Python动物代码优化:提升性能和可扩展性,打造高效的动物模拟器
发布时间: 2024-06-20 13:47:52 阅读量: 50 订阅数: 49 

# 1. Python动物代码基础
Python动物代码是一种利用Python编程语言模拟动物行为和种群动态的代码。它广泛应用于生态学、进化生物学和计算机科学等领域。
### 1.1 动物行为建模
动物代码通常通过定义动物类来模拟动物行为。每个动物类包含描述动物属性(如位置、速度、能量)的属性,以及定义动物行为(如移动、进食、繁殖)的方法。
### 1.2 种群管理
动物代码还可用于模拟动物种群的动态。通过创建动物种群类,可以跟踪种群大小、年龄结构和空间分布。种群类还包含方法来模拟种群增长、竞争和捕食等过程。
# 2. Python动物代码优化技巧
在构建动物模拟器时,优化代码至关重要,它可以提升性能、增强可扩展性,并确保代码的可维护性。本章将探讨各种Python动物代码优化技巧,涵盖算法、数据结构和代码重构方面。
### 2.1 算法优化
#### 2.1.1 空间复杂度优化
空间复杂度是指算法在运行时所需的内存量。优化空间复杂度可以减少内存消耗,从而提高性能。
**技术:**
* **使用空间高效的数据结构:**例如,使用字典代替列表存储键值对,使用集合代替列表存储唯一元素。
* **避免不必要的副本:**通过引用传递或使用浅拷贝,而不是创建对象的副本。
* **释放未使用的内存:**使用`del`语句释放不再需要的对象,以防止内存泄漏。
**代码示例:**
```python
# 空间复杂度优化:使用字典代替列表存储键值对
# 使用列表存储键值对
animals = [
{"name": "Lion", "age": 5},
{"name": "Tiger", "age": 4},
]
# 使用字典存储键值对
animals = {
"Lion": 5,
"Tiger": 4,
}
```
**逻辑分析:**
使用字典代替列表存储键值对可以优化空间复杂度,因为字典具有 O(1) 的查找时间复杂度,而列表具有 O(n) 的查找时间复杂度。
#### 2.1.2 时间复杂度优化
时间复杂度是指算法执行所需的时间量。优化时间复杂度可以减少执行时间,从而提高响应能力。
**技术:**
* **使用高效的算法:**例如,使用二分查找算法代替线性查找算法。
* **减少不必要的循环:**通过使用提前终止条件或使用更有效的循环结构。
* **利用缓存:**存储频繁访问的数据,以避免重复计算。
**代码示例:**
```python
# 时间复杂度优化:使用二分查找算法代替线性查找算法
# 使用线性查找算法
def find_animal_by_name(animals, name):
for animal in animals:
if animal["name"] == name:
return animal
# 使用二分查找算法
def find_animal_by_name_optimized(animals, name):
low = 0
high = len(animals) - 1
while low <= high:
mid = (low + high) // 2
if animals[mid]["name"] == name:
return animals[mid]
elif animals[mid]["name"] < name:
low = mid + 1
else:
high = mid - 1
```
**逻辑分析:**
使用二分查找算法代替线性查找算法可以优化时间复杂度,因为二分查找算法具有 O(log n) 的查找时间复杂度,而线性查找算法具有 O(n) 的查找时间复杂度。
### 2.2 数据结构优化
#### 2.2.1 字典优化
字典是 Python 中存储键值对的有序集合。优化字典可以提高查找、插入和删除操作的效率。
**技术:**
* **选择合适的哈希函数:**哈希函数决定了键如何映射到哈希表中的桶中。选择一个好的哈希函数可以减少冲突。
* **调整桶大小:**桶大小决定了每个桶中存储的键值对数量。调整桶大小可以优化查找效率。
* **使用自定义比较函数:**自定义比较函数允许您指定键的比较方式。这对于优化具有复杂键的数据结构很有用。
**代码示例:**
```python
# 字典优化:调整桶大小
# 创建一个字典,桶大小为 8
animals = {}
# 调整桶大小为 16
animals.__init__(buckets=16)
```
**逻辑分析:**
调整桶大小可以优化查找效率。较大的桶大小可以减少冲突,但也会增加内存消耗。较小的桶大小可以减少内存消耗,但可能会增加冲突。
#### 2.2.2 列表优化
列表是 Python 中存储有序元素的可变序列。优化列表可以提高插入、删除和访问元素的效率。
**技术:**
* **使用适当的列表实现:**Python 提供了多种列表实现,例如列表、元组和 NumPy 数组。选择合适的实现可以优化性能。
* **避免不必要的列表操作:**例如,避免创建列表副本或使用列表推导。
* **使用切片操作:**切片操作可以高效地从列表中提取子列表。
**代码示例:**
```python
# 列表优化:使用切片操作
# 创建一个列表
animals = [
{"name": "Lion", "age": 5},
{"name": "Tiger", "age": 4},
{"name": "Elephant", "age": 10},
]
# 使用切片操作获取年龄大于 5 的动物
animals_over_5 = animals[1:]
```
**逻辑分析:**
使用切片操作可以高效地从列表中提取子列表。切片操作具有 O(n) 的时间复杂度,其中 n 是列表的长度。
# 3. Python动物代码实践应用
### 3.1 动物行为模拟
#### 3.1.1 随机漫步算法
**简介:**
随机漫步算法是一种用于模拟动物随机移动的算法。它通过在每个时间步长中随机选择一个方向和距离来实现。
**代码:**
```python
import random
class Animal:
def __init__(self, x, y):
self.x = x
self.y = y
def move(self):
# 随机选择一个方向
direction = random.choice(['up', 'down', 'left', 'right'])
# 随机选择一个距离
distance = random.randint(1, 10)
# 根据方向和距离更新位置
if direction == 'up':
self.y += distance
elif direction == 'down':
self.y -= distance
elif direction == 'left':
self.x -= distance
elif direction == 'right':
self.x += distance
```
**逻辑分析:**
* `__init__()` 方法初始化动物的位置。
* `move()` 方法模拟动物的移动:
* 随机选择一个方向(上、下、左、右)。
* 随机选择一个距离(1 到 10 之间)。
* 根据方向和距离更新动物的位置。
#### 3.1.2 遗传算法
**简介:**
遗传算法是一种受生物进化启发的优化算法。它通过选择、交叉和变异操作来优化动物的行为。
**代码:**
```python
import random
class Animal:
def __init__(self, genes):
self.genes = genes
def fitness(self):
# 计算动物的适应度(例如,生存时间)
def select(self, population):
# 根据适应度选择动物
def crossover(self, other):
# 交叉两个动物的基因
def mutate(self):
# 变异动物的基因
```
**逻辑分析:**
* `__init__()` 方法初始化动物的基因。
* `fitness()` 方法计算动物的适应度。
* `select()` 方法根据适应度选择动物。
* `crossover()` 方法交叉两个动物的基因。
* `mutate()` 方法变异动物的基因。
### 3.2 动物种群管理
#### 3.2.1 种群增长模型
**简介:**
种群增长模型用于模拟动物种群随时间的变化。它考虑了出生、死亡和移民等因素。
**代码:**
```python
import numpy as np
class Population:
def __init__(self, size, birth_rate, death_rate):
self.size = size
self.birth_rate = birth_rate
self.death_rate = death_rate
def update(self):
# 更新种群大小
self.size += np.random.poisson(self.birth_rate * self.size)
self.size -= np.random.poisson(self.death_rate * self.size)
```
**逻辑分析:**
* `__init__()` 方法初始化种群大小、出生率和死亡率。
* `update()` 方法更新种群大小:
* 使用泊松分布模拟出生事件,并增加种群大小。
* 使用泊松分布模拟死亡事件,并减少种群大小。
#### 3.2.2 种群分布分析
**简介:**
种群分布分析用于研究动物种群在空间或时间上的分布。它可以帮助了解种群的动态和栖息地利用。
**代码:**
```python
import matplotlib.pyplot as plt
class Population:
def __init__(self, positions):
self.positions = positions
def plot_distribution(self):
# 绘制种群分布图
plt.scatter(self.positions[:, 0], self.positions[:, 1])
plt.show()
```
**逻辑分析:**
* `__init__()` 方法初始化动物种群的位置。
* `plot_distribution()` 方法绘制种群分布图:
* 将动物位置的 x 坐标和 y 坐标作为散点图绘制。
# 4. Python动物代码进阶应用
### 4.1 多线程编程
多线程编程是一种并发编程技术,它允许一个程序同时执行多个任务。在Python中,可以使用`threading`模块来创建和管理线程。
**4.1.1 线程同步**
当多个线程同时访问共享资源时,可能会发生竞争条件,导致数据损坏或程序崩溃。为了防止这种情况,需要使用线程同步机制,例如锁和信号量。
**锁**:锁是一种同步原语,它允许一次只有一个线程访问共享资源。在Python中,可以使用`threading.Lock`类来创建锁。
```python
import threading
lock = threading.Lock()
def access_shared_resource():
with lock:
# 访问共享资源
```
**信号量**:信号量是一种同步原语,它限制同时可以访问共享资源的线程数量。在Python中,可以使用`threading.Semaphore`类来创建信号量。
```python
import threading
semaphore = threading.Semaphore(3)
def access_shared_resource():
with semaphore:
# 访问共享资源
```
**4.1.2 线程池**
线程池是一种管理线程的机制,它可以减少创建和销毁线程的开销。在Python中,可以使用`concurrent.futures.ThreadPoolExecutor`类来创建线程池。
```python
import concurrent.futures
def task(n):
return n * n
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(task, range(10))
```
### 4.2 分布式计算
分布式计算是一种将计算任务分配给多台计算机同时执行的技术。在Python中,可以使用`multiprocessing`模块和`dask`库来进行分布式计算。
**4.2.1 并行计算**
并行计算是一种分布式计算技术,它将一个大任务分解成多个较小的任务,并同时在多台计算机上执行这些任务。在Python中,可以使用`multiprocessing`模块来进行并行计算。
```python
import multiprocessing
def task(n):
return n * n
if __name__ == '__main__':
with multiprocessing.Pool() as pool:
results = pool.map(task, range(10))
```
**4.2.2 集群计算**
集群计算是一种分布式计算技术,它将计算任务分配给一个计算机集群,并通过一个管理节点协调这些任务。在Python中,可以使用`dask`库来进行集群计算。
```python
import dask.dataframe as dd
df = dd.read_csv('data.csv')
df['result'] = df['value'] * 2
```
# 5. Python动物代码性能分析
### 5.1 性能指标
#### 5.1.1 运行时间
运行时间是衡量代码执行速度的重要指标。它表示代码从开始到结束执行所需的时间。对于动物模拟器来说,运行时间至关重要,因为它影响模拟的实时性。
#### 5.1.2 内存消耗
内存消耗衡量代码执行时占用的内存量。对于动物模拟器来说,内存消耗也是一个重要的考虑因素,因为它会影响模拟的稳定性和可扩展性。
### 5.2 性能分析工具
为了分析动物代码的性能,可以使用以下工具:
#### 5.2.1 cProfile
cProfile是一个内置的Python模块,用于分析代码的运行时间和函数调用次数。它通过在代码中插入探测点来收集性能数据。
```python
import cProfile
def animal_simulation():
# 模拟动物行为
if __name__ == "__main__":
cProfile.run("animal_simulation()")
```
执行此代码后,将生成一个包含性能数据的统计报告。
#### 5.2.2 memory_profiler
memory_profiler是一个第三方Python模块,用于分析代码的内存消耗。它通过在代码中插入探测点来收集内存使用数据。
```python
import memory_profiler
@memory_profiler.profile
def animal_simulation():
# 模拟动物行为
if __name__ == "__main__":
animal_simulation()
```
执行此代码后,将生成一个包含内存使用数据的统计报告。
### 5.3 性能分析步骤
使用性能分析工具后,可以采取以下步骤分析代码的性能:
1. **识别性能瓶颈:**确定代码中消耗时间或内存最多的部分。
2. **优化瓶颈:**应用优化技巧(例如算法优化、数据结构优化、代码重构)来减少瓶颈的影响。
3. **重新分析性能:**使用性能分析工具重新分析优化后的代码,以验证改进。
4. **持续优化:**随着模拟器的复杂性增加,定期进行性能分析和优化至关重要。
# 6. Python动物代码可扩展性
### 6.1 模块化设计
模块化设计是一种将代码组织成独立模块的软件设计方法。每个模块都封装了特定功能,并通过明确的接口与其他模块交互。模块化设计的好处包括:
- **代码复用:**模块可以被多个程序重复使用,从而减少代码重复和维护成本。
- **依赖管理:**模块之间明确的依赖关系使依赖管理变得更加容易,从而简化了代码维护和更新。
### 6.1.1 代码复用
为了在动物模拟器中实现代码复用,可以将不同动物的行为和特性封装到单独的模块中。例如,可以创建一个 `Animal` 模块,包含所有动物共有的属性和方法,如名称、位置和移动速度。然后,可以创建特定动物的子模块,如 `Dog` 和 `Cat`,继承 `Animal` 模块并添加特定于该动物的特性。
```python
# Animal.py
class Animal:
def __init__(self, name, position, speed):
self.name = name
self.position = position
self.speed = speed
def move(self):
# 移动动物
pass
# Dog.py
from Animal import Animal
class Dog(Animal):
def __init__(self, name, position, speed, bark_volume):
super().__init__(name, position, speed)
self.bark_volume = bark_volume
def bark(self):
# 狗叫
pass
# Cat.py
from Animal import Animal
class Cat(Animal):
def __init__(self, name, position, speed, meow_pitch):
super().__init__(name, position, speed)
self.meow_pitch = meow_pitch
def meow(self):
# 猫叫
pass
```
### 6.1.2 依赖管理
模块化设计还简化了依赖管理。通过明确定义模块之间的依赖关系,可以确保在运行程序时加载正确的模块。在动物模拟器中,可以创建一个 `main.py` 模块,导入所需的动物模块并初始化模拟器。
```python
# main.py
import Animal
import Dog
import Cat
# 创建动物
dog = Dog("Buddy", (0, 0), 5)
cat = Cat("Whiskers", (10, 10), 3)
# 运行模拟器
while True:
# 更新动物位置
dog.move()
cat.move()
# 检查动物是否相遇
if dog.position == cat.position:
# 动物相遇,执行互动逻辑
pass
```
### 6.2 可配置性
可配置性允许用户根据特定需求定制程序。这可以通过配置文件或命令行参数来实现。
### 6.2.1 配置文件
配置文件是一种存储程序设置和配置信息的文本文件。在动物模拟器中,可以创建一个 `config.ini` 文件来存储模拟器参数,如动物数量、模拟时间和输出日志级别。
```
[Simulation]
num_animals = 100
simulation_time = 1000
log_level = INFO
```
### 6.2.2 命令行参数
命令行参数允许用户在运行程序时指定配置选项。在动物模拟器中,可以添加命令行参数来覆盖配置文件中的设置。
```
python main.py --num_animals=200 --simulation_time=2000
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 动物代码专栏,一个全面的指南,带您探索 Python 编程语言在动物模拟器开发中的强大功能。从基础代码到高级技术,本专栏涵盖了构建逼真的动物模拟器的方方面面。
您将学习如何使用面向对象编程和继承创建灵活的模拟器,构建虚拟动物园以体验动物世界的生机勃勃,并优化代码以实现高效性能。此外,您还将深入了解排序和搜索算法、数据结构、异常处理、文件操作、单元测试、性能分析和设计模式。
本专栏旨在帮助您编写高质量、可维护、可测试和可扩展的动物代码。它还提供了部署、扩展、安全和持续集成的最佳实践,以确保您的模拟器可靠且易于使用。通过本专栏,您将掌握 Python 动物代码的艺术,并创建令人惊叹的动物模拟器,让您沉浸在虚拟动物世界的奇妙中。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Linux Mint XFCE电源管理提升秘籍】:笔记本续航力倍增指南

# 1. Linux Mint XFCE电源管理概述
Linux Mint的XFCE版本以其轻量级和性能为用户所喜爱,而其中的电源管理是确保系统运行效率和延长电池续航的关键因素。在本章中,我们将简要介绍电源管理的概念以及它在Linux Mint XFCE中的重要性,并为读者提供一个全面的概览,作为深入理解后续章节的起点。
## 1.1 Linux Mint中电源
【大数据处理】:结合Hadoop_Spark轻松处理海量Excel数据
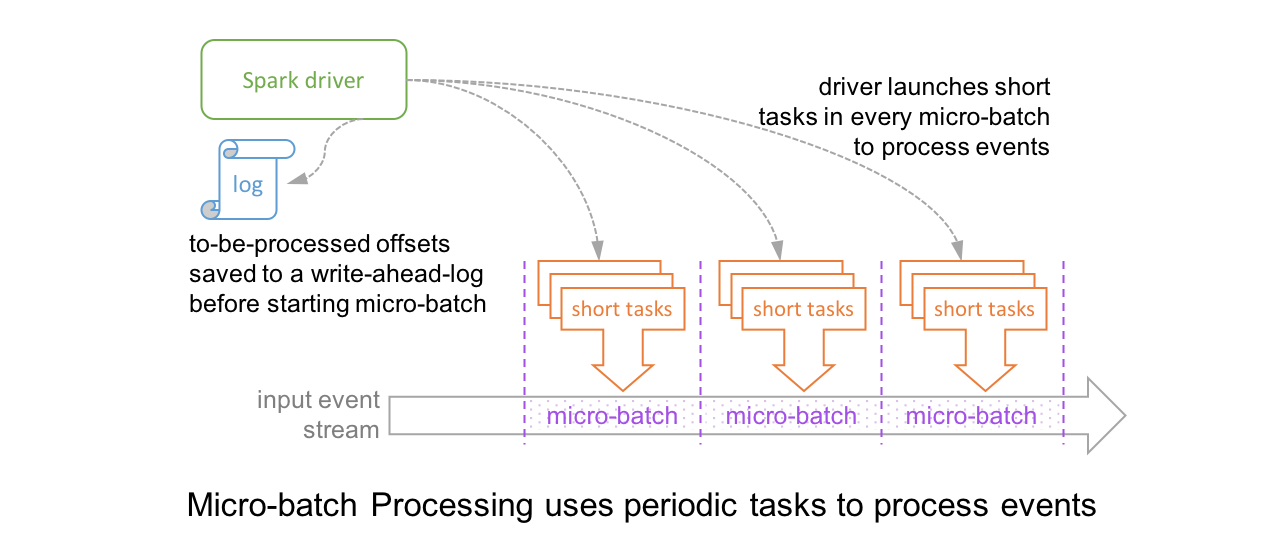
# 1. 大数据与分布式计算基础
## 1.1 大数据时代的来临
随着信息技术的快速发展,数据量呈爆炸式增长。大数据不再只是一个时髦的概念,而是变成了每个企业与组织无法忽视的现实。它在商业决策、服务个性化、产品优化等多个方面发挥着巨大作用。
## 1.2 分布式计算的必要性
面对如此庞大且复杂的数据,传统单机计算已无法有效处理。分布式计算作为一种能够将任务分散到多台计算机上并行处
前端技术与iText融合:在Web应用中动态生成PDF的终极指南
# 1. 前端技术与iText的融合基础
## 1.1 前端技术概述
在现代的Web开发领域,前端技术主要由HTML、CSS和JavaScript组成,这三者共同构建了网页的基本结构、样式和行为。HTML(超文本标记语言)负责页面的内容结构,CSS(层叠样式表)定义页面的视觉表现,而J
Apache FOP性能大跃进:提高大规模文档转换效率

# 1. Apache FOP基础介绍
Apache FOP(Formatting Objects Processor)是一个强大的开源库,用于将XSL-FO(Extensible Stylesheet Language Formatting Objects)文档转换为PDF格式。它在IT行业中广泛应用,尤其是在需要将结构化文档内容转换为可打印或者可查看的格式时。
在本章,我们
【PDF文档版本控制】:使用Java库进行PDF版本管理,版本控制轻松掌握

# 1. PDF文档版本控制概述
在数字信息时代,文档管理成为企业与个人不可或缺的一部分。特别是在法律、财务和出版等领域,维护文档的历史版本、保障文档的一致性和完整性,显得尤为重要。PDF文档由于其跨平台、不可篡改的特性,成为这些领域首选的文档格式
Linux Mint Debian版内核升级策略:确保系统安全与最新特性

# 1. Linux Mint Debian版概述
Linux Mint Debian版(LMDE)是基于Debian稳定分支的一个发行版,它继承了Linux Mint的许多优秀特性,同时提供了一个与Ubuntu不同的基础平台。本章将简要介绍LMDE的特性和优势,为接下来深入了解内核升级提供背景知识。
## 1.1 Linux Min
Ubuntu桌面环境个性化定制指南:打造独特用户体验

# 1. Ubuntu桌面环境介绍与个性化概念
## 简介 Ubuntu 桌面
Ubuntu 桌面环境是基于 GNOME Shell 的一个开源项目,提供一个稳定而直观的操作界面。它利用 Unity 桌面作为默认的窗口管理器,旨在为用户提供快速、高效的工作体验。Ubuntu 的桌面环境不仅功能丰富,还支持广泛的个性化选项,让每个用户都能根据
【Linux Mint Cinnamon性能监控实战】:实时监控系统性能的秘诀

# 1. Linux Mint Cinnamon系统概述
## 1.1 Linux Mint Cinnamon的起源
Linux Mint Cinnamon是一个流行的桌面发行版,它是基于Ubuntu或Debian的Linux系统,专为提供现代、优雅而又轻量级的用户体验而设计。Cinnamon界面注重简洁性和用户体验,通过直观的菜单和窗口管理器,为用户提供高效的工作环境。
#
Linux Mint 22用户账户管理
# 1. Linux Mint 22用户账户管理概述
Linux Mint 22,作为Linux社区中一个流行的发行版,以其用户友好的特性获得了广泛的认可。本章将简要介绍Linux Mint 22用户账户管理的基础知识,为读者在后续章节深入学习用户账户的创建、管理、安全策略和故障排除等高级主题打下坚实的基础。用户账户管理不仅仅是系统管理员的日常工作之一,也是确保Linux Mint 22系统安全和资源访问控制的关键组成
【性能基准测试】:Apache POI与其他库的效能对比

# 1. 性能基准测试的理论基础
性能基准测试是衡量软件或硬件系统性能的关键活动。它通过定义一系列标准测试用例,按照特定的测试方法在相同的环境下执行,以量化地评估系统的性能表现。本章将介绍性能基准测试的基本理论,包括测试的定义、重要性、以及其在实际应用中的作用。
## 1.1 性能基准测试的定义
性能基准测试是一种评估技术,旨在通过一系列
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )