Jetson Nano与CUDA编程:GPU加速应用开发
发布时间: 2023-12-21 09:38:33 阅读量: 152 订阅数: 48 

基于CUDA的GPU加速通用遗传算法实现c++源码+报告-实验平台为英伟达Jetson Nano.zip
# 1. Jetson Nano简介
### 1.1 Jetson Nano概述
Jetson Nano是由NVIDIA推出的一款嵌入式平台,尤其适用于AI和深度学习应用开发。它具有强大的GPU加速能力和高性能的计算能力,可以实现实时推理和图像处理等任务。Jetson Nano采用小尺寸的系统级SoC方案,集成了NVIDIA的GPU架构,可以实现低功耗和高效能的平衡。
### 1.2 Jetson Nano的硬件规格
Jetson Nano拥有强大的硬件配置,包括:
- 四核ARM Cortex-A57 CPU
- 128核NVIDIA Maxwell GPU
- 4GB LPDDR4内存
- 支持MicroSD卡存储和NVMe SSD存储
- 支持USB 3.0和USB 2.0接口
- 支持HDMI和DisplayPort显示输出
Jetson Nano的硬件规格使其能够在嵌入式系统中处理高性能计算任务,并实现实时推理和图像处理等功能。
### 1.3 Jetson Nano在AI和嵌入式系统中的应用
由于Jetson Nano具有强大的GPU加速能力和高性能的计算能力,因此它在AI和嵌入式系统中有广泛的应用场景,包括但不限于:
#### 1.3.1 深度学习应用
Jetson Nano可以使用CUDA进行GPU加速,从而加速深度学习模型的训练和推理过程。通过利用Jetson Nano的强大GPU计算能力,可以在嵌入式设备上实现高效的深度学习应用。
#### 1.3.2 图像处理和计算机视觉
Jetson Nano的GPU加速能力可以用于实时图像处理和计算机视觉任务。例如,可以利用Jetson Nano进行实时目标检测、图像分割和物体跟踪等任务,以满足在嵌入式系统中对图像处理和计算机视觉的需求。
#### 1.3.3 自动驾驶和无人机
Jetson Nano在自动驾驶和无人机领域也有广泛的应用。通过利用Jetson Nano的GPU加速能力,可以实现高效的图像识别和实时感知,从而提高自动驾驶系统和无人机的性能和安全性。
总之,Jetson Nano作为一款强大的嵌入式平台,具有广泛的应用潜力,在AI和嵌入式系统领域有着广阔的发展前景。
# 2. CUDA编程基础
### 2.1 CUDA编程模型概述
CUDA(Compute Unified Device Architecture)是一种并行计算平台和编程模型,由NVIDIA推出。它允许开发者利用GPU(图形处理器)进行高性能计算,加速各种应用程序的执行。CUDA编程模型的核心思想是将计算任务划分成多个线程,并在GPU上并行执行这些线程,从而实现加速计算。
CUDA编程模型中有两个重要的概念:主机(Host)和设备(Device)。主机是指CPU和主存,而设备指的是GPU和显存。CUDA程序由主机代码和设备代码组成,主机代码负责协调GPU上的并行计算任务,而设备代码则是实际执行计算任务的地方。
### 2.2 CUDA C/C++ 编程语言
CUDA C/C++是一种在GPU上进行并行计算的编程语言。它是基于C/C++语言的扩展,提供了一些专门用于并行计算的语法和关键字。CUDA C/C++允许开发者在现有的C/C++代码中插入GPU并行计算任务,并使用CUDA提供的API函数来管理GPU的资源、调度计算任务等。
CUDA C/C++代码的编译过程较为复杂,需要经过两次编译。首先,将CUDA代码编译成PTX(Parallel Thread Execution)中间代码,然后再由PTX编译成GPU机器码。NVIDIA提供了一套工具链来完成这个过程,包括nvcc编译器和相应的GPU驱动程序。
### 2.3 CUDA核心概念和编程范例
在CUDA编程中,有几个核心概念需要理解和掌握。
首先是网格(Grid)、线程块(Block)和线程(Thread)的概念。网格是由若干个线程块组成的,线程块是由若干个线程组成的,线程是并行计算的最小单位。开发者通过指定网格、线程块和线程的数量来达到对并行计算的精细控制。
其次是内存层次结构的理解。CUDA设备上的内存分为全局内存(Global Memory)、共享内存(Shared Memory)和本地内存(Local Memory)等几个层次。全局内存是所有线程共享的,可以在所有的线程之间进行数据传输。共享内存是线程块中的线程共享的,读写速度较快,可以用来加速计算。本地内存则是每个线程私有的,速度较慢,因此应尽量避免使用。
最后是CUDA编程的范例,下面以一个简单的向量加法的例子来说明。
```cuda
__global__ void vectorAdd(int* a, int* b, int* c, int size) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < size) {
c[index] = a[index] + b[index];
}
}
int main() {
int size = 1000;
int* a, * b, * c;
// 分配和初始化a、b、c的内存
// 在设备上分配内存
cudaMalloc((void**)&a, size * sizeof(int));
cudaMalloc((void**)&b, size * sizeof(int));
cudaMalloc((void**)&c, size * sizeof(int));
// 将a、b的数据从主机内存拷贝到设备内存
cudaMemcpy(a, host_a, size * sizeof(int), cudaMemcpyHostToDe
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
"Jetson Nano"专栏涵盖了广泛的主题,从入门指南开始一直到高级应用和案例解析。专栏的目标是帮助读者从最基础的硬件配置和操作系统安装开始,逐步掌握Jetson Nano的使用和开发技能。文章涵盖了Python基础入门、图像处理、计算机视觉、深度学习、物体检测与识别、语音识别、SLAM技术、GPU加速应用开发、容器虚拟化、容器编排与管理平台等多个方面。此外,专栏还介绍了Jetson Nano在物联网应用开发和远程监控与控制方面的应用。通过专栏,读者将了解如何使用Jetson Nano构建智能小车、实现传感器数据采集与云端连接等应用案例。无论是初学者还是有一定经验的开发者,都可以从这个专栏中找到所需要的信息和指导,助力他们在Jetson Nano平台上进行开发和创新。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【掌握电路表决逻辑】:裁判表决电路设计与分析的全攻略
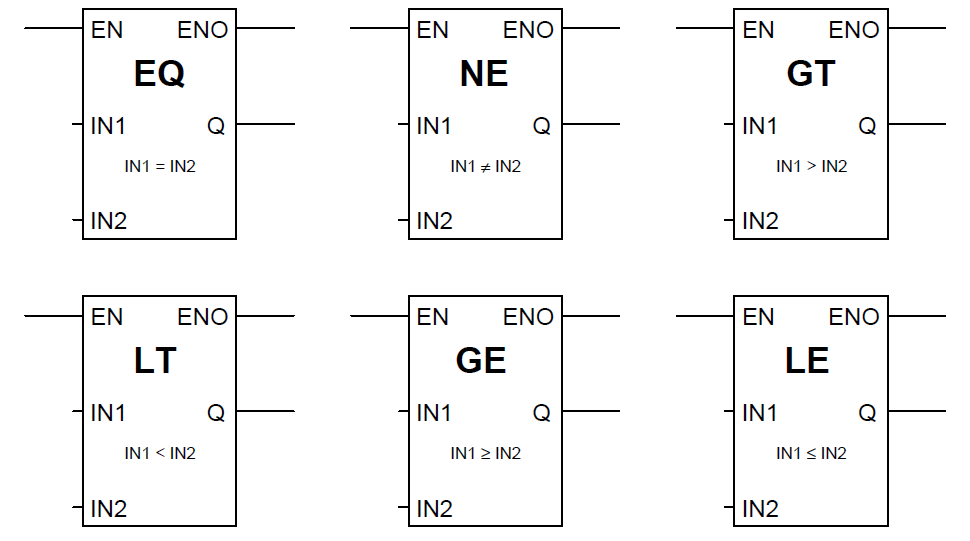
# 摘要
本文对电路表决逻辑进行了全面的概述,包括基础理论、设计实践、分析与测试以及高级应用等方面。首先介绍了表决逻辑的基本概念、逻辑门和布尔代数基础,然后详细探讨了表决电路的真值表和功能表达。在设计实践章节中,讨论了二输入和多输入表决电路的设计流程与实例,并提出了优化与改进方法。分析与测试
C# WinForm程序打包优化术:5个技巧轻松减小安装包体积
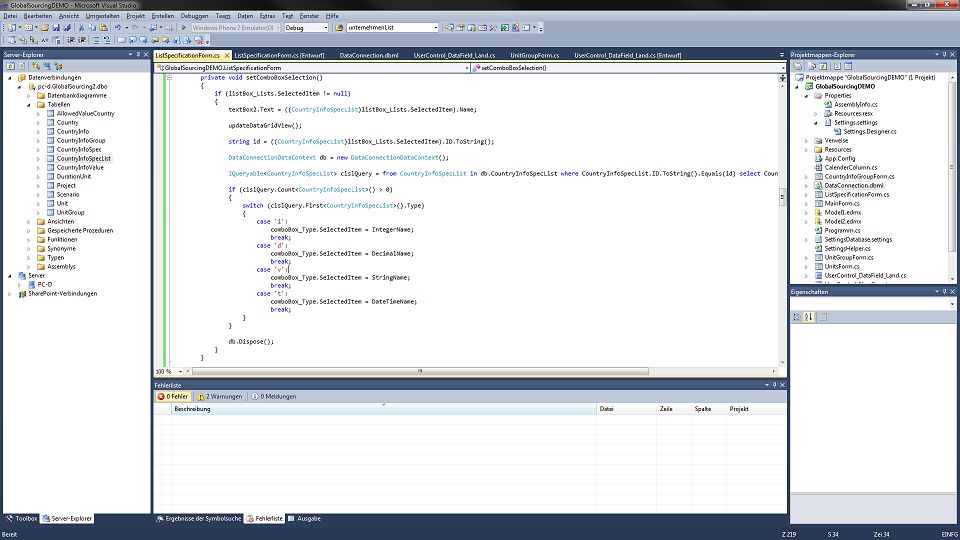
# 摘要
WinForm程序打包是软件分发的重要步骤,优化打包流程可以显著提升安装包的性能和用户体验。本文首先介绍了WinForm程序打包的基础知识,随后详细探讨了优化打包流程的策略,包括依赖项分析、程序集和资源文件的精简,以及配置优化选项。接着深入到代码级别,阐述了如何通过精简代码、优化数据处理和调整运行时环境来进一步增强应用程序。文章还提供了第三方打包工具的选择和实际案例分析,用以解决打包过程中的常见问题。最后,本
【NI_Vision调试技巧】:效率倍增的调试和优化方法,专家级指南

# 摘要
本文全面介绍了NI_Vision在视觉应用中的调试技术、实践案例和优化策略。首先阐述了NI_Vision的基础调试方法,进而深入探讨了高级调试技术,包括图像采集与处理、调试工具的使用和性能监控。通过工业视觉系统调试和视觉测量与检测应用的案例分析,展示了NI_Vision在实际问题解决中的应用。本文还详细讨论了代码、系统集成、用户界面等方面的优化方法,以及工具
深入理解Windows内存管理:第七版内存优化,打造流畅运行环境
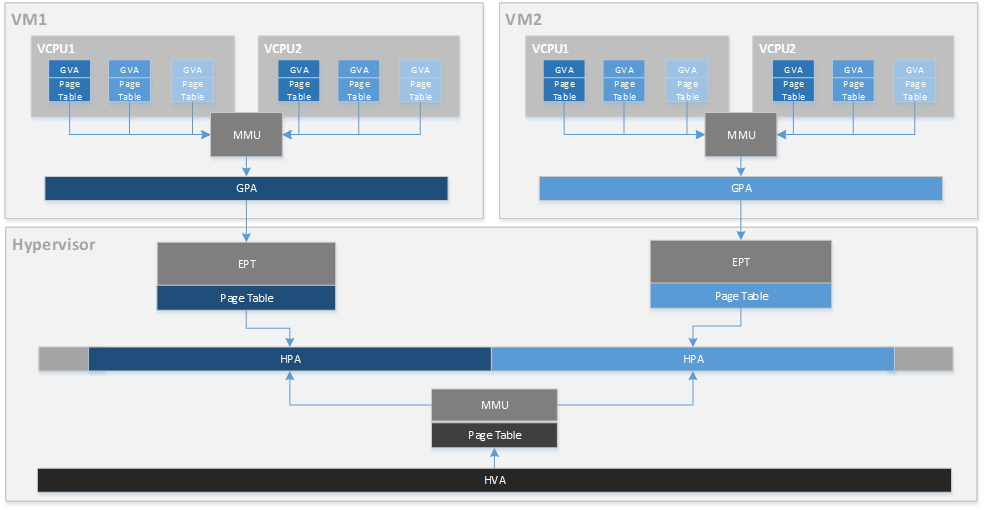
# 摘要
本文深入探讨了Windows环境下内存管理的基础知识、理论与实践操作。文章首先介绍内存管理的基本概念和理论框架,包括不同类型的内存和分页、分段机制。接着,本文详细阐述了内存的分配、回收以及虚拟内存管理的策略,重点讨论了动态内存分配算法和内存泄漏的预防。第三章详细解析了内存优化技术,包括监控与分析工具的选择应用、内存优化技巧及故障诊断与解决方法。第四章聚焦于打造高性能运行环境,分别从系统、程
专家揭秘:7个技巧让威纶通EasyBuilder Pro项目效率翻倍
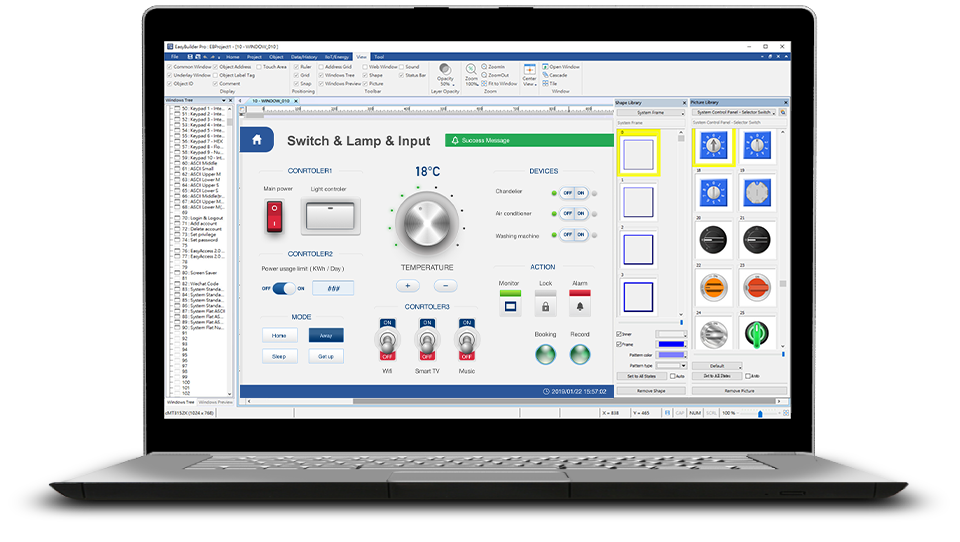
# 摘要
本论文旨在为初学者提供威纶通EasyBuilder Pro的快速入门指南,并深入探讨高效设计原则与实践,以优化用户界面的布局和提高设计的效率。同时,本文还涵盖了通过自动化脚本编写和高级技术提升工作效率的方法。项目管理章节着重于资源规划与版本控制策略,以优化项目的整体执行。最后,通过案例分析,本文提供了问题解决的实践方法和技巧,旨在帮助读者将理论知识应用于实际工作中,解决常见的开发难题,
Jetson Nano编程入门:C++和Python环境搭建,轻松开始AI开发

# 摘要
Jetson Nano作为NVIDIA推出的边缘计算开发板,以其实惠的价格和强大的性能,为AI应用开发提供了新的可能性。本文首先介绍了Jetson Nano的硬件组成、接口及配置指南,并讨论了其安全维护的最佳实践。随后,详细阐述了如何为Jetson Nano搭建C++和P
软件操作手册撰写:遵循这5大清晰易懂的编写原则

# 摘要
软件操作手册是用户了解和使用软件的重要参考文档,本文从定义和重要性开始,详细探讨了手册的受众分析、需求评估、友好的结构设计。接下来,文章指导如何编写清晰的操作步骤,使用简洁的语言,并通过示例和截图增强理解。为提升手册的质量,本文进一步讨论了实现高级功能的说明,包含错误处理、自定义设置以及技术细节。最后,探讨了格式选择、视觉布局和索引系统的设计,以及测试、反馈收集与文档持续改进的策略。本文旨在为编写高
西门子G120变频器维护秘诀:专家告诉你如何延长设备寿命

# 摘要
本文对西门子G120变频器的基础知识、日常维护实践、故障诊断技术、性能优化策略进行了系统介绍。首先,概述了变频器的工作原理及关键组件功能,然后深入探讨了变频器维护的理论基础,包括日常检查、定期维护流程以及预防性维护策略的重要性。接着,文章详述了西门子G
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )