TypeScript中的模块化编程
发布时间: 2023-12-20 03:54:35 阅读量: 37 订阅数: 41 

TypeScript 模块
# 1. 理解模块化编程
## 1.1 什么是模块化编程?
模块化编程是一种将软件系统分解为独立功能模块的编程方法。每个模块都有明确的目标和职责,可以独立开发、测试、维护和扩展。模块之间通过定义的接口进行交互,实现了高内聚低耦合的设计原则。
## 1.2 模块化编程的优势
模块化编程带来了许多优势:
- **可维护性**:模块化的代码结构使得代码更易于理解和维护,可以快速定位和修复问题。
- **复用性**:模块化的设计可以提高代码的复用性,避免重复编写相同的逻辑。
- **可扩展性**:通过增加、替换、组合模块,可以方便地扩展系统功能。
- **团队协作**:模块化的代码结构使得多人协作更加高效和有序。
## 1.3 TypeScript对模块化的支持
TypeScript提供了完整的模块化系统,兼容ES6的模块语法。它支持通过`import`和`export`关键字来定义模块的导入和导出,以及命名导出和默认导出的功能。
使用TypeScript进行模块化编程可以带来许多好处,如代码的类型检查、模块的封装与暴露、模块依赖管理等。接下来的章节将介绍如何在TypeScript中使用模块化编程来构建可维护、可复用的代码。
# 2. TypeScript中的模块系统
在TypeScript中,模块是用于组织和管理代码的重要概念。模块可以将相关的功能封装起来,提供复用和维护性,使代码结构更加清晰和可维护。本章将介绍TypeScript中的模块系统以及如何使用它来组织和管理代码。
### 2.1 模块的概念
模块是一种逻辑上独立且可复用的代码块。它可以包含变量、函数、类等,并且可以通过导出和引入来在不同的模块之间进行交互。
在TypeScript中,我们可以使用`export`关键字将模块中的内容导出,在其他模块中使用`import`关键字引入模块中的内容。
### 2.2 导出和引入模块
在一个模块中,我们可以通过`export`关键字将模块中的内容导出,使其可以在其他模块中被引入和使用。有两种方式可以导出模块中的内容:默认导出和命名导出。
**默认导出**
在一个模块中,可以使用`export default`语法来默认导出一个值。默认导出的值可以是任意类型,包括变量、函数、类等。
下面是一个示例代码:
```typescript
// greeter.ts
export default function sayHello(name: string) {
console.log(`Hello, ${name}!`)
}
// main.ts
import sayHello from './greeter'
sayHello('Alice'); // 输出:Hello, Alice!
```
在上面的代码中,`sayHello`函数被默认导出,可以在其他模块中用`import`语法直接引入并使用。
**命名导出**
在一个模块中,可以使用`export`关键字将模块中的内容命名导出,使其可以在其他模块中被引入。命名导出可以是变量、函数、类等。我们可以使用`export`关键字在定义的同时进行命名导出,也可以将导出放在模块的最后,通过`export { ... }`方式进行导出。
下面是一个示例代码:
```typescript
// math.ts
export const PI = 3.14;
export function add(a: number, b: number) {
return a + b;
}
// main.ts
import { PI, add } from './math';
console.log(PI); // 输出:3.14
console.log(add(2, 3)); // 输出:5
```
在上面的代码中,`math`模块通过命名导出导出了`PI`常量和`add`函数,我们可以通过`import`语法引入具名导出的内容,并在使用时指明具体的名称。
### 2.3 默认导出和命名导出的区别
在使用导入和导出模块的时候,需要注意默认导出和命名导出之间的区别。
- 默认导出可以导出任意类型的值,而命名导出只能导出变量、函数和类等命名实体。
- 引入默认导出时可以使用任意变量名,而引入命名导出时需要使用具体导出的名字。
- 模块中可以同时使用默认导出和命名导出,但默认导出只能有一个。
### 总结
本章介绍了TypeScript中的模块系统。模块是用于组织和管理代码的重要概念,可以将相关的功能封装起来,提供复用和维护性。我们可以使用`export`关键字将模块中的内容导出,并使用`import`关键字引入模块中的内容。在使用导入和导出模块的时候要注意默认导出和命名导出的区别。
下一章将介绍如何创建可复用的模块。
# 3. 构建可复用的模块
在 TypeScript 中,我们可以通过模块化的方式来构建可复用的代码块,使得代码更加清晰、可维护性更高。本章将介绍如何创建可复用的模块,并讨论模块的封装与暴露,以及设计可靠的模块接口。
### 3.1 创建可复用的模块
要创建一个可复用的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了TypeScript语言的各个方面,为读者提供全面而系统的学习经验。从TypeScript的基础入门开始,逐步学习数据类型、函数与箭头函数、接口和类、模块化编程等核心概念。专栏还介绍了如何使用泛型提升代码复用性,并深入解析了装饰器的使用。此外,还探讨了TypeScript中的异步编程、模块解析与规范、枚举类型、RESTful API构建以及类型推断机制等内容。此外,读者还将了解到高级类型、可测试代码编写、函数重载、错误处理、抽象类等高级特性的应用。专栏最后介绍了如何使用TypeScript开发React应用,并探讨了类型别名和字符串字面量类型的使用。通过本专栏的学习,读者将能够熟练运用TypeScript的各种特性进行开发,并提升代码的可维护性和可扩展性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Silvaco仿真全攻略:揭秘最新性能测试、故障诊断与优化秘籍(专家级操作手册)

# 摘要
本文全面介绍并分析了Silvaco仿真技术的应用和优化策略。首先,概述了Silvaco仿真技术的基本概念和性能测试的理论基础。随后,详细阐述了性能测试的目的、关键指标以及实践操作,包括测试环境搭建、案例分析和数据处理。此外,本文还深入探讨了Silvaco仿真中的故障诊断理论和高级技巧,以及通过案例研究提供的故障处理经验。最后,本文论述了仿
MODTRAN模拟过程优化:8个提升效率的实用技巧

# 摘要
本文详细探讨了MODTRAN模拟工具的使用和优化,从模拟过程的概览到理论基础,再到实际应用中的效率提升技巧。首先,概述了MODTRAN的模拟过程,并对其理论基础进行了介绍,然后,着重分析了如何通过参数优化、数据预处理和分析以及结果验证等技巧来提升模拟效率。其次,本文深入讨论了自动化和批处理技术在MODTRAN模拟中的应用,包括编写自
【故障快速修复】:富士施乐DocuCentre SC2022常见问题解决手册(保障办公流程顺畅)
# 摘要
本文旨在提供富士施乐DocuCentre SC2022的全面故障排除指南,从基本介绍到故障概述,涵盖故障诊断与快速定位、硬件故障修复、软件故障及网络问题处理,以及提高办公效率的高级技巧和预防措施。文章详细介绍常见的打印机故障分类及其特征,提供详尽的诊断流程和快速定位技术,包括硬件状态的解读与软件更新的检查。此外,文中也探讨了硬件升级、维护计划,以及软件故障排查和网络故障的解决方法,并最终给出提高工作效率和预防故障的策略。通过对操作人员的教育和培训,以及故障应对演练的建议,本文帮助用户构建一套完整的预防性维护体系,旨在提升办公效率并延长设备使用寿命。
# 关键字
富士施乐DocuCe
【Python环境一致性宝典】:降级与回滚的高效策略

# 摘要
本文重点探讨了Python环境一致性的重要性及其确保方法。文中详细介绍了Python版本管理的基础知识,包括版本管理工具的比较、虚拟环境的创建与使用,以及环境配置文件与依赖锁定的实践。接着,文章深入分析了Python环境降级的策略,涉及版本回滚、代码兼容性检查与修复,以及自动化降级脚本的编写和部署。此外,还提供了Pyt
打造J1939网络仿真环境:CANoe工具链的深入应用与技巧

# 摘要
J1939协议作为商用车辆的通信标准,对于车载网络系统的开发和维护至关重要。本文首先概述了J1939协议的基本原理和结构,然后详细介绍CANoe工具在J1939网络仿真和数据分析中的应用,包括界面功能、网络配置、消息操作以及脚本编程技巧。接着,本文讲述了如何构建J1939网络仿真环境,包括
数字电路新手入门:JK触发器工作原理及Multisim仿真操作(详细指南)
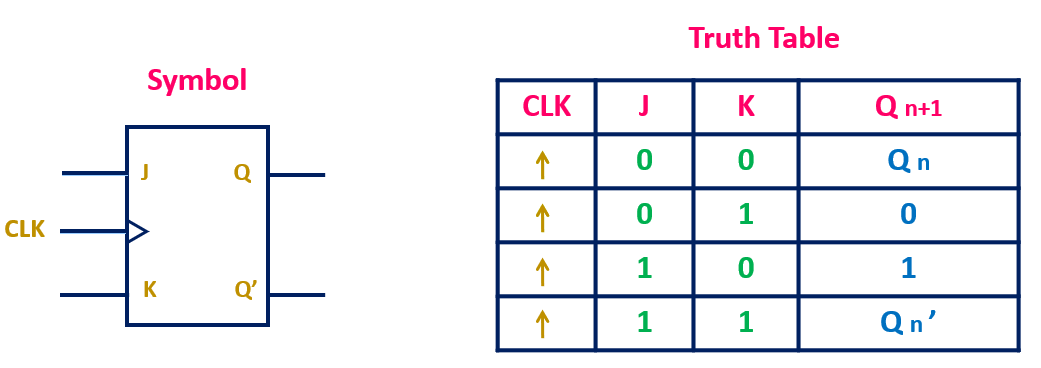
# 摘要
本文深入探讨了数字电路中的JK触发器,从基础知识到高级应用,包括其工作原理、特性、以及在数字系统设计中的应用。首先,本文介绍了触发器的分类和JK触发器的基本工作原理及其内部逻辑。接着,详细阐述了Multisim仿真软件的界面和操作环境,并通过仿真实践,展示如何在Multisim中构建和测试JK触发器电路。进一步地,本文分析了JK触发
物联网新星:BES2300-L在智能连接中的应用实战
# 摘要
本文系统分析了物联网智能连接的现状与前景,重点介绍了BES2300-L芯片的核心技术和应用案例。通过探讨BES2300-L的硬件架构、软件开发环境以及功耗管理策略,本文揭示了该芯片在智能设备中的关键作用。同时,文章详细阐述了BES2300-L在智能家居、工业监控和可穿戴设备中的应用实践,指出了开发过程中的实用技巧及性能优
C++11新特性解读:实战演练与代码示例
# 摘要
C++11标准在原有的基础上引入了许多新特性和改进,极大地增强了语言的功能和表达能力。本文首先概述了C++11的新特性,并详细讨论了新数据类型和字面量的引入,包括nullptr的使用、auto关键字的类型推导以及用户定义字面量等。接着,文章介绍了现代库特性的增强,例如智能指针的改进、线程库的引入以及正则表达式库的增强。函数式编程特性,如Lambda表达式、std::function和std::b
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )