AWS Lambda函数的编写与部署流程解析
发布时间: 2024-02-24 10:10:26 阅读量: 42 订阅数: 29 
# 1. AWS Lambda函数概述
## 1.1 什么是AWS Lambda函数
AWS Lambda是Amazon Web Services(AWS)提供的无服务器计算服务,允许开发者在无需管理服务器的情况下运行代码。用户只需上传代码至Lambda,AWS会自动管理和扩展基础设施,按实际使用的计算资源付费。
## 1.2 AWS Lambda函数的优势和适用场景
- **弹性扩展**:根据请求量自动扩展计算资源,无需关注服务器容量。
- **按需计费**:只需为实际使用的计算资源付费,无需预留或长期租赁。
- **无服务器管理**:无需管理服务器维护、安全补丁等操作,更专注于业务逻辑开发。
- **多种事件来源**:可通过多种事件触发Lambda函数,如API网关、S3存储桶等。
## 1.3 AWS Lambda函数与传统服务器架构的对比
| 特点 | AWS Lambda函数 | 传统服务器架构 |
| ---------------- | --------------------------------------------- | ------------------------------------------ |
| 管理 | 无需管理服务器,完全由AWS托管 | 需要自行购买、部署、管理服务器 |
| 按需计费 | 按实际使用计算资源付费 | 预留或按时间计费 |
| 弹性扩展 | 自动扩展计算资源以满足请求量 | 需要手动扩展服务器容量 |
| 运维 | 无需维护服务器操作系统、安全补丁等 | 需要负责服务器维护、更新等 |
| 适用场景 | 适用于事件驱动型、规模小、计算密集度低的应用 | 适用于长时间运行、计算密集度高的应用 |
通过以上对比,我们可以看出AWS Lambda函数相对于传统服务器架构在管理、成本和扩展性等方面有诸多优势。在适合的场景下,AWS Lambda函数可以极大地简化开发和运维工作。
# 2. AWS Lambda函数的编写
在AWS Lambda中编写函数是非常简单直接的,只需要选择适当的运行时环境,并编写相应的代码即可。接下来将详细介绍如何编写AWS Lambda函数的代码。
### 2.1 选择合适的运行时环境
AWS Lambda支持多种编程语言的运行时环境,包括但不限于Python、Java、Go和JavaScript等。在编写Lambda函数之前,首先需要选择合适的运行时环境,根据项目需求和个人熟悉程度选择最合适的编程语言。
### 2.2 编写Lambda函数的代码
下面以Python为例,展示一个简单的Lambda函数示例,该函数用于将输入的两个数字相加并返回结果:
```python
import json
def lambda_handler(event, context):
num1 = event['num1']
num2 = event['num2']
result = num1 + num2
return {
'statusCode': 200,
'body': json.dumps({
'result': result
})
}
```
**代码说明:**
- `lambda_handler`为Lambda函数的入口方法,接收事件和上下文作为参数。
- 从事件中获取两个数字进行相加操作。
- 返回包含结果的JSON响应。
### 2.3 处理事件和触发器
AWS Lambda函数的执行是由事件和触发器来驱动的。事件可以是来自各种服务的通知,触发器则定义了Lambda函数执行的条件。在编写Lambda函数时,需要根据具体的业务场景来处理事件和触发器的逻辑,确保函数能够按需启动和执行。
在实际应用中,根据具体业务需求编写Lambda函数的代码,并确保函数的逻辑和事件来源能够正确匹配,以实现自动化、异步处理等功能。
通过上述内容,我们已经了解了如何在AWS Lambda中编写函数的基本步骤和注意事项。接下来,将深入探讨AWS Lambda函数的部署过程。
# 3. AWS Lambda函数的部署
在这一章节中,我们将学习如何在AWS上部署Lambda函数,包括创建Lambda函数、设置函数的执行角色和权限以及配置函数的触发器。
#### 3.1 创建Lambda函数
在AWS管理控制台上,点击“服务”并选择“Lambda”服务。在Lambda控制台上,点击“创建函数”按钮,选择“从头开始创建”。
选择一个适合的运行时环境,比如Node.js、Python、Java等,并设置函数的名称、描述、运行时环境等基本信息。接着可以直接编写函数代码或者上传 ZIP 文件。点击“创建函数”按钮即可完成部署。
#### 3.2 设置函数的执行角色和权限
在Lambda控制台上,找到创建的函数,点击函数名称进入函数详情页面。在“权限”选项卡下,可以配置函数的执行角色。AWS Lambda函数需要执行相关的AWS服务API,因此需要一个包含相关权限的执行角色。点击“添加权限”按钮,选择一个现有的执行角色或者创建一个新的执行角色。
#### 3.3 配置函数的触发器
在Lambda函数详情页面,点击“触发器”选项卡,然后点击“添加触发器”按钮。根据具体的需求,可以选择不同的触发器类型,比如API网关、S3、DynamoDB、CloudWatch事件等。根据选择的触发器类型,配置相应的触发器参数,然后点击“添加”即可完成触发器的配置。
以上就是AWS Lambda函数部署的基本流程,通过这些步骤可以轻松地在AWS上部署自己的Lambda函数。
# 4. AWS Lambda函数的调试与测试
在开发AWS Lambda函数时,调试和测试是至关重要的步骤。本章将详细讨论如何进行Lambda函数的调试与测试,包括使用日志监控、AWS X-Ray和编写测试用例等内容。
#### 4.1 使用日志监控调试Lambda函数
在Lambda函数中,我们可以使用日志监控功能来输出调试信息和错误日志,以便更好地理解函数的执行过程。以下是一个简单的Python Lambda函数示例,演示如何使用日志输出:
```python
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
logger.info('Lambda function was triggered!')
try:
result = 10 / 0
except ZeroDivisionError as e:
logger.error(f'Error: {str(e)}')
return {
'statusCode': 200,
'body': 'Lambda function executed successfully!'
}
```
在上面的示例中,我们通过`logger.info()`和`logger.error()`输出信息和错误日志。当然,你也可以根据实际需求设置不同的日志级别来输出更详细的信息。
#### 4.2 使用AWS X-Ray进行分布式追踪
AWS X-Ray是AWS提供的一项服务,可用于分析和调试分布式应用程序。通过集成X-Ray,我们可以跟踪Lambda函数调用链和性能数据,帮助排查性能问题和优化函数性能。以下是一个简单的Java Lambda函数示例,演示如何使用X-Ray:
```java
package example;
import com.amazonaws.xray.AWSXRay;
import com.amazonaws.xray.handlers.TracingHandler;
public class LambdaHandler {
public String handleRequest(Object input) {
AWSXRay.beginSegment("SegmentName");
// Your Lambda function logic here
AWSXRay.endSegment();
return "Lambda function executed successfully!";
}
}
```
在上面的示例中,我们通过`AWSXRay.beginSegment()`和`AWSXRay.endSegment()`手动创建一个段来记录函数调用链,然后可以在X-Ray控制台查看相应的追踪数据。
#### 4.3 编写单元测试和集成测试
为了保证Lambda函数的质量和稳定性,我们可以编写单元测试和集成测试来验证函数的逻辑和行为。以下是一个简单的JavaScript单元测试示例,演示如何使用Jest框架进行测试:
```javascript
// lambda.js
exports.handler = async (event) => {
return {
statusCode: 200,
body: JSON.stringify('Lambda function executed successfully!')
};
};
// lambda.test.js
const lambda = require('./lambda');
test('Lambda function execution', async () => {
const event = {
// Your test event payload here
};
const response = await lambda.handler(event);
expect(response.statusCode).toBe(200);
expect(typeof response.body).toBe('string');
});
```
在上面的示例中,我们通过Jest框架编写了一个单元测试,验证Lambda函数的返回结果是否符合预期。你可以根据实际情况编写更多的测试用例来覆盖不同的场景。
# 5. AWS Lambda函数的性能优化
AWS Lambda函数的性能优化是保障函数高效稳定运行的重要步骤,本章将讨论如何优化Lambda函数的性能,包括减少函数的启动时间、利用内存与CPU来提升性能以及处理异步和并发请求。
#### 5.1 减少函数的启动时间
在编写Lambda函数时,可以采取以下措施来减少函数的启动时间:
- **精简代码和依赖库**: 移除不必要的代码和依赖库,减少部署包的大小,从而加快函数的启动时间。
- **冷启动优化**: 可以通过预热函数的方式来减少冷启动时间,例如使用CloudWatch事件定时调用函数。
#### 5.2 利用内存与CPU来提升性能
通过配置Lambda函数的内存和CPU资源,可以提升函数的性能:
- **合理配置内存**: 增加函数的内存配置可以提升CPU份额,从而加快函数的运行速度。
- **CPU配置**: 部分运行时环境支持配置CPU份额,可以根据函数的计算密集型程度进行合理配置。
#### 5.3 处理异步和并发请求
针对异步和并发请求,可以采用以下策略来优化Lambda函数的性能:
- **使用异步IO**: 对于IO密集型任务,使用异步IO操作能够提升函数的吞吐量和性能。
- **并发配置**: 根据函数的并发需求,合理配置函数的并发限制以及预留容量,避免因并发不足导致性能瓶颈。
以上是关于AWS Lambda函数性能优化的一些关键点,合理的性能优化策略能够显著提升Lambda函数的执行效率和稳定性。
# 6. AWS Lambda函数的监控与告警
在AWS Lambda函数部署完成后,及时进行监控和告警是非常重要的,可以帮助您及时发现潜在的问题,并确保函数的稳定性和高可用性。本章将介绍如何在AWS Lambda函数中设置监控指标和告警,以及如何分析函数的性能和稳定性数据。
### 6.1 设定CloudWatch监控指标
AWS Lambda函数可以通过Amazon CloudWatch来监控其性能指标和日志数据。您可以在控制台上设置监控指标,如执行次数、执行时间、错误次数等,以便实时跟踪函数的运行状况。
以下是一个示例Python代码,用于在Lambda函数中记录调用次数到CloudWatch:
```python
import boto3
def lambda_handler(event, context):
cloudwatch = boto3.client('cloudwatch')
# 声明一个CloudWatch指标
metric_data = {
'MetricName': 'CustomMetric',
'Dimensions': [
{
'Name': 'FunctionName',
'Value': context.function_name
}
],
'Unit': 'Count',
'Value': 1
}
# 发布指标到CloudWatch
response = cloudwatch.put_metric_data(
Namespace='LambdaMetrics',
MetricData=[metric_data]
)
return {
'statusCode': 200,
'body': response
}
```
### 6.2 创建告警并设置通知
除了监控指标外,您还可以在CloudWatch中创建告警,以便在函数发生异常或性能下降时及时通知相关人员或团队。您可以选择通过电子邮件、短信或其他方式接收告警通知。
以下是一个示例Python代码,用于在CloudWatch中创建告警:
```python
import boto3
def lambda_handler(event, context):
cloudwatch = boto3.client('cloudwatch')
# 创建告警
cloudwatch.put_metric_alarm(
AlarmName='LambdaErrorAlarm',
ComparisonOperator='GreaterThanThreshold',
EvaluationPeriods=1,
MetricName='Errors',
Namespace='AWS/Lambda',
Period=60,
Statistic='Sum',
Threshold=1,
ActionsEnabled=True,
AlarmActions=['arn:aws:sns:us-east-1:123456789012:MyTopic'],
AlarmDescription='Alarm when Lambda function errors occur',
Dimensions=[
{
'Name': 'FunctionName',
'Value': context.function_name
}
]
)
return {
'statusCode': 200,
'body': 'Alarm created successfully'
}
```
### 6.3 分析函数的性能和稳定性数据
最后,您可以利用CloudWatch提供的功能对Lambda函数的性能和稳定性数据进行分析。通过监控指标、日志数据和告警信息,您可以及时发现问题,优化函数的性能,并保证其持续稳定运行。
以上是AWS Lambda函数监控与告警的基本内容,希望对您有所帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨AWS云计算平台的各个方面,从搭建与配置指南、EC2实例创建与初始化、Lambda函数编写与部署,到IAM身份验证与权限管理的最佳实践,CloudWatch监控系统设置和日志分析,SNS与SQS消息队列系统的应用,Route 53域名服务与负载均衡设置,以及AWS IoT物联网平台接入与数据处理流程。通过详细解析每个主题,读者将全面了解如何在AWS平台上进行计算、存储、管理和监控,为构建可靠、安全、高效的云计算架构提供指导和实践经验。无论您是初学者还是经验丰富的专业人士,本专栏都将为您提供实用的知识和技巧,助力您在AWS云计算平台上取得成功。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
【Python预测模型构建全记录】:最佳实践与技巧详解
# 1. Python预测模型基础
Python作为一门多功能的编程语言,在数据科学和机器学习领域表现得尤为出色。预测模型是机器学习的核心应用之一,它通过分析历史数据来预测未来的趋势或事件。本章将简要介绍预测模型的概念,并强调Python在这一领域中的作用。
## 1.1 预测模型概念
预测模型是一种统计模型,它利用历史数据来预测未来事件的可能性。这些模型在金融、市场营销、医疗保健和其
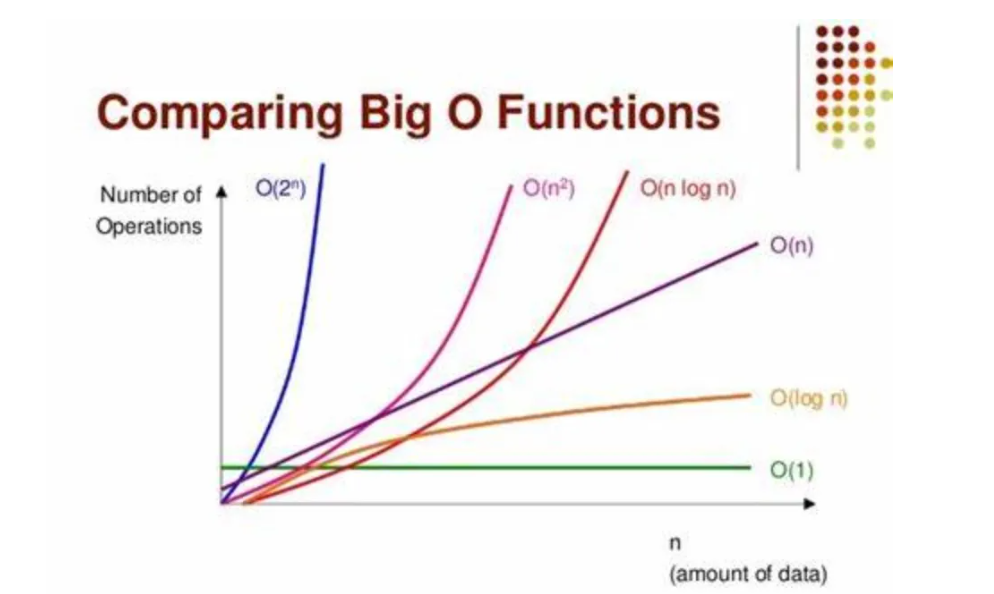
【算法竞赛中的复杂度控制】:在有限时间内求解的秘籍
# 1. 算法竞赛中的时间与空间复杂度基础
## 1.1 理解算法的性能指标
在算法竞赛中,时间复杂度和空间复杂度是衡量算法性能的两个基本指标。时间复杂度描述了算法运行时间随输入规模增长的趋势,而空间复杂度则反映了算法执行过程中所需的存储空间大小。理解这两个概念对优化算法性能至关重要。
## 1.2 大O表示法的含义与应用
大O表示法是用于描述算法时间复杂度的一种方式。它关注的是算法运行时
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
模型训练的动态Epochs策略
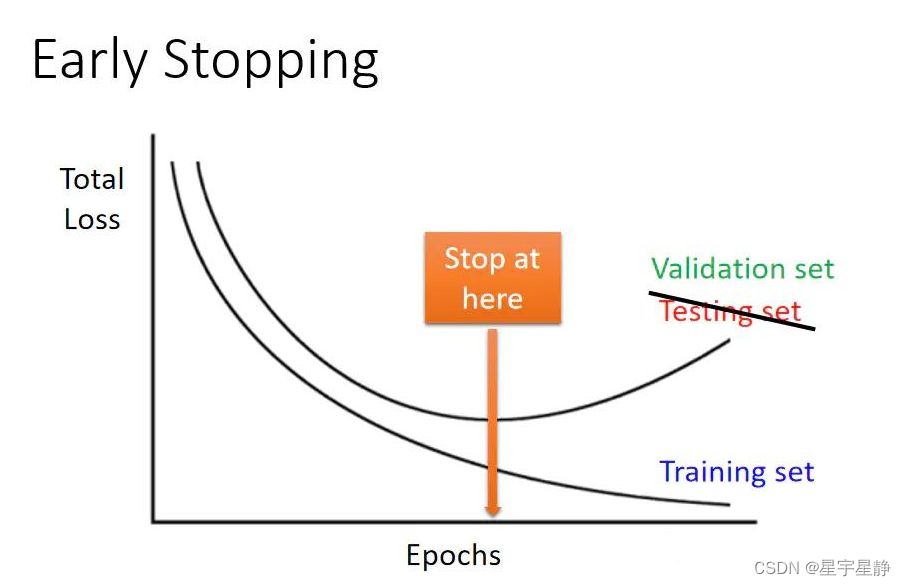
# 1. 模型训练基础与Epochs概念
在机器学习与深度学习模型的训练过程中,模型训练的循环次数通常由一个重要的参数控制:Epochs。简单来说,一个Epoch代表的是使用训练集中的所有数据对模型进行一次完整训练的过程。理解Epochs对于掌握机器学习模型训练至关重要,因为它的选择直接影响到模型的最终性能。
## Epochs的作用
Epochs的作用主要体现在两个方面:
- **模型参数更新:** 每一
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
贝叶斯优化:智能搜索技术让超参数调优不再是难题
# 1. 贝叶斯优化简介
贝叶斯优化是一种用于黑盒函数优化的高效方法,近年来在机器学习领域得到广泛应用。不同于传统的网格搜索或随机搜索,贝叶斯优化采用概率模型来预测最优超参数,然后选择最有可能改进模型性能的参数进行测试。这种方法特别适用于优化那些计算成本高、评估函数复杂或不透明的情况。在机器学习中,贝叶斯优化能够有效地辅助模型调优,加快算法收敛速度,提升最终性能。
接下来,我们将深入探讨贝叶斯优化的理论基础,包括它的工作原理以及如何在实际应用中进行操作。我们将首先介绍超参数调优的相关概念,并探讨传统方法的局限性。然后,我们将深入分析贝叶斯优化的数学原理,以及如何在实践中应用这些原理。通过对
探索与利用平衡:强化学习在超参数优化中的应用
# 1. 强化学习与超参数优化的交叉领域
## 引言
随着人工智能的快速发展,强化学习作为机器学习的一个重要分支,在处理决策过程中的复杂问题上显示出了巨大的潜力。与此同时,超参数优化在提高机器学习模型性能方面扮演着关键角色。将强化学习应用于超参数优化,不仅可实现自动化,还能够通过智能策略提升优化效率,对当前AI领域的发展产生了深远影响。
## 强化学习与超参数优化的关系
强化学习能够通过与环境的交互来学
模型参数泛化能力:交叉验证与测试集分析实战指南

# 1. 交叉验证与测试集的基础概念
在机器学习和统计学中,交叉验证(Cross-Validation)和测试集(Test Set)是衡量模型性能和泛化能力的关键技术。本章将探讨这两个概念的基本定义及其在数据分析中的重要性。
## 1.1 交叉验证与测试集的定义
交叉验证是一种统计方法,通过将原始数据集划分成若干小的子集,然后将模型在这些子集上进行训练和验证,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )