文还探讨了在组织内部如何通过
【虚拟化技术】:smartRack资源利用效率提升秘籍
# 摘要
本文全面介绍了虚拟化技术,特别是smartRack平台在资源管理方面的关键特性和实施技巧。从基础的资源调度理论到存储和网络资源的优化,再到资源利用效率的实践技巧,本文系统阐述了如何在smartRack环境下实现高效的资源分配和管理。此外,本文还探讨了高级资源管理技巧,如资源隔离、服务质量(QoS)保障以及性能分析与瓶颈诊
【聚类算法选型指南】:K-means与ISODATA对比分析
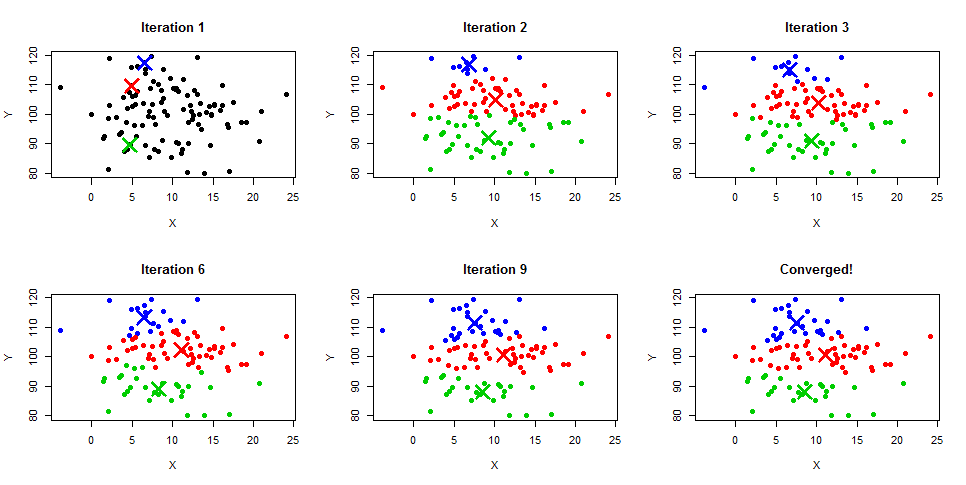
# 摘要
本文系统地介绍了聚类算法的基础知识,着重分析了K-means算法和ISODATA算法的原理、实现过程以及各自的优缺点。通过对两种算法的对比分析,本文详细探讨了它们在聚类效率、稳定性和适用场景方面的差异,并展示了它们在市场细分和图像分割中的实际应用案例。最后,本文展望了聚类算法的未来发展方向,包括高维数据聚类、与机器学习技术的结合以及在新兴领域的应用前景。
# 关
小米mini路由器序列号恢复:专家教你解决常见问题

# 摘要
本文对小米mini路由器序列号恢复问题进行了全面概述。首先介绍了小米mini路由器的硬件基础,包括CPU、内存、存储设备及网络接口,并探讨了固件的作用和与硬件的交互。随后,文章转向序列号恢复的理论基础,阐述了序列号的重要性及恢复过程中的可行途径。实践中,文章详细描述了通过Web界面和命令行工具进行序列号恢复的方法。此外,本文还涉及了小米mini路由器的常见问题解决,包括
深入探讨自然辩证法与软件工程的15种实践策略

# 摘要
自然辩证法作为哲学原理,为软件工程提供了深刻的洞见和指导原则。本文探讨了自然辩证法的基本原理及其在软件开发、设计、测试和管理中的应用。通过辩证法的视角,文章分析了对立统一规律、质量互变规律和否定之否定原则在软件生命周期、迭代优化及软件架构设计中的体现。此外,还讨论了如何将自然辩证法应用于面向对象设计、设计模式选择以及测试策略的制定。本文强调了自然辩证法在促进软
【自动化控制】:PRODAVE在系统中的关键角色分析

# 摘要
本文对自动化控制与PRODAVE进行了全面的介绍和分析,阐述了PRODAVE的基础理论、应用架构以及在自动化系统中的实现。文章首先概述了PRODAVE的通信协议和数据交换模型,随后深入探讨了其在生产线自动化、能源管理和质量控制中的具体应用。通过对智能工厂、智能交通系统和智慧楼宇等实际案例的分析,本文进一步揭示了PR
【VoIP中的ITU-T G.704应用】:语音传输最佳实践的深度剖析

# 摘要
本文系统地分析了ITU-T G.704协议及其在VoIP技术中的应用。文章首先概述了G.704协议的基础知识,重点阐述了其关键特性,如帧结构、时间槽、信道编码和信号传输。随后,探讨了G.704在保证语音质量方面的作用,包括误差检测控制机制及其对延迟和抖动的管理。此外,文章还分析了G.704
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )