PHP数据入库性能优化秘籍:提升数据添加效率的5大技巧
发布时间: 2024-07-28 12:10:44 阅读量: 31 订阅数: 30 

MYSQL开发性能研究之批量插入数据的优化方法

# 1. 数据入库性能瓶颈分析**
数据入库性能低下是困扰许多应用程序的常见问题。其根源可能在于多个方面,包括:
- **数据库架构不合理:**表设计不当、索引缺失或不合理、数据类型选择不当。
- **PHP代码优化不足:**未采用批量插入、连接池等优化技术,导致数据库连接频繁、资源消耗过大。
- **服务器配置不当:**硬件配置不足、软件配置不合理,影响数据库和PHP代码的执行效率。
# 2. 优化数据库架构
### 2.1 表设计优化
表设计是影响数据入库性能的关键因素。合理的表设计可以减少数据冗余,提高查询效率,从而提升数据入库性能。
#### 2.1.1 索引的合理使用
索引是数据库中一种重要的数据结构,可以快速定位数据记录。合理使用索引可以大大提高查询效率,减少数据入库时间。
**参数说明:**
* **CREATE INDEX index_name ON table_name (column_name)**:创建索引
* **DROP INDEX index_name ON table_name**:删除索引
**代码块:**
```sql
CREATE INDEX idx_user_name ON user (user_name);
```
**逻辑分析:**
该代码创建了一个名为 `idx_user_name` 的索引,用于加速对 `user` 表中 `user_name` 列的查询。
#### 2.1.2 数据类型选择
选择合适的数据类型可以优化数据存储和查询效率。例如,使用定长数据类型(如 `INT`、`CHAR`) 可以减少数据存储空间,提高查询速度。
**参数说明:**
* **INT(M)**:有符号整数,M 指定位数
* **CHAR(M)**:定长字符,M 指定字符数
**代码块:**
```sql
ALTER TABLE user MODIFY COLUMN age INT(3);
```
**逻辑分析:**
该代码将 `user` 表中 `age` 列的数据类型修改为 `INT(3)`,表示该列只能存储三位数的整数。
### 2.2 数据库引擎选择
不同的数据库引擎具有不同的特性,适合不同的应用场景。选择合适的数据库引擎可以显著提升数据入库性能。
#### 2.2.1 InnoDB与MyISAM对比
InnoDB和MyISAM是MySQL中常用的两种数据库引擎。
| 特性 | InnoDB | MyISAM |
|---|---|---|
| 事务支持 | 支持 | 不支持 |
| 行锁 | 支持 | 表锁 |
| 存储空间 | 较大 | 较小 |
| 查询效率 | 较慢 | 较快 |
**表格:InnoDB与MyISAM对比**
#### 2.2.2 NoSQL数据库的应用
NoSQL数据库是一种非关系型数据库,具有高性能、高可扩展性等特点。在某些场景下,使用NoSQL数据库可以大幅提升数据入库性能。
**代码块:**
```php
// 使用MongoDB插入数据
$collection->insertOne([
'name' => 'John Doe',
'age' => 30
]);
```
**逻辑分析:**
该代码使用MongoDB插入一条数据,其中 `collection` 为MongoDB集合对象。
# 3. 优化PHP代码
**3.1 批量插入操作**
批量插入操作可以有效减少数据库连接次数和服务器负载,从而提升数据入库性能。PHP中提供了两种批量插入操作的方法:mysqli_multi_query()函数和PDO事务处理。
**3.1.1 mysqli_multi_query()函数**
mysqli_multi_query()函数允许一次性执行多个SQL查询,非常适合批量插入操作。其语法如下:
```php
mysqli_multi_query($link, $query);
```
其中:
* `$link`:MySQL连接句柄
* `$query`:包含多个SQL查询的字符串
**代码块逻辑分析:**
mysqli_multi_query()函数会依次执行`$query`字符串中包含的所有SQL查询。如果执行成功,则返回`true`;否则,返回`false`。
**参数说明:**
* `$link`:MySQL连接句柄,用于连接到数据库。
* `$query`:包含多个SQL查询的字符串,每个查询以分号(`;`)分隔。
**3.1.2 PDO事务处理**
PDO事务处理也可以用于批量插入操作。其步骤如下:
1. 开启事务
2. 执行多个插入操作
3. 提交事务
```php
$pdo->beginTransaction();
$stmt = $pdo->prepare("INSERT INTO table (name, age) VALUES (?, ?)");
for ($i = 0; $i < 1000; $i++) {
$stmt->execute([$name, $age]);
}
$pdo->commit();
```
**代码块逻辑分析:**
* `$pdo->beginTransaction()`:开启事务。
* `$stmt = $pdo->prepare("INSERT INTO table (name, age) VALUES (?, ?)")`:准备SQL语句。
* `for ($i = 0; $i < 1000; $i++)`:循环执行1000次插入操作。
* `$stmt->execute([$name, $age])`:执行插入操作。
* `$pdo->commit()`:提交事务。
**参数说明:**
* `$pdo`:PDO对象,用于连接到数据库。
* `$stmt`:PDOStatement对象,用于准备和执行SQL语句。
* `$name`:要插入的姓名。
* `$age`:要插入的年龄。
**3.2 减少数据库连接次数**
频繁的数据库连接会消耗大量资源,因此减少数据库连接次数可以有效提升性能。有两种方法可以减少数据库连接次数:连接池和数据库缓存。
**3.2.1 连接池的使用**
连接池是一种管理数据库连接的机制,它可以复用已经建立的连接,从而减少创建新连接的开销。PHP中可以使用PDO连接池扩展来实现连接池功能。
**3.2.2 数据库缓存**
数据库缓存可以将查询结果缓存起来,当需要相同查询时,直接从缓存中读取,从而减少数据库查询次数。PHP中可以使用Memcached或Redis等缓存系统来实现数据库缓存功能。
# 4. 优化服务器配置
服务器配置对数据入库性能的影响不容忽视。本章节将介绍硬件和软件方面的优化技巧,帮助你提升服务器性能,从而优化数据入库效率。
### 4.1 硬件优化
#### 4.1.1 CPU、内存、硬盘的配置
* **CPU:**选择多核高主频的CPU,以提升数据处理能力。
* **内存:**充足的内存可避免频繁的磁盘读写,提高数据访问速度。
* **硬盘:**使用固态硬盘(SSD)代替传统机械硬盘,大幅提升数据读写性能。
#### 4.1.2 服务器负载均衡
当服务器负载过高时,数据入库性能会明显下降。因此,需要考虑使用负载均衡技术,将请求分发到多台服务器上,从而减轻单台服务器的压力。
### 4.2 软件优化
#### 4.2.1 MySQL配置优化
MySQL配置参数的调整可以显著影响数据库性能。以下是一些重要的优化参数:
| 参数 | 说明 |
|---|---|
| `innodb_buffer_pool_size` | 缓冲池大小,用于缓存经常访问的数据 |
| `innodb_flush_log_at_trx_commit` | 事务提交时是否立即写入日志 |
| `innodb_flush_method` | 刷新日志的方式 |
#### 4.2.2 PHP配置优化
PHP配置参数的调整也可以优化数据入库性能。以下是一些关键参数:
| 参数 | 说明 |
|---|---|
| `max_execution_time` | PHP脚本的最大执行时间 |
| `max_input_time` | PHP脚本读取输入数据的最长时间 |
| `memory_limit` | PHP脚本可使用的最大内存 |
**代码块:**
```php
// 调整PHP配置参数
ini_set('max_execution_time', 300); // 将最大执行时间设置为5分钟
ini_set('max_input_time', 60); // 将读取输入数据的最长时间设置为1分钟
ini_set('memory_limit', '512M'); // 将可使用的最大内存设置为512MB
```
**逻辑分析:**
这段代码通过`ini_set()`函数调整了三个PHP配置参数:`max_execution_time`、`max_input_time`和`memory_limit`。这些参数的调整可以防止PHP脚本因超时或内存不足而导致数据入库失败。
# 5. 监控与调优
### 5.1 性能监控工具
**5.1.1 MySQL慢查询日志**
慢查询日志是MySQL中一项重要的性能监控工具,它可以记录执行时间超过指定阈值的查询语句。通过分析慢查询日志,我们可以找出执行效率低下的查询语句,并针对性地进行优化。
**配置慢查询日志:**
```
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 1
```
**参数说明:**
* `slow_query_log`:开启慢查询日志
* `slow_query_log_file`:慢查询日志文件路径
* `long_query_time`:慢查询时间阈值(单位:秒)
**分析慢查询日志:**
```
tail -f /var/log/mysql/slow.log
```
慢查询日志中包含以下关键信息:
* 查询语句
* 执行时间
* 连接信息
* 索引使用情况
**5.1.2 PHP性能分析工具**
除了MySQL慢查询日志,我们还可以使用PHP性能分析工具来监控PHP代码的执行效率。常用的PHP性能分析工具包括:
* Xdebug
* Blackfire
* Tideways
这些工具可以提供详细的性能分析报告,包括函数调用、内存使用、数据库查询等信息。
### 5.2 性能调优策略
**5.2.1 索引优化**
索引是数据库中一种重要的数据结构,它可以加快数据查询的速度。优化索引可以有效提升数据入库性能。
**索引优化策略:**
* 创建必要的索引
* 选择合适的索引类型(B-Tree、哈希索引)
* 避免冗余索引
* 定期重建索引
**5.2.2 查询语句优化**
查询语句的优化也是提升数据入库性能的关键。以下是一些查询语句优化策略:
* 使用合适的连接类型(INNER JOIN、LEFT JOIN)
* 避免不必要的子查询
* 使用LIMIT子句限制查询结果
* 优化排序和分组操作
* 使用缓存查询结果
# 6. 其他优化技巧
### 6.1 数据预处理
在将数据插入数据库之前,可以对数据进行预处理,以提高入库效率。预处理操作包括:
- **数据类型转换:**将数据类型转换为数据库支持的类型,避免不必要的类型转换。
- **数据格式化:**将数据格式化为数据库期望的格式,例如日期格式化、字符串转义。
- **数据验证:**验证数据的有效性,防止无效数据入库。
### 6.2 异步入库
异步入库是指将数据插入操作交给一个后台进程处理,从而释放主线程,避免阻塞。这对于需要处理大量数据的场景非常有效。
**代码示例:**
```php
// 创建一个队列
$queue = new Queue();
// 将数据入库操作加入队列
$queue->push(function() {
// 执行数据入库操作
});
// 启动队列处理进程
$queue->start();
```
### 6.3 数据压缩
对于需要存储大量文本数据的情况,可以考虑使用数据压缩技术。这可以显著减少数据量,提高入库效率。
**代码示例:**
```php
// 使用 GZIP 压缩数据
$compressedData = gzencode($data);
// 将压缩后的数据插入数据库
$stmt = $pdo->prepare("INSERT INTO table (data) VALUES (?)");
$stmt->bindParam(1, $compressedData);
$stmt->execute();
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《PHP数据入库全攻略》旨在为PHP开发者提供从入门到精通的全面指南,涵盖数据入库的各个方面。从基础概念到高级技巧,专栏深入解析了数据入库的完整流程,揭秘了客户端与数据库之间的交互机制。此外,专栏还提供了性能优化、异常处理、安全实践、事务处理、批量操作、异步处理、并发控制、性能监控、日志记录、测试用例编写、代码重构、最佳实践、常见问题解答、性能调优和数据校验等方面的详细指导。通过深入学习本专栏,PHP开发者可以掌握数据入库的精髓,提升数据操作效率,确保数据完整性和安全性,并为构建高性能、可靠的PHP应用程序奠定坚实基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【API网关在系统对接中的应用】:一站式解决方案
# 摘要
API网关作为微服务架构中的关键组件,不仅提供了统一的入口管理服务,还承担着请求路由、负载均衡、安全验证和监控等重要功能。本文首先介绍了API网关的基本概念及其在系统架构中的作用,然后详细探讨了其设计原则,包括高可用性、扩展性和安全性,并比较了单体架构、微服务架构和Serverless架构等不同架构模式下的实现方式
【系统性能优化】:深入挖掘PHP在线考试系统性能瓶颈及解决方案

# 摘要
本文系统地探讨了PHP在线考试系统面临的性能挑战,并从理论到实践层面提出了一系列性能优化策略。首先介绍了性能优化的理论基础,强调了识别性能瓶颈和性能指标的重要性。其次,深入讨论了代码级
LS-DYNA隐式求解:材料模型的智慧选择与应用
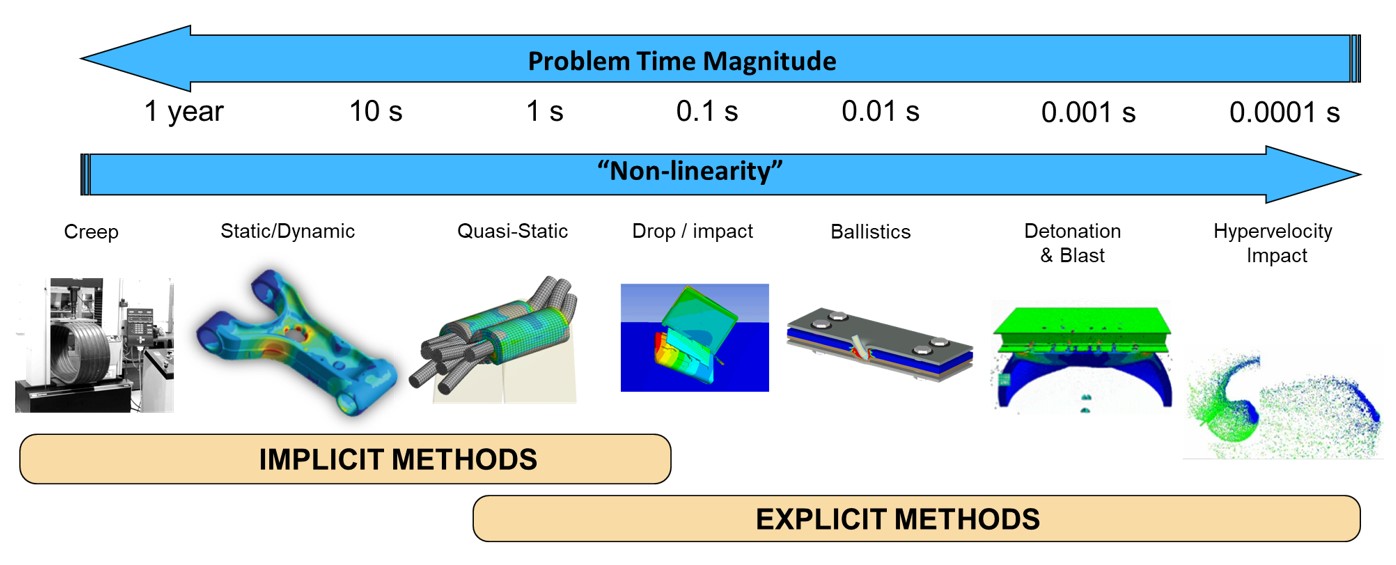
# 摘要
本文全面阐述了LS-DYNA隐式求解框架下材料模型的基础知识、分类、参数确定以及在实际应用中的表现和优化。首先,介绍了隐式求解的基本理论及其与材料模型的关系,强调了材料模型在提高求解精度和稳定性方面的作用。然后,详细讨论了材料模型的分类及其特点,以及如何通过实验数据和数值模
案例分析:企业如何通过三权分立强化Windows系统安全(实用型、私密性、稀缺性)

# 摘要
本文探讨了三权分立原则在Windows系统安全中的应用及其作用,详细介绍了三权分立的理论基础,并分析了如何在实践中结合Windows系
云计算平台上的多媒体内容分发:英语视听说教程数字化新途径

# 摘要
本文探讨了云计算平台在教育领域的应用,特别是在多媒体内容的分发、自动化处理和英语视听说教程的数字化实现方面。通过分析多媒体内容的特点和需求,本文详细阐述了云计算环境下的内容分发技术、存储管理,以及自动化处理流程。特别指出,内容上传、索引构建、用户交互分析是实现高效教学资源管理的关键步
【索引管理高效秘籍】:精通Solr索引构建与维护的黄金法则

# 摘要
本文系统地介绍了Solr索引的构建原理、维护策略及优化实践。首先,概述了Solr索引的基本概念和核心构成,随后深入探讨了索引构建的流程、存储结构和性能优化方法。在索引维护方面,本文详述了更新、删除、备份与恢复机制,并提供了监控与分析索引状态的策略。针对性能提升和结构优化,本文提出了一系列技术方案,包括查询性能
MIDAS M32动态处理艺术:压缩与限制的最佳实践
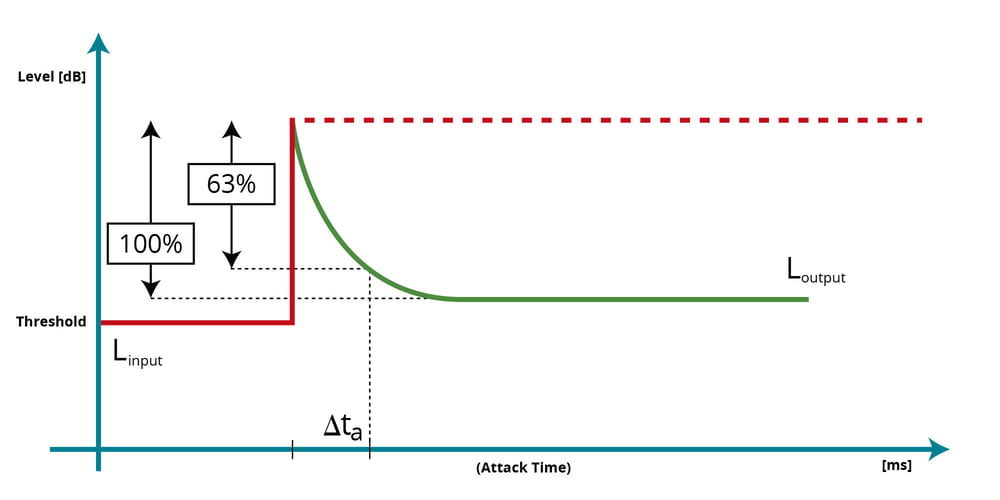
# 摘要
本文全面探讨了MIDAS M32数字混音器中动态处理功能的应用与优化。首先,介绍了压缩器和限制器的理论基础及其工作原理,接着详细分析了如何在MIDAS M32中设置和应用这些动态处理工具。第三章探讨了动态处理的高级技巧,包括音频信号的精细处理和实时动态处理的应用。案例研究展示了在
【源码编译】:OpenSSH到Android的编译环境与步骤精讲

# 摘要
本文详细介绍了如何在Android开发环境中搭建和编译OpenSSH,以及如何将编译后的OpenSSH集成和测试到Android设备上。文章
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )