【VSCode Python开发环境搭建秘籍】:从零基础到实战部署,一文搞定
发布时间: 2024-06-23 20:41:09 阅读量: 76 订阅数: 37 
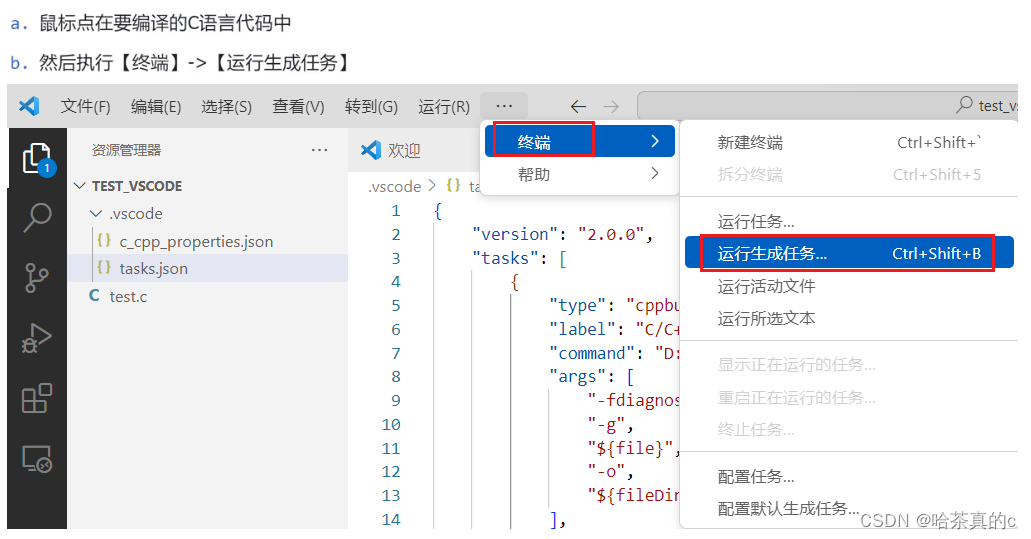
# 1. Python开发环境搭建**
Python开发环境的搭建是Python学习和开发的第一步。本章将介绍如何安装和配置Python开发环境,包括Python解释器的安装、IDE的选择和配置,以及必要的库和工具的安装。
1. **Python解释器的安装:**
- 下载Python官方网站的最新稳定版本。
- 按照安装向导进行安装,选择"添加Python 3.x到PATH"选项。
2. **IDE的选择和配置:**
- 推荐使用PyCharm或Visual Studio Code等IDE。
- 安装IDE后,配置Python解释器路径和虚拟环境。
# 2.1 Python语言基础
### 2.1.1 Python数据类型
Python是一种动态类型语言,这意味着变量在运行时被分配类型。Python支持多种内置数据类型,包括:
- **整数 (int)**:表示整数,如 1、-100
- **浮点数 (float)**:表示浮点数,如 3.14、-5.6
- **布尔值 (bool)**:表示真或假,如 True、False
- **字符串 (str)**:表示文本序列,如 "Hello World"
- **列表 (list)**:表示有序的可变元素集合,如 [1, 2, 3, "a"]
- **元组 (tuple)**:表示有序的不可变元素集合,如 (1, 2, 3, "a")
- **字典 (dict)**:表示键值对集合,如 {"name": "John", "age": 30}
### 2.1.2 Python运算符和表达式
Python支持各种运算符,用于执行算术、逻辑和比较操作。以下是几个常见的运算符:
- **算术运算符**:+、-、*、/、%
- **逻辑运算符**:and、or、not
- **比较运算符**:==、!=、<、>、<=、>=
表达式是使用运算符和操作数组合而成的。例如:
```python
# 算术表达式
result = 10 + 5 * 3
# 逻辑表达式
is_valid = (age >= 18) and (gender == "male")
# 比较表达式
if score > 90:
print("Excellent")
```
**代码逻辑逐行解读:**
1. `result = 10 + 5 * 3`:将 5 乘以 3,然后将结果加到 10 中,并将结果存储在变量 `result` 中。
2. `is_valid = (age >= 18) and (gender == "male")`:如果 `age` 大于或等于 18 且 `gender` 等于 "male",则将 `is_valid` 设置为 `True`。
3. `if score > 90:`:如果 `score` 大于 90,则执行缩进代码块。
# 3. Python面向对象编程**
### 3.1 类和对象
#### 3.1.1 类定义和对象创建
**类定义**
Python中的类使用`class`关键字定义,其语法格式如下:
```python
class ClassName:
# 类属性
class_attribute = value
# 构造函数
def __init__(self, *args, **kwargs):
# 对象属性
self.instance_attribute = value
```
**对象创建**
使用`class`定义的类可以创建对象,其语法格式如下:
```python
object_name = ClassName(arg1, arg2, ..., kwarg1=value1, kwarg2=value2, ...)
```
其中,`object_name`为创建的对象名称,`arg1`, `arg2`, ..., `kwarg1`, `kwarg2`, ...为创建对象时传递的参数。
#### 3.1.2 类属性和方法
**类属性**
类属性是属于类的属性,所有该类创建的对象都共享该属性。类属性在类定义中使用`class_attribute = value`的形式定义。
**类方法**
类方法是属于类的函数,所有该类创建的对象都可以调用该方法。类方法在类定义中使用`def method_name(self, *args, **kwargs):`的形式定义,其中`self`参数表示调用该方法的对象本身。
### 3.2 继承和多态
#### 3.2.1 子类继承
**子类定义**
Python中使用`class`关键字定义子类,其语法格式如下:
```python
class SubclassName(SuperclassName):
# 子类属性
subclass_attribute = value
# 子类方法
def subclass_method(self, *args, **kwargs):
# 方法实现
```
其中,`SubclassName`为子类名称,`SuperclassName`为父类名称。
**继承属性和方法**
子类继承父类的所有属性和方法,子类可以重写父类的方法,也可以定义自己的新属性和方法。
#### 3.2.2 多态实现
**多态**
多态是指不同的对象可以对同一个方法做出不同的响应。在Python中,多态可以通过继承和方法重写来实现。
**方法重写**
当子类重写父类的方法时,子类的方法将覆盖父类的方法。当调用该方法时,会根据对象的类型调用相应的方法。
### 3.3 Python异常处理
#### 3.3.1 异常类型和处理
**异常类型**
Python中有内置的异常类型,如`ValueError`, `IndexError`, `KeyError`等,这些异常类型表示程序中发生的错误。
**异常处理**
Python中使用`try-except`语句来处理异常,其语法格式如下:
```python
try:
# 可能引发异常的代码
except ExceptionType1 as e1:
# 处理 ExceptionType1 异常
except ExceptionType2 as e2:
# 处理 ExceptionType2 异常
else:
# 没有引发异常时的处理
finally:
# 无论是否引发异常,都会执行的处理
```
#### 3.3.2 自定义异常
**自定义异常**
Python中可以自定义异常,其语法格式如下:
```python
class CustomException(Exception):
def __init__(self, message):
self.message = message
```
其中,`CustomException`为自定义异常的名称,`message`为异常消息。
**抛出异常**
使用`raise`关键字抛出异常,其语法格式如下:
```python
raise CustomException("异常消息")
```
# 4. Python数据处理与分析
### 4.1 NumPy基础
NumPy(Numerical Python)是Python中用于科学计算和数据分析的强大库。它提供了多维数组对象和一系列数学运算函数,使数据处理和分析变得更加高效。
#### 4.1.1 NumPy数组创建和操作
NumPy数组是同质数据的集合,可以是一维、二维或多维的。可以通过以下方式创建NumPy数组:
```python
import numpy as np
# 从列表创建一维数组
array1 = np.array([1, 2, 3, 4, 5])
# 从嵌套列表创建二维数组
array2 = np.array([[1, 2, 3], [4, 5, 6]])
# 创建具有特定形状和数据类型的数组
array3 = np.zeros((3, 4), dtype=np.int32)
```
NumPy提供了丰富的数组操作函数,包括:
- **索引和切片:** `array[index]` 或 `array[start:stop:step]`
- **数学运算:** `+`, `-`, `*`, `/`, `**`
- **比较运算:** `==`, `!=`, `<`, `>`, `<=`, `>=`
- **逻辑运算:** `&`, `|`, `~`
#### 4.1.2 NumPy数学运算
NumPy提供了广泛的数学运算函数,包括:
- **三角函数:** `sin()`, `cos()`, `tan()`
- **指数函数:** `exp()`, `log()`, `log10()`
- **统计函数:** `mean()`, `std()`, `var()`
- **线性代数函数:** `linalg.solve()`, `linalg.inv()`, `linalg.eig()`
这些函数可以对NumPy数组执行复杂的操作,简化了科学计算和数据分析。
### 4.2 Pandas数据分析
Pandas是Python中用于数据操作和分析的另一个强大的库。它提供了数据框和数据系列对象,以及一系列数据处理和分析工具。
#### 4.2.1 Pandas数据框创建和操作
数据框是类似于表格的结构,包含行和列。可以通过以下方式创建Pandas数据框:
```python
import pandas as pd
# 从字典创建数据框
df1 = pd.DataFrame({'Name': ['John', 'Mary', 'Bob'], 'Age': [25, 30, 28]})
# 从CSV文件创建数据框
df2 = pd.read_csv('data.csv')
```
Pandas提供了丰富的DataFrame操作函数,包括:
- **索引和切片:** `df[index]` 或 `df[start:stop:step]`
- **列操作:** `df['column_name']`, `df.drop('column_name')`
- **行操作:** `df.loc[index]`, `df.iloc[index]`
- **数据聚合:** `df.groupby('column_name').agg('function')`
#### 4.2.2 Pandas数据分析和可视化
Pandas提供了强大的数据分析和可视化功能,包括:
- **统计分析:** `df.describe()`, `df.corr()`
- **数据过滤:** `df[condition]`, `df.query('condition')`
- **数据排序:** `df.sort_values('column_name')`
- **可视化:** `df.plot()`, `df.hist()`, `df.scatter()`
这些功能使Pandas成为数据探索和分析的理想工具。
### 4.3 Matplotlib数据可视化
Matplotlib是Python中用于数据可视化的库。它提供了丰富的绘图类型和自定义选项,使数据可视化变得更加灵活。
#### 4.3.1 Matplotlib绘图基础
可以通过以下方式创建基本的Matplotlib绘图:
```python
import matplotlib.pyplot as plt
# 创建折线图
plt.plot([1, 2, 3, 4], [5, 6, 7, 8])
# 显示绘图
plt.show()
```
Matplotlib提供了各种绘图类型,包括:
- **折线图:** `plt.plot()`
- **散点图:** `plt.scatter()`
- **条形图:** `plt.bar()`
- **饼图:** `plt.pie()`
#### 4.3.2 Matplotlib高级绘图
Matplotlib提供了高级绘图功能,包括:
- **子图:** `plt.subplot()`
- **图例:** `plt.legend()`
- **标题和标签:** `plt.title()`, `plt.xlabel()`, `plt.ylabel()`
- **自定义颜色和标记:** `plt.color()`, `plt.marker()`
这些功能使Matplotlib成为创建复杂且信息丰富的可视化的强大工具。
# 5.1 Django Web框架
### 5.1.1 Django项目创建和配置
#### 项目创建
1. 安装Django:`pip install django`
2. 创建项目:`django-admin startproject myproject`
3. 进入项目目录:`cd myproject`
4. 创建应用:`python manage.py startapp myapp`
#### 项目配置
1. 编辑`settings.py`文件:
- 设置时区:`TIME_ZONE = 'Asia/Shanghai'`
- 设置数据库:`DATABASES = {...}`
- 设置应用程序:`INSTALLED_APPS = ['myapp', ...]`
2. 运行迁移:`python manage.py migrate`
3. 创建超级用户:`python manage.py createsuperuser`
### 5.1.2 Django模型和视图
#### 模型
- 定义数据模型:`models.py`
- 模型字段类型:`CharField`、`IntegerField`、`BooleanField`等
- 模型关系:`ForeignKey`、`ManyToManyField`等
```python
# models.py
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField()
is_active = models.BooleanField(default=True)
```
#### 视图
- 定义视图:`views.py`
- 处理HTTP请求和响应
- 使用模板渲染HTML页面
```python
# views.py
from django.shortcuts import render
def index(request):
persons = Person.objects.all()
context = {'persons': persons}
return render(request, 'index.html', context)
```
#### URL路由
- 定义URL路由:`urls.py`
- 将URL请求映射到视图
```python
# urls.py
from django.urls import path
from . import views
urlpatterns = [
path('index/', views.index, name='index'),
]
```
#### 模板
- 定义模板:`templates/index.html`
- 使用Django模板语言渲染数据
```html
<!-- index.html -->
{% for person in persons %}
<p>{{ person.name }} - {{ person.age }}</p>
{% endfor %}
```
#### 运行项目
1. 启动服务器:`python manage.py runserver`
2. 访问URL:`http://127.0.0.1:8000/index/`
# 6. Python实战部署**
**6.1 Python项目打包和部署**
**6.1.1 Python项目打包**
Python项目打包是将项目代码、依赖库和资源文件打包成一个可分发的归档文件,以便在其他环境中部署和运行。常用的打包工具有:
- **PyInstaller:**适用于Windows、macOS和Linux,生成可执行文件。
- **cx_Freeze:**适用于Windows,生成可执行文件。
- **nuitka:**适用于Windows、macOS和Linux,生成本机代码。
**打包步骤:**
1. 安装打包工具。
2. 创建一个包含项目代码和资源文件的目录。
3. 运行打包命令,例如:
```
pyinstaller --onefile main.py
```
**6.1.2 Python项目部署到服务器**
项目打包后,需要将其部署到服务器上,以便通过互联网访问。常见的部署方式有:
- **SSH:**使用安全外壳协议将文件传输到服务器。
- **FTP:**使用文件传输协议将文件传输到服务器。
- **云平台:**使用云平台提供的服务,例如Heroku或AWS,自动部署和管理项目。
**部署步骤:**
1. 选择一种部署方式。
2. 将打包后的项目文件上传到服务器。
3. 配置服务器环境,例如安装必要的依赖库。
4. 启动项目,例如运行以下命令:
```
python main.py
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏涵盖了使用 Visual Studio Code (VSCode) 搭建 Python 开发环境的各个方面。从基础设置到高级技术,您将了解如何:
* 配置 Python 解释器和扩展
* 使用 Pip 和 Conda 管理 Python 包
* 调试和分析 Python 代码
* 编写单元测试和测量代码覆盖率
* 优化 Python 代码性能
* 实施多线程和异步编程
* 掌握数据结构、算法和设计模式
* 构建 web 应用程序和数据可视化工具
无论您是 Python 初学者还是经验丰富的开发人员,本专栏都将为您提供在 VSCode 中高效开发 Python 应用程序所需的所有知识和技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【QT基础入门】:QWidgets教程,一步一个脚印带你上手
# 摘要
本文全面介绍了Qt框架的安装配置、Widgets基础、界面设计及进阶功能,并通过一个综合实战项目展示了这些知识点的应用。首先,文章提供了对Qt框架及其安装配置的简要介绍。接着,深入探讨了Qt Widgets,包括其基本概念、信号与槽机制、布局管理器等,为读者打下了扎实的Qt界面开发基础。文章进一步阐述了Widgets在界面设计中的高级用法,如标准控件的深入使用、资源文件和样式表的应用、界面国际化处理。进阶功能章节揭示了Qt对话框、多文档界面、模型/视图架构以及自定义控件与绘图的强大功能。最后,实战项目部分通过需求分析、问题解决和项目实现,展示了如何将所学知识应用于实际开发中,包括项目
数学魔法的揭秘:深度剖析【深入理解FFT算法】的关键技术

# 摘要
快速傅里叶变换(FFT)是信号处理领域中一项关键的数学算法,它显著地降低了离散傅里叶变换(DFT)的计算复杂度。本文从FFT算法的理论基础、实现细节、在信号处理中的应用以及编程实践等多方面进行了详细讨论。重点介绍了FFT算法的数学原理、复杂度分析、频率域特性,以及常用FFT变体和优化技术。同时,本文探讨了FFT在频谱分析、数字滤波器设计、声音和图像处理中的实
MTK-ATA技术入门必读指南:从零开始掌握基础知识与专业术语

# 摘要
MTK-ATA技术作为一种先进的通信与存储技术,已经在多个领域得到广泛应用。本文首先介绍了MTK-ATA技术的概述和基础理论,阐述了其原理、发展以及专业术语。随后,本文深入探讨了MTK-ATA技术在通信与数据存储方面的实践应用,分析了其在手机通信、网络通信、硬盘及固态存储中的具体应用实例。进一步地,文章讲述了MTK-ATA技术在高
优化TI 28X系列DSP性能:高级技巧与实践(性能提升必备指南)

# 摘要
本文系统地探讨了TI 28X系列DSP性能优化的理论与实践,涵盖了从基础架构性能瓶颈分析到高级编译器技术的优化策略。文章深入研究了内存管理、代码优化、并行处理以及多核优化,并展示了通过调整电源管理和优化RTOS集成来进一步提升系统级性能的技巧。最后,通过案例分析和性能测试验证了优化
【提升响应速度】:MIPI接口技术在移动设备性能优化中的关键作用

# 摘要
移动设备中的MIPI接口技术是实现高效数据传输的关键,本论文首先对MIPI接口技术进行了概述,分析了其工作原理,包括MIPI协议栈的基础、信号传输机制以及电源和时钟管理。随后探讨了MIPI接口在移动设备性能优化中的实际应用,涉及显示和摄像头性能提升、功耗管理和连接稳定性。最后,本文展望了MIPI技术的未来趋势,分析了新兴技术标准的进展、性能优化的创新途径以及当前面临的技术挑战。本论文旨在为移动
PyroSiM中文版高级特性揭秘:精通模拟工具的必备技巧(专家操作与界面布局指南)
# 摘要
PyroSiM是一款功能强大的模拟软件,其中文版提供了优化的用户界面、高级模拟场景构建、脚本编程、自动化工作流以及网络协作功能。本文首先介绍了PyroSiM中文版的基础配置和概览,随后深入探讨了如何构建高级模拟场景,包括场景元素组合、模拟参数调整、环境动态交互仿真、以及功能模块的集成与开发。第三章关注用户界面的优化
【云计算优化】:选择云服务与架构设计的高效策略
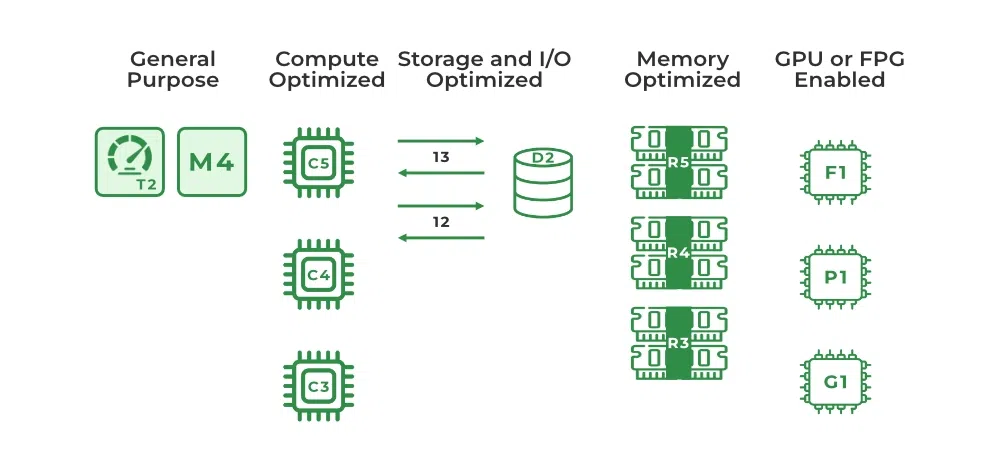
# 摘要
本文系统地探讨了云计算优化的各个方面,从云服务类型的选择到架构设计原则,再到成本控制和业务连续性规划。首先概述了云计算优化的重要性和云服务模型,如IaaS、PaaS和SaaS,以及在选择云服务时应考虑的关键因素,如性能、安全性和成本效益。接着深入探讨了构建高效云架构的设计原则,包括模块化、伸缩性、数据库优化、负载均衡策略和自动化扩展。在优化策
性能飙升指南:Adam's CAR性能优化实战案例
# 摘要
随着软件复杂性的增加,性能优化成为确保应用效率和响应速度的关键环节。本文从理论基础出发,介绍了性能优化的目的、指标及技术策略,并以Adam's CAR项目为例,详细分析了项目性能需求及优化目标。通过对性能分析与监控的深入探讨,本文提出了性能瓶颈识别和解决的有效方法,分别从代码层面和系统层面展示了具体的优化实践和改进措施。通过评估优化效果,本文强调了持续监控和分析的重要性,以实现性能的持续改进和提升。
#
【Oracle服务器端配置】:5个步骤确保PLSQL-Developer连接稳定性
# 摘要
本文对Oracle数据库服务器端配置进行了详细阐述,涵盖了网络环境、监听器优化和连接池管理等方面。首先介绍
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )