




【基础】python使用scapy进行网络抓包
发布时间: 2024-06-28 01:29:11 阅读量: 239 订阅数: 123 
1. Scapy简介及安装
Scapy是一个强大的Python网络分析和操作工具包,它允许用户在网络层级上捕获、解析、修改和注入数据包。Scapy以其灵活性和可扩展性而闻名,使其成为网络安全专业人员、网络工程师和研究人员的理想选择。
安装Scapy
在大多数Linux发行版上,可以通过以下命令安装Scapy:
- sudo apt-get install scapy
对于Windows用户,可以通过以下步骤安装Scapy:
- 从官方网站下载Scapy安装程序。
- 运行安装程序并按照提示进行操作。
- 将Scapy添加到系统路径中(例如,在命令提示符中运行
set path=%path%;C:\Program Files\Scapy)。
2. Scapy抓包基础
2.1 Scapy基本语法和API
Scapy是一个基于Python的网络数据包处理库,它提供了一组强大的API,用于创建、解析和操作网络数据包。Scapy的基本语法与Python类似,它使用对象表示网络数据包,并提供了一系列函数和方法来操作这些对象。
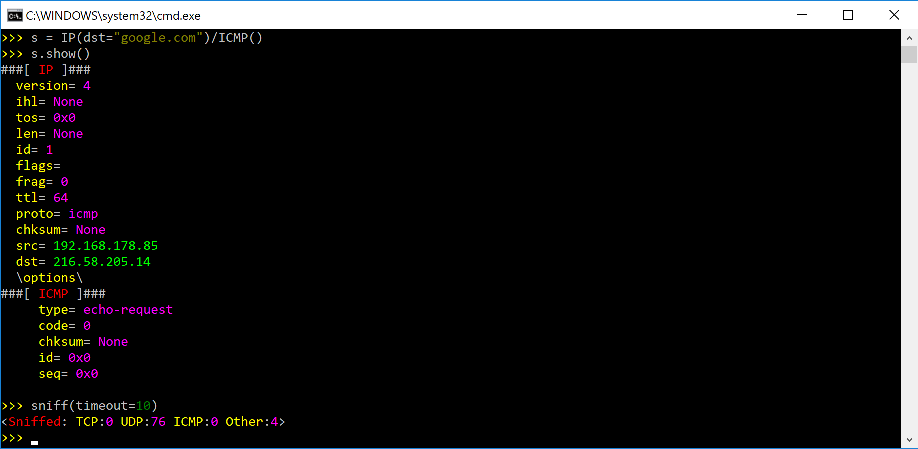
- >>> from scapy.all import *
- >>> packet = Ether()/IP()/TCP() # 创建一个简单的TCP数据包
- >>> packet.show() # 显示数据包的详细信息
Scapy还提供了一系列API,用于解析和操作网络数据包。这些API包括:
ls():列出数据包中可用的层getlayer():获取指定层的对象setlayer():设置指定层的对象dellayer():删除指定层payload():获取数据包的有效载荷
2.2 抓包过滤器
Scapy提供了强大的抓包过滤器,允许用户根据各种条件过滤网络流量。过滤器语法基于Berkeley Packet Filter (BPF),它使用布尔表达式来指定过滤条件。
- >>> sniff(filter="tcp and dst port 80") # 过滤TCP流量,目的端口为80
- >>> sniff(filter="arp and src host 192.168.1.1") # 过滤ARP流量,源主机为192.168.1.1
Scapy还支持更高级的过滤器,例如:
haslayer():检查数据包是否包含指定层load():检查数据包有效载荷是否包含指定字符串len():检查数据包长度是否满足指定条件
2.3 抓包数据的解析和处理
Scapy提供了各种方法来解析和处理抓包数据。这些方法包括:
summary():显示数据包的简要摘要hexdump():显示数据包的十六进制转储fields():显示数据包中所有字段的列表getfieldval():获取指定字段的值setfieldval():设置指定字段的值
- >>> packet = sniff()[0] # 捕获第一个数据包
- >>> packet.summary() # 显示数据包摘要
- >>> packet.hexdump() # 显示数据包十六进制转储
- >>> packet.fields() # 显示数据包字段列表
- >>> packet.getfieldval("IP.src") # 获取源IP地址
通过使用Scapy的API和过滤器,用户可以轻松地抓取、解析和处理网络流量,从而进行各种网络分析和安全任务。
3.1 流量重放和篡改
流量重放
流量重放是指将捕获的流量重新发送到网络中,以模拟特定事件或测试网络设备的响应。Scapy提供了sendp()函数来实现流量重放,其语法如下:
- def sendp(p, iface=None, count=1, inter=0, verbose=None, realtime=F

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了网络安全和信息安全领域的综合知识,为初学者和从业者提供全面的指南。从网络安全和信息安全的基本概念和原则入手,专栏深入探讨了常见的安全威胁和攻击类型。此外,专栏还涵盖了 Python 编程的基础知识,包括语法、数据类型和控制结构,以及 Python 标准库和开发工具的介绍。专栏还深入探讨了 Python 中的加密库 PyCryptodome,并介绍了安全编码的基本原则。通过本专栏,读者可以获得网络安全和信息安全领域的扎实基础,并掌握 Python 编程的技能,以应对当今的网络安全挑战。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【H3C S5130S-EI 网络功能揭秘】:掌握VLAN与ACL的高级应用
# 摘要
本文首先概述了H3C S5130S-EI交换机的基本功能和特点,随后深入探讨了VLAN和ACL的核心原理及其在网络管理中的配置和应用。通过详细解释VLAN的定义、类型、配置方法和故障排查技巧,以及ACL的工作原理、配置实例和在网络安全中的应用,本文提供了理论和实践
安全信息和事件管理(SIEM):精通集中管理安全事件的艺术
# 摘要
随着信息技术的不断进步,安全信息和事件管理(SIEM)系统已成为维护网络安全的重要工具。本文系统地解读了SIEM的基本概念、系统组成及工作原理,包括其核心的架构概览、数据流处理流程,以及关键技术如用户和实体行为分析(UEBA)和机器学习的应用。文章进一步探讨了SIEM系统的
IAR嵌入式环境搭建全攻略:新手入门到高手进阶
# 摘要
本文详细介绍了IAR嵌入式开发环境的基础知识、安装配置、编程实践、高级功能应用及项目案例分析。首先概述了IAR环境的特性及重要性,随后深入讲解了软件的下载安装步骤、环境变量配置、项目创建与设置。接着,通过实例阐述了嵌入式编程实践,包括代码编写、编译、调试、性能分析和优化技巧。文章还探讨了IAR环境的高级功能,如硬件接口调试、中断管理、RTOS集成、多核与多任务开发。最后,通过案例分析,展示了实际项目中IAR环境的搭建、代码优化、调试、发布及维护过程。本文旨在为嵌入式开发人员提供全面的IAR开发指南,提升开发效率和产品质量。
# 关键字
IAR嵌入式开发;环境安装配置;代码编写编译;
三晶SAJ变频器能效管理手册:实施8项节能减排策略
# 摘要
本文综合介绍了三晶SAJ变频器的概述、节能减排的理论基础,以及其在节能管理中的应用实例。通过分析能效管理的重要性、变频器的工作原理以及能效管理策略,文章展示了如何通过三晶SAJ变频器实现节能减排目标。同时,本文详细阐述了实施节能减排策略的具体步骤与方法,包括建立评估与监测系统、优化操作流程以及定期维护与升级等措施。通过多个应用实例,本文证明了三晶SAJ变频器在不同领域的节能潜力,并对未来智能制造和可持续发展的技术挑战进行了展望。
# 关键字
三晶SAJ变频器;节能减排;能效管理;智能制造;零碳排放;技术挑战
参考资源链接:[三晶SAJ变频器A-8000操作与储存指南](https
NI分布式系统管理器升级全攻略:一步到位gicv3_software_overview_official_release_b实践详解
# 摘要
本文详细介绍了NI分布式系统管理器的最新升级版本gicv3_software_overview_official_release_b的全貌。文章从升级概述开始,进一步探讨了升级包的新特性、兼容性变更及升级前的准备工作,为读者提
【Vivado深度剖析】:掌握Xilinx Vivado特性的5大优势与10个关键应用案例
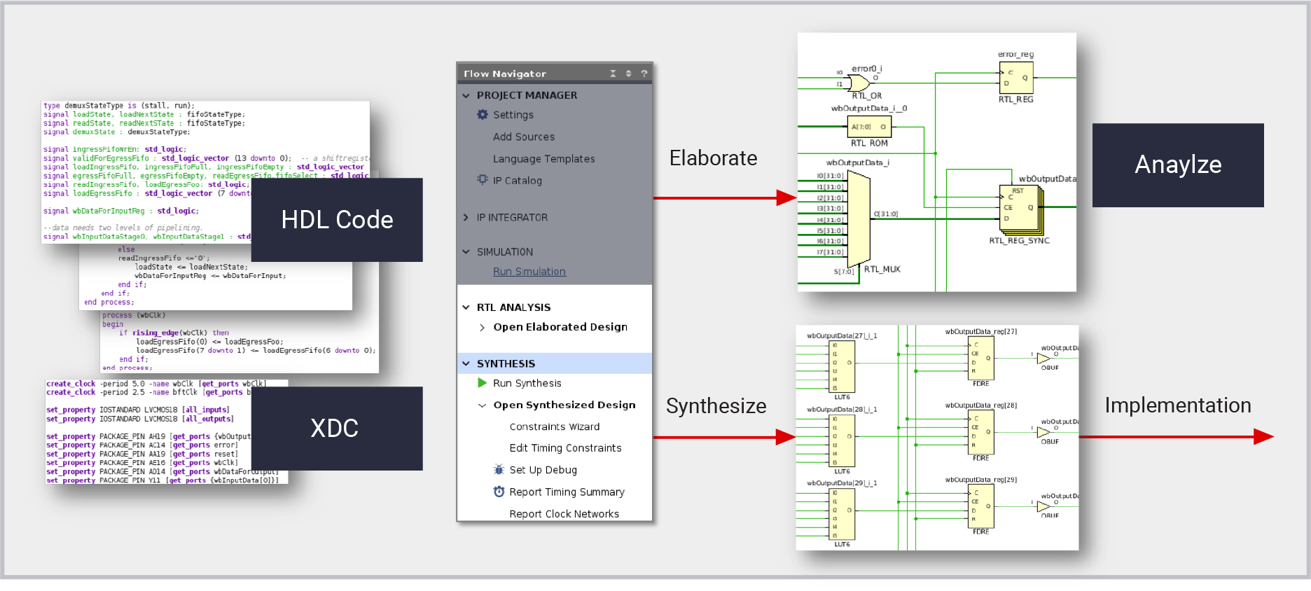
# 摘要
本文综合分析了Xilinx Vivado设计套件的功能优势,特别强调了其在现代FPGA开发中的关键作用。通过与传统工具的对比,探讨了Vivado在设计流程、性能和生产力方面的创新。此外,本文详细讨论了Vivado在IP集成与复用、实时性能优化等方面的高级特性,并提供了关键应用案例分析,展示了Vivado如何在高速数
C#与WMI终极指南:硬件信息采集技术的集大成者
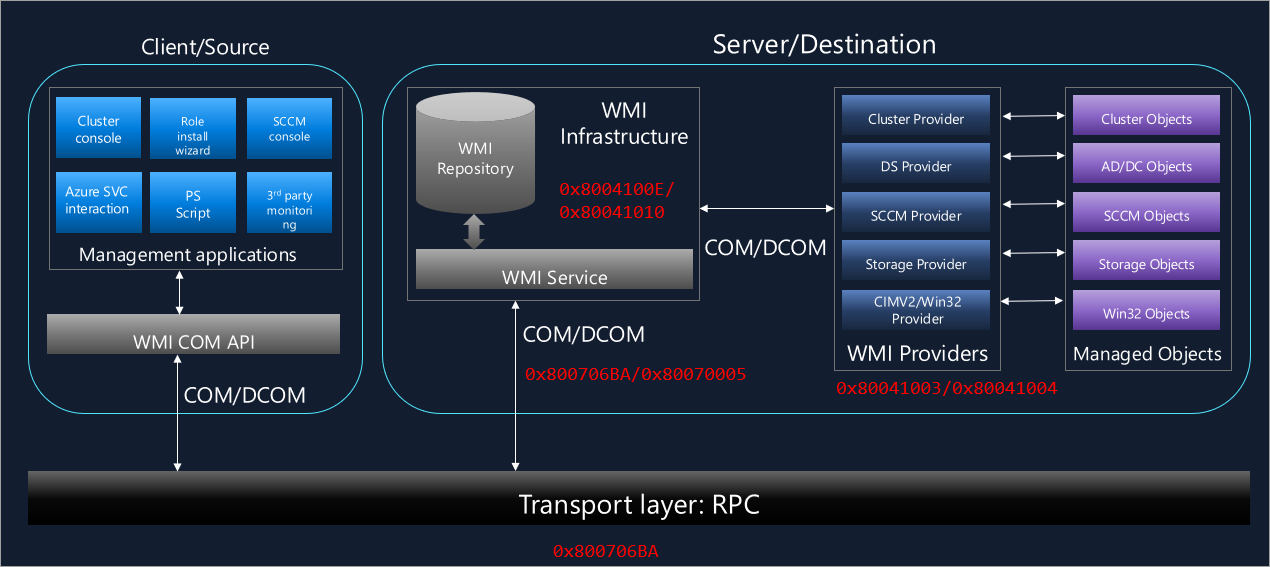
# 摘要
随着计算机技术的快速发展,C#编程语言与Windows管理规范(WMI)的集成成为了系统管理和监控的一个重要领域。本文首先概述了C#与WMI的基础知识,然后深入探讨了WMI的架构和对象模型,包括其组成、命名空间、
【和利时LE系列PLC硬件秘籍】:全面解读硬件架构、故障诊断与维护技巧
# 摘要
本文全面介绍LE系列PLC的硬件组成、架构细节、故障诊断技术、维护与优化策略以及高级应用与实践。首先,概述了PLC硬件的各个核心组件,并详细解析了CPU模块性能特点和I/O模块的多样性。接着,深入探讨了PLC的通讯机制和扩展能力,以及硬件架构的未来发展趋势。故障诊断章节涵盖了常见故障类型、诊断工具使用以及案例分析。在维护与优化策略方面,文中提出了日常保养、故障预防以及性能提升的方法。最后,展示了PLC在高级编程、系统集成和自动化解决方案中的应用,以及创新应用实例和行业发展趋势预测。
# 关键字
PLC硬件;架构解析;故障诊断;维护优化;系统集成;自动化应用
参考资源链接:[和利时
【打包工具原理深度解码】:工程打包机制全解析
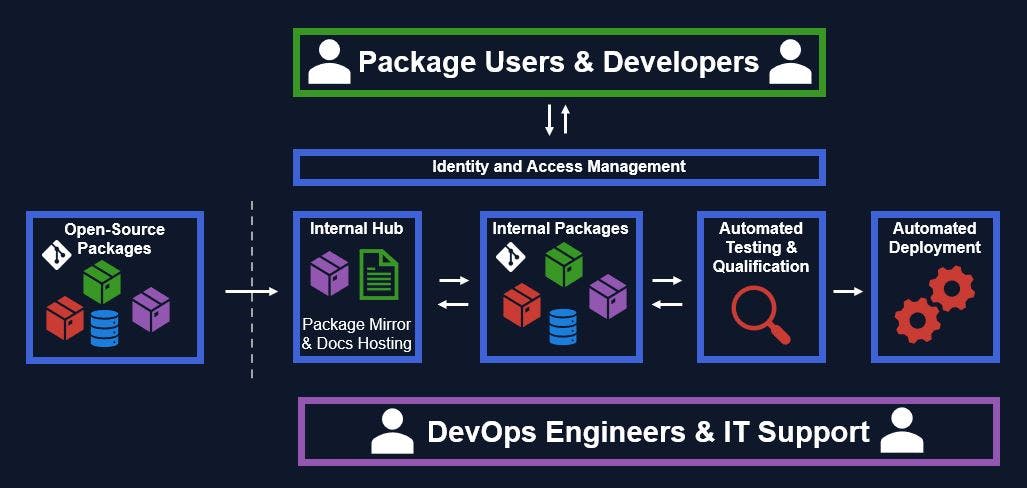
# 摘要
工程打包机制是软件开发和分发过程中的关键步骤,它将各种资源和代码打包成单一的可执行文件,优化了应用的部署与维护。本文从基础理论入手,详细介绍了打包工具的工作原理、文件格式解析以及性能优化。通过探讨常用打包工具的实践应用、问题解决和自定义扩展,文章深入分
【PLC编程案例解析】:从新手到专家的地址寄存器高级应用研究
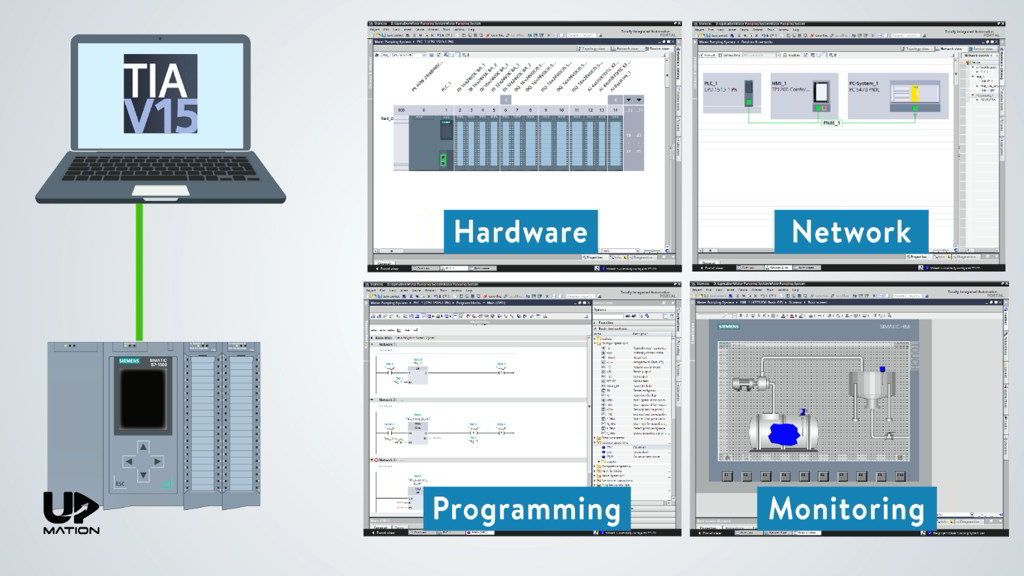
# 摘要
PLC(可编程逻辑控制器)编程中,地址寄存器是实现逻辑控制、数据处理和系统维护的关键组件。本文首先介绍了地址寄存器的基础概念和其在逻辑控制中的应用,涵盖了寄存器的读写机制、数据类型及格式、与计数器和定时器的结合使用。随后,文章深入探讨了地址寄存器的高级编程技巧,包括间接寻址和位操作的理论与实践案例。案例分析部分强调了地址寄存器在制造业、建筑自动化和交通控制等特定行业中的应用和创新。最后,本文讨论了地址寄存器的调试、维护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















