MyBatis-Plus的缓存机制深度解析
发布时间: 2023-12-08 14:12:49 阅读量: 34 订阅数: 25 
# 1. MyBatis-Plus简介和缓存机制概述
## 1.1 MyBatis-Plus简介
MyBatis-Plus 是 MyBatis 的增强工具,在 MyBatis 的基础上扩展了许多实用的功能,旨在简化开发、提高效率。它提供了通用 Mapper、通用 Service 等功能,大大简化了开发流程。在实际项目中,MyBatis-Plus 已经成为众多开发者的选择。
## 1.2 缓存机制的重要性
缓存是提高系统性能的重要手段之一,通过缓存可以减少对数据库的访问次数,加快数据读取速度,提升系统的响应性能。在高并发访问场景下,合理地使用缓存可以有效减轻服务器压力,提高系统的稳定性和可靠性。
## 1.3 MyBatis-Plus中的缓存机制概览
MyBatis-Plus 作为 MyBatis 的增强工具,对缓存机制进行了进一步的优化和扩展,提供了一级缓存、二级缓存等功能,并且能够灵活配置和使用。深入理解MyBatis-Plus的缓存机制对于提高系统性能至关重要。接下来我们将详细介绍MyBatis-Plus的缓存机制及其使用方法。
# 2. MyBatis-Plus的一级缓存
### 2.1 什么是一级缓存
在介绍一级缓存之前,我们先来了解一下什么是缓存。缓存是一种临时存储数据的机制,它可以将数据保存在内存中,以提高数据访问的速度和性能。一级缓存指的是在同一个会话中,对于相同的查询,MyBatis-Plus会将查询结果缓存起来。当再次执行相同的查询时,MyBatis-Plus会先从缓存中获取结果,而不是再次去数据库执行查询操作。
### 2.2 MyBatis-Plus中一级缓存的实现原理
在 MyBatis-Plus 中,默认情况下,每个 SqlSession 都拥有一个独立的一级缓存。一级缓存是通过一个称为 `PerpetualCache` 的 HashMap 来实现的。当执行一个查询语句,并且开启了一级缓存时,MyBatis-Plus会将查询的结果对象存储在一级缓存中,以便后续再次使用。
### 2.3 一级缓存的使用注意事项
虽然一级缓存可以提高查询的性能,但是在特定的情况下,我们需要注意一些使用上的问题:
- 当修改了一个对象并且提交了事务后,MyBatis-Plus会清空一级缓存。因此,如果在同一个事务中执行了两次相同的查询,并且在第一次查询之后修改了查询结果对应的数据,那么第二次查询将不会从一级缓存中获取结果。
- 如果一个 session 中执行了两次相同的查询,并且在这两次查询之间执行了一次修改操作,则第二次查询不会从一级缓存中获取结果。
- 在并发的情况下,同一个 session 可能会被多个线程同时访问,这时需要注意一级缓存的线程安全性问题。
因此,我们在使用一级缓存的时候,要格外注意这些使用注意事项,以避免出现数据不一致的情况。
以上就是关于 MyBatis-Plus 的一级缓存的介绍和使用注意事项。在接下来的章节中,我们将继续介绍 MyBatis-Plus 的二级缓存及其使用方式。
# 3. MyBatis-Plus的二级缓存
在本章中,我们将深入探讨MyBatis-Plus中的二级缓存。我们将首先介绍什么是二级缓存,然后解析MyBatis-Plus中二级缓存的实现原理,并讨论如何配置和使用二级缓存。
#### 3.1 什么是二级缓存
二级缓存是指在不同的SqlSession之间共享缓存,可以提高数据库查询的性能。当我们在一个SqlSession中执行查询操作后,查询的结果会被存储在SqlSession的一级缓存中。而当我们关闭SqlSession,再重新打开一个新的SqlSession时,之前查询的结果不再可用,这时就需要通过二级缓存来实现不同SqlSession之间的共享缓存。
#### 3.2 MyBatis-Plus中二级缓存的实现原理
MyBatis-Plus中的二级缓存是通过Cache接口实现的,我们可以通过配置来启用和使用二级缓存。在MyBatis-Plus的配置文件中添加如下配置即可开启二级缓存:
```java
@Configuration
@MapperScan("com.example.mapper")
public class MyBatisPlusConfig {
@Bean
public ConfigurationCustomizer mybatisConfigurationCustomizer() {
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 赠618次下载
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MyBatis-Plus实战指南》是一本针对MyBatis-Plus框架的专栏,旨在帮助开发者快速了解和掌握该框架的各种功能和用法。该专栏从集成方式开始,详细介绍了MyBatis-Plus的基本使用、实体操作、条件构造器、高级查询、自定义SQL语句执行、乐观锁与悲观锁的使用等内容。此外,还讲解了MyBatis-Plus的关联查询、分页查询、批量操作等实现方法,并分享了性能优化和缓存机制的实战经验。专栏还涵盖了MyBatis-Plus与Spring Boot的整合、悲观锁的并发控制、在Spring Cloud微服务架构中的使用,以及单元测试和持续集成等实践。通过阅读本专栏,读者将深入了解MyBatis-Plus的各种特性和用法,并能够灵活使用该框架进行项目开发和优化。
专栏目录
最低0.47元/天 解锁专栏
赠618次下载
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python变量作用域与云计算:理解变量作用域对云计算的影响

# 1. Python变量作用域基础
变量作用域是Python中一个重要的概念,它定义了变量在程序中可访问的范围。变量的作用域由其声明的位置决定。在Python中,有四种作用域:
- **局部作用域:**变量在函数或方法内声明,只在该函数或方法内可见。
- **封闭作用域:**变量在函数或方法内声明,但在其外层作用域中使用。
- **全局作用域:**变量在模块的全局作用域中声明
Python Lambda函数在DevOps中的作用:自动化部署和持续集成
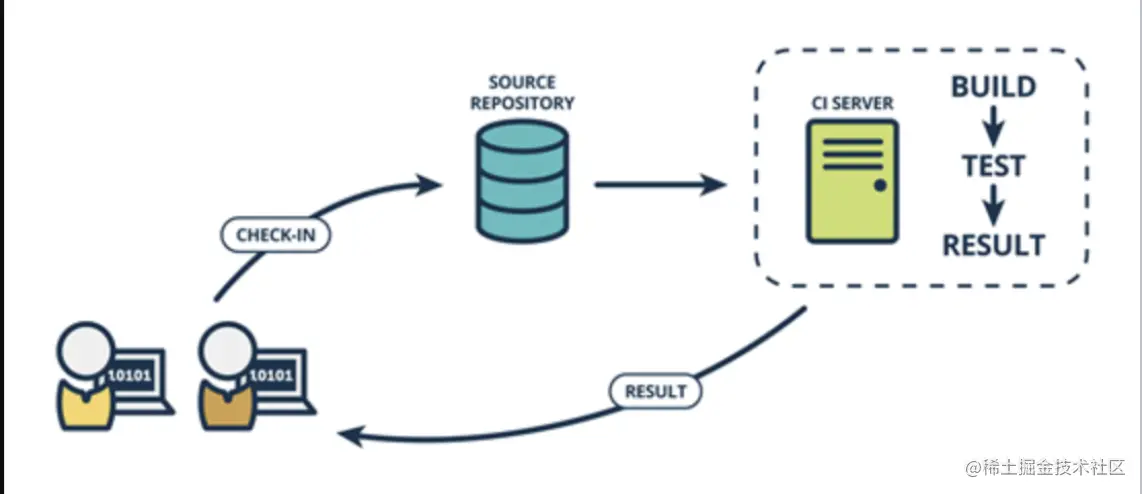
# 1. Python Lambda函数简介**
Lambda函数是一种无服务器计算服务,它允许开发者在无需管理服务器的情况下运行代码。Lambda函数使用按需付费的定价模型,只在代码执行时收费。
Lambda函数使用Python编程语言编写
Python生成Excel文件:开发人员指南,自动化架构设计
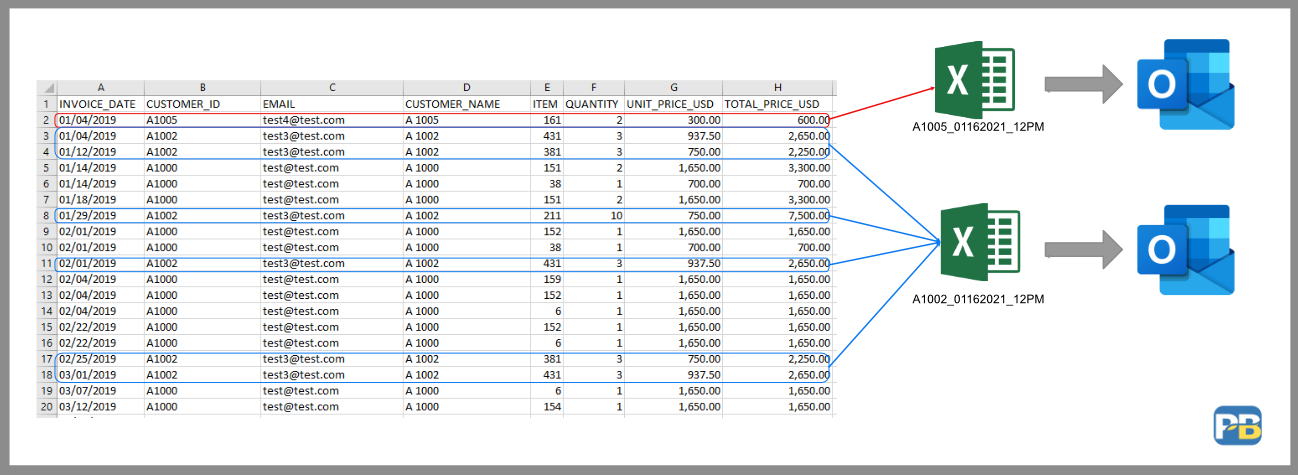
# 1. Python生成Excel文件的概述**
Python是一种功能强大的编程语言,它提供了生成和操作Excel文件的能力。本教程将引导您了解Python生成Excel文件的各个方面,从基本操作到高级应用。
Excel文件广泛用于数据存储、分析和可视化。Python可以轻松地与Excel文件交互,这使得它成为自动化任务和创建动态报表的理想选择。通过使用Python,您可以高效地创建、读取、更新和格式化E
Python3.7.0安装与最佳实践:分享经验教训和行业标准
# 1. Python 3.7.0 安装指南
Python 3.7.0 是 Python 编程语言的一个主要版本,它带来了许多新特性和改进。要开始使用 Python 3.7.0,您需要先安装它。
本指南将逐步指导您在不同的操作系统(Windows、macOS 和 Linux)上安装 Python 3.7.0。安装过程相对简单,但根据您的操作系统可能会有所不同。
# 2. Pyt
Python Requests库:常见问题解答大全,解决常见疑难杂症

# 1. Python Requests库简介
Requests库是一个功能强大的Python HTTP库,用于发送HTTP请求并处理响应。它提供了简洁、易用的API,可以轻松地与Web服务和API交互。
Requests库的关键特性包括:
- **易于使用:**直观的API,使发送HTTP请求变得简单。
- **功能丰富:**支持各种HTTP方法、身份验证机制和代理设
Jupyter Notebook安装与配置:云平台详解,弹性部署,按需付费

# 1. Jupyter Notebook概述**
Jupyter Notebook是一个基于Web的交互式开发环境,用于数据科学、机器学习和Web开发。它提供了一个交互式界面,允许用户创建和执行代码块(称为单元格),并查看结果。
Jupyter Notebook的主
PyCharm Python路径与移动开发:配置移动开发项目路径的指南

# 1. PyCharm Python路径概述
PyCharm是一款功能强大的Python集成开发环境(IDE),它提供
Python字符串为空判断的自动化测试:确保代码质量

# 1. Python字符串为空判断的必要性
在Python编程中,字符串为空判断是一个至关重要的任务。空字符串表示一个不包含任何字符的字符串,在各种场景下,判断字符串是否为空至关重要。例如:
* **数据验证:**确保用户输入或从数据库中获取的数据不为空,防止程序出现异常。
* **数据处理:**在处理字符串数据时,需要区分空字符串和其他非空字符串,以进行不同的操作。
* **代码可读
Python连接SQL Server性能优化技巧:显著提升连接速度

# 1. Python连接SQL Server的性能基础**
Python连接SQL Server的性能优化是一个多方面的过程,涉及到连接参数、查询语句、数据传输和高级技巧的优化。在本章中,我们将探讨连接SQL Server的性能基础,了解影响性能的关键因素,为后续的优化章节奠定基础。
首先,理解SQ
Python Excel读写项目管理与协作:提升团队效率,实现项目成功

# 1. Python Excel读写的基础**
Python是一种强大的编程语言,它提供了广泛的库来处理各种任务,包括Excel读写。在这章中,我们将探讨Python Excel读写的基础,包括:
* **Excel文件格式概述:**了解Excel文件格式(如.xlsx和.xls)以及它们的不同版本。
* **Python Excel库:**介绍用于Python
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
赠618次下载
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )