MyBatis-Plus的自定义SQL语句执行
发布时间: 2023-12-08 14:12:50 阅读量: 31 订阅数: 35 
### 1. 简介
#### 1.1 什么是 MyBatis-Plus
MyBatis-Plus 是 MyBatis 的增强工具库,提供了很多方便实用的功能,简化了开发人员在使用 MyBatis 进行数据库操作的过程。其中包括了自动生成 SQL、分页、逻辑删除、性能分析等功能。
#### 1.2 为什么需要自定义 SQL 语句执行
虽然 MyBatis-Plus 提供了很多方便的 CRUD 方法,但在实际开发中,有时仍然需要执行一些复杂的 SQL 查询,比如多表关联查询、统计查询等。这时就需要我们自定义 SQL 语句,并手动执行。
#### 1.3 目标和意义
自定义 SQL 语句执行的目标是满足特定需求的灵活性和性能优化。通过自定义 SQL,我们可以灵活地组织复杂的查询语句,减少数据传输和 SQL 解析等开销,提升查询性能。同时,自定义 SQL 也可以更好地满足业务需求,比如数据统计、多表关联等操作。
### 2. MyBatis-Plus简要介绍
#### 2.1 MyBatis-Plus的概述
MyBatis-Plus 是基于 MyBatis 的开发辅助工具,简化了 MyBatis 的使用过程,提供了一系列方便的工具和功能,包括代码生成器、分页插件、逻辑删除支持等。它不仅拥有 MyBatis 的所有功能,还提供了更加强大和便捷的功能。
#### 2.2 特性和优势
MyBatis-Plus 的特性和优势包括:
- 代码生成器:能够根据数据库表结构自动生成实体类、mapper 接口以及 XML 映射文件,快速生成基本的增删改查方法。
- 分页插件:提供了分页查询的支持,可以简单地实现分页功能。
- 逻辑删除支持:支持逻辑删除,即在数据库中标记删除而不是真正的删除数据。
- 性能分析插件:可以输出 SQL 执行的时间、执行计划等相关信息,便于性能调优。
- 条件构造器:提供了更加友好和灵活的条件构造方式,可以使用链式调用来组装复杂的查询条件。
#### 2.3 基本用法回顾
为了使用 MyBatis-Plus,我们只需要添加相应的 Maven 依赖,并在配置文件中加入相应的配置即可。基本用法回顾略,后续章节将详细介绍如何使用 MyBatis-Plus 进行自定义 SQL 的开发。
### 3. 自定义SQL语句的基本原理
自定义SQL语句的执行是指在使用MyBatis-Plus时,开发者需要执行一些自定义的SQL,而不是使用MyBatis-Plus提供的默认方法。本节将介绍自定义SQL语句执行的基本原理,包括MyBatis原生支持的SQL语句、MyBatis-Plus封装的自定义SQL语句执行以及SQL语句执行时的参数绑定和结果映射。
#### 3.1 MyBatis原生支持的SQL语句
在MyBatis中,使用XML映射文件或注解的方式,开发者可以编写自定义的SQL语句,并通过SqlSession执行相应的操作。这些SQL语句可以包括增删改查等各种操作,同时可以进行参数绑定和结果映射。
#### 3.2 MyBatis-Plus封装的自定义SQL语句执行
MyBatis-Plus在MyBatis的基础上进行了扩展,提供了更加便捷的方式执行自定义SQL语句。开发者可以通过@Select注解、Wrapper封装以及Mapper接口定义SQL方法等方式来执行自定义SQL。
#### 3.3 SQL语句执行时的参数绑定和结果映射
在执行自定义SQL语句时,需要注意参数绑定和结果映射。参数绑定指的是将方法参数绑定到SQL语句中
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MyBatis-Plus实战指南》是一本针对MyBatis-Plus框架的专栏,旨在帮助开发者快速了解和掌握该框架的各种功能和用法。该专栏从集成方式开始,详细介绍了MyBatis-Plus的基本使用、实体操作、条件构造器、高级查询、自定义SQL语句执行、乐观锁与悲观锁的使用等内容。此外,还讲解了MyBatis-Plus的关联查询、分页查询、批量操作等实现方法,并分享了性能优化和缓存机制的实战经验。专栏还涵盖了MyBatis-Plus与Spring Boot的整合、悲观锁的并发控制、在Spring Cloud微服务架构中的使用,以及单元测试和持续集成等实践。通过阅读本专栏,读者将深入了解MyBatis-Plus的各种特性和用法,并能够灵活使用该框架进行项目开发和优化。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
掌握MySQL JSON字段数据操作技巧:数据处理指南

# 1. MySQL JSON 字段简介**
MySQL JSON 字段是一种数据类型,用于存储和处理 JSON(JavaScript Object Notation)数据。JSON 是一种轻量级、基于文本的数据格式,广泛用于数据交换和表示复杂数据结构。
MySQL JSON 字段允许您将 JSON 数据作为单个值存储在表中。这提供了以下优势:
- **灵活性:**JSON 字段可以存储任意结构的
PHP数据库JSON返回与边缘计算:靠近数据,实时响应

# 1. PHP数据库JSON返回**
JSON(JavaScript对象表示法)是一种轻量级的数据交换格式,广泛用于Web开发。PHP数据库JSON返回功能允许开发者从PHP脚本中以JSON格式检索数据库查询结果。
与传统的文本或XML格式相比,JSON具有以下优势:
- **易于解
Redis数据库实战指南:打造高性能缓存系统
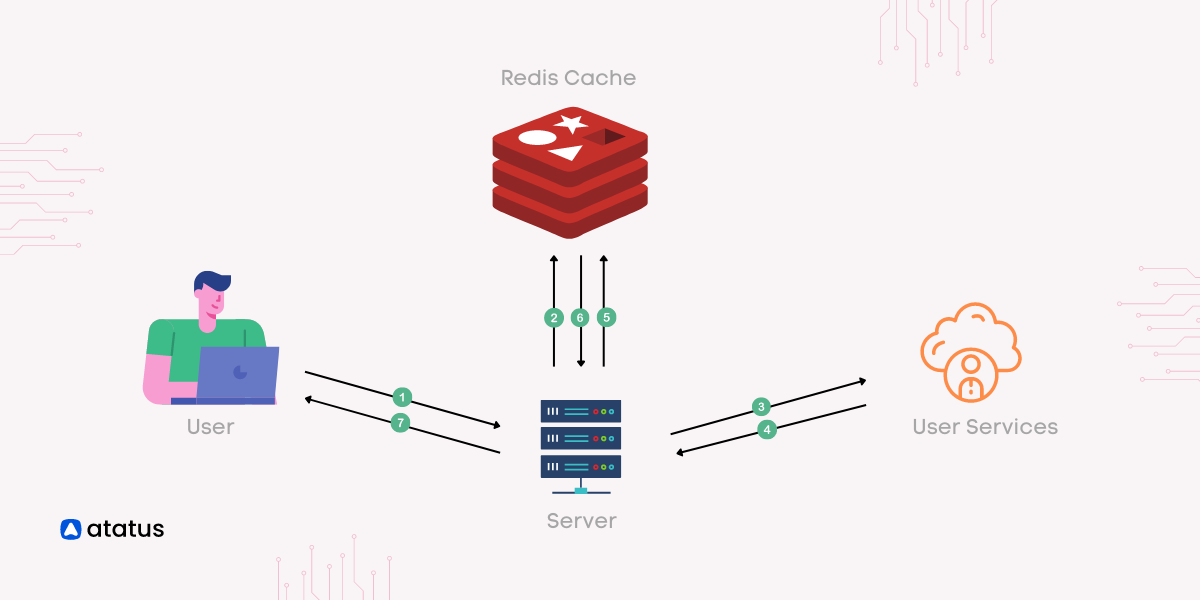
# 1. Redis数据库简介与理论基础
Redis(Remote Dictionary Server)是一个开源的、基于内存的键值对数据库,以其高性能、低延迟和可扩展性而闻名。它广泛用于缓存、消息队列和分布式锁等场景。
### 1.1 Redis的特点
* **内存操作:**Redis将数据存储在内存中,因此具有极高的读写性能。
* **单线程模型:**Redis使用
JSON数据在物联网中的应用:助力物联网数据管理
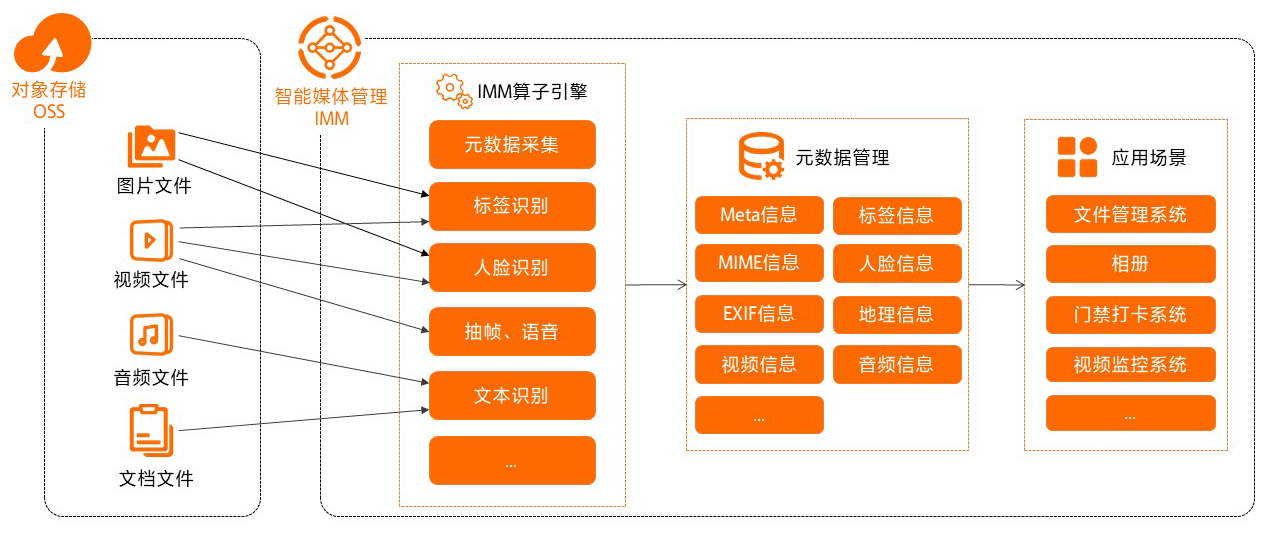
# 1. JSON数据简介**
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,用于在不同系统和应用程序之间传输和存储结构化数据。它基于JavaScript对象语法,使用键值对来表示数据,具有以下特点:
- **文本格式:** JSON数据以文本格式存储,易于阅读和解析。
- **层次结构:** JSON数据可以表示复杂的数
大数据场景下MySQL数据库的优化策略:应对海量数据挑战,打造高性能数据库系统
# 1. MySQL数据库基础**
MySQL是一种流行的关系型数据库管理系统(RDBMS),以其高性能、可扩展性和可靠性而闻名。它广泛应用于各种规模的企业,从小型企业到大型企业。
MySQL数据库的基础架构由以下关键组件组成:
*
PHP数据库连接单元测试指南:保障连接稳定性,提升代码质量

# 1. PHP数据库连接单元测试简介
PHP数据库连接单元测试是一种测试技术,用于验证PHP应用程序中与数据库交互的代码的正确性。它通过创建独立的测试用例来检查数据库连接的各个方面,例如连接建立、查询执行和数据操作。
单元测试数据库连接对于确保应用程序的可靠性和稳定性至关重要。通过在开发过程中及早发现和修复缺陷,它可以防止错误传播到生产环境并导致中断或数据丢失。
# 2. 数据库连接单元测试
实现虚拟表导出:MySQL命令行导出数据到视图,轻松导出复杂查询结果
# 1. MySQL导出数据概述
MySQL导出数据是将数据库中的数据提取到外部文件或其他系统中的过程。它在数据备份、数据迁移、数据分析等场景中有着广泛的应用。MySQL提供了多种导出数据的方法,其中虚拟表导出是一种高效、灵活的导出方式。
虚拟表导出利用MySQL的虚拟表功能,将查询结果作为
【MySQL运维指南】:保障数据库稳定运行,提升业务连续性

# 1. MySQL数据库基础**
MySQL是一种开源的关系型数据库管理系统(RDBMS),以其高性能、可靠性和可扩展性而闻名。它广泛用于各种应用程序,从小型网站到大型企业系统。
MySQL使用结构化查询语言(SQL)来管理和查询数据。SQL是一种标准化
MongoDB数据库与JSON交互最佳实践:打造高效交互

# 1. MongoDB与JSON基础**
MongoDB是一款文档型数据库,它将数据存储在类似于JSON的文档中。JSON(JavaScript对象表示法)是一种轻量级数据格式,用于在应用程序和服务器之间交换数据。MongoDB和JSON的紧密集成提供了以下优势:
- **灵活的数据建模:**JSON文档的非结构化性质允许灵活的数据建模,可以轻松适应不断变化的数据需求。
MySQL数据库性能监控与调优:保障数据库稳定运行,优化数据库性能

# 1. MySQL数据库性能监控基础
MySQL数据库性能监控是确保数据库系统高效运行的关键环节。本章将介绍MySQL数据库性能监控的基础知识,包括:
- **监控的重要性:**了解数据库性能监控对于识别和解决性能问题至关重要。
- **监控指标:**介绍关键性能指标(KPI),例如查询响应时间、连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )