深入剖析HDFS心跳机制:掌握数据节点健康的关键技术
发布时间: 2024-10-29 16:35:30 阅读量: 118 订阅数: 44 

Java源码ssm框架的房屋租赁系统-合同-毕业设计论文-期末大作业.rar
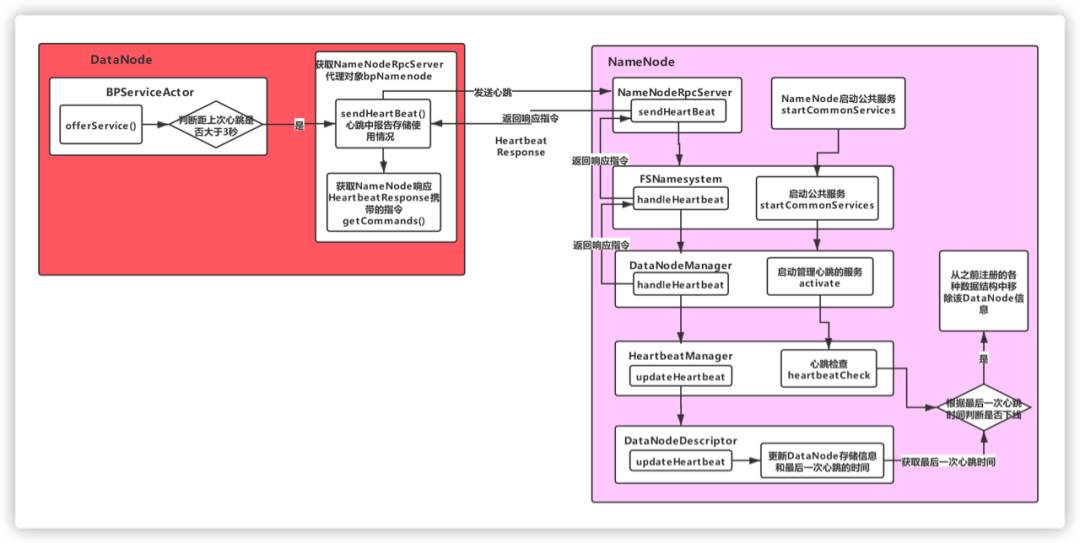
# 1. HDFS心跳机制概述
Hadoop分布式文件系统(HDFS)是大数据存储的核心技术之一,它通过高容错性保证了数据在大规模集群中的可靠性。心跳机制是HDFS中的一个重要组成部分,它对于维护集群健康状态起到了至关重要的作用。本章将简要介绍HDFS心跳机制,并为读者提供对后续章节内容的概览。心跳机制通过定期的信号传递确保NameNode能够持续监控DataNode的状态,从而及时发现并处理潜在的节点故障或网络问题。我们将详细探讨HDFS心跳机制的配置、优化以及在实际应用中的案例分析。通过本章节,读者将对HDFS心跳机制的基础概念有一个清晰的理解。
# 2. HDFS心跳机制的理论基础
## 2.1 HDFS的架构与组件
### 2.1.1 NameNode与DataNode的角色
在Hadoop分布式文件系统(HDFS)中,NameNode和DataNode是两个主要的组件,它们的角色和职责为整个系统的稳定运行提供了基础保障。
- **NameNode:** 在HDFS架构中,NameNode扮演着主控制器的角色。它负责管理文件系统的命名空间,记录每个文件中各个块所在的DataNode节点,以及控制客户端对文件的访问。NameNode维护着整个文件系统的元数据,其中包括文件系统树以及整个HDFS集群中所有的文件和目录。这些信息以文件系统的命名空间的形式存储在NameNode的内存中,并且写入到一个称为fsimage的文件中。元数据信息的变更记录被称为编辑日志,也就是edits文件。
- **DataNode:** DataNode在HDFS中代表了存储数据的实际节点。它们负责存储和检索块数据,并且执行文件系统命名空间中客户端的读写请求。DataNode通常运行在集群中的数据节点服务器上,每个节点存储一部分数据。DataNode会定期向NameNode发送心跳信号,并报告它所存储的块列表。
这两个组件共同协作,确保了数据在HDFS集群中的高可靠性和可用性。NameNode的元数据管理与DataNode的数据存储相结合,为分布式文件系统提供了必要的性能和可扩展性。
### 2.1.2 HDFS的核心组件介绍
除了NameNode和DataNode之外,HDFS还有一些其他核心组件,它们对整个系统的功能至关重要。
- **Secondary NameNode:** 这并不是一个热备或主备的NameNode,而是一个辅助节点,用于定期合并编辑日志和fsimage文件,以防止NameNode的内存元数据过大。它帮助减轻了主NameNode的内存负担,但并不参与实时的命名空间操作。
- **JournalNode:** 在高可用性(HA)的HDFS设置中,JournalNode负责维护NameNode的状态。当多个NameNode同时运行时,它们会共享编辑日志,以确保文件系统的状态可以被及时恢复。
- **ZooKeeper:** 在某些配置中,ZooKeeper用于管理集群中的NameNode和DataNode的选举。ZooKeeper是一个开源的分布式协调服务,它能够维护配置信息,进行命名服务,提供分布式同步和提供组服务。
通过这些核心组件的协同工作,HDFS能够在大规模、分布式环境中提供稳定的数据存储解决方案。
## 2.2 心跳机制在HDFS中的作用
### 2.2.1 心跳信号的定义与目的
心跳信号是分布式系统中一种常见的机制,它用于监测节点的活跃状态。在HDFS中,心跳信号是由DataNode向NameNode发送的周期性信息,用于确认DataNode是否存活并能够正常提供服务。
- **心跳信号的定义:** 心跳信号包含特定信息,比如DataNode的ID、存储的块列表以及其健康状态。心跳通常是一个空操作,不含任何实际的数据传输,但可以携带一些如负载信息、磁盘空间和网络利用率等监控指标。
- **心跳信号的目的:** 其主要目的是让NameNode持续了解DataNode的状态,确保数据节点的可用性。如果NameNode在一定时间内没有收到某个DataNode的心跳信号,它会将该DataNode标记为宕机,并开始处理数据的复制,以保证数据的可靠性和可用性。
心跳机制对于HDFS来说非常重要,它帮助NameNode维护对集群状态的实时监控,并在DataNode节点发生故障时迅速作出反应。
### 2.2.2 心跳机制对数据节点的监控功能
心跳机制不仅仅是简单的状态检查,它还包括了更深层次的监控功能。
- **负载均衡:** NameNode通过监控DataNode的心跳报告,可以了解集群中各个节点的负载情况。当检测到集群中的负载不均衡时,NameNode可以优化数据块的分布,例如通过移动数据块或者复制数据到负载较轻的节点上,从而实现负载均衡。
- **故障预测:** 心跳信号携带着各种系统级别的指标,比如CPU使用率、磁盘空间、网络带宽和读写吞吐量等。通过分析这些指标,NameNode可以预测可能的故障节点,并采取预防措施,比如提前复制数据到其他节点,以避免因节点故障导致的数据丢失。
- **性能调整:** 心跳机制提供的性能数据还可以帮助优化HDFS的性能。比如,如果发现某节点的读写性能下降,NameNode可以调整数据块的读写策略,减轻该节点的负担。
通过心跳机制的监控功能,HDFS能够及时响应节点的健康状况和性能状况,保证整个分布式文件系统的稳定性和高效运行。
## 2.3 心跳机制的原理与流程
### 2.3.1 数据节点与NameNode通信原理
在HDFS中,DataNode与NameNode之间的通信是基于TCP/IP协议的。心跳信号就是通过这种可靠的连接在DataNode与NameNode之间传递的。
- **通信过程:** 当DataNode启动时,它首先会向NameNode注册,并且建立一个持续的心跳通信。DataNode会周期性地向NameNode发送心跳信号,同时NameNode会记录心跳到达的时间,用来判断DataNode的存活状态。
- **心跳间隔:** 心跳信号的发送通常有一个预设的间隔,这个间隔可以配置,通常情况下,心跳间隔的大小会影响系统对节点状态变化的反应速度。
- **异常处理:** 如果NameNode在预设的超时时间内未收到心跳信号,它会认为对应的DataNode已经宕机或者网络连接出现问题,并采取相应措施,如启动数据块的复制过程。
### 2.3.2 心跳与块报告的交互过程
心跳信号和块报告是DataNode与NameNode之间交互的两个主要元素,它们共同维护了集群的健康状态。
- **心跳信号:** 周期性发送,主要功能是确认DataNode的存活状态和提供一些监控指标。
- **块报告:** 当DataNode启动或者有新的数据块加入时,它会向NameNode发送块报告。块报告包含了DataNode上存储的所有块的详细信息,这样NameNode就可以更新自己的元数据。
- **交互过程:** 在正常工作过程中,DataNode会定期发送心跳信号,在心跳信号中同时附加块报告信息。如果NameNode发现有新的块报告或者块的数量发生变化,它会更新自身的元数据信息。如果NameNode在配置的超时时间内没有收到心跳信号,它会认为DataNode宕机,根据配置采取相应的数据复制等措施。
心跳机制和块报告机制共同确保了HDFS能够实时监控和管理集群中各个节点的状态,从而保障了系统的稳定性和数据的可靠性。
在第二章中,我们探讨了HDFS心跳机制的理论基础,深入理解了HDFS架构中NameNode与DataNode的角色、心跳信号的定义与目的以及心跳与块报告的交互过程。接下来,我们将继续深入了解心跳机制的配置与优化,掌握如何根据实际需要调整心跳间隔、超时设置以及优化心跳频率的策略。此外,我们还将探讨心跳机制的性能优化、故障诊断与恢复,以及实践案例分析,进一步提升对HDFS心跳机制的掌握和应用能力。
# 3. HDFS心跳机制的配置与优化
## 3.1 心跳机制的配置参数
### 3.1.1 心跳间隔的配置与调整
在HDFS中,DataNode通过定时发送心跳信息到NameNode来报告其存活状态以及磁盘使用情况。心跳间隔的配置对于集群的性能至关重要。如果心跳间隔设置得太短,那么NameNode将会花费过多的时间来处理这些心跳,从而减少了处理其他关键任务的时间;如果设置得太长,NameNode可能会无法及时发现故障的DataNode,导致数据的不可用性增加。
为了合理设置心跳间隔,我们通常需要考虑以下因素:
- **集群的规模**:更大的集群可能需要更短的心跳间隔,以便及时发现问题。
- **网络延迟**:高延迟网络环境下,可能需要适当增加心跳间隔。
- **硬件性能**:高性能机器可以支持更频繁的心跳,以实现更细粒度的监控。
HDFS提供参数`dfs.heartbeat.interval`来设置心跳间隔,其默认值为3秒。调整此参数时应充分测试其对集群性能的影响。
示例配置调整心跳间隔:
```xml
<property>
<name>dfs.heartbeat.interval</name>
<value>5</value> <!-- 将心跳间隔调整为5秒 -->
</property>
```
### 3.1.2 超时设置的影响与应用
与心跳间隔密切相关的配置是超时设置。HDFS中DataNode的超时时间`dfs.namenode.heartbeat.recheck-interval`用于控制NameNode多久检查一次DataNode是否超时。超时设置过高可能会导致在DataNode故障时不能及时发现;设置过低可能会因为网络波动等导致误判为故障。
调整超时设置时,需要权衡集群的稳定性与实时性:
```xml
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>120000</value> <!-- 设置为120秒 -->
</property>
```
此参数默认值为30秒,意即NameNode每30秒会检查一次DataNode心跳超时情况。延长此时间可以在网络不稳定环境中减少不必要的状态检查,从而提高集群性能。
## 3.2 心跳机制的性能优化
### 3.2.1 优化心跳频率的策略
优化心跳频率的策略一般围绕着平衡心跳检查的实时性与资源消耗。一个有效的策略是引入“批处理”机制,即DataNode在一定时间窗口内累积多个状态更新后再一次性发送给NameNode,从而减少通信次数。
我们可以通过调整`dfs.http.policy`参数来指定心跳包的处理策略,如下:
- `HTTP_ONLY`(默认):使用HTTP协议发送心跳包。
- `WEBHDFS`:使用WebHDFS接口进行通信。
- `PROPRIETARY`:使用Hadoop的私有接口。
对于大规模集群,可以考虑调整策略到`HTTP_ONLY`来提升效率:
```xml
<property>
<name>dfs.http.policy</name>
<value>HTTP_ONLY</value> <!-- 启用HTTP_ONLY策略 -->
</property>
```
### 3.2.2 监控与故障排查工具的应用
监控工具在优化心跳机制中扮演着关键角色。在HDFS集群中,通常会使用Nagios、Zabbix或者Ambari等工具来监控心跳信号,以及集群的健康状况。
此外,Hadoop自带的一些命令行工具和Web界面也可以用来进行故障排查:
- **hdfs dfsadmin -report**:报告集群的状态信息。
- **hdfs haadmin -getServiceState <namenodeId>**:查看NameNode的服务状态。
- **hdfs datanode -report**:报告各个DataNode的状态和资源使用情况。
- **Ambari或Cloudera Manager**:提供图形界面,方便监控和故障诊断。
## 3.3 心跳机制故障诊断与恢复
### 3.3.1 常见心跳问题及解决方法
在HDFS心跳机制中,常见的问题通常涉及网络问题、资源不足或者配置错误。比如,如果DataNode无法与NameNode建立连接,可能会出现“无法连接到NameNode”的错误。
解决此类问题时,可以按照以下步骤进行:
1. **检查网络连接**:确保DataNode和NameNode之间网络是可达的。
2. **检查日志文件**:分析NameNode和DataNode的日志,查看可能的错误信息。
3. **调整配置**:根据问题调整相关的HDFS配置参数。
4. **重启服务**:在某些情况下,重启DataNode或NameNode服务可能解决问题。
### 3.3.2 数据节点恢复流程详解
当DataNode检测到本地故障时,需要执行一系列恢复流程,以保证数据的一致性和可用性。恢复流程通常包括以下几个步骤:
1. **自我检查**:DataNode在启动或者出现故障恢复后会执行自我检查,包括磁盘空间、文件系统的一致性检查等。
2. **向NameNode报告状态**:检查无误后,DataNode会向NameNode发送心跳,报告自己的存活状态。
3. **重新注册**:NameNode会根据报告的状态重新评估DataNode的状态,并进行必要的处理,如重新分配副本等。
4. **数据同步**:DataNode可能需要从其他DataNode同步数据来恢复损坏的数据块。
在整个恢复流程中,HDFS的副本管理机制起着关键作用,确保数据的副本数量和位置符合HDFS的设计要求。在这个过程中,心跳机制是持续监控DataNode状态、维护数据副本完整性的核心。
在下一章节,我们将深入探讨HDFS心跳机制在大规模集群中的应用案例,包括心跳机制在监控、故障诊断以及数据可靠性保障中的作用。
# 4. HDFS心跳机制实践案例分析
在这一章中,我们将深入探讨心跳机制在实际工作场景中的应用和实践。我们将通过案例分析的形式,展示心跳机制是如何在大规模集群中发挥作用的,以及它与数据可靠性的关联,最后介绍在自动化运维中的监控和管理策略。
## 4.1 心跳机制在大规模集群中的应用
大规模集群的管理是HDFS心跳机制最直观的应用场景之一。心跳信号不仅反映了各个节点的状态,而且对于整个集群的性能优化和故障预防都至关重要。
### 4.1.1 大数据环境下的心跳优化实践
在大数据环境下,心跳优化通常涉及到提高集群的性能和稳定性。这通常需要结合具体的业务场景和硬件资源来进行细致的调整。
以一个拥有上千个数据节点的HDFS集群为例,优化心跳配置首先需要评估集群的平均性能指标,如CPU、内存和磁盘的I/O使用情况。通过监控系统收集这些数据,我们能够找到性能瓶颈的节点。然后,我们可以针对性地调整心跳间隔和超时时间。
调整的逻辑是这样的:
1. 减少不必要的心跳频率可以降低NameNode的负载。
2. 对于性能较高的节点,可以适当延长心跳间隔,而性能较差的节点则需要更频繁的心跳来监控其健康状态。
3. 高频率的心跳数据可以帮助运维人员快速定位问题。
具体的调整步骤如下:
```bash
# 编辑 hdfs-site.xml 配置文件
$ sudo vi /etc/hadoop/conf/hdfs-site.xml
# 增加以下配置参数
<configuration>
<property>
<name>dfs心跳间隔</name>
<value>3</value> <!-- 设置心跳间隔为3秒 -->
</property>
<property>
<name>dfs数据节点超时</name>
<value>60</value> <!-- 设置数据节点超时时间为60秒 -->
</property>
</configuration>
```
**参数说明:**
- `dfs.heartbeat.interval`:数据节点发送心跳的时间间隔,单位为秒。较低的值会增加NameNode的负载,但能更快地检测到故障节点。
- `dfs.data.transfer.timeout`:设置数据传输超时时间,超过此时间未完成数据传输则认为传输失败。
### 4.1.2 复杂网络下的心跳策略配置
在复杂的网络环境下,如跨数据中心的集群,心跳信号的可靠性也会受到网络质量的影响。例如,在高延迟或网络不稳定的情况下,可能会出现误判节点故障的情况。因此,在这样的环境下,合理配置心跳策略是必要的。
在这种情况下,我们需要考虑的策略包括:
1. 增加超时时间,以适应网络延迟。
2. 使用数据包重传机制,减少因网络丢包导致的误判。
3. 实施快速重连机制,当检测到网络波动时,快速恢复数据节点与NameNode之间的连接。
配置示例如下:
```bash
# 编辑 hdfs-site.xml 配置文件
$ sudo vi /etc/hadoop/conf/hdfs-site.xml
# 增加以下配置参数
<configuration>
<property>
<name>dfs.心跳检查超时</name>
<value>180</value> <!-- 设置心跳超时时间为180秒 -->
</property>
<property>
<name>dfs.数据包重传次数</name>
<value>3</value> <!-- 设置数据包重传次数为3次 -->
</property>
</configuration>
```
**参数说明:**
- `dfs.heartbeat.check.interval`:NameNode检测数据节点心跳信号的时间间隔。
- `***ology/resolved關鍵字`:控制HDFS如何识别和处理网络拓扑的变化。
在实际操作中,需要结合网络性能测试结果来调整这些参数,以达到最佳的网络适应性。
## 4.2 心跳机制与数据可靠性保障
心跳机制除了监控集群的状态外,还是确保数据可靠性的关键一环。通过心跳机制,HDFS能够确保数据的副本数量始终满足用户定义的冗余级别。
### 4.2.1 心跳数据与副本管理
心跳信号不仅传递节点的状态信息,还包含了关于数据块健康性的信息。心跳消息中会报告每个数据块的状态,如校验和验证结果。如果某个数据块的副本数量低于设定的最小值,NameNode将触发数据的重新复制过程。
副本管理流程图如下:
```mermaid
graph LR
A[数据节点发送心跳] --> B[NameNode检查数据块副本]
B -->|副本不足| C[触发数据复制]
B -->|副本正常| D[维持现状]
C --> E[新的数据节点接收数据副本]
E --> F[更新副本计数]
```
这个流程确保了即使在硬件故障或其他非预期事件发生时,HDFS也能保证数据的高可用性。
### 4.2.2 防止数据丢失与校验机制
心跳信号中包含的校验机制是防止数据丢失的重要手段。每个数据节点都会周期性地对存储的数据块进行校验,确保数据块的完整性。如果检测到校验失败,心跳信号将报告错误,并触发数据块的修复流程。
数据修复过程如下:
1. 数据节点检测到某个数据块的校验失败。
2. 数据节点将损坏的数据块标记为“待修复”。
3. 数据节点通知NameNode,请求获取该数据块的其他副本。
4. NameNode分配一个有效的数据节点来进行数据块的复制。
5. 新的数据节点从健康的副本复制数据。
6. 复制完成,数据块状态更新。
此过程是自动化的,极大减少了手动干预的需求,并确保了数据的可靠性和完整性。
## 4.3 心跳机制的监控与自动化运维
心跳机制的数据为集群的自动化运维提供了宝贵的实时信息。通过监控心跳状态,运维团队可以及时发现问题并采取行动。
### 4.3.1 使用监控工具跟踪心跳状态
在Hadoop集群中,监控心跳状态是一个常见的运维任务。常用的监控工具有Ganglia、Nagios和Cloudera Manager等。这些工具可以帮助运维人员跟踪和分析心跳信号,从而更好地了解集群状态。
心跳状态监控的示例配置如下:
```bash
# 安装并配置Ganglia监控系统
$ sudo apt-get install ganglia-monitor
$ sudo apt-get install ganglia-webfrontend
# 编辑 Ganglia配置文件
$ sudo vi /etc/ganglia/conf.d/hadoop.conf
# 重启Ganglia服务
$ sudo service gmond restart
$ sudo service gmetad restart
```
通过Ganglia的Web界面,运维人员可以实时监控心跳状态,如下图所示:
 {
local node=$1
local count=$(hdfs dfsadmin -report | grep $node | awk '{print $5}')
if [ $count -ge $HEARTBEAT_THRESHOLD ]; then
echo "节点 $node 心跳信号丢失,尝试重启"
hadoop-daemon.sh --config /etc/hadoop/conf --script hdfs -- restart datanode $node
# 重试计数
local retries=0
until [ $(hdfs dfsadmin -report | grep $node | awk '{print $5}') -lt $HEARTBEAT_THRESHOLD ]
do
((retries++))
if [ $retries -ge $RESTART_LIMIT ]; then
echo "重启失败超过限制,请求人工干预"
break
fi
sleep 30 # 等待30秒
done
fi
}
check heartbeat "***"
```
通过执行这样的脚本,运维团队可以减轻工作负担,提高运维效率。当然,这只是一个基础例子,实际部署时可能需要更复杂的逻辑和安全措施。
通过以上分析,我们可以看到心跳机制在大规模集群应用、数据可靠性保障以及自动化运维中的重要性。接下来,我们将展望HDFS心跳机制的未来发展和可能的创新方向。
# 5. HDFS心跳机制的未来展望
随着技术的发展和大数据应用领域的不断拓展,HDFS作为大数据存储的核心解决方案,其心跳机制也在不断的演进与创新。HDFS心跳机制的未来发展不仅仅关乎于其自身性能的优化,更关系到与新兴技术的融合以及对云计算环境的适应。
## 5.1 HDFS心跳机制的发展趋势
### 5.1.1 适应云计算环境的改造
随着云计算环境成为主流,HDFS心跳机制也需要进行相应的改造以适应这种变化。云环境下的HDFS心跳机制将趋向于更加灵活的资源管理与优化。例如,心跳机制需要能够响应动态资源分配的变化,自动调整心跳频率以减少不必要的网络开销,同时保证数据的高可用性和一致性。
```yaml
# 云计算环境下心跳机制优化配置示例
hdfs-site.xml:
<property>
<name>dfs心跳间隔</name>
<value>3s</value>
</property>
<property>
<name>dfs数据节点超时</name>
<value>60s</value>
</property>
```
在上述配置中,心跳间隔被设置得更短,以应对动态环境的快速响应需求,而数据节点超时则根据网络和硬件环境进行调整,以减少因网络波动造成的误判。
### 5.1.2 新一代大数据技术对心跳的影响
新一代的大数据技术如Kafka、Spark等对数据的实时处理能力要求更高,传统的HDFS心跳机制可能无法满足实时数据流的需求。因此,心跳机制将可能发展为更加精细的数据管理和事件驱动的机制,以支持实时计算和流处理的场景。
## 5.2 HDFS心跳机制的创新探索
### 5.2.1 开源社区中的心跳机制改进
开源社区一直是推动技术发展的重要力量。在HDFS心跳机制的改进方面,社区已经提出了一些创新方案。例如,利用机器学习算法来预测数据节点的健康状态,从而智能地调整心跳频率,减少不必要的资源消耗。
### 5.2.2 新技术对心跳机制的潜在影响
未来,可能引入的新技术如量子计算和边缘计算等,将会对HDFS的心跳机制带来新的挑战和机遇。心跳机制需要考虑到节点计算能力的异构性以及网络延迟的降低,从而实现更加高效和智能化的健康监测。
心跳机制的持续优化和创新探索,将确保HDFS能够在不断变化的数据存储需求中保持其领先地位。这一机制的每一步改进,都是对大数据生态系统的深刻理解和前瞻性预判的结果。通过深入挖掘心跳机制的潜力,我们可以期待一个更加高效、智能且可靠的大数据存储解决方案的未来。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 HDFS 心跳机制,揭示了分布式存储系统稳定运行的秘密。文章涵盖了心跳机制的工作流程、优化策略、故障诊断、数据丢失应对方案以及在高可用架构中的作用。此外,还提供了心跳频率调整实践、监控与报警、扩展性分析、故障转移过程、网络负载均衡、与 NameNode 的交互、性能调优、代码实现、版本差异、容错机制和负载均衡策略等方面的深入见解。通过深入剖析 HDFS 心跳机制,读者可以掌握数据节点健康的关键技术,提升大数据集群性能,确保数据完整性,并实现高可用服务。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【伺服电机安装宝典】:汇川IS620P(N)系列伺服电机的正确安装与关键注意事项

# 摘要
本文详细介绍了伺服电机的安装、调试与维护过程,首先概述了伺服电机安装的相关内容,随后对硬件准备进行了深入讨论,包括选型标准、组件与配件以及保护措施。在安装步骤详解章节,我们探讨了安装环境的准备、电机安装过程和调试过程,为确保电机的精确安装和功能提供了实践指导。文章继续讲述了调试前的准备工作、参数调试以及日常维护,旨在提升伺服系统的性能和可靠性。最后
【桥接器调试必知】:PCIe Gen3 AXI桥接问题的有效诊断技巧
# 摘要
PCIe与AXI桥接技术作为高性能互连领域的关键技术,对于实现不同协议间的无缝通信发挥着至关重要的作用。本文全面探讨了PCIe与AXI桥接的基础知识,分析了桥接器在实际应用中可能遇到的问题,如信号完整性和时序同步问题,并提供了桥接器调试与测试的方法和技巧。实践案例研究帮助读者理解故障排除流程和预防策略,同时介绍了目前桥
【弱电系统巡检必备指南】:12个实用技巧,确保数据中心安全高效运行
# 摘要
弱电系统巡检在确保通信、安防及广播系统稳定运行中扮演着至关重要的角色。本文系统地探讨了弱电系统巡检的理论基础、实践技巧以及辅助技术,并通过案例分析展示了巡检在不同环境中的应用效果。巡检工作的核心标准与要求、弱电系统故障的理论分析、现代监控技术的应用等均是本文讨论的重点。随着智能化技术的发展,巡检工作正逐步迈向自动化和预测性维护,文章最后展望了未来巡检技术的趋势与挑战
【蓝桥杯EDA编程之道】:从新手到专家的进阶秘诀
# 摘要
本文全面阐述了电子设计自动化(EDA)编程的基础知识、核心技能以及项目管理与优化的高级应用。首先介绍了EDA编程的基础概念和工具的安装配置过程,包括软件选择、环境搭建和硬件软件交互设置。随后深入探讨了EDA编程的核心技能,如电路设计仿真、PCB布线布局和嵌入式系统编程。第四章着重分析了EDA项目管理的关键要素,包括项目
绿联USB转RS232驱动稳定性提升指南:专家级调试与维护教程
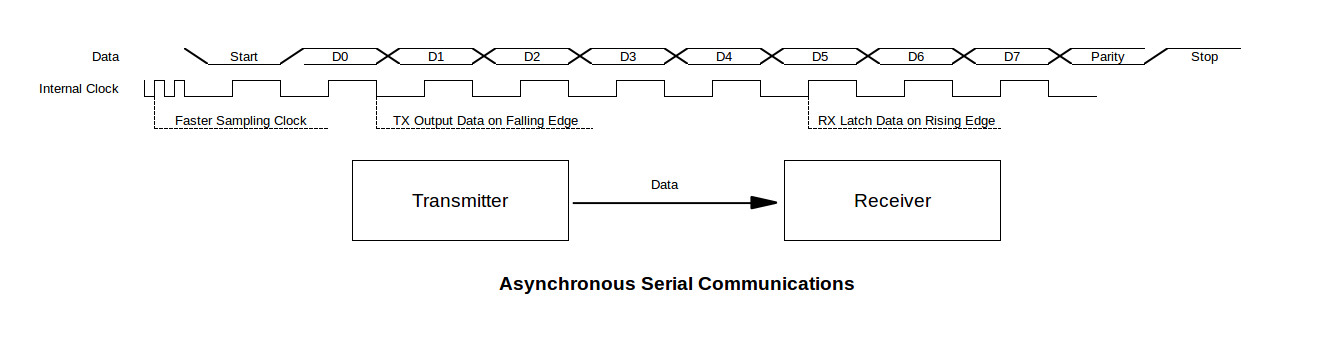
# 摘要
本文探讨了USB转RS232驱动的设计与开发,深入分析了驱动的基本原理、稳定性理论、调试方法、性能优化以及维护与生命周期管理。通过详细阐述USB与RS232协议、数据转换流程和驱动稳定性关键因素,本文为提高驱动的稳定性和性能提供了理论与实践的指导。本文还介绍了如何通过调试技巧和性能瓶颈分析来优化驱动,并强调了驱动维护和自动化测试部署的重要性。最终,文章总结了当前技术的发展,并对未来趋势做出了预测,旨在为USB转RS232驱
【Spring Data JPA实战指南】:构建响应式动态数据处理系统
/filters:no_upscale()/articles/Servlet-and-Reactive-Stacks-Spring-Framework-5/en/resources/1non-blocking-write-1521513541572.png)
# 摘要
本文详细介绍了Spring Data JPA的入门知识、配置方法以及核心实践,包括实体映射、CRUD操作、响应式编程集成、微服务
多语言搜索优化攻略:ISO-639-2实施策略大公开

# 摘要
随着全球化和互联网的普及,多语言搜索优化成为提升网站可达性和用户体验的关键。本文首先阐述了多语言搜索优化的必要性,并对ISO-639-2标准的起源、发展和结构进行了详细介绍。随后,文章提出了一系列实施ISO-639-2标准的策略,涵盖了语言检测、内容本地化、技术实现及SEO优化等关键环节。通过实际案例分析,进一步探讨了成功策略与常见问题解决方案。最后,本文展望了
Erdas遥感图像分类后处理技巧:4种方法提升分类精度
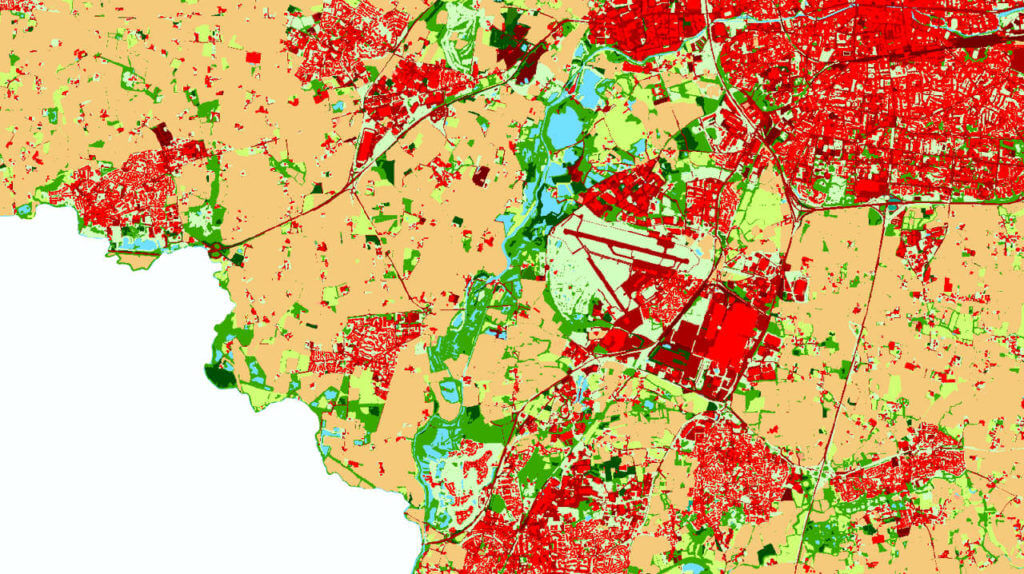
# 摘要
随着遥感技术的快速发展,Erdas软件在图像分类领域中的应用越来越广泛。本文首先介绍了Erdas遥感图像分类的基础知识和理论框架,包括遥感图像分类的原理、分类精度评价指标等。然后,文章深入探讨了提升遥感图像分类精度的实践方法,涵盖了图像预处理、增强技术、精细分类以及后处理技术。接着,文章进一步讨论了遥感图像分类后处理的高级应用,
【分布式架构】
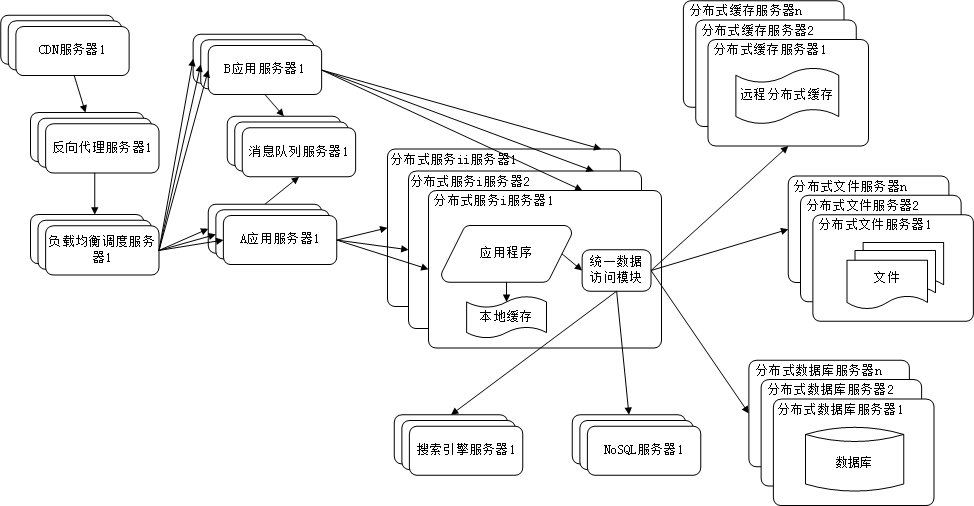
# 摘要
分布式架构作为一种先进的软件架构,支持现代大规模、高性能和高可用性系统的设计与实现。本文系统地探讨了分布式架构的基本概念、关键技术以及设计模式与实践,包括通信机制、数据管理、缓存和负载均衡策略。同时,文章深入分析了分布式系统在服务治理、容错和弹性架构设计方面的实践方法,并探讨了如何进行有效的监控与维护。此外,本文展望
【Apollo Dreamview问题排查】:系统错误无处遁形,专家诊断与解决策略

# 摘要
本文全面介绍了Apollo Dreamview系统,从其概述和常见问题出发,深入探讨了系统的架构与工作流程。文中详细分析了系统的主要组件及其间的通信机制,并对启动、配置及运行时数据处理流程进行了详解。同时,针对常见的启动失败、数据不一致和系统崩溃问题,提供了具体的错误诊断理论基础和实践技巧,包括日志分析、性能瓶颈定位和关键性能指标的监
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )