




【Python网络编程案例集】:urllib2在XML解析与多线程中的高效应用(urllib2实战案例分析)


Python 中的多线程爬网程序
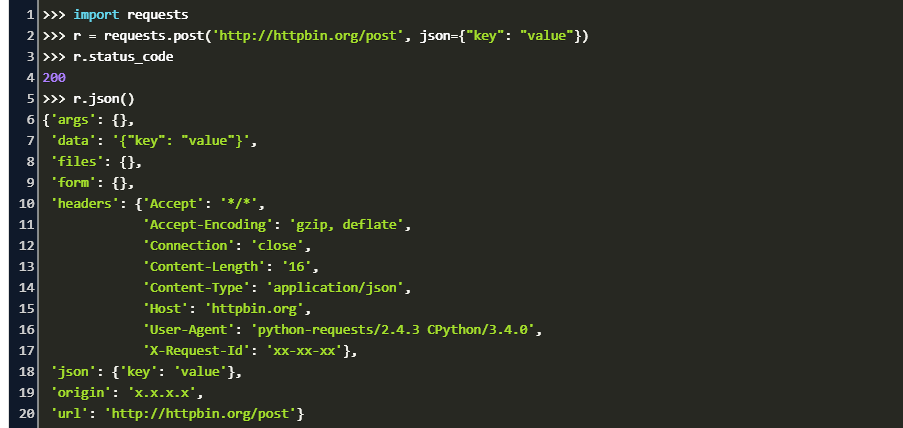
1. Python网络编程概述与urllib2入门
网络编程是现代软件开发中不可或缺的技能之一,尤其是在构建需要与网络进行交互的应用程序时。Python作为一种高级编程语言,提供了强大的网络编程库。urllib2是Python标准库中的一个模块,专为网络请求而设计,它提供了非常方便的API来发送网络请求,并处理HTTP以及HTTPS等网络协议。
Python网络编程的核心是理解和操作网络协议。urllib2不仅支持基本的HTTP请求,还能通过各种处理器和插件处理代理、身份验证等复杂的网络场景。本章将介绍网络编程的基础知识,并引导读者入门urllib2,为后续章节中深入学习和实践做准备。
2. urllib2模块详解与实践
2.1 urllib2模块基本使用
2.1.1 发送请求与接收响应
当开始使用urllib2模块进行网络请求时,首先要了解其基本的请求发送和响应接收的机制。urllib2模块允许我们使用Request对象来表示要发送的请求,然后用urlopen方法打开并获取响应。
以下是简单的示例代码:
- import urllib2
- # 创建请求对象
- req = urllib2.Request('***')
- # 发送请求并接收响应
- response = urllib2.urlopen(req)
- # 读取响应内容
- html = response.read()
- print(html)
执行这段代码,将会向***发送一个HTTP请求,并打印出响应的HTML内容。这里的urlopen方法实际上返回了一个http.client.HTTPResponse对象,它是一个文件类对象,包含了响应的内容和头部信息。
2.1.2 异常处理与编码细节
网络请求并不总是成功的。服务器可能不存在、网络连接可能中断,或者服务器可能返回错误响应码。在使用urllib2时,必须考虑异常处理。
urllib2会抛出urllib2.URLError异常,在遇到网络问题时应该捕获此异常。以下是一个简单的异常处理代码示例:
- try:
- response = urllib2.urlopen(req)
- except urllib2.URLError as e:
- print(f"请求失败: {e.reason}")
在处理网络请求时,还需要关注编码问题。urllib2默认处理一些常见的编码问题,但有时可能需要手动解码。特别是当服务器返回非标准编码内容时,需要使用***().get_param('charset')获取内容编码,然后使用正确的编码方式读取数据。
- try:
- response = urllib2.urlopen(req)
- html = response.read()
- charset = ***().get_param('charset')
- if charset:
- html = html.decode(charset)
- except urllib2.URLError as e:
- print(f"请求失败: {e.reason}")
2.2 urllib2高级特性
2.2.1 自定义协议处理器
urllib2允许用户自定义协议处理器,这允许你拦截和修改请求和响应对象。自定义协议处理器通常继承自BaseHandler类,你可以覆盖其方法来实现特定逻辑。
下面的示例展示了如何创建一个自定义的协议处理器,用于在发送请求前修改HTTP请求头:
- import urllib2
- class MyHandler(urllib2.BaseHandler):
- def http_request(self, req):
- print(f"Adding custom header to request: {req}")
- req.add_header('My-Custom-Header', 'Value')
- return req
- opener = urllib2.build_opener(MyHandler())
- response = opener.open(req)
通过使用build_opener方法,我们创建了一个opener对象,使用我们的自定义处理器处理请求。
2.2.2 身份验证与代理使用
当访问某些需要身份验证的资源时,urllib2提供了支持。通过使用HTTPBasicAuthHandler,可以很容易地添加HTTP基本认证到你的请求中。同样地,使用代理也很简单,只需要在ProxyHandler中指定即可。
以下代码示例演示了如何使用HTTP基本身份验证:

而设置代理,可以使用以下代码:
- proxy_handler = urllib2.ProxyHandler({'http': '***'})
- opener = urllib2.build_opener(proxy_handler)
- response = opener.open(req)
2.3 urllib2与多线程结合
2.3.1 多线程基础
多线程编程是提高Python程序性能的一个重要手段,尤其是对于那些I/O密集型任务。在Python中,我们通常使用threading模块来创建和管理线程。要将urllib2与多线程结合使用,需要创建一个线程函数,它负责网络请求。
示例代码如下:
在上述示例中,fetch_url函数用于获取指定的URL,threading.Thread用于创建线程。这样,两个线程几乎可以同时进行网络请求。
2.3.2 urllib2在多线程中的应用
在多线程环境中,urllib2的线程安全问题需要特别注意。如果多个线程使用同一个全局的opener对象,那么它们可能会相互干扰。因此,通常建议为每个线程创建一个独立的opener对象。下面是如何实现的代码示例:
在本示例中,为每个线程创建了一个独立的opener对象,从而避免了线程间的资源冲突。
3. XML解析技术与urllib2集成应用
3.1 XML基础知识
3.1.1 XML结构与语法规则
XML(Extensible Markup Language,可扩展标记语言)是一种用于存储和传输数据的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【T-Box能源管理】:智能化节电解决方案详解
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
Cygwin系统监控指南:性能监控与资源管理的7大要点
【精准测试】:确保分层数据流图准确性的完整测试方法


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















