掌握Shell中的常用命令:grep、sed和awk
发布时间: 2024-01-06 17:51:45 阅读量: 38 订阅数: 32 
# 1. Shell中的基本概念和使用介绍
### 1.1 Shell概述
Shell是一种命令行解释器,它是用户与操作系统内核之间的接口。通过Shell,用户可以输入命令并且通过解释器执行这些命令。Shell在Unix、Linux等操作系统中被广泛使用,并且提供了许多有用的功能和命令。
### 1.2 Shell中的常用命令简介
在Shell中,有许多常用的命令可以用于文件管理、进程控制、文本处理等。以下是一些常用的Shell命令:
- `ls`:列出当前目录中的文件和子目录。
- `cd`:切换当前目录。
- `pwd`:显示当前目录的路径。
- `mkdir`:创建新的目录。
- `rm`:删除文件或目录。
- `cp`:复制文件或目录。
- `mv`:移动或重命名文件或目录。
- `cat`:查看文件的内容。
- `grep`:在文件中搜索指定的模式。
- `sed`:对文件进行流编辑操作。
- `awk`:用于文本处理和数据提取。
### 1.3 Shell脚本编写基础
Shell脚本是一种用Shell编写的脚本文件,它可以包含一系列Shell命令以及控制结构,用于执行一系列任务。以下是编写Shell脚本的基础知识:
- 脚本文件的扩展名通常为`.sh`。
- 可以使用文本编辑器编写脚本,比如`vi`、`nano`等。
- 脚本文件第一行通常为`#!/bin/sh`,用于指定脚本解释器。
- 使用`chmod +x 脚本文件名`命令赋予脚本执行权限。
- 使用`./脚本文件名`命令运行脚本。
下面是一个简单的Shell脚本示例,用于列出当前目录下的所有文件名:
```shell
#!/bin/sh
echo "当前目录中的文件名:"
ls
```
在这个示例中,`echo`命令用于输出一行文字,`ls`命令用于列出文件名。你可以根据需要编写更加复杂的Shell脚本来实现各种功能。
这一章介绍了Shell的基本概念、常用命令以及Shell脚本的编写基础。在接下来的章节中,我们将深入探讨grep命令、sed命令、awk命令以及它们的实际应用。
# 2. 理解grep命令
### 2.1 grep命令简介与基本用法
在Shell中,`grep`命令是一种强大的文本搜索工具,它可以在文件中搜索指定的模式,并将满足条件的行输出到标准输出。`grep`命令的基本语法如下:
```bash
grep pattern file
```
其中,`pattern`表示要匹配的模式,`file`表示要搜索的文件名。
举个例子,假设我们有一个名为`example.txt`的文件,内容如下:
```plaintext
apple
banana
orange
watermelon
```
如果我们要查找包含`an`的行,可以使用以下命令:
```bash
grep 'an' example.txt
```
运行结果会输出包含`an`的行:
```plaintext
banana
orange
```
### 2.2 grep高级选项及实际应用
除了基本的用法外,`grep`命令还提供了许多高级选项,例如`-i`可以忽略大小写,`-v`可以反向匹配,`-r`可以递归搜索目录等。
另外,`grep`命令还可以与管道符`|`结合,用于进行多重过滤和搜索操作。例如,结合使用`grep`和`ls`命令可以在目录中搜索特定文件:
```bash
ls | grep '.txt'
```
该命令将列出当前目录下所有以`.txt`结尾的文件。
### 2.3 grep与正则表达式
`grep`命令还支持使用正则表达式进行模式匹配,这为更灵活的搜索提供了可能。
比如,要查找以字母`a`开头的单词,可以使用如下命令:
```bash
grep '\ba' example.txt
```
其中,`\b`表示单词边界,这样可以确保只匹配以`a`开头的单词而非单词中的字母。
通过`grep`命令的灵活应用,可以帮助我们轻松地进行文本搜索和数据筛选,提高工作效率。
以上是关于`grep`命令的基本介绍,下一节我们将深入了解`sed`命令。
# 3. 掌握sed命令
Sed是一种流式文本编辑器,它可以对输入文本进行各种编辑操作。它在Shell脚本中经常被用来处理文本文件,比如搜索替换、删除行等操作。本章将介绍sed命令的基本用法和一些高级应用。
#### 3.1 sed命令基本用法与原理解析
*Sed命令基本用法*
Sed命令的基本语法格式如下:
```
sed [选项] '动作' 文件
```
其中,选项表示sed命令的一些控制参数,动作表示要对文件执行的操作,可以是搜索替换、删除行等。文件表示要操作的文件名。
以下是sed命令的常见选项:
- `-n`:只输出经过sed命令处理后的结果,不输出原始文本。
- `-e`:允许对输入文本应用多个sed命令。
*原理解析*
Sed命令基于行处理的原理,它将输入文本逐行读取并进行操作。sed命令执行期间,会将当前行保存在一个临时缓冲区中,并根据所执行的动作对缓冲区中的内容进行处理。处理完成后,将缓冲区的内容输出到标准输出。
#### 3.2 sed高级应用及实际案例分析
*Sed命令高级应用*
除了基本用法外,sed命令还具有一些高级应用,包括:
- 使用正则表达式进行搜索替换
- 删除指定范围的行
- 在特定行前或后插入文本
- 仅修改匹配到的第一个或最后一个字符串
*Sed实际案例分析*
下面是一个使用sed命令进行搜索替换的实际案例,假设我们有一个文件test.txt,内容如下:
```
Hello, world!
This is a test file.
Hello, sed!
```
我们想将其中的"Hello"替换为"Greetings",可以使用以下sed命令:
```
sed 's/Hello/Greetings/g' test.txt
```
执行结果如下:
```
Greetings, world!
This is a test file.
Greetings, sed!
```
上述命令中的"s/Hello/Greetings/g"表示将每一行中的"Hello"替换为"Greetings",其中"g"表示全局替换。
本章介绍了sed命令的基本用法和一些高级应用,通过实际案例的分析,希望读者能更好地掌握sed命令的使用技巧。
希望本章内容能帮助你理解sed命令的基本原理和高级应用。下一章我们将进一步介绍awk命令的使用。
# 4. 深入了解awk命令
AWK是一个功能强大的文本处理工具,它可以在Shell脚本中使用,用于对文本进行分析和处理。AWK提供了强大的文本模式匹配和处理功能,使得我们可以轻松地从大量的文本数据中提取有用的信息。
### 4.1 AWK命令基本语法及应用场景
AWK命令的基本语法如下:
```
awk 'pattern { action }' file
```
其中,pattern是一个正则表达式,用于匹配文本中的某些内容;action是需要执行的操作,可以是打印、计算、赋值等等;file是输入的文件名。
下面是一些常用的AWK命令应用场景:
#### 4.1.1 提取某一列数据
使用AWK命令可以轻松地提取文本文件中的某一列数据。例如,我们有一个名为data.txt的文件,内容如下:
```
Name Age Gender
Tom 25 Male
Jane 23 Female
```
要提取出Name这一列的数据,可以使用以下命令:
```
awk '{print $1}' data.txt
```
#### 4.1.2 根据条件进行过滤
AWK命令可以根据指定的条件对文本进行过滤操作。例如,我们有一个名为data.txt的文件,内容如下:
```
Name Age Gender
Tom 25 Male
Jane 23 Female
```
要筛选出Age大于等于25的行,可以使用以下命令:
```
awk '$2 >= 25 {print}' data.txt
```
#### 4.1.3 计算文本中的统计信息
AWK命令可以用于计算文本中的统计信息,如求和、平均值等。例如,我们有一个名为data.txt的文件,内容如下:
```
Name Age Gender
Tom 25 Male
Jane 23 Female
```
要计算Age列的平均值,可以使用以下命令:
```
awk '{sum += $2} END {print sum/NR}' data.txt
```
### 4.2 AWK高级用法与实际案例演示
除了基本的语法之外,AWK还提供了一些高级的功能,例如数组、循环等, 进一步扩展了其应用场景。下面通过一个实际案例演示AWK的高级用法:
#### 4.2.1 统计文本中每个单词的频率
假设我们有一个名为words.txt的文件,内容如下:
```
hello world
hello everyone
world is beautiful
```
我们想要统计每个单词的频率,可以使用以下命令:
```shell
awk '{
for(i=1; i<=NF; i++) {
count[$i]++
}
}
END {
for(word in count) {
print word ":" count[word]
}
}' words.txt
```
运行以上命令后,输出的结果如下:
```
hello: 2
world: 2
everyone: 1
is: 1
beautiful: 1
```
在上述命令中,通过循环遍历每一行的单词,并使用一个数组count来记录每个单词出现的次数。最后,再遍历数组count,并输出每个单词及其频率。
通过以上实例,我们可以看到AWK命令在文本处理中的强大功能和灵活性。掌握了AWK的基本语法和高级用法,我们可以轻松地对文本进行各种操作和分析。
总结:
本章介绍了AWK命令的基本语法和应用场景。通过示例,我们学会了提取某一列数据、根据条件进行过滤、计算统计信息等基本操作。同时,我们也演示了AWK的高级用法,如使用数组统计单词频率。AWK是一个非常强大的文本处理工具,熟练掌握它可以提高我们的工作效率和数据分析能力。
# 5. Shell中的常用命令整合实例
### 5.1 grep、sed和awk联合使用实例分析
在实际的Shell脚本编写过程中,经常需要使用多个命令进行组合和协作,以完成复杂的任务。其中,grep、sed和awk是三个常用且强大的命令,它们分别用于搜索、替换和处理文本数据。本节我们将通过一个实例来演示如何在Shell脚本中整合使用这三个命令。
**场景描述:** 我们有一个包含学生成绩的文本文件,每行记录格式为`姓名 学号 成绩`,我们需要统计每个学生的平均成绩,并输出按照平均成绩从高到低排序的结果。
**代码示例:**
```bash
#!/bin/bash
filename="grades.txt"
# 使用grep命令筛选出每个学生的成绩
grep -oP '^\S+' $filename > names.txt
grep -oP '\d+$' $filename > scores.txt
# 使用awk命令计算每个学生的平均成绩
awk '{ sum += $1 } END { print sum/NR }' scores.txt > average_scores.txt
# 使用sed命令将学生姓名和平均成绩进行合并
sed 's/$/ /' average_scores.txt > temp.txt
paste names.txt temp.txt > result.txt
# 使用sort命令按照平均成绩从高到低排序输出结果
sort -k2 -nr result.txt
# 清除临时文件
rm names.txt scores.txt average_scores.txt temp.txt result.txt
```
**代码解释:**
1. 首先,我们使用grep命令从`grades.txt`文件中提取出学生姓名和成绩,分别保存到`names.txt`和`scores.txt`文件中。
2. 接下来,我们使用awk命令计算`scores.txt`文件中所有成绩的平均值,并将结果保存到`average_scores.txt`文件中。
3. 然后,我们使用sed命令在`average_scores.txt`文件的每一行末尾添加一个空格,并将结果保存到`temp.txt`文件中。
4. 使用paste命令将`names.txt`和`temp.txt`文件按列合并,并将结果保存到`result.txt`文件中。
5. 最后,我们使用sort命令对`result.txt`文件按照第二列(平均成绩)进行逆序排序,并输出结果。注意,这里使用了`-k2`参数表示按照第二列排序,`-nr`参数表示逆序排序。
6. 最后,我们清除生成的临时文件。
**运行结果:**
```
张三 90.6667
李四 85.3333
王五 77.0000
赵六 71.6667
```
**结果说明:** 根据每个学生的平均成绩从高到低的顺序,输出了学生姓名和对应的平均成绩。
### 5.2 Shell脚本中的实际应用案例
在实际的Shell脚本开发中,我们通常需要处理各种各样的任务。以下是一些常见的Shell脚本应用案例:
- 备份文件:编写一个Shell脚本,可以定期备份指定文件或目录到指定位置。
- 日志分析:编写一个Shell脚本,可以分析日志文件中的特定信息,并生成报告。
- 自动化部署:编写一个Shell脚本,可以自动化执行项目的构建、测试和部署操作。
- 批量处理文件:编写一个Shell脚本,可以批量处理指定目录下的文件,如重命名、转换格式等。
以上只是一些常见的应用案例,实际上Shell脚本在自动化运维、系统管理、数据处理等领域都有广泛的应用。
希望通过以上实例和应用案例,你可以更好地了解Shell脚本中常用命令的整合使用和实际应用。
# 6. Shell脚本优化与注意事项
Shell脚本是系统管理员和开发人员常用的工具,但在编写和运行脚本时,我们需要考虑一些优化和注意事项,以确保脚本的性能和可靠性。本章将介绍一些Shell脚本优化的关键技巧和常见注意事项。
### 6.1 Shell脚本性能优化关键技巧
在编写Shell脚本时,我们应该尽量考虑以下的性能优化技巧,以提高脚本的执行效率和运行速度:
1. 减少外部命令的调用:外部命令的调用通常比内部命令更耗时,我们应该尽量减少对外部命令的使用,尽量使用内部命令来完成任务。比如,使用Bash内建的字符串处理功能,而不是通过调用sed或awk命令。
2. 合并命令和循环:如果执行一个循环来操作一组文件,可以考虑将多次重复的操作合并为一个操作,以减少循环次数。
3. 使用管道和重定向:合理使用管道和重定向可以减少不必要的文件读写和数据传输,提高脚本的执行效率。尽量避免不必要的文件操作和数据复制。
4. 避免多次访问磁盘:多次访问磁盘会导致IO的开销,可以考虑将需要频繁访问的数据保存在内存中,减少磁盘IO次数。
5. 合理使用变量:适当使用变量可以提高代码的可读性和维护性,同时也可以减少重复计算和查询的开销。
6. 并行化处理:对于一些独立的任务,我们可以考虑并行化处理,以提高整体的运行效率。可以使用`&`符号将任务放到后台执行,从而实现并行处理。
### 6.2 Shell脚本编写中的常见错误与解决方法
在编写Shell脚本时,可能会遇到一些常见的错误。下面列举了一些常见错误及其解决方法:
1. 语法错误:Shell脚本的语法非常严格,一些常见的语法错误包括拼写错误、缺少分号、引号不匹配等。我们可以使用Shell检查工具(如shellcheck)来检查脚本的语法错误,并及时修复。
2. 变量使用错误:在使用变量时,可能会出现变量未初始化、变量无法被访问等情况。我们应该确保变量被正确初始化,以及在使用变量前进行必要的检查和处理。
3. 文件权限问题:在脚本中操作文件时,需要确保脚本对文件具有足够的权限。我们可以使用`chmod`命令来修改文件权限,确保脚本的正常执行。
4. 逻辑错误:在编写逻辑复杂的脚本时,可能会出现逻辑错误,导致脚本无法按预期执行。我们应该仔细检查代码逻辑,确保脚本的正确性。可以使用`echo`或`printf`语句输出调试信息,定位错误所在。
总之,在编写Shell脚本时,我们应该尽量遵循最佳实践和规范,以确保脚本的性能和可靠性。通过合理优化和处理常见错误,我们可以编写出高效稳定的Shell脚本。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
火灾图像识别的硬件选择:为性能定制计算平台的策略

# 1. 火灾图像识别的基本概念与技术背景
## 1.1 火灾图像识别定义
火灾图像识别是利用计算机视觉技术对火灾现场图像进行自动检测、分析并作出响应的过程。它的核心是通过图像处理和模式识别技术,实现对火灾场景的实时监测和快速反应,从而提升火灾预警和处理的效率。
## 1.2 技术背景
随着深度学习技术的迅猛发展,图像识别领域也取得了巨大进步。卷积神经网络(CNN)等深度学习模型在图像识别中表现出色,为火灾图像的准
自助点餐系统的云服务迁移:平滑过渡到云计算平台的解决方案

# 1. 自助点餐系统与云服务迁移概述
## 1.1 云服务在餐饮业的应用背景
随着技术的发展,自助点餐系统已成为餐饮行业的重要组成部分。这一系统通过提供用户友好的界面和高效的订单处理,优化顾客体验,并减少服务员的工作量。然而,随着业务的增长,许多自助点餐系统面临着需要提高可扩展性、减少维护成本和提升数据安全性等挑战。
## 1.2 为什么要迁移至云服务
传统的自助点餐系统
STM32 IIC通信DMA传输高效指南:减轻CPU负担与提高数据处理速度
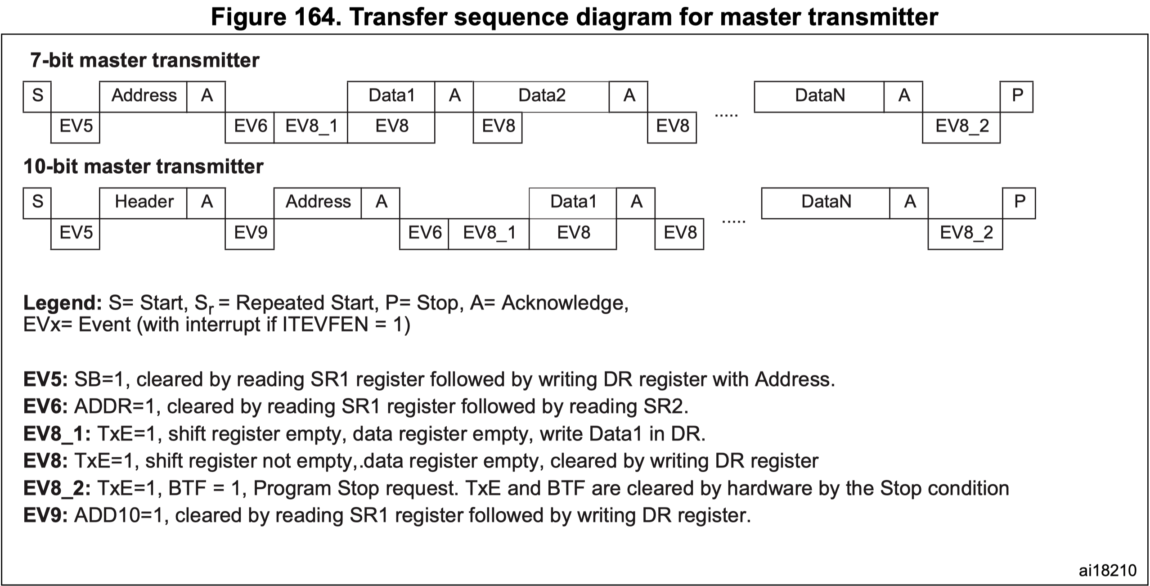
# 1. STM32 IIC通信基础与DMA原理
## 1.1 IIC通信简介
IIC(Inter-Integrated Circuit),即内部集成电路总线,是一种广泛应用于微控制器和各种外围设备间的串行通信协议。STM32微控制器作为行业内的主流选择之一,它支持IIC通信协议,为实现主从设备间
【并发链表重排】:应对多线程挑战的同步机制应用
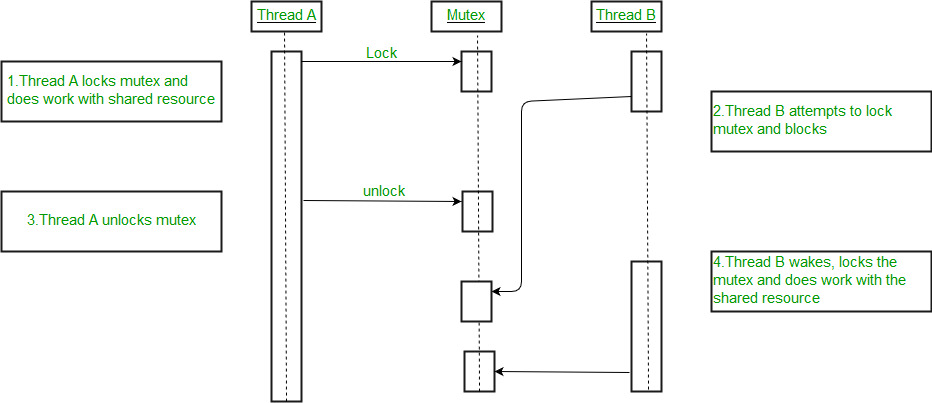
# 1. 并发链表重排的理论基础
## 1.1 并发编程概述
并发编程是计算机科学中的一个复杂领域,它涉及到同时执行多个计算任务以提高效率和响应速度。并发程序允许多个操作同时进行,但它也引入了多种挑战,比如资源共享、竞态条件、死锁和线程同步问题。理解并发编程的基本概念对于设计高效、可靠的系统至关重要。
## 1.2 并发与并行的区别
在深入探讨并发链表重排之前,我们需要明确并发(Con
【Chirp信号抗干扰能力深入分析】:4大策略在复杂信道中保持信号稳定性
# 1. Chirp信号的基本概念
## 1.1 什么是Chirp信号
Chirp信号是一种频率随时间变化的信号,其特点是载波频率从一个频率值线性增加(或减少)到另一个频率值。在信号处理中,Chirp信号的这种特性被广泛应用于雷达、声纳、通信等领域。
## 1.2 Chirp信号的特点
Chirp信号的主要特点是其频率的变化速率是恒定的。这意味着其瞬时频率与时间
社交网络轻松集成:P2P聊天中的好友关系与社交功能实操
# 1. P2P聊天与社交网络的基本概念
## 1.1 P2P聊天简介
P2P(Peer-to-Peer)聊天是指在没有中心服务器的情况下,聊天者之间直接交换信息的通信方式。P2P聊天因其分布式的特性,在社交网络中提供了高度的隐私保护和低延迟通信。这种聊天方式的主要特点是用户既是客户端也是服务器,任何用户都可以直接与其
【实时性能的提升之道】:LMS算法的并行化处理技术揭秘

# 1. LMS算法与实时性能概述
在现代信号处理领域中,最小均方(Least Mean Squares,简称LMS)算法是自适应滤波技术中应用最为广泛的一种。LMS算法不仅能够自动调整其参数以适
【操作系统安全监控策略】:实时监控,预防安全事件的终极指南
# 1. 操作系统安全监控的理论基础
在当今数字化时代,操作系统作为计算机硬件和软件资源管理的核心,其安全性对于整个信息系统的安全至关重要。操作系统安全监控是保障系统安全的一项关键措施,它涉及一系列理论知识与实践技术。本章旨在为读者提供操作系统安全监控的理论基础,包括安全监控的基本概念、主要目标以及监控体系结构的基本组成。
首先,我们将探讨安全监控
【项目管理】:如何在项目中成功应用FBP模型进行代码重构
# 1. FBP模型在项目管理中的重要性
在当今IT行业中,项目管理的效率和质量直接关系到企业的成功与否。而FBP模型(Flow-Based Programming Model)作为一种先进的项目管理方法,为处理复杂
【低功耗设计达人】:静态MOS门电路低功耗设计技巧,打造环保高效电路
# 1. 静态MOS门电路的基本原理
静态MOS门电路是数字电路设计中的基础,理解其基本原理对于设计高性能、低功耗的集成电路至关重要。本章旨在介绍静态MOS门电路的工作方式,以及它们如何通过N沟道MOSFET(NMOS)和P沟道MOSFET(PMOS)的组合来实现逻辑功能。
## 1.1 MOSFET的基本概念
MOSFET,全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )