【Python网络编程速成】:urllib2源码揭秘与常见问题解决指南(专家级urllib2使用技巧)
发布时间: 2024-10-07 17:53:24 阅读量: 7 订阅数: 7 
# 1. Python网络编程基础和urllib2简介
Python作为一种广泛应用于网络编程的高级语言,提供了丰富多样的网络编程工具库。而`urllib2`正是Python标准库中的一个用于处理URLs的模块,它提供了一种便捷的方式来读取URLs,处理重定向,处理用户认证以及维护状态信息。
在本章中,我们将介绍Python网络编程的基础知识,并对`urllib2`进行一个基本的概述。我们会了解网络编程中的核心概念,以及如何使用`urllib2`模块执行基本的HTTP请求和响应处理。同时,对`urllib2`的安装和设置过程进行简单说明。
接下来,我们将从一些实例开始,展示如何使用`urllib2`完成简单的网络任务,比如发送GET和POST请求、处理异常以及如何使用urllib2解析和下载网页内容。此外,我们还会讨论与`urllib2`相关的其他模块和库,如`urllib`,`httplib`,`urlparse`等,以帮助读者构建一个对`urllib2`的深入理解。
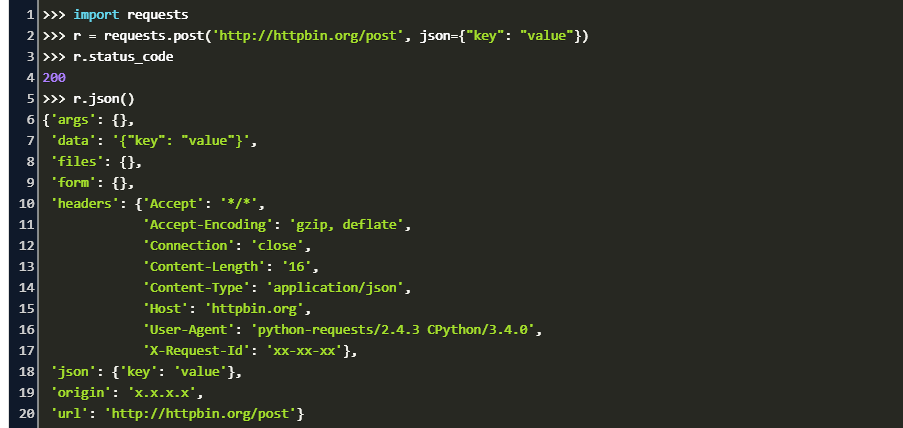
以下是使用`urllib2`进行网络请求的一个简单示例代码:
```python
import urllib2
# 创建一个请求对象
request = urllib2.Request('***')
try:
# 发送请求并获取响应
response = urllib2.urlopen(request)
# 读取响应数据
data = response.read()
print(data)
except urllib2.HTTPError as e:
# 处理HTTP错误响应
print("Error code: ", e.code)
except Exception as e:
print("Some error: ", e)
```
这段代码展示了从发送请求、接收响应到错误处理的整个流程,是学习`urllib2`不可或缺的第一步。
# 2. urllib2源码分析
## 2.1 urllib2模块架构
### 2.1.1 urllib2的主要组件
在Python的网络编程中,`urllib2` 是一个用于打开URL的模块,相当于网络请求的入口。`urllib2` 由几个核心组件构成,主要包括以下几个部分:
- `Request` 对象:它封装了网络请求的各个部分,包括URL、请求头、数据体等。
- `Opener` 对象:用于打开URL的低级接口,是创建网络连接的直接手段。
- `Handler` 对象:抽象层,它通过定义一系列的方法来处理网络请求的各种事件。
- `urlopen` 和 `build_opener` 函数:简化API,`urlopen` 用来发送请求并接收响应,而 `build_opener` 用于创建一个自定义的 `Opener` 对象。
这些组件协同工作,支持HTTP、HTTPS等不同协议的请求,并能够处理多种网络异常情况。
### 2.1.2 urllib2请求与响应流程
`urllib2` 的请求和响应流程遵循HTTP协议规范。当你调用 `urlopen` 函数时,它会按以下步骤进行:
1. 创建一个请求 `Request` 对象,并填充要请求的URL和任何额外的请求头。
2. 选择合适的 `Handler`,它们会处理请求的各个阶段。
3. 请求被传递给 `Opener` 对象,这个对象负责建立实际的网络连接。
4. `Opener` 使用底层网络库(如socket)发送请求,并等待服务器响应。
5. 收到响应后,`Handler` 会进行必要的处理,例如自动处理重定向,或处理服务器返回的错误代码。
6. 最终,用户获得一个响应对象,可以从中读取响应数据。
整个过程是高度模块化的,你可以自定义 `Handler` 来控制和修改请求处理行为。
## 2.2 urllib2内部机制
### 2.2.1 Handler和Opener机制
`Handler` 和 `Opener` 是 `urllib2` 模块的精华所在,它们共同负责处理网络请求和响应。
- `Handler`:是处理请求和响应的方法的集合,每个方法对应请求和响应的特定阶段。例如,`HTTPRedirectHandler` 可以处理HTTP重定向,而 `HTTPDefaultErrorHandler` 可以处理服务器返回的错误码。
- `Opener`:是一个包含多个 `Handler` 的对象。`Opener` 的主要作用是使用 `Handler` 来处理请求,并且打开网络连接。
`urllib2` 默认提供了一系列常用的 `Handler`,用户也可以通过继承 `BaseHandler` 类来创建自己的 `Handler`,通过重写方法来实现特定的功能。
### 2.2.2 Transport层的实现
`urllib2` 通过 `Transport` 层实现网络连接。`Transport` 层主要涉及与底层网络协议的交互,包括建立连接、发送请求和接收响应等。
该层内部通常会使用Python标准库中的 `httplib`、`ftplib` 等模块,或通过第三方库如 `requests` 来实现网络请求。`urllib2` 通过抽象的接口,使得开发者无需关心底层实现细节,能够专注于业务逻辑的处理。
### 2.2.3 缓存和代理处理
`urllib2` 支持缓存和代理设置,这对提升网络请求性能和满足特定网络访问需求尤为重要。
- 缓存处理:`urllib2` 可以通过 `Cache-Control` 请求头来控制缓存行为,如设置缓存的最大使用量、缓存时间等。
- 代理处理:通过 `ProxyHandler`,用户可以指定请求应该通过的代理服务器。这在访问特定网络资源时非常有用,尤其是在网络受限的环境中。
通过这些高级功能,`urllib2` 提供了一种灵活且强大的方式来处理复杂的网络请求场景。
## 2.3 urllib2源码深入剖析
### 2.3.1 核心类和方法
`urllib2` 的核心类包括 `Request`、`OpenerDirector`、`BaseHandler` 等。每个类都有其特定的职责和作用。
- `Request` 类:它封装了请求的所有元素,并提供了一个 `get_data` 方法来获取请求数据。
- `OpenerDirector` 类:这是实际处理请求的类。它管理着 `Handler` 链,并且负责创建、维护和使用 `Opener` 对象。
- `BaseHandler` 类:它是所有 `Handler` 的基类。通常,开发者会通过继承这个类并覆盖特定的方法来实现自定义的 `Handler`。
通过分析这些核心类和它们的方法,我们可以更好地理解 `urllib2` 如何协同工作以及如何实现网络请求和响应的处理。
### 2.3.2 异常处理源码解析
异常处理是 `urllib2` 中的重要组成部分。`urllib2` 定义了各种异常类,以便在发生错误时提供准确的反馈。
在源码中,异常处理逻辑遍布于各个 `Handler` 的方法中。例如,`HTTPErrorProcessor` 类中的 `http_response` 方法会捕获并处理来自服务器的错误响应。如果HTTP响应码表示出错,则会抛出一个 `HTTPError` 异常。
异常处理机制的实现保证了 `urllib2` 的鲁棒性,使得网络请求在遇到各种不可预知的问题时能够给出明确的错误信息,并允许用户通过异常处理机制来应对。
### 2.3.3 代码优化与重构建议
分析 `urllib2` 的源码,不难发现其中有一些优化和重构的空间。
- **模块化设计**:`urllib2` 的模块化设计是其优势之一,但可以通过定义更多的接口和抽象类来进一步提升模块化水平。
- **异常处理**:尽管异常处理机制很完备,但过多的异常类型可能会导致复杂的调用栈。建议通过合并或精简异常类型来简化异常处理逻辑。
- **性能优化**:`urllib2` 在某些情况下可能存在性能瓶颈。通过引入异步IO或协程支持可以提高性能,特别是在处理大量或高延迟的网络请求时。
通过这些优化措施,`urllib2` 可以成为一个更加高效且易于使用的网络请求库。
以上是根据您的目录框架信息,提供的文章第二章节的内容。以下是整个Markdown结构:
```markdown
# 第二章:urllib2源码分析
## 2.1 urllib2模块架构
### 2.1.1 urllib2的主要组件
`urllib2` 模块由几个核心组件构成,包括 `Request` 对象、`Opener` 对象、`Handler` 对象,以及提供简化API的 `urlopen` 和 `build_opener` 函数。这些组件协同工作,支持多种协议的网络请求,并能处理网络异常。
### 2.1.2 urllib2请求与响应流程
`urllib2` 的请求和响应流程遵循HTTP协议规范,具体步骤包括创建请求对象、选择合适的 `Handler`,请求被传递给 `Opener` 对象,该对象负责建立实际的网络连接,然后服务器响应被处理,并最终返回给用户。
## 2.2 urllib2内部机制
### 2.2.1 Handler和Opener机制
`Handler` 和 `Opener` 是 `urllib2` 的核心机制。`Handler` 处理请求和响应的各个阶段,而 `Opener` 是 `Handler` 的容器,负责打开URL和发送请求。
### 2.2.2 Transport层的实现
`urllib2` 通过 `Transport` 层与底层网络协议交互,处理网络连接的建立和数据的传输。它通常利用Python的标准库模块实现,但也可以通过第三方库来扩展其功能。
### 2.2.3 缓存和代理处理
`urllib2` 支持通过 `Cache-Control` 请求头来控制缓存行为,并允许用户通过 `ProxyHandler` 来设置代理服务器,这对提升网络请求性能和满足特定网络访问需求很有帮助。
## 2.3 urllib2源码深入剖析
### 2.3.1 核心类和方法
深入分析 `urllib2` 的核心类,例如 `Request`、`OpenerDirector` 和 `BaseHandler`,以及这些类提供的方法,可以让我们更好地理解 `urllib2` 的工作原理。
### 2.3.2 异常处理源码解析
`urllib2` 源码中的异常处理逻辑是其稳定性的保障。分析这些逻辑,可以让我们了解在遇到网络问题时,`urllib2` 是如何提供准确反馈并允许用户进行异常处理的。
### 2.3.3 代码优化与重构建议
通过对 `urllib2` 源码的分析,可以提出一些优化和重构建议,例如进一步的模块化设计,简化异常处理逻辑,以及性能优化等方面。
```
请注意,上述内容是根据章节标题和子标题提供的示例性描述,具体的实现和细节需要根据实际的 `urllib2` 源码来编写。
# 3. urllib2使用技巧与最佳实践
## 3.1 urllib2高级功能应用
### 3.1.1 处理HTTP重定向
HTTP重定向是一种常见的网络协议行为,它允许服务器指引客户端到一个新的地址继续请求。在urllib2中处理HTTP重定向非常简单,通常不需要额外的代码,因为urllib2会自动处理符合HTTP/1.1标准的3xx响应。
```python
import urllib2
# 请求一个通常会重定向的网址,例如GitHub
req = urllib2.Request('***')
response = urllib2.urlopen(req)
print(response.url) # 输出最终重定向到的URL地址
```
上述代码演示了最简单的重定向处理。但有时候,你可能需要控制重定向的行为,比如希望遵循某些重定向,但又不希望总是无条件跟随。
```python
from urllib2 import HTTPError, URLError
# 设置超时
opener = urllib2.build_opener()
opener.addheaders.append(('User-Agent', 'Mozilla/5.0'))
req = urllib2.Request('***', headers={'Accept-Language': 'en-US,en;q=0.5'})
try:
response = opener.open(req)
except HTTPError as e:
print(e.code) # 打印HTTP状态码
print(e.msg) # 打印HTTP状态信息
except URLError as e:
print(e.reason) # 打印错误原因
```
### 3.1.2 身份验证和授权
当访问需要身份验证的资源时,urllib2提供了方便的HTTPBasicAuthHandler来处理用户名和密码的认证。
```python
import urllib2
# 创建一个请求
req = urllib2.Request('***')
# 设置授权信息
password_mgr = urllib2.HTTPPasswordMgrWithDefaultRealm()
top_level_url = "***"
password_mgr.add_password(None, top_level_url, "username", "password")
handler = urllib2.HTTPBasicAuthHandler(password_mgr)
opener = urllib2.build_opener(handler)
# 使用opener打开URL
response = opener.open(req)
html = response.read()
```
### 3.1.3 Cookie的管理
有时候,需要对网站的Cookie进行管理,urllib2提供了Cookie相关的处理器来处理这些场景。
```python
import urllib2, http.cookiejar
# 创建cookie处理器
cookie_handler = urllib2.HTTPCookieProcessor(http.cookiejar.CookieJar())
# 创建一个opener
opener = urllib2.build_opener(cookie_handler)
# 使用opener打开URL
response = opener.open('***')
```
## 3.2 urllib2性能优化
### 3.2.1 并发请求处理
在进行大规模网络请求时,一个一个顺序请求效率低下,urllib2可以通过多线程或异步IO实现并发请求处理。
```python
import urllib2
from threading import Thread
def fetch_url(url):
try:
response = urllib2.urlopen(url)
return response.read()
except urllib2.URLError as e:
print('Failed to fetch:', url, e.reason)
def fetch_all(urls):
threads = []
for url in urls:
thread = Thread(target=fetch_url, args=(url,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
if __name__ == '__main__':
urls = ['***'] * 100 # 举例100个相同的URL
fetch_all(urls)
```
### 3.2.2 连接池的使用
urllib2没有内置连接池的实现,但是可以借助第三方库,例如`requests`,来实现连接池的优化。
```python
import requests
session = requests.Session()
# 创建连接池
session.mount('***', requests.adapters.HTTPAdapter(pool_connections=10, pool_maxsize=10))
# 使用session发起请求
response = session.get('***')
```
## 3.3 urllib2异常处理与调试
### 3.3.1 常见错误及其应对策略
urllib2在请求网络资源时可能会遇到多种异常,了解并合理处理这些异常对于网络编程非常重要。
```python
import urllib2
try:
response = urllib2.urlopen('***')
except urllib2.HTTPError as e:
# 处理HTTP错误
print('The server couldn\'t fulfill the request.')
print('Error code: ', e.code)
except urllib2.URLError as e:
# 处理网络问题
print('We failed to reach a server.')
print('Reason: ', e.reason)
except Exception as e:
# 处理其他错误
print('Something went wrong: ', e)
```
### 3.3.2 日志记录和分析技巧
使用日志记录不仅可以帮助开发者在开发过程中调试程序,还能在程序部署后,对程序运行情况进行监控和分析。
```python
import urllib2
import logging
# 配置日志
logging.basicConfig(level=***)
# 创建一个请求
req = urllib2.Request('***')
try:
response = urllib2.urlopen(req)
except Exception as e:
logging.error('Request failed: %s', str(e))
# 输出内容
print(response.read())
```
以上章节内容介绍了如何使用urllib2来处理重定向、身份验证、Cookie管理以及性能优化中的并发请求处理和连接池使用。同时,也提供了异常处理和日志记录的策略,旨在帮助开发者更好地掌握urllib2库的高级技巧和最佳实践。
# 4. urllib2常见问题与解决方案
## 4.1 HTTP请求相关问题
### 4.1.1 HTTP错误代码处理
在使用urllib2进行HTTP请求时,可能会遇到各种HTTP错误代码,如404、500等。处理这些错误代码的常见做法是使用try-except语句块捕获异常。urllib2会抛出`HTTPError`异常,其中包含了错误代码和错误信息。开发者可以根据错误代码采取相应的措施。
```python
import urllib.request
try:
response = urllib.request.urlopen('***')
except urllib.error.HTTPError as e:
print(f'Error code: {e.code}')
print(f'Reason: {e.reason}')
```
以上代码尝试访问一个不存在的页面,并捕获了`HTTPError`异常。`e.code`属性将给出HTTP错误码,而`e.reason`提供了错误原因。根据错误码,可以决定是否重试请求、返回特定错误信息或者记录日志等。
### 4.1.2 HTTPS连接问题
HTTPS是一种安全的网络协议,它通过SSL/TLS实现数据的加密传输。urllib2默认支持HTTPS连接,但是如果遇到SSL证书问题,如证书无效或者过期,会导致连接失败。
为了处理这种情况,可以临时关闭SSL证书验证,虽然这种方法会降低安全性,但在测试或者信任的环境下可以作为一种快速解决方案:
```python
import urllib.request
import ssl
context = ssl._create_unverified_context() # 禁用证书验证
response = urllib.request.urlopen('***', context=context)
```
上述代码创建了一个不验证SSL证书的上下文,并用它来打开一个HTTPS连接。通常,这个上下文应该仅在开发和测试环境中使用,生产环境始终应该验证SSL证书。
## 4.2 urllib2安全问题
### 4.2.1 SSL证书验证问题
如前所述,SSL证书验证是确保HTTPS连接安全的关键部分。当SSL证书验证失败时,可能是因为证书不被信任、证书吊销、证书和域名不匹配等原因。不推荐完全禁用SSL证书验证,而应该确保服务器的SSL证书是有效的,并且使用受信任的证书颁发机构(CA)签发的证书。
如果只是想临时忽略某些特定的证书错误,可以使用`cert_ignore_error`上下文管理器:
```python
import urllib.request
import ssl
cert_ignore_errors = ssl.CERT_NONE # 忽略所有证书错误
context = ssl._create_default_context(cert_ignore_errors)
response = urllib.request.urlopen('***', context=context)
```
### 4.2.2 防止请求劫持和重放攻击
在处理敏感数据时,需要确保HTTP请求的安全性。urllib2本身没有内置防止请求劫持和重放攻击的机制。因此,必须依赖HTTPS提供的传输层安全保证。
为了进一步提高安全性,可以在应用程序层面增加额外的验证措施,如使用OAuth、API密钥等机制来确保请求的合法性。同时,对于敏感操作应确保使用POST、PUT等方法,并且只接受HTTPS请求。
## 4.3 urllib2与现代Web特性的兼容性问题
### 4.3.1 会话保持和维持
HTTP是一种无状态协议,但是有时候需要维持会话状态,比如用户登录。urllib2提供了一个机制用于模拟会话,通过`HTTPCookieProcessor`可以处理Cookie,实现会话的维持。
```python
import urllib.request
import urllib.error
cookie_handler = urllib.request.HTTPCookieProcessor()
opener = urllib.request.build_opener(cookie_handler)
urllib.request.install_opener(opener)
try:
response = urllib.request.urlopen('***')
except urllib.error.HTTPError as e:
print('Login failed:', e.code)
```
这段代码创建了一个会话,其中包含处理Cookie的处理器。该处理器会在后续的请求中发送之前接收到的Cookie,以此维持会话状态。
### 4.3.2 支持新的HTTP方法和头部
urllib2默认支持一些标准的HTTP方法(如GET、POST、PUT、DELETE等)。如果需要发送自定义的HTTP头部,可以通过`add_header`方法添加到请求中:
```python
req = urllib.request.Request('***', method='GET')
req.add_header('X-Custom-Header', 'CustomValue')
response = urllib.request.urlopen(req)
```
这里创建了一个HTTP请求,并添加了一个自定义的头部`X-Custom-Header`。对于现代Web服务可能使用的一些非标准HTTP方法,可能需要在请求头中添加`X-HTTP-Method-Override`等。
| 特性 | 支持情况 | 说明 |
| --- | --- | --- |
| HTTPS | 支持 | 默认支持HTTPS连接 |
| Cookie处理 | 支持 | 通过HTTPCookieProcessor进行Cookie的设置和获取 |
| 自定义头部 | 支持 | 可以通过add_header方法添加 |
| HTTP方法支持 | 部分 | 标准HTTP方法支持,对新特性的自定义方法可能需要特殊处理 |
| 会话维持 | 支持 | 可以通过会话模拟维持状态 |
在处理现代Web服务时,需要综合考虑这些特性,以确保网络请求的安全性和功能性。随着Web技术的不断进步,urllib2可能需要与第三方库如`requests`结合,以支持更多新特性和优化。
# 5. urllib2与第三方库的结合使用
## 5.1 结合requests库的高级用法
urllib2是Python标准库的一部分,尽管功能强大,但在易用性上略显不足。幸运的是,第三方库如requests提供了一个更简洁、更直观的API来处理HTTP请求。在本节中,我们将探索如何结合使用urllib2和requests库来增强我们的网络编程能力。
### 5.1.1 requests与urllib2的对比
虽然urllib2在Python中被广泛使用,但requests库以更加简洁和直观的API著称。以下是一个简单的对比,说明了两者在使用上的差异。
**urllib2 示例代码:**
```python
import urllib2
req = urllib2.Request('***')
response = urllib2.urlopen(req)
data = response.read()
```
**requests 示例代码:**
```python
import requests
response = requests.get('***')
data = response.text
```
从上面的例子可以看出,使用requests库可以更加简洁地完成相同的功能。requests的API设计更接近于开发者日常使用的语言,而非底层的HTTP协议细节。
### 5.1.2 requests的异步IO支持
异步编程是处理高并发网络请求的关键技术之一。requests库通过支持异步IO,使用户能够更加高效地处理大量网络请求。
**使用`aiohttp`进行异步请求示例代码:**
```python
import aiohttp
import asyncio
import requests
async def fetch_data(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch_data(session, '***')
print(html)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
```
在上述代码中,使用了`aiohttp`库配合`asyncio`来实现异步请求。这样能够显著提高网络请求的效率,特别是在涉及到大量请求时。
## 5.2 其他Python网络编程库概览
### 5.2.1 HTTPX的介绍和应用
HTTPX是一个新型的Python HTTP客户端库,它在requests的基础上进行了扩展,提供了异步IO支持,并且是完全类型注释的。
**使用HTTPX进行同步请求示例代码:**
```python
import httpx
response = httpx.get('***')
print(response.text)
```
**使用HTTPX进行异步请求示例代码:**
```python
import httpx
import asyncio
async def fetch_url(url):
async with httpx.AsyncClient() as client:
response = await client.get(url)
return response.text
async def main():
html = await fetch_url('***')
print(html)
asyncio.run(main())
```
HTTPX不仅能够处理HTTP/1.1协议,还支持HTTP/2,使其成为处理现代Web服务的强大工具。
### 5.2.2 Twisted框架的事件驱动模型
Twisted是一个事件驱动的网络编程框架,它提供了一个完全不同的网络编程范式。它使用事件驱动的方式处理网络事件,非常适合于需要同时处理多个网络连接的应用。
**Twisted框架处理HTTP请求的简单示例:**
```python
from twisted.web.client import Agent, HTTPConnectionPool
from twisted.internet import reactor
agent = Agent(reactor, HTTPConnectionPool(reactor))
d = agent.request(b'GET', b'***')
def requestDone(response):
print(response.code)
print(response.delivered_body)
reactor.stop()
d.addCallback(requestDone)
reactor.run()
```
在上述代码中,Twisted框架通过定义回调函数来处理请求响应。这种模型需要程序员理解事件驱动编程的概念,但它能够有效地处理大量的并发连接。
本章通过对比urllib2和其他第三方库,展示了网络编程的多样性和复杂性,同时也指出了在不同场景下选择合适工具的重要性。这些库之间的结合使用,不仅能够提升开发效率,还能增强网络应用的性能和可靠性。
# 6. urllib2项目实战与案例分析
## 6.1 实战项目:构建一个简单的网络爬虫
在本章节中,我们将深入了解如何使用urllib2库来构建一个简单的网络爬虫。这将包括网页抓取以及如何解析和存储抓取到的数据。
### 6.1.1 使用urllib2进行网页抓取
首先,为了演示如何使用urllib2进行网页抓取,我们将创建一个Python脚本,该脚本可以从一个指定的URL中获取网页内容。我们将使用urllib2打开和读取网页,然后将其内容打印出来。
```python
import urllib.request
def fetch_url_content(url):
try:
with urllib.request.urlopen(url) as response:
# 确保网页内容返回的状态码是200 OK
if response.status == 200:
content = response.read()
return content
else:
print(f"Error fetching URL {url}: {response.status}")
except urllib.error.URLError as e:
print(f"Failed to fetch URL {url}: {e.reason}")
if __name__ == "__main__":
target_url = "***"
content = fetch_url_content(target_url)
if content:
print(content)
```
### 6.1.2 数据解析和存储
一旦我们获取了网页的内容,通常需要解析它以提取有用的数据。Python提供了多种方法可以做到这一点,包括使用`html.parser`模块。下面是一个简单的例子,展示了如何提取HTML页面中的标题。
```python
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print(f"Start tag: {tag}")
def handle_endtag(self, tag):
print(f"End tag: {tag}")
def handle_data(self, data):
if data.strip():
print(f"Data: {data}")
def handle_startendtag(self, tag, attrs):
print(f"Empty tag: {tag}")
parser = MyHTMLParser()
parser.feed(content)
# 假设我们已经通过解析得到了需要的数据,下面是如何将这些数据保存到文件
with open("output.txt", "wb") as f:
f.write(content)
```
## 6.2 案例分析:复杂网络请求处理
### 6.2.1 面对高负载网站的请求策略
当面对高负载的网站时,单个请求可能会导致服务器过载或被封禁IP。我们需要制定一些策略来减少负载并提高请求的成功率。
下面是一些处理高负载网站请求的策略:
- 分布式爬虫:利用多台机器或分布式代理服务器分摊请求压力。
- 限速:在爬虫中设置合理的请求间隔,遵循robots.txt协议。
- 错误处理:增加异常处理机制,例如暂时性错误(503)时重试,限速或更改用户代理。
### 6.2.2 自动化网络测试和监控工具开发
网络测试和监控是确保网站和服务稳定运行的重要环节。使用urllib2可以开发出一套自动化工具来进行这些工作。
下面是一个示例代码片段,展示如何使用urllib2进行HTTP请求的响应时间监控。
```python
import time
def test_url_response_time(url, repeat=5):
start = time.time()
for _ in range(repeat):
fetch_url_content(url)
end = time.time()
response_time = (end - start) / repeat
print(f"Average response time for {url}: {response_time:.3f} seconds")
if __name__ == "__main__":
test_url = "***"
test_url_response_time(test_url, 10)
```
在本章节中,我们通过实际的例子展示了如何使用urllib2库构建网络爬虫和网络监控工具。这些技能对于处理复杂的网络请求非常有用,并且可以扩展到更高级的项目和用例中。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python cookielib库的性能优化:提升网络请求效率

# 1. Python cookielib库概述
Python作为一个强大的编程语言,其丰富的标准库为各种应用提供了便利。cookielib库,作为Python标准库的一部分,主要负责HTTP cookie的管理。这个库允许开发者存储、修改以及持久化cookie,这对于需要处理HTTP请求和响应的应用程序来说至关重要。
## 1.1 cook
【Django认证视图的RESTful实践】:创建RESTful认证接口和最佳实践
# 1. Django认证视图简介
在当今的网络时代,用户认证和授权是构建Web应用不可或缺的环节。Django作为一个功能强大的Python Web框架,提供了完善的认证系统来简化这一过程。Django的认证视图是其中的核心组件,它负责处理登录、登出和用户注册等操作。
Python数学序列与级数处理秘籍:math库在复杂计算中的应用

# 1. Python数学序列与级数处理概述
数学序列与级数是计算机编程和数据科学中不可或缺的数学基础。在Python中,这些概念可以通过简洁易懂的方式进行构建和计算。序列通常是一系列按照特定顺序排列的数字,而级数则是序列的和的延伸。理解和应用这些数学概念对于构建高效的算法和进行精确的数据分析至关重
Django模板上下文中的会话管理:在模板中处理用户会话的有效方法

# 1. Django模板上下文的基础知识
Django模板系统是构建Web应用时分离设计和逻辑的关键组件。在本章中,我们将详细介绍Django模板
Python tempfile的测试与验证:单元测试编写指南保证代码质量
# 1. Python tempfile概述与应用
Python的tempfile模块提供了一系列工具用于创建临时文件和临时目录,并在使用完毕后清理这些临时文件或目录。在现代软件开发中,我们常常需要处理一些临时数据,tempfile模块让这个过程变得简单、安全且高效。本章将简要介绍tempfile模块的基本概念,并通过实例来说明如何在不同场景下应用tempfile模块。
## 1.1 tempfi
【Python 3的traceback改进】:新特性解读与最佳实践指南
# 1. Python 3 traceback概述
Python作为一门高级编程语言,在编写复杂程序时,难免会遇到错误和异常。在这些情况发生时,traceback信息是帮助开发者快速定位问题的宝贵资源。本章将为您提供对Python 3中traceback机制的基本理解,介绍其如何通过跟踪程序执行的堆栈信息来报告错误。
Python 3 的traceback通过
【并发编程高级】:结合Decoder实现Python高效数据处理

# 1. 并发编程基础与Python并发模型
并发编程是现代软件开发中一个不可或缺的部分,它允许程序同时执行多个任务,极大地提升了应用的效率和性能。Python作为一种高级编程语言,在并发编程领域也有着自己独特的模型和工具。本章将从Python并发模型的基本概念讲起,带领读者了解Python如何处理并发任务,并探讨在实际编程中如何有效地利用这些并发模型。
首先,我们将解释什么是进程和线程,它们之间的区别以及各自的优
【Python网络编程与Ajax交互】:urllib2在Ajax请求中的应用与实践(urllib2与Ajax交互教程)

# 1. 网络编程与Ajax交互概述
## 1.1 网络编程的基础概念
网络编程是IT领域不可或缺的一部分,它涉及客户端与服务器之间的信息交换。网络编程允许软件组件通过网络进行数据传输,并在多种硬件和操作系统之间实现良好的兼容
【提升Django数据库性能】:5步查询优化与索引策略

# 1. Django数据库性能概述
随着Web应用的发展,数据库性能优化已经成为提高应用响应速度和用户体验的关键。Django,一个高级Python Web框架,它自动生成数据库访问层代码,简化了Web开发流程。然而,如果不恰当地使用Django
【Django表单进阶】:forms.util中的陷阱全解析及避免策略
# 1. Django表单基础知识回顾
在本章中,我们将对Django表单的基础知识进行一个全面的回顾。Django作为Python的一个强大的Web框架,其表单系统是构建Web应用程序不可或缺的一部分。我们将从表单的基本概念讲起,逐步深入到表单的构建、验证和处理过程。
## 表单
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )