【Python网络编程高级教程】:urllib2故障排查与性能调试秘籍(urllib2高级故障排查与性能优化)
发布时间: 2024-10-07 18:03:18 阅读量: 28 订阅数: 20 

基于微信小程序的社区门诊管理系统php.zip

# 1. Python网络编程概述与urllib2介绍
网络编程是现代IT应用中不可或缺的一部分,它允许软件与软件、软件与服务间实现高效的数据交互。Python语言因其简洁易学,在网络编程领域中占据了重要的地位。尤其当涉及到HTTP协议的应用时,`urllib2`库成为了Python开发者们的得力助手。
`urllib2`是Python标准库的一部分,提供了诸多功能,使得HTTP及其他网络协议的请求变得简单。从基本的GET和POST请求,到处理重定向、认证、代理等高级特性,`urllib2`都提供了丰富的接口。
在本章中,我们首先会对Python网络编程进行一个大致的概述,从而为后续章节中对`urllib2`更深入的探讨打下基础。我们会逐一介绍网络编程的基本概念、Python在其中扮演的角色,以及如何通过`urllib2`实现网络请求和响应的基本操作。这样,读者就能够在这个基础上继续深入学习`urllib2`库的高级特性及故障排查与性能调试技巧。
## 1.1 Python网络编程简介
Python由于其简洁的语法和丰富的标准库,成为网络编程的热门选择。无论是构建Web服务,还是进行API集成,Python都能够提供灵活的解决方案。
## 1.2 urllib2的作用与应用场景
`urllib2`库是Python用于网络编程的核心库之一,它能够发送HTTP请求并处理响应。无论是简单的网页抓取还是复杂的Web服务交互,`urllib2`都能轻松应对。
## 1.3 如何使用urllib2进行基本的网络请求
接下来我们将介绍如何使用`urllib2`库来实现基本的网络请求。这包括导入模块、创建请求对象、打开和读取内容等步骤,为读者构建一个清晰的使用`urllib2`的入门基础。
```python
import urllib2
# 打开URL并读取内容
response = urllib2.urlopen('***')
html = response.read()
```
通过上述代码块,我们将演示如何使用`urllib2`发起一个简单的GET请求并获取网页内容。这将帮助读者快速掌握`urllib2`的基础应用。
# 2. urllib2的高级故障排查技巧
## 2.1 理解urllib2的工作原理
### 2.1.1 urllib2的模块结构和关键组件
urllib2是Python标准库中的一个模块,用于处理URL的请求和响应,它封装了许多与网络通信相关的功能,使得开发者能够轻松实现复杂的网络请求。urllib2主要由以下几个组件构成:
- **Opener**:负责发送HTTP请求并接收响应。
- **Handler**:用于处理请求的中间件,如ProxyHandler可以处理代理,HTTPPasswordMgr用于处理认证。
- **Request**:表示一个HTTP请求,包含请求的URL、方法、头部信息和数据体。
- **Response**:代表HTTP服务器返回的响应,通常包含状态码、头部信息和响应内容。
urllib2的高级操作都是通过继承`BaseHandler`类并重写相应的方法来实现的。例如,一个`ProxyHandler`类通过修改请求的URL来提供代理服务。
### 2.1.2 urllib2请求和响应处理流程
当使用urllib2发起一个网络请求时,它的工作流程如下:
1. 创建一个请求实例(`Request`),其中包含URL、HTTP方法、头部信息和可能的体内容。
2. 创建一个或多个`Handler`来处理请求的特定方面,如代理或认证。
3. 使用这些`Handler`创建一个`Opener`对象。
4. 使用`Opener`对象打开(发送请求并接收响应)。
处理响应的过程包括解析HTTP状态码和响应头信息,以及获取响应体内容。urllib2会根据状态码进行基本的错误处理,并返回一个`Response`对象,其中包含了请求的结果。
## 2.2 常见错误类型与诊断方法
### 2.2.1 HTTP错误码和对应的问题
HTTP错误码是服务器响应请求时返回的状态码,它们指示了请求的状态和结果。在urllib2中,错误码可以用来识别问题类型并进行相应的故障排查。常见的错误码包括:
- `404 Not Found`:请求的资源不存在。
- `403 Forbidden`:服务器拒绝访问请求的资源。
- `500 Internal Server Error`:服务器遇到了意料不到的情况。
理解这些错误码有助于确定请求失败的原因。例如,如果遇到404错误,可能是请求的URL不正确或资源已被移除。
### 2.2.2 连接超时和重试机制
当网络请求由于服务器未在预期时间内响应而超时时,urllib2允许用户设置超时时间并实现重试逻辑。这可以防止程序因长时间等待响应而挂起。通过`timeout`参数,我们可以设定超时时间:
```python
import urllib.request
req = urllib.request.Request(url)
try:
response = urllib.request.urlopen(req, timeout=10) # 设置超时时间为10秒
except urllib.error.URLError as e:
if hasattr(e, 'code') and e.code == 110: # 110代表超时错误码
print("连接超时,正在尝试重新连接...")
# 在这里添加重试逻辑
else:
print(f"请求错误: {e}")
```
### 2.2.3 SSL证书验证问题排查
SSL证书验证问题通常发生在SSL握手阶段。urllib2默认会验证服务器SSL证书的有效性。如果证书无效,Python将抛出`URLError`。要绕过证书验证(不推荐),可以使用`HTTPSHandler`并传递一个空的上下文参数:
```python
import urllib.request
# 创建一个HTTPS处理器,但不进行证书验证
context = ssl._create_unverified_context()
handler = urllib.request.HTTPSHandler(context=context)
opener = urllib.request.build_opener(handler)
response = opener.open(req)
```
## 2.3 故障排查实例分析
### 2.3.1 代理和重定向问题解决
遇到无法通过代理访问或重定向问题时,需要检查代理设置或重定向处理逻辑是否正确。
```python
import urllib.request
# 设置代理
proxy_handler = urllib.request.ProxyHandler({'http': '***'})
opener = urllib.request.build_opener(proxy_handler)
response = opener.open(req)
# 处理重定向
try:
response = urllib.request.urlopen(req)
except urllib.error.HTTPError as e:
if e.code == 301 or e.code == 302:
print("页面已重定向")
# 在这里添加处理重定向的逻辑
else:
print(f"请求错误: {e}")
```
### 2.3.2 编码和解码问题处理
URL中的特殊字符需要进行编码以符合URL标准,urllib2可以自动处理编码。但有时可能需要手动编码或解码,以避免字符错误:
```python
import urllib.parse
# 编码URL参数
params = {'name': '张三', 'city': '上海'}
encoded_params = urllib.parse.urlencode(params)
url = f"***{encoded_params}"
# 解码URL
decoded_url = urllib.parse.unquote(url)
```
### 2.3.3 自定义异常处理和日志记录
通过自定义异常处理,可以对urllib2中发生的错误进行更细致的控制。同时,记录日志有助于调试和维护。
```python
import logging
import urllib.request
# 配置日志
logging.basicConfig(level=logging.DEBUG)
def custom_handler(e):
if isinstance(e, urllib.error.HTTPError):
logging.error(f"HTTP错误:{e.code} - {e.reason}")
else:
logging.error(f"请求错误:{e}")
# 使用自定义异常处理器
try:
response = urllib.request.urlopen(req)
except Exception as e:
custom_handler(e)
```
以上章节内容详细介绍了urllib2的工作原理、常见的错误类型以及如何进行故障排查。通过这些知识和技巧,开发者能够更好地理解和使用urllib2,并在遇到网络编程问题时能够进行有效的排查和解决。下一章节,我们将探讨urllib2的性能调试和优化方法,帮助提升网络应用的性能和响应速度。
# 3. urllib2性能调试与优化
在现代的网络应用开发中,应用程序的性能至关重要。urllib2作为一个功能强大的网络请求库,它的性能直接影响到整个应用的响应时间和处理能力。本章将深入探讨如何对urllib2进行性能调试与优化,使网络请求更加高效、稳定。
## 3.1 性能调试的基础知识
### 3.1.1 分析urllib2的性能瓶颈
在着手优化之前,首先需要找出性能瓶颈的所在。urllib2可能在多个环节上产生性能瓶颈,如DNS解析、连接建立、数据传输等。由于urllib2是在Python的C语言层面实现的,因此很多性能瓶颈可能发生在Python解释器层面,而不是urllib2库本身。
对于性能瓶颈的分析,建议开发者采取以下步骤:
- 使用Python的内置模块`cProfile`或者`pstats`进行性能分析。
- 利用`timeit`模块对关键代码段进行性能测试。
- 使用`traceback`模块来跟踪异常发生的位置和原因。
### 3.1.2 工具和方法:使用cProfile进行性能分析
Python的`cProfile`模块是一个性能分析工具,它可以帮助开发者找

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《Python网络编程:从入门到精通》全面解析urllib2库,涵盖从基础应用到高级技巧。
专栏文章包括:
* urllib2库的全面解析与应用技巧
* urllib2应用全攻略,助你打造高效爬虫
* 专家级urllib2使用技巧,揭秘源码和解决常见问题
* urllib2 JSON数据交互全解析,一文搞定数据交互
* urllib2的高级安全与优化策略,保障网络安全和提升性能
* urllib2高级故障排查与性能优化秘籍,解决疑难杂症
* urllib2实战案例分析,展示在XML解析和多线程中的高效应用
* urllib2安全防护指南,防范XSS和CSRF攻击
* urllib2高级会话与中间件管理技巧,扩展网络功能
* urllib2协议处理器定制指南,定制化网络请求解决方案
* urllib2加密通信权威指南,实现最佳实践
* urllib2与Ajax交互教程,应用于Ajax请求中
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CMOS集成电路设计实战解码】:从基础到高级的习题详解,理论与实践的完美融合
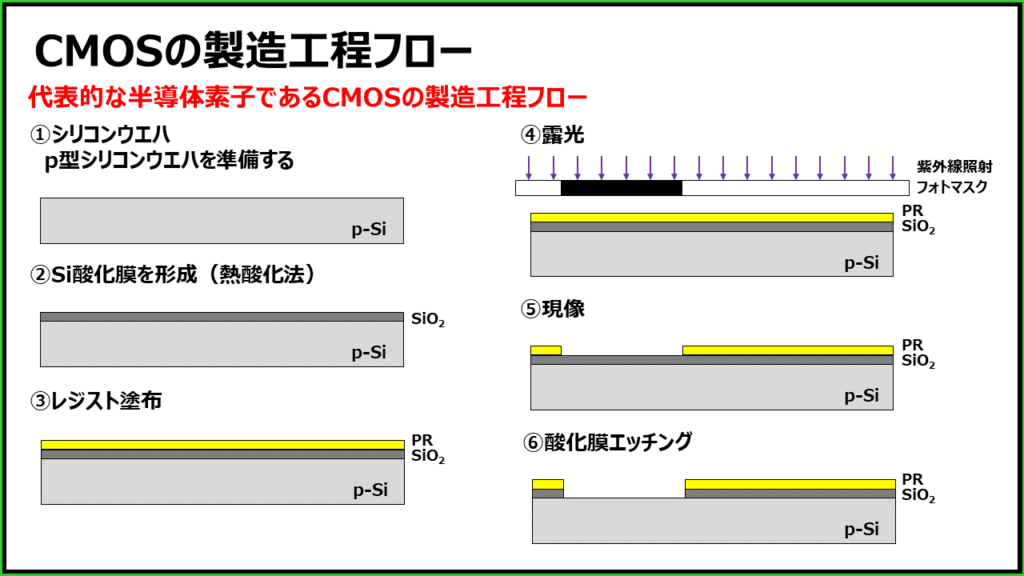
# 摘要
CMOS集成电路设计是现代电子系统中不可或缺的一环,本文全面概述了CMOS集成电路设计的关键理论和实践操作。首先,介绍了CMOS技术的基础理论,包括晶体管工作机制、逻辑门设计基础、制造流程和仿真分析。接着,深入探讨了CMOS集成电路的设计实践,涵盖了反相器与逻辑门设计、放大器与模拟电路设计,以及时序电路设计。此外,本文还
CCS高效项目管理:掌握生成和维护LIB文件的黄金步骤

# 摘要
本文深入探讨了CCS项目管理和LIB文件的综合应用,涵盖了项目设置、文件生成、维护优化以及实践应用的各个方面。文中首先介绍了CCS项目的创建与配置、编译器和链接器的设置,然后详细阐述了LIB文件的生成原理、版本控制和依赖管理。第三章重点讨论了LIB文件的代码维护、性能优化和自动化构建。第四章通过案例分析了LIB文件在多项目共享、嵌入式系统应用以及国际化与本地化处理中的实际应
【深入剖析Visual C++ 2010 x86运行库】:架构组件精讲

# 摘要
Visual C++ 2010 x86运行库是支持开发的关键组件,涵盖运行库架构核心组件、高级特性与实现,以及优化与调试等多个方面。本文首先对运行库的基本结构、核心组件的功能划分及其交互机制进行概述。接着,深入探讨运行时类型信息(RTTI)与异常处理的工作原理和优化策略,以及标准C++内存管理接口和内存分配与释放策略。本文还阐述了运行库的并发与多线程支持、模板与泛型编程支持,
从零开始掌握ACD_ChemSketch:功能全面深入解读
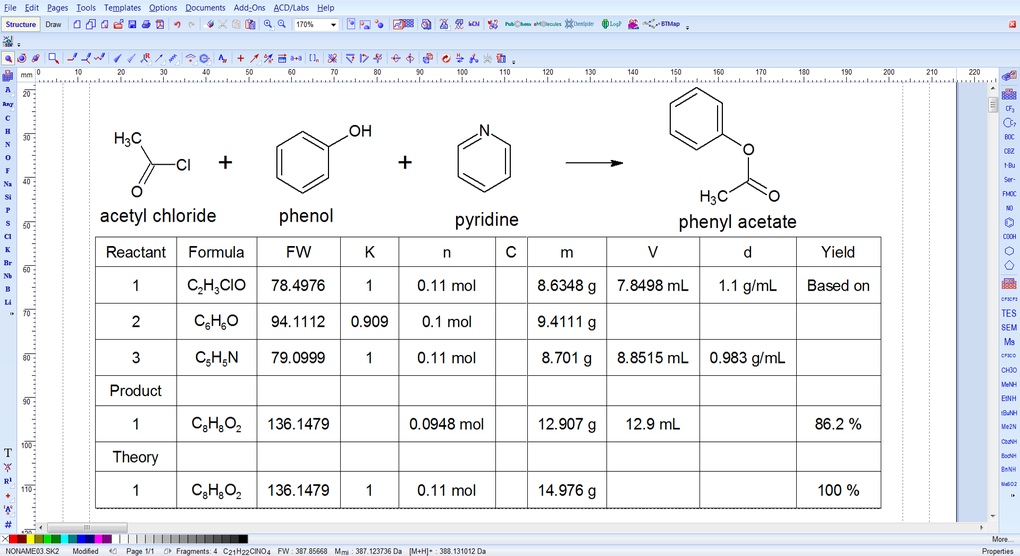
# 摘要
ACD_ChemSketch是一款广泛应用于化学领域的绘图软件,本文概述了其基础和高级功能,并探讨了在科学研究中的应用。通过介绍界面布局、基础绘图工具、文件管理以及协作功能,本文为用户提供了掌握软件操作的基础知识。进阶部分着重讲述了结构优化、立体化学分析、高
蓝牙5.4新特性实战指南:工业4.0的无线革新

# 摘要
蓝牙技术是工业4.0不可或缺的组成部分,它通过蓝牙5.4标准实现了新的通信特性和安全机制。本文详细概述了蓝牙5.4的理论基础,包括其新增功能、技术规格,以及与前代技术的对比分析。此外,探讨了蓝牙5.4在工业环境中网络拓扑和设备角色的应用,并对安全机制进行了评估。本文还分析了蓝牙5.4技术的实际部署,包
【Linux二进制文件执行错误深度剖析】:一次性解决执行权限、依赖、环境配置问题(全面检查必备指南)
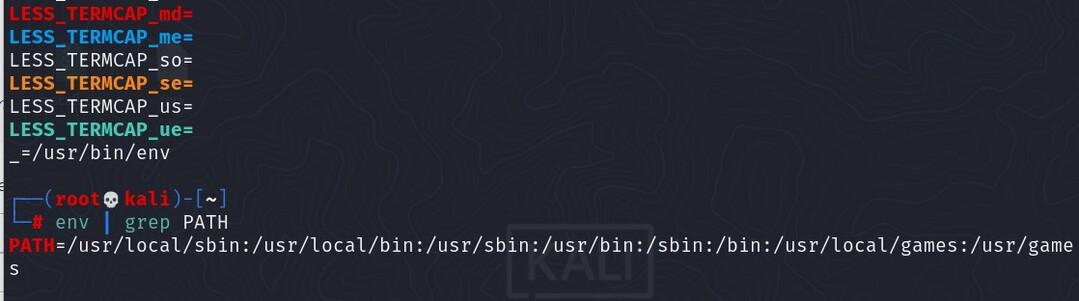
# 摘要
本文详细探讨了二进制文件执行过程中遇到的常见错误,并提出了一系列理论与实践上的解决策略。首先,针对执行权限问题,文章从权限基础理论出发,分析了权限设置不当所导致的错误,并探讨了修复权限的工具和方法。接着,文章讨论了依赖问题,包括依赖管理基础、缺失错误分析以及修复实践,并对比了动态与静态依赖。环境配置问题作为另一主要焦点,涵盖了
差分输入ADC滤波器设计要点:实现高效信号处理
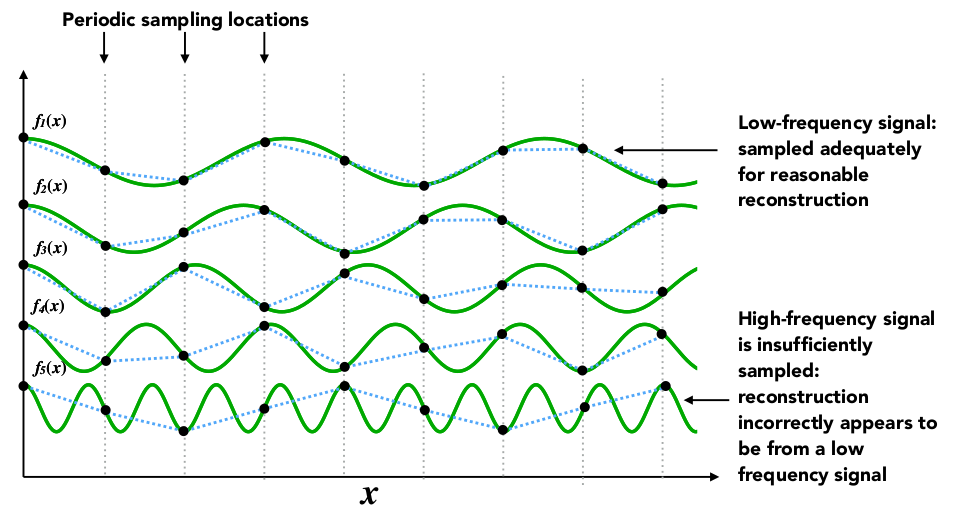
# 摘要
本论文详细介绍了差分输入模数转换器(ADC)滤波器的设计与实践应用。首先概述了差分输入ADC滤波器的理论基础,包括差分信号处理原理、ADC的工作原理及其类型,以及滤波器设计的基本理论。随后,本研究深入探讨了滤波器设计的实践过程,从确定设计规格、选择元器件到电路图绘制、仿真、PCB布局,以及性能测试与验证的方法。最后,论文分析了提高差分输入ADC滤波器性能的优化策略,包括提升精
【HPE Smart Storage性能提升指南】:20个技巧,优化存储效率

# 摘要
本文深入探讨了HPE Smart Storage在性能管理方面的方法与策略。从基础性能优化技巧入手,涵盖了磁盘配置、系统参数调优以及常规维护和监控等方面,进而探讨高级性能提升策略,如缓存管理、数据管理优化和负载平衡。在自动化和虚拟化环境下,本文分析了如何利用精简配置、快照技术以及集成监控解决方案来进一步提升存储性能,并在最后章节中讨论了灾难恢复与备份策略的设计与实施。通过案
【毫米波雷达性能提升】:信号处理算法优化实战指南
# 摘要
毫米波雷达信号处理是一个涉及复杂数学理论和先进技术的领域,对于提高雷达系统的性能至关重要。本文首先概述了毫米波雷达信号处理的基本理论,包括傅里叶变换和信号特性分析,然后深入探讨了信号处理中的关键技术和算法优化策略。通过案例分析,评估了现有算法性能,并介绍了信号处理软件实践和代码优化技巧。文章还探讨了雷达系统的集成、测试及性能评估方法,并展望了未来毫米波雷达性能提升的技术趋
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )