【深入了解PCIe v4.1 DMA操作】:原理深度剖析与实现策略
发布时间: 2024-12-21 09:37:19 阅读量: 5 订阅数: 11 

【java毕业设计】智慧社区在线教育平台(源代码+论文+PPT模板).zip
# 摘要
PCIe总线技术作为现代计算机系统中高速数据传输的关键,与DMA(直接内存访问)技术紧密相连,有效降低CPU负载并提高系统性能。本文系统性介绍了PCIe总线技术和DMA的概念,并深入探讨了PCIe v4.1协议的新特性和DMA传输原理。通过分析DMA在数据传输中的应用,实践案例和软件实现,本文提供了编写DMA控制器驱动程序的策略,DMA操作的安全性保障,以及性能优化方法。此外,文章还探讨了PCIe和DMA技术的发展趋势,包括虚拟化支持和在AI、大数据应用中的展望,为PCIe v4.1 DMA操作的高级应用提供了见解。
# 关键字
PCIe总线;DMA;数据传输;协议特性;性能优化;技术趋势
参考资源链接:[PCI Express v4.1 XDMA 学习笔记:DMA桥接子系统解析](https://wenku.csdn.net/doc/644b7a5afcc5391368e5ee07?spm=1055.2635.3001.10343)
# 1. PCIe总线技术与DMA概念介绍
## 1.1 PCIe总线技术概述
PCI Express(PCIe)总线技术已经成为现代计算机系统中不可或缺的接口标准。它是一种高速串行计算机扩展总线标准,用于连接主板与各种外围设备,包括显卡、网络卡、存储设备等。PCIe提供了一种灵活的点对点连接方式,允许设备间以极高的速度传输数据。随着技术的迭代,PCIe已经发展到第四代,也就是PCIe v4.1,它带来了更高的带宽和新的特性,以满足日益增长的数据传输需求。
## 1.2 DMA的基本概念
直接内存访问(DMA)是一种允许硬件子系统直接读写系统内存的技术,无需CPU介入处理数据传输。DMA技术可以极大地减少CPU的负担,因为它允许外部设备绕过CPU直接与内存交互。这种技术在需要大量数据传输的应用中尤为重要,如文件存储、显卡图像渲染和网络数据包的接收与发送等。随着系统性能需求的不断提升,DMA技术与PCIe总线技术的结合变得越来越紧密。
# 2. PCIe v4.1协议基础与特性
## 2.1 PCIe v4.1协议概览
### 2.1.1 PCIe的发展历程及v4.1的新特性
PCIe(Peripheral Component Interconnect Express),作为一种高速串行计算机扩展总线标准,被广泛应用于服务器、数据中心、高性能计算系统等领域。从PCIe的初始版本到目前的PCIe v4.1,协议经历了多次迭代,每一次更新都带来了显著的性能提升和新功能的增加。
PCIe 1.0在2002年被引入,提供了2.5 GT/s(千兆传输/秒)的原始带宽。几年后,PCIe 2.0翻倍了这一速度,达到了5 GT/s。随后,2010年左右,PCIe 3.0进一步将速度提升到了8 GT/s,并引入了256b/257b编码和前向纠错(FEC)等技术。2017年,PCIe 4.0推出,将速率再次翻倍,达到16 GT/s,为服务器和存储设备带来了革命性的性能提升。
2022年,PCI-SIG正式发布了PCIe 5.0规范,实现了32 GT/s的惊人速度,进一步缩短了数据传输延迟。而我们这里关注的PCIe v4.1,尽管官方并没有明确发布这一版本,但在实际市场和开发社区中,通常指代的是在PCIe 4.0基础上引入的优化和改进,具体包括更精细的流量控制、改进的功率管理策略以及对新型设备和应用场景的更好支持。
新特性例如,增加链路状态的稳定性、改善对低功耗状态的管理,使得设备在空闲时能更有效地进入低功耗模式,从而降低总体能耗。此外,还引入了更复杂的错误检测与纠正机制,保证数据传输的可靠性,对于数据中心等环境尤为重要。
### 2.1.2 PCIe体系架构及信号层
PCIe总线的体系架构是一个分层的结构,它由事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer)三个基本层次组成。
- **事务层**主要负责处理PCIe总线上的请求和响应,是协议的最高层,它对系统软件而言是透明的。事务层通过一系列抽象的事务来与系统软件交互,如内存读写请求、I/O操作、配置读写等。
- **数据链路层**负责确保事务的正确交付,它实现了一个可靠的点对点连接,用于确认数据包的接收和发送。该层还负责维护总线上的流量控制和数据包序列的顺序。
- **物理层**则与信号的传输和接收密切相关。它定义了电气和机械接口特性,包括信号的编码、解码、发送和接收。物理层还负责链路的初始化和配置,以及错误检测和纠正。
信号层将协议的操作从上层的逻辑和事务转换为实际的电信号传输。PCIe总线采用差分信号技术,每个通道包含一对发送和接收线路。这种设计有效地减少了信号干扰,允许高速的数据传输。
## 2.2 PCIe v4.1 DMA传输原理
### 2.2.1 DMA的基本工作原理
直接内存访问(Direct Memory Access,DMA)是一种硬件能力,允许某些内部或外部设备直接读写系统内存,而不通过CPU。这样做可以大幅提升数据传输的效率,因为CPU不再需要为每一字节的数据传输提供中间服务,从而降低了处理工作量和总体延迟。
DMA通常包含以下几个关键步骤:
1. **设备请求DMA通道**:设备需要与内存之间进行数据传输时,它会向DMA控制器发出请求。
2. **DMA请求(DREQ)**:一旦DMA控制器接受请求,它会向CPU发出DMA请求。
3. **CPU响应**:在CPU的空闲周期中,它将同意DMA请求,授权设备访问内存。
4. **数据传输**:设备通过DMA控制器直接读写内存。
5. **结束传输**:当数据传输完成,设备会通知DMA控制器,并且DMA控制器撤销CPU的请求。
整个过程CPU参与较少,主要负责处理请求和结束确认,从而实现高效的数据处理。
### 2.2.2 PCIe DMA与传统I/O对比
传统的I/O数据传输方式中,数据从设备传输到CPU的寄存器,然后CPU再将其存储到内存中。这种方法的一个缺点是CPU的处理能力会被频繁的数据传输请求所占用,特别是在处理大量数据时,会严重影响系统的性能。
而使用PCIe DMA的数据传输方式则绕过了CPU,直接在设备和内存之间进行数据传输。这种传输方式具有如下优势:
- **性能提升**:由于直接与内存交互,DMA传输减少了CPU的干预,大幅提高了数据处理速度。
- **减少CPU负载**:CPU不再需要参与数据传输的每个环节,可以专注于执行其他核心任务。
- **灵活性**:支持多种内存映射方法,使得设备可以灵活地访问系统内存。
## 2.3 PCIe v4.1中的DMA传输机制
### 2.3.1 QEMU模拟器中的DMA实现
在虚拟化环境中,模拟器如QEMU提供了对硬件设备的虚拟化支持,包括DMA操作。QEMU中的DMA实现依赖于其虚拟I/O(vI/O)架构,这种架构允许模拟的硬件设备能够访问虚拟机的内存空间。
QEMU通过以下机制实现DMA:
1. **设备模型(Device Models)**:QEMU为每种虚拟设备提供了一个设备模型,并实现了一个与真实硬件通信的前端接口。
2. **IOMMU虚拟化**:在虚拟化环境中,IOMMU(输入/输出内存管理单元)负责管理DMA请求,并为设备提供内存的虚拟地址到物理地址的转换。
3. **地址翻译(Address Translation)**:为了在虚拟化环境中正确地执行DMA操作,QEMU必须维护一个地址翻译机制,确保虚拟设备能够正确访问宿主机内存。
### 2.3.2 硬件支持的DMA机制
硬件层面的DMA机制与模拟器实现有着本质的不同。硬件设备如GPU、网络控制器等,通过物理总线直接与系统内存连接,并进行内存访问操作。在PCIe v4.1中,这些硬件设备使用特定的硬件DMA控制器来处理事务层、数据链路层和物理层的所有交互。
硬件DMA机制通常包含以下几个组件:
- **DMA控制器**:是硬件设备中的一个组件,负责管理DMA传输。
- **请求队列(Request Queue)**:用于排队DMA请求。
- **完成队列(Completion Queue)**:用于记录完成的DMA操作,使得系统能够处理完成的通知。
硬件DMA实现通常会利用现代操作系统的内核驱动程序来配置和启动DMA操作,驱动程序会初始化DMA引擎,为设备分配适当的内存缓冲区,并管理好内存映射与权限。
# 3. 深入分析PCIe DMA操作的实践应用
## 3.1 DMA在数据传输中的角色
### 3.1.1 DMA与CPU负载关系
直接内存访问(DMA)技术允许外围设备直接访问系统内存,而不经过CPU的介入,从而减少了CPU的负担。随着技术的发展,特别是PCIe总线技术的普及,DMA已经变得不可或缺。在现代计算机系统中,大量数据的高速传输是常见的需求,例如高清视频的处理、大文件的复制以及虚拟机的内存复制等。这些任务如果全部依赖CPU来处理,将会消耗大量的处理器资源,导致CPU无法高效执行其他逻辑运算任务。
为了具体理解这一点,可以考虑一个典型的文件复制操作。当操作系统需要将大量数据从一个存储器复制到另一个存储器时,如果使用传统的内存复制方法,CPU必须逐个字节或逐个数据块地读取数据并写入新位置。在这个过程中,CPU大部分时间都消耗在了数据搬移上,而不是执行程序逻辑。DMA的介入,使得数据传输可以绕过CPU,直接在源地址和目标地址之间进行,显著降低了CPU的负载。
### 3.1.2 DMA对系统性能的影响
DMA技术不仅减少了CPU的负载,还显著提高了系统的整体性能。在没有DMA的系统中,处理器需要通过执行一系列指令来完成数据传输任务,这不仅耗时,还消耗处理器资源。而有了DMA控制器的介入,数据传输变得更为高效。DMA控制器可以管理总线上的数据流,实现多通道并发传输,并且通常具有较高的传输速率。
举个例子,当执行大规模的图形渲染时,图形处理单元(GPU)需要访问大量纹理数据和渲染目标。如果GPU不能直接访问系统内存(即没有DMA支持),则需要CPU将数据从内存中取出,然后传送给GPU。这种情况下,图形渲染效率会受到CPU性能的限制。通过DMA,GPU可以绕过CPU直接访问内存,实现更高的渲染效率和更佳的图形性能。
## 3.2 PCIe DMA操作的实现策略
### 3.2.1 编写DMA控制器的驱动程序
要使PCIe总线上的设备能够执行DMA操作,首先需要编写相应的驱动程序。驱动程序需要与硬件设备的DMA控制器进行交互,实现数据的传输。编写驱动程序的目的是为了创建一个能够控制硬件行为的软件接口,使得硬件可以被操作系统以及应用程序所利用。
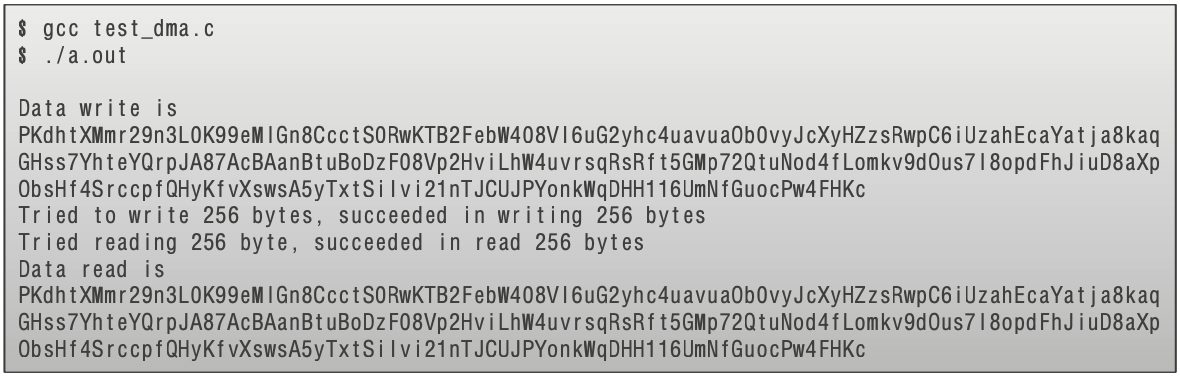
编写驱动程序时,开发者需要详细理解硬件的技术手册,了解DMA控制器的各个寄存器和其功能。例如,需要知道如何配置DMA控制器来开始和停止数据传输,如何设置源地址和目标地址,以及如何处理传输中断。以下是一个简化的代码示例,演示了在Linux环境下,驱动程序如何通过设置寄存器来启动DMA传输:
```c
#define DMA_CONTROL_REG 0x00 // 假设控制寄存器的地址为0x00
#define DMA_SRC_ADDR_REG 0x04 // 假设源地址寄存器的地址为0x04
#define DMA_DST_ADDR_REG 0x08 // 假设目标地址寄存器的地址为0x08
void start_dma_transfer(uint32_t src, uint32_t dst, size_t size) {
// 1. 关闭DMA控制器以进行配置
outl(0, DMA_CONTROL_REG);
// 2. 设置源地址和目标地址
outl(src, DMA_SRC_ADDR_REG);
outl(dst, DMA_DST_ADDR_REG);
// 3. 设置传输大小
outl(size, DMA_CONTROL_REG);
// 4. 启动DMA传输
outl(1, DMA_CONTROL_REG);
}
```
### 3.2.2 DMA缓冲区的管理和分配
为了使DMA传输顺利进行,需要预先分配一块系统内存作为传输的缓冲区。这块内存需要满足DMA传输的要求,例如对齐、可访问性等。在现代操作系统中,内核提供了专用的API来分配和管理适合DMA的内存。
在Linux内核中,可以使用`dma_alloc_coherent`函数来分配一块连续的物理内存,并保证这块内存的虚拟地址和物理地址是一致的,这对于DMA传输是必须的。以下是一个简单的示例:
```c
#include <linux/dma-mapping.h>
void *dma_buffer;
size_t buffer_size = 4096; // 分配4KB的DMA缓冲区
dma_buffer = dma_alloc_coherent(&init_task, buffer_size,
(dma_addr_t *)&dma_handle, GFP_KERNEL);
if (!dma_buffer) {
printk("dma_alloc_coherent failed\n");
// 处理错误...
}
```
通过上述代码,驱动程序可以为DMA操作分配一块适当的缓冲区。这样,外围设备就可以使用这个缓冲区进行数据传输,而无需CPU参与。
## 3.3 实际案例分析
### 3.3.1 Linux内核中的DMA映射案例
Linux内核中,DMA映射是一个非常重要的部分。为了安全和高效地实现用户空间和内核空间之间的数据传输,内核提供了多个API来映射和释放用户空间的缓冲区,以供DMA使用。
举一个典型的案例,当网络接口卡(NIC)接收数据包时,为了将数据包从NIC缓冲区传输到用户空间的应用程序,必须进行DMA映射。首先,驱动程序需要调用`dma_map_single`函数,将用户空间的缓冲区映射为内核可以访问的DMA缓冲区。在数据传输完成后,需要调用`dma_unmap_single`函数来通知内核数据传输完成,释放映射。
```c
void *user_buffer; // 用户空间缓冲区指针
dma_addr_t dma_handle;
size_t size = 1024; // 数据包大小
// 映射用户缓冲区
dma_handle = dma_map_single(&init_task, user_buffer, size, DMA_FROM_DEVICE);
// ... NIC接收数据包到user_buffer ...
// 取消映射
dma_unmap_single(&init_task, dma_handle, size, DMA_FROM_DEVICE);
```
### 3.3.2 现代GPU中的PCIe DMA运用实例
GPU(图形处理单元)是使用PCIe DMA技术最典型的场景之一。GPU处理图形和并行计算任务时,需要频繁地访问系统内存中的大规模数据集。为了提供足够的带宽,GPU通常通过PCIe总线连接到系统,并利用DMA进行高效的数据传输。
在GPU计算中,如NVIDIA的CUDA技术,PCIe DMA用于在主机内存(CPU的内存)和设备内存(GPU的内存)之间传输数据。CUDA API提供了多种函数来处理主机和设备之间的内存传输,例如`cudaMemcpy`函数。在底层,这些函数会调用驱动程序的DMA接口,实现数据的高效传输。
```c
// CUDA内存复制示例
void *device_ptr; // GPU端内存指针
void *host_ptr; // 主机端内存指针
size_t size = 2048; // 要复制的数据大小
// 将数据从主机内存复制到设备内存
cudaMemcpy(device_ptr, host_ptr, size, cudaMemcpyHostToDevice);
```
在上述CUDA代码示例中,`cudaMemcpy`函数在后台使用了DMA来完成数据的传输工作。GPU通过DMA能够直接访问主机内存中的数据,从而实现了高速的数据交换。
在本章中,我们详细探讨了PCIe DMA操作的实践应用,从DMA在数据传输中的角色到具体的实现策略,再到实际案例的分析,每一部分都由浅入深地展示了PCIe DMA的深刻内涵和实际操作过程。这些内容对于理解PCIe技术在现代计算机系统中的应用至关重要。
# 4. PCIe v4.1 DMA操作的软件实现
## 4.1 DMA编程接口和API分析
在第四章中,我们将深入了解PCIe v4.1的DMA操作是如何通过软件层面实现的。首先,我们将探讨现有的DMA编程接口和API的功能以及它们在实际应用中的使用方法。
### 4.1.1 现有DMA API的功能和使用
现代操作系统为DMA操作提供了丰富的API。例如,在Linux内核中,`dma_map_*`系列函数用于将CPU内存地址映射到DMA地址空间。这些API允许设备直接访问内存,而不需要CPU介入。
```c
dma_addr_t dma_map_single(struct device *dev, void *cpu_addr, size_t size,
enum dma_data_direction direction);
```
该函数的参数包括:
- `struct device *dev`:设备结构体指针,用于标识哪个设备进行DMA操作。
- `void *cpu_addr`:CPU内存地址,该地址的内存区域将会被映射。
- `size_t size`:要映射的内存区域大小。
- `enum dma_data_direction direction`:DMA传输方向,例如`DMA_TO_DEVICE`、`DMA_FROM_DEVICE`或`DMA_BIDIRECTIONAL`。
映射后返回的`dma_addr_t`类型是设备能理解的物理地址,设备可以通过这个地址进行数据传输。
### 4.1.2 开发自定义DMA API的考虑
在某些特定场景下,开发者可能需要创建自定义的DMA API来满足特殊需求。开发自定义API时需考虑以下要点:
- **兼容性**:确保API能够在不同版本的内核和硬件上正常工作。
- **性能**:优化DMA操作,以最小化延迟和提升吞吐量。
- **安全**:确保API提供足够的隔离和保护机制,防止潜在的DMA攻击。
- **易用性**:API应设计得易于理解和使用,提供必要的文档和示例。
开发者在设计自定义API时,还需要考虑与现有DMA框架和驱动程序的整合性,以及如何在不影响系统稳定性的情况下进行测试。
## 4.2 DMA操作的安全性与隔离
### 4.2.1 DMA攻击的防范措施
随着硬件技术的发展,DMA攻击已成为一种潜在的安全风险。这类攻击允许未授权的设备访问系统的物理内存。防范措施包括:
- **IOMMU(输入输出内存管理单元)**:使用IOMMU能够对设备的内存访问进行隔离,从而限制设备只能访问授权的内存区域。
- **沙盒机制**:为每个设备创建独立的内存区域,限制设备只能在该区域内操作。
- **签名和验证**:确保所有DMA请求都经过签名和验证,以防止篡改和伪造。
### 4.2.2 IOMMU在DMA安全中的应用
IOMMU为系统中的内存访问提供了额外的安全层次。IOMMU可以跟踪每个设备的内存访问权限,并提供内存地址转换功能,确保设备的内存访问仅限于授权的区域。
```bash
# 配置IOMMU的示例命令
echo 1 > /sys/kernel/iommu_groups/enable
```
该命令会启用系统中的IOMMU组,并为每个设备创建独立的内存区域。配置IOMMU后,所有设备的DMA请求都需要经过IOMMU的检查,确保安全性。
## 4.3 DMA操作的调试与性能优化
### 4.3.1 调试DMA操作的方法和工具
调试DMA操作通常需要深入了解系统底层的硬件和软件交互。常用调试工具包括`dmesg`命令、`ftrace`、`perf`工具等。以下是使用`dmesg`来检查DMA错误的一个示例:
```bash
dmesg | grep DMA
```
这个命令会打印所有与DMA相关的内核日志信息,帮助开发者快速定位问题。
### 4.3.2 提升DMA性能的策略和技术
提升DMA性能的策略包括:
- **内存池分配**:预先分配和管理内存池可以减少内存分配和释放的开销。
- **缓存对齐**:确保DMA缓冲区对齐到缓存线,减少缓存未命中。
- **批量传输**:在可能的情况下使用批量传输来减少控制开销。
此外,使用先进的编程技术如零拷贝(zero-copy)和内存页合并(page merging)也可以显著提升DMA的性能。
通过上述章节的分析,我们可以看到PCIe v4.1 DMA操作的软件实现涉及了编程接口、安全隔离和性能调试优化等多个方面。对于开发者来说,了解这些方面是实现高效、安全和可维护的DMA操作的基础。
# 5. 未来PCIe和DMA技术的发展趋势
随着计算机系统越来越依赖于高速数据传输和处理,PCI Express (PCIe) 和直接内存访问 (DMA) 技术的重要性日益增长。本章将探讨这两种技术未来可能的发展趋势。
## 5.1 PCIe总线技术的演进路线图
PCIe作为一种高速串行计算机扩展总线标准,已经发展了多个版本。技术的演进遵循摩尔定律,同时不断适应新的市场需求和技术挑战。
### 5.1.1 PCIe未来版本的预测和期望
随着云计算、人工智能、物联网和高吞吐量网络应用的兴起,PCIe技术需要进一步发展以满足这些新环境下的要求。未来的PCIe版本可能会包括更高的带宽、更低的延迟、改进的电源管理以及更好地集成到网络和存储解决方案中。此外,随着数据中心对绿色计算的重视,更高效的能耗比也将成为设计的重要考虑因素。
### 5.1.2 对比竞争技术的优劣势分析
在与其它高速数据传输技术的比较中,PCIe需要确保其独特的优势。例如,与Thunderbolt技术相比,PCIe具有更低的硬件成本和更广泛的生态系统支持,但Thunderbolt提供了更简单的即插即用特性。对比InfiniBand和Ethernet,PCIe的竞争焦点在于实现与网络技术相似的高速度和低延迟,同时保持更低的总体成本。
## 5.2 DMA技术的未来发展方向
DMA技术作为减少CPU负担、提高数据传输效率的关键技术,其发展趋势同样值得关注。
### 5.2.1 新一代DMA技术的特点
新一代DMA技术有望将包括改进的内存管理策略、更高的传输速率以及对安全性的增强考虑。为了提升传输效率,可能会采用更智能化的数据流控制和管理算法。安全性方面的增强可能包括硬件级别的安全特性,例如与IOMMU更紧密的集成,以及加密和验证机制来防止DMA攻击。
### 5.2.2 DMA技术在AI和大数据中的应用展望
随着人工智能和大数据应用的增加,DMA技术在这些领域中扮演着越来越重要的角色。为适应这些应用,DMA技术可能需要进一步优化以处理大块数据和复杂的数据结构。此外,对实时数据处理的需求也需要DMA技术提供更加快速和灵活的数据传输方案,以便于数据能够更高效地在系统各个部分之间移动。
随着IT行业持续发展,对PCIe和DMA技术的需求也在不断变化。这些技术的未来将由新的应用需求和不断演进的技术标准共同塑造。随着创新的不断推进,我们可以预期PCIe和DMA将继续提供高性能的数据传输和处理能力,成为未来计算机架构的核心组成部分。
# 6. 深入PCIe v4.1 DMA操作的高级话题
PCIe v4.1作为当前数据传输领域的一个重要标准,其DMA(直接内存访问)操作的深入应用不仅依赖于硬件层面的支持,更需要软件层面的优化。本章节将探讨一些高级话题,如虚拟化支持、跨平台兼容性问题,以及在现代网络化和分布式系统中PCIe DMA的应用。
## 6.1 PCIe v4.1 DMA的虚拟化支持
### 6.1.1 虚拟化环境下DMA的挑战和解决方案
虚拟化技术的广泛应用带来了对硬件资源的高效利用,然而它也引入了新的挑战,尤其是在DMA操作方面。在虚拟化环境中,多个虚拟机(VMs)共享物理硬件,这可能导致资源竞争、数据隔离和安全性问题。
一个常见的挑战是,虚拟机可能无法直接访问物理硬件的DMA资源,因为传统的DMA机制并没有设计来支持虚拟化的环境。为了解决这个问题,出现了几种技术:
- **I/O虚拟化技术**,如Intel VT-d(Virtualization Technology for Directed I/O),它能够为虚拟机提供独立的DMA资源。
- **设备分配机制**,允许虚拟化管理层(如Hypervisor)管理设备的DMA访问权限,从而保证了数据隔离和安全性。
### 6.1.2 典型虚拟化技术中的PCIe DMA实现
在主流虚拟化技术中,如KVM(Kernel-based Virtual Machine)和Xen中,PCIe DMA的实现需要对这些虚拟化平台提供的I/O虚拟化支持进行集成。
- **KVM中的PCIe设备直通(Passthrough)技术**:允许直接将PCIe设备分配给虚拟机,从而绕过宿主机操作系统。这样虚拟机可以像在物理环境中一样使用DMA进行数据传输。
- **Xen中的准虚拟化驱动(PV驱动)**:通过软件模拟DMA操作,允许虚拟机通过轻量级的接口与物理硬件通信,同时不失去虚拟化环境的优势。
## 6.2 跨平台PCIe DMA操作的兼容性问题
### 6.2.1 不同操作系统中的DMA实现差异
DMA操作的实现与操作系统的硬件抽象层(HAL)紧密相关。在不同的操作系统中,如Windows、Linux或macOS,DMA的实现细节可能有很大差异。这些差异可能来源于:
- **驱动程序模型**:例如,Linux使用设备树(Device Tree)来描述硬件,而Windows使用硬件抽象层(HAL)。
- **内存管理**:内存的分配和回收机制在不同操作系统间不同,这直接影响DMA缓冲区的管理。
### 6.2.2 跨平台DMA操作的兼容性解决策略
为了确保跨平台的兼容性,开发者需要:
- **采用标准化的硬件抽象层(HAL)**,如PCI SIG提供的HAL,它为不同操作系统间的硬件访问提供了一个通用的接口。
- **编写与平台无关的驱动程序代码**,尽量使用操作系统提供的标准API进行硬件访问,避免使用平台特定的函数或调用。
- **利用现有的跨平台开发工具和库**,这些工具和库通常提供了一套API封装,用于抽象底层平台的差异。
## 6.3 网络化与分布式系统中的PCIe DMA应用
### 6.3.1 在分布式系统中实现PCIe DMA
在分布式系统中,PCIe DMA可以被用于实现高性能的数据共享和通信。通过RDMA(Remote Direct Memory Access)技术,节点间可以直接对对方的内存进行读写操作,而无需CPU的介入,从而大大降低了通信的延迟和开销。
实现步骤包括:
- **配置RDMA网络设备**:确保所有网络节点上的RDMA设备都正确配置,以支持远程直接内存访问。
- **映射远程内存区域**:在本地节点上,将远程节点的内存映射到本地地址空间,使得可以像访问本地内存一样访问远程内存。
### 6.3.2 PCIe DMA在远程直接数据存取(RDMA)中的应用
RDMA是现代数据中心和高性能计算中不可或缺的一部分,它让数据能够在不同的物理位置之间直接传输,而不必经过操作系统的内核。
- **RDMA的关键优势**:与传统网络通信相比,RDMA可以减少大量的数据复制操作,显著提高了数据传输效率。
- **RDMA在现代应用中的角色**:例如,在大数据处理、云计算和AI训练任务中,RDMA可以提供更低延迟的数据访问,有助于提升整体系统的性能。
通过以上高级话题的探讨,我们可以看到PCIe v4.1 DMA操作在现代技术应用中扮演着重要的角色。无论是虚拟化环境、跨平台兼容性,还是网络化系统中,理解并掌握这些高级话题对于提升系统性能和效率都是至关重要的。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探讨了 PCI Express (PCIe) v4.1 中的 DMA/Bridge 子系统,涵盖了从基础知识到高级应用的广泛主题。它提供了对 PCIe v4.1 协议、DMA 操作、Bridge 子系统、DMA 优化策略和 XDMA 设计模式的全面理解。专栏还包括案例分析、技术突破、性能优化技巧、兼容性问题排查、大规模系统部署策略和 PCIe v4.1 DMA/Bridge 系统设计要点。通过深入的分析和实际示例,该专栏为工程师和开发人员提供了掌握 PCIe v4.1 DMA/Bridge 子系统所需的关键知识和技能,从而实现技术飞跃并提升数据传输效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Chem3D视觉艺术】:氢原子在分子模型中脱颖而出的秘诀

# 摘要
本论文探讨了氢原子在分子模型中的关键角色,以及如何通过化学绘图与视觉艺术将其实现更有效的可视化。从氢原子的化学特性到3D分子模型中的视觉表现,本文深入分析了氢原子在化学反应和生物大分子中的作用,并提供了使用Chem3D软件创建和优化氢原子模型的详细指南。此外,论文
动态面板性能优化攻略:5个步骤,打造极致流畅交互体验
# 摘要
本文全面探讨了动态面板性能优化的策略和方法。首先,介绍了性能基准测试的重要性和分析流程,阐述了如何选择合适的测试工具,进行性能瓶颈的识别与诊断。其次,针对前端性能,详细讨论了减少HTTP请求、资源优化、缓存策略、代码优化等技术的应用。在动态面板渲染优化方面,强调了渲染机制对性能的影响,并提出了提升渲染性能的技术手段,如DOM操作优化和动画效果的改进。进一步,文章分析了后端服务和数据库性能优化
数字通信原理深度剖析:Proakis第五版,理论与实践的融合之道
# 摘要
本文综合分析了数字通信系统的基础理论、传输技术、差错控制编码以及实际设计与实现。首先概述了数字通信系统的基本概念,接着深入探讨了数字信号的表示、分类及其调制解调技术。文章还涉及了差错控制编码与信号检测的基本原理,并通过信息论基础和熵的
天线理论进阶宝典:第二版第一章习题全面解读

# 摘要
本文全面探讨了天线理论的基础知识、设计、计算、测试、优化以及实践应用。首先概述了天线理论的基本概念和原理,然后详细介绍了不同类型的天线(线性、面、阵列)及其特点,包括各自的辐射特性和参数。接着,本文阐述了天线设计的原理和方法,计算工具的应用,以及设计案例和实践技巧。在此基础上,文章深入讨论了天线性能测试和优化的方法和软件应用。最后,本文预测了天线理论的未来发展,分析
零基础学习Flac3D:构建流体计算环境的终极指南
# 摘要
本文全面介绍了Flac3D在地质工程领域的应用,涵盖了从基础入门到高级应用的各个方面。首先,本文为读者提供了Flac3D的入门基础知识,然后详细阐述了网格划分的技巧及其在确保计算精度方面的重要性。之后,转向流体计算理论,深入探讨了流体动力学基础、模型选择与应用以及数值方法。通过案例分析,展示了如何在实际操作中构建、执行、监控及分析流体模型。文章还探讨了高级应用,例如多相流与流固耦合计算,以及流体计算的参数敏
【解锁Quartus II 9.0编译秘籍】:5大技巧优化编译效率
# 摘要
Quartus II 9.0是一款广泛使用的FPGA设计软件,它提供了一套完整的编译流程,从设计输入到最终生成用于编程FPGA的文
【构建高效网格图】:网格计算入门与实战演练

# 摘要
网格计算作为一种集成、共享和协调使用地理上分布的计算资源的先进计算模式,已在多个领域展示了其强大的计算能力与资源优化潜力。本文首先从网格计算的概念和架构入手,概述了其理论基础和关键技术,包括资源管理、数据传输及安全隐私保护等方面。接着,文章转入实践技巧的讨论,详细介绍了如何搭建网格计算环境、开发计算任务以及性能监控。通过实际案例分析,本文展示了网格计算在实践中的应用,并提供了一个实战演练示例,从需求到部署的全
【MySQL复制机制】:主从同步原理与实践精讲

# 摘要
MySQL复制技术是数据库管理中的核心组成部分,它通过二进制日志记录主服务器上的数据变更,并将这些变更同步到一个或多个从服务器,从而实现数据的备份、负载均衡和高可用性。本文详细介绍了MySQL复制的理论基础,包括复制原理、关键技术如SQL线程与IO线程的工作机制,以及数据一致性保证机制。同时,实践操作指南部分提供了详细配置步骤和故障排查方法,而高级复制技术与场景应用章节则探讨了链式复制、级联复制、G
【Qt信号与槽实战】:曲线图交互的秘诀
# 摘要
本文系统地探讨了Qt框架中信号与槽机制的基础知识、在曲线图控件中的应用,以及交互实操和高级应用。首先介绍了信号与槽的工作原理和自定义信号槽函数的重要性。接着,通过曲线图控件的案例,展示了预定义信号介绍、用户交互响应实现及高级特性的应用。第三章深入曲线图交互实战,包括基本操作、信号与槽的实现以及动态效果的增强。第四章对信号与槽的深入理解和高级应用进行了讨论,涵盖了自定义对象的连接和多线程环境下的安全使用。最后一章通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )