【C语言格式化大师】:sprintf的10个高级用法,专家级教程
发布时间: 2024-09-23 02:39:12 阅读量: 131 订阅数: 34 

C语言教程:sprintf()函数的使用方法
# 1. sprintf函数简介与基础使用
`sprintf` 函数是C语言标准库中的一个输出函数,主要用于生成格式化的字符串。它相当于C语言中的字符串 "打印机",可以将不同类型的数据转换成字符串形式,并按照指定格式输出到一个字符数组中。
## 基本使用方法
`sprintf` 的基本使用方法如下:
```c
#include <stdio.h>
int main() {
char str[100];
int a = 10;
float b = 20.5;
sprintf(str, "整数: %d, 浮点数: %.2f", a, b);
printf("%s\n", str);
return 0;
}
```
在这个简单的例子中,我们创建了一个字符数组 `str` 作为目标缓冲区,然后使用 `sprintf` 将整数 `a` 和浮点数 `b` 格式化后存储到 `str` 中,并通过 `printf` 输出结果。
## 格式化字符串的组成部分
格式化字符串由普通文本和格式说明符组成。格式说明符以 `%` 开始,后面可以跟有修饰符、宽度、精度、长度等控制信息。例如:
- `%d` 用于输出整数。
- `%.2f` 用于输出浮点数,并限制小数点后有两位数字。
正确使用 `sprintf` 可以在格式化输出时控制数据的精确表示,这在需要精确控制输出格式的情况下非常有用。
在接下来的章节中,我们将深入探讨 `sprintf` 的高级用法,包括如何处理不同数据类型的格式化输出、特殊字符和转义序列的使用技巧,以及如何安全和高效地使用 `sprintf`。
# 2. 掌握sprintf的高级格式化技巧
## 2.1 基本数据类型的高级格式化
### 2.1.1 整数类型的格式化输出
在C语言的字符串格式化函数sprintf中,整数类型的格式化输出是其最基本也是最重要的功能之一。要实现高级格式化,我们需要了解各种格式化占位符。例如,`%d` 用于十进制整数,`%x` 或 `%X` 用于十六进制整数(小写字母或大写字母),`%o` 用于八进制整数。
高级格式化技巧之一是控制整数的输出宽度和对齐方式。比如,`%5d` 会输出至少宽度为5的十进制整数,如果数字不足5位,则左侧用空格填充;`%-5d` 则是右对齐,左侧不填充空格。如果指定的宽度小于实际数字位数,则不会进行截断。
```c
#include <stdio.h>
int main() {
int num = 1234;
printf("%5d\n", num); // 输出: 1234
printf("%-5d\n", num); // 输出:1234
printf("%05d\n", num); // 输出:001234
return 0;
}
```
上述代码中,`%5d` 和 `%-5d` 控制了数字的对齐,而 `%05d` 在数字前面补零,确保输出宽度为5。
### 2.1.2 浮点数的精确控制输出
对于浮点数的格式化输出,sprintf提供了`%f`格式化指令,它允许我们设置小数点后的精度。格式化语法为`%.xf`,其中`x`表示小数点后的位数。如果要指定输出宽度和小数点精度,可以使用`% wx.yf`的形式。
高级格式化技巧还包括控制浮点数的四舍五入。例如,`%.3f`表示保留三位小数,`%.2f`保留两位小数。
```c
#include <stdio.h>
int main() {
double num = 123.456789;
printf("%.2f\n", num); // 输出:123.46
printf("%.5f\n", num); // 输出:123.45679
printf("%7.2f\n", num); // 输出: 123.46
return 0;
}
```
在上述代码示例中,`%.2f`和`%.5f`分别控制了输出的小数位数,`%7.2f`则在数字前面增加了空白,使得整体宽度达到7个字符。
## 2.2 特殊字符和转义序列的应用
### 2.2.1 特殊字符的输出方法
在字符串格式化中,经常会遇到需要输出特殊字符,例如换行符`\n`、制表符`\t`或者反斜杠`\\`等。这些特殊字符在C语言中使用转义序列来表示。
```c
#include <stdio.h>
int main() {
printf("Hello, World!\n");
printf("This is a tab: \t");
printf("This is a backslash: \\");
return 0;
}
```
上述代码中,`\n`代表换行,`\t`代表制表符,`\\`代表一个反斜杠字符。
### 2.2.2 转义序列在sprintf中的使用
sprintf函数也支持这些转义序列。将特殊字符嵌入到字符串中进行格式化输出,转义序列必须使用反斜杠。
```c
#include <stdio.h>
int main() {
char buffer[100];
sprintf(buffer, "This is a newline character: \n");
printf("%s", buffer);
return 0;
}
```
上述代码中,`sprintf`将包含换行符的字符串格式化到`buffer`中,并通过`printf`输出,从而在控制台中实现换行效果。
## 2.3 格式化指针和内存地址
### 2.3.1 指针变量的格式化输出
在C语言中,指针是一个极其重要的概念,sprintf也提供了将指针变量转换为字符串的格式化输出。使用`%p`格式化占位符来输出指针地址。
```c
#include <stdio.h>
int main() {
int a = 10;
int *p = &a;
printf("The address of integer variable is: %p\n", (void*)p);
return 0;
}
```
在上述代码中,`%p`格式化输出指针`p`的内存地址。
### 2.3.2 内存地址的显示技巧
内存地址显示时,可以通过`%#p`来显示十六进制的指针格式,这样指针地址前会自动加上`0x`前缀。
```c
#include <stdio.h>
int main() {
int a = 10;
int *p = &a;
printf("The formatted address of integer variable is: %#p\n", (void*)p);
return 0;
}
```
通过`%#p`格式化占位符,在输出指针地址时能更加直观地以十六进制显示地址,方便阅读和调试。
# 3. sprintf在实际编程中的应用案例
在这一章节中,我们将深入了解sprintf函数在真实世界编程任务中的应用,通过案例学习如何构建复杂的字符串,记录日志,以及在用户界面中展示数据。这些案例不仅帮助你理解sprintf的实用性,还将展示如何在高级编程场景中优化使用sprintf。
## 3.1 构建复杂的字符串
字符串构建是编程中的常见任务,sprintf函数在这一过程中扮演着至关重要的角色。我们将探讨如何使用sprintf来构建字符串数组以及结合动态内存分配技术来优化性能。
### 3.1.1 字符串数组的构建和拼接
在编程中,字符串的构建和拼接是基本操作,sprintf使得这一过程变得更加灵活和强大。
```c
#include <stdio.h>
int main() {
char buffer[100];
const char *str1 = "Hello, ";
const char *str2 = "World!";
sprintf(buffer, "%s%s", str1, str2);
printf("Concatenated String: %s\n", buffer);
return 0;
}
```
在上述代码中,我们定义了一个足够大的字符数组`buffer`以存储最终的字符串。接着,我们使用sprintf函数将`str1`和`str2`拼接起来,并输出到`buffer`中。这种方法在处理大量字符串拼接时特别有用,因为它可以减少多次使用`+`运算符进行字符串连接导致的内存重新分配问题。
### 3.1.2 动态内存分配与sprintf结合使用
在某些情况下,字符串的长度是预先无法确定的。此时,结合动态内存分配,sprintf函数可以提供一个灵活的解决方案。
```c
#include <stdio.h>
#include <stdlib.h>
int main() {
int n = 10;
char *buffer = (char *)malloc(n * sizeof(char)); // 动态分配内存
if(buffer == NULL) {
fprintf(stderr, "Memory allocation failed!\n");
return -1;
}
// 使用sprintf函数填充动态分配的内存
sprintf(buffer, "Number: %d", n);
printf("Dynamic String: %s\n", buffer);
free(buffer); // 释放内存
return 0;
}
```
在上述代码示例中,我们使用`malloc`动态地为`buffer`分配了足够存储数字和字符串的空间。然后使用sprintf将字符串和数字拼接,最终通过`free`函数释放了内存。
## 3.2 日志和文件写入
在软件开发中,日志记录是跟踪程序运行状态的重要手段,sprintf函数常用于日志文件的格式化写入和高效文件内容更新策略。
### 3.2.1 日志文件的格式化写入
日志文件通常包含时间戳、错误级别和错误描述等信息。sprintf可以用于创建这些信息,并将其格式化输出到日志文件中。
```c
#include <stdio.h>
#include <time.h>
void log_error(const char *format, ...) {
va_list args;
va_start(args, format);
FILE *log_file = fopen("error.log", "a");
if (log_file == NULL) {
perror("Error opening file");
return;
}
// 获取当前时间并格式化为字符串
char time_str[26];
time_t raw_time;
time(&raw_time);
struct tm *time_info = localtime(&raw_time);
strftime(time_str, sizeof(time_str), "%Y-%m-%d %H:%M:%S", time_info);
// 写入时间戳和消息
fprintf(log_file, "%s: ", time_str);
vfprintf(log_file, format, args);
fprintf(log_file, "\n");
fclose(log_file);
va_end(args);
}
int main() {
log_error("This is a formatted error message");
return 0;
}
```
上面的代码定义了一个`log_error`函数,使用`va_list`处理可变参数列表,并将格式化后的错误消息写入日志文件。这种方法可以减少日志记录的代码冗余,并提高其灵活性。
### 3.2.2 高效文件内容更新策略
当频繁写入文件时,直接使用文件I/O可能会导致性能问题。sprintf可以与缓冲技术结合,优化文件内容更新。
```c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define BUFFER_SIZE 4096
void update_file(const char *message) {
static char buffer[BUFFER_SIZE];
static int current_length = 0;
// 检查是否需要刷新缓冲区
if(current_length + strlen(message) + 1 >= BUFFER_SIZE) {
// 打开文件
FILE *fp = fopen("example.txt", "a");
if(fp == NULL) {
perror("Error opening file");
return;
}
// 写入缓冲区内容
fwrite(buffer, sizeof(char), current_length, fp);
// 清空缓冲区
memset(buffer, 0, BUFFER_SIZE);
current_length = 0;
fclose(fp);
}
// 追加消息到缓冲区
strcpy(buffer + current_length, message);
current_length += strlen(message);
}
int main() {
update_file("First line of text\n");
update_file("Second line of text\n");
return 0;
}
```
在上述代码中,我们定义了一个静态缓冲区`buffer`用于暂存数据,并通过一个静态变量`current_length`跟踪当前缓冲区中的内容长度。这样当缓冲区满时,我们可以将整个缓冲区的内容一次性写入文件,从而减少I/O操作次数。
## 3.3 用户界面数据展示
在用户界面编程中,数据的格式化展示对于用户体验至关重要。无论是在命令行界面还是图形用户界面中,sprintf都可作为数据格式化的有力工具。
### 3.3.1 命令行界面下的数据格式化展示
在命令行程序中,sprintf可以帮助我们格式化输出,使得数据展示更加整洁、易读。
```c
#include <stdio.h>
void display_data(int number, float value) {
char buffer[128];
sprintf(buffer, "Number: %d, Value: %.2f", number, value);
printf("%s\n", buffer);
}
int main() {
display_data(10, 3.14159);
return 0;
}
```
上述示例中,我们定义了一个`display_data`函数,它接收整数和浮点数作为参数,使用sprintf进行格式化,然后将格式化后的字符串输出到命令行界面。
### 3.3.2 图形用户界面中的格式化显示技术
在图形用户界面(GUI)中,使用sprintf进行数据格式化同样重要。虽然具体实现依赖于所用的GUI库,但基本思想是一致的。
```c
#include <gtk/gtk.h>
void on_button_clicked(GtkWidget *widget, gpointer data) {
char buffer[128];
int user_value = GPOINTER_TO_INT(data);
sprintf(buffer, "You clicked %d times", user_value);
GtkWidget *dialog = gtk_message_dialog_new(NULL, GTK_DIALOG_DESTROY_WITH_PARENT, GTK_MESSAGE_INFO, GTK_BUTTONS_OK, "%s", buffer);
gtk_dialog_run(GTK_DIALOG(dialog));
gtk_widget_destroy(dialog);
}
int main(int argc, char *argv[]) {
GtkWidget *window;
GtkWidget *button;
int click_count = 0;
gtk_init(&argc, &argv);
window = gtk_window_new(GTK_WINDOW_TOPLEVEL);
gtk_window_set_title(GTK_WINDOW(window), "GTK Test");
gtk_container_set_border_width(GTK_CONTAINER(window), 10);
g_signal_connect(window, "destroy", G_CALLBACK(gtk_main_quit), NULL);
button = gtk_button_new_with_label("Click me!");
g_signal_connect(button, "clicked", G_CALLBACK(on_button_clicked), GINT_TO_POINTER(click_count));
g_signal_connect_swapped(button, "clicked", G_CALLBACK(gtk_widget_destroy), window);
gtk_container_add(GTK_CONTAINER(window), button);
gtk_widget_show_all(window);
gtk_main();
return 0;
}
```
上述代码创建了一个简单的GTK程序,包含一个窗口和一个按钮。每次点击按钮时,都会调用`on_button_clicked`函数,该函数利用sprintf格式化一个消息,并用它来创建一个消息对话框。
这些案例展示了sprintf函数在实际编程应用中的多样性和强大能力。通过这些示例,我们可以看到sprintf如何帮助开发者高效地构建和管理字符串,以及它在日志记录和用户界面数据展示中的关键作用。接下来,我们将深入探讨sprintf的安全性和性能优化。
# 4. sprintf的安全性与性能优化
为了避免在使用sprintf时出现常见的安全漏洞和性能问题,程序员需要深入理解该函数的工作机制,并掌握相应的优化和安全防护技巧。本章将深入探讨如何通过合适的方法来减少缓冲区溢出的风险,提高sprintf的性能,并处理一些边界情况。
## 4.1 避免缓冲区溢出的风险
在C语言中,由于缺乏内置的数组边界检查,使用sprintf时很容易发生缓冲区溢出。当目标缓冲区大小不足以容纳格式化后的字符串时,会导致数据被覆盖,这可能会引起程序崩溃或安全漏洞。
### 4.1.1 确保目标缓冲区足够大
为了避免缓冲区溢出,开发者必须确保为sprintf提供的目标缓冲区足够大以容纳最终的字符串。这通常需要预先知道或计算出可能的最大字符串长度。使用如`snprintf()`函数,它可以限制写入的最大字符数,从而提供了一定程度的安全保障。
```c
#include <stdio.h>
int main() {
char buffer[512];
int number = 12345;
// 使用snprintf来确保不会溢出
snprintf(buffer, sizeof(buffer), "The number is %d", number);
printf("%s\n", buffer);
return 0;
}
```
### 4.1.2 使用动态内存分配的策略
有时候,很难预先确定字符串的最大长度。在这些情况下,可以使用动态内存分配来为字符串分配足够的空间。`asprintf()`是一个方便的函数,它会根据格式化后的字符串自动分配空间。
```c
#include <stdio.h>
#include <stdlib.h>
int main() {
int number = 12345;
char *buffer;
// 使用asprintf自动分配空间
asprintf(&buffer, "The number is %d", number);
printf("%s\n", buffer);
free(buffer); // 记得释放内存
return 0;
}
```
## 4.2 优化sprintf的执行效率
除了安全性之外,提高sprintf的性能也是重要的考虑因素。性能优化通常涉及到减少不必要的操作和利用编译器优化技巧。
### 4.2.1 减少不必要的字符串操作
在格式化之前,应尽量减少对字符串的处理,如不必要的拼接或修改。因为每次字符串操作都可能导致内存复制,从而影响性能。
### 4.2.2 使用局部变量和宏定义提高效率
在循环或频繁调用的代码段中,可以利用局部变量和宏定义来存储重复使用的格式化字符串或变量,以避免重复的格式化操作。
```c
#define FORMAT_STR "The number is %d\n"
char buffer[256];
int number;
for (int i = 0; i < 100; ++i) {
number = i; // 假设这是动态获取的数值
// 使用宏定义的格式化字符串,避免重复格式化
snprintf(buffer, sizeof(buffer), FORMAT_STR, number);
// 输出或使用buffer
}
```
## 4.3 理解和应用边界情况
sprintf函数的边界情况处理也是至关重要的。开发者必须了解在哪些情况下sprintf的行为可能与预期不符,并采取措施应对。
### 4.3.1 探索sprintf的边界情况
了解sprintf对不同类型数据的处理方式,包括非标准大小的整数类型和特殊字符,可以帮助开发者写出更健壮的代码。
### 4.3.2 应对特殊格式化需求的解决方案
在处理特殊格式化需求时,如对齐、填充、特定精度输出等,需要恰当使用格式化指定符来满足这些需求,同时保证输出的准确性和效率。
在这一章节中,我们已经探讨了如何通过一系列技巧和策略来提高sprintf的性能并确保其安全稳定地运行。优化和安全性问题往往贯穿整个开发周期,因此,作为一名有经验的IT行业从业者,理解这些细微之处对于提升个人的技术水平和项目质量至关重要。
# 5. sprintf的替代方案和扩展函数
## 5.1 格式化输出的替代选项
### 5.1.1 asprintf等动态内存分配的函数
`asprintf` 是一个在 C 语言中非常有用的函数,它的功能类似于 `sprintf`,但其优势在于它会自动分配足够的内存来存储最终的字符串,这避免了需要预先知道字符串长度的麻烦。使用 `asprintf` 可以简化内存管理,并减少缓冲区溢出的风险。
```c
#include <stdio.h>
#include <stdlib.h>
int main() {
int n = 42;
char *str = NULL;
asprintf(&str, "The answer is %d\n", n);
printf("%s", str);
free(str);
return 0;
}
```
在上述代码中,`asprintf` 为包含格式化输出的字符串分配了足够的内存,并通过指针返回了这个内存地址。这样,开发者就不必担心分配的缓冲区大小是否合适,也不需要手动释放内存,因为 `asprintf` 负责了这一切。然而,需要注意的是,当不再需要该字符串时,`free` 函数必须被调用来释放内存,以避免内存泄漏。
### 5.1.2 snprintf的安全和性能优势
`snprintf` 是 `sprintf` 的一个安全版本,它允许开发者指定目标缓冲区的最大容量。`snprintf` 会将格式化后的字符串写入缓冲区,但不会超出指定的长度,这样就有效防止了缓冲区溢出的问题。除此之外,`snprintf` 在性能上也更优,因为它可以在循环中安全使用,而不需要每次都进行内存分配。
```c
#include <stdio.h>
int main() {
int num = 1024;
char buffer[128];
snprintf(buffer, sizeof(buffer), "The number is: %d\n", num);
printf("%s", buffer);
return 0;
}
```
在此例中,`snprintf` 将格式化后的字符串写入 `buffer`,同时确保不超过 `buffer` 的大小。这意味着即使格式化字符串很长,也决不会覆盖 `buffer` 之外的内存。`snprintf` 对于处理动态数据尤其有用,因为它可以保证输出始终不会超出预期。
## 5.2 格式化函数的扩展应用
### 5.2.1 格式化函数在其他编程语言中的应用
格式化输出不仅仅局限于 C 语言,许多其他编程语言都提供了类似的格式化方法。例如,Python 使用 `%` 操作符或者 `str.format()` 方法来格式化字符串;在 JavaScript 中,模板字符串提供了一种简洁的格式化方式;Java 中则有 `String.format()` 方法等。
### 5.2.2 比较不同格式化函数的优劣
不同编程语言中的格式化函数各有优劣,它们各自适合不同的使用场景。在选择格式化函数时,需要考虑以下因素:
- **易用性**:函数的使用是否直观,是否有丰富的格式化选项。
- **性能**:格式化操作的执行速度和内存消耗。
- **灵活性**:函数是否能够处理复杂的格式化需求。
- **安全性**:函数是否能够防止常见的安全问题,如缓冲区溢出。
- **跨平台**:函数是否能够在不同的操作系统和硬件架构上提供一致的行为。
例如,虽然 `printf` 相关的函数在性能上可能略逊一筹,但它们在格式化选项上提供了极大的灵活性。而像 Python 的字符串格式化,虽然简单易用,但在性能上可能不适合大量数据的格式化处理。
表格1比较了C、Python和JavaScript中格式化方法的特性:
| 特性/语言 | C语言的sprintf | Python的%操作符 | JavaScript模板字符串 |
|------------|----------------|-----------------|-----------------------|
| 易用性 | 需要详细格式化指令 | 简洁明了,支持基本和高级格式化 | 语义清晰,易于阅读和维护 |
| 性能 | 对齐等操作较慢 | 较快 | 快速 |
| 灵活性 | 可以实现复杂的格式化 | 格式化选项较多 | 功能较为基础 |
| 安全性 | 易出现缓冲区溢出 | 内置防范机制 | 由语言特性保证 |
| 跨平台 | 标准化,跨平台 | 标准化,跨平台 | 需要环境支持 |
选择合适的格式化函数,需要综合考虑实际应用场景、开发者的熟悉程度以及编程语言的特性。在编写代码时,开发者应该权衡易用性、性能和安全性之间的平衡,以做出最佳选择。
# 6. 深度剖析sprintf的内部实现
## 6.1 sprintf的工作原理
### 6.1.1 格式化过程的内部机制
在深入理解`sprintf`的工作原理前,需要明白它实际上是一个封装了`printf`的变体,它将格式化的字符串直接写入到一个指定的内存缓冲区中。这一过程涉及以下几个核心步骤:
1. **读取格式字符串**:`sprintf`从第一个参数(格式字符串)开始解析,寻找格式指定符(如`%d`, `%f`, `%s`等)。
2. **参数处理**:随后`sprintf`会根据格式指定符的类型,从参数列表中取出相应的参数。它会按照指定格式处理这些参数,并准备转换成字符串。
3. **转换与存储**:格式化转换由库函数中的转换器来完成,最终结果被写入目标缓冲区。
4. **添加结束符**:格式化完成后,`sprintf`会在目标字符串的末尾自动添加空字符`\0`以确保它是一个有效的C字符串。
### 6.1.2 格式字符串的解析过程
格式字符串是`sprintf`功能强大的根源,它告诉函数如何处理和转换后续的参数。解析过程包括:
- **定位格式指定符**:首先找到格式字符串中的`%`符号,这标志着一个格式指定符的开始。
- **识别类型和修饰符**:紧跟在`%`符号后的字符指定了参数的类型(如`d`表示十进制整数),以及可能的修饰符,比如宽度、精度、左右对齐标志等。
- **处理参数**:`sprintf`根据上述指定符从参数列表中取出相应的数据,将其转换为字符串形式。
- **重复解析**:解析格式字符串的剩余部分,直到所有格式指定符被处理完毕。
理解这个过程对于避免常见的格式化错误至关重要,特别是在处理指针、浮点数或大型数据类型时。
## 6.2 格式化错误的调试技巧
### 6.2.1 常见错误和陷阱
在使用`sprintf`时,开发者可能会遇到几种常见错误和陷阱:
- **缓冲区溢出**:未正确指定目标缓冲区大小,导致写入的数据超出分配的空间。
- **类型不匹配**:提供的参数类型与格式指定符不匹配,比如使用整数指定符来处理浮点数。
- **不完整的格式字符串**:未包含足够的格式指定符来匹配所有待处理的参数,或参数数量超过指定符数量。
### 6.2.2 利用调试工具定位和修复问题
定位和修复`sprintf`相关错误通常可以通过以下方法:
- **静态代码分析器**:利用静态分析工具(例如`cppcheck`或`clang-tidy`)在编译时检查潜在的格式化问题。
- **调试工具的断点和追踪功能**:使用调试器(如`gdb`)设置断点,观察程序在格式化过程中的行为。
- **字符串长度检查**:在代码中增加逻辑,对格式化后的字符串长度进行检查,确保没有超出缓冲区界限。
- **单元测试**:编写单元测试,确保`sprintf`调用在各种边界条件下都能正确执行,包括空缓冲区、极小和极大的数值等。
通过深入理解`sprintf`的内部实现和采取有效的调试策略,开发者可以更安全、有效地利用这一强大的标准库函数。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“字符串格式化”专栏,在这里您将深入了解各种编程语言中字符串格式化的奥秘。本专栏汇集了来自 Python、C、Java、C++、Go、PHP、SQL、JavaScript 等语言的专家级教程和实用技巧。从基础概念到高级用法,我们将为您提供全面的指导,让您掌握字符串格式化的艺术。此外,我们还探讨了字符串格式化在数据科学、前端开发、Linux shell 和 Excel 中的应用,以及防范注入式攻击的安全实践。无论您是初学者还是经验丰富的程序员,本专栏都将为您提供提升字符串格式化技能所需的知识和见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
空间统计学新手必看:Geoda与Moran'I指数的绝配应用
# 摘要
本论文深入探讨了空间统计学在地理数据分析中的应用,特别是运用Geoda软件进行空间数据分析的入门指导和Moran'I指数的理论与实践操作。通过详细阐述Geoda界面布局、数据操作、空间权重矩阵构建以及Moran'I指数的计算和应用,本文旨在为读者提供一个系统的学习路径和实操指南。此外,本文还探讨了如何利用Moran'I指数进行有效的空间数据分析和可视化,包括城市热岛效应的空间分析案例研究。最终,论文展望了空间统计学的未来
【Python数据处理秘籍】:专家教你如何高效清洗和预处理数据

# 摘要
随着数据科学的快速发展,Python作为一门强大的编程语言,在数据处理领域显示出了其独特的便捷性和高效性。本文首先概述了Python在数据处理中的应用,随后深入探讨了数据清洗的理论基础和实践,包括数据质量问题的认识、数据清洗的目标与策略,以及缺失值、异常值和噪声数据的处理方法。接着,文章介绍了Pandas和NumPy等常用Python数据处理库,并具体演示了这些库在实际数
【多物理场仿真:BH曲线的新角色】:探索其在多物理场中的应用
# 摘要
本文系统介绍了多物理场仿真的理论基础,并深入探讨了BH曲线的定义、特性及其在多种材料中的表现。文章详细阐述了BH曲线的数学模型、测量技术以及在电磁场和热力学仿真中的应用。通过对BH曲线在电机、变压器和磁性存储器设计中的应用实例分析,本文揭示了其在工程实践中的重要性。最后,文章展望了BH曲线研究的未来方向,包括多物理场仿真中BH曲线的局限性
【CAM350 Gerber文件导入秘籍】:彻底告别文件不兼容问题
# 摘要
本文全面介绍了CAM350软件中Gerber文件的导入、校验、编辑和集成过程。首先概述了CAM350与Gerber文件导入的基本概念和软件环境设置,随后深入探讨了Gerber文件格式的结构、扩展格式以及版本差异。文章详细阐述了在CAM350中导入Gerber文件的步骤,包括前期
【秒杀时间转换难题】:掌握INT、S5Time、Time转换的终极技巧
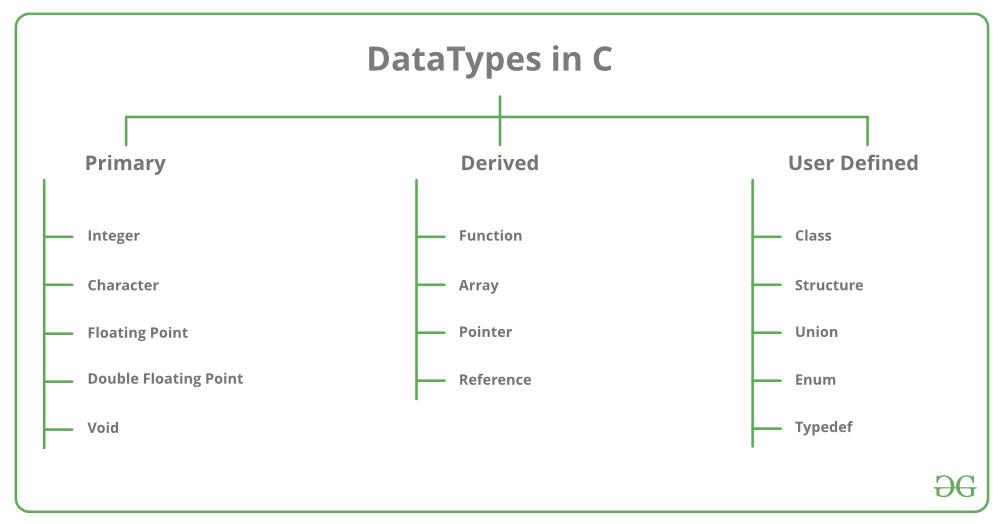
# 摘要
时间表示与转换在软件开发、系统工程和日志分析等多个领域中起着至关重要的作用。本文系统地梳理了时间表示的概念框架,深入探讨了INT、S5Time和Time数据类型及其转换方法。通过分析这些数据类型的基本知识、特点、以及它们在不同应用场景中的表现,本文揭示了时间转换在跨系统时间同步、日志分析等实际问题中的应用,并提供了优化时间转换效率的策略和最
【传感器网络搭建实战】:51单片机协同多个MLX90614的挑战

# 摘要
本论文首先介绍了传感器网络的基础知识以及MLX90614红外温度传感器的特点。接着,详细分析了51单片机与MLX90614之间的通信原理,包括51单片机的工作原理、编程环境的搭建,以及传感器的数据输出格式和I2C通信协议。在传感器网络的搭建与编程章节中,探讨了网络架构设计、硬件连接、控制程序编写以及软件实现和调试技巧。进一步
Python 3.9新特性深度解析:2023年必知的编程更新
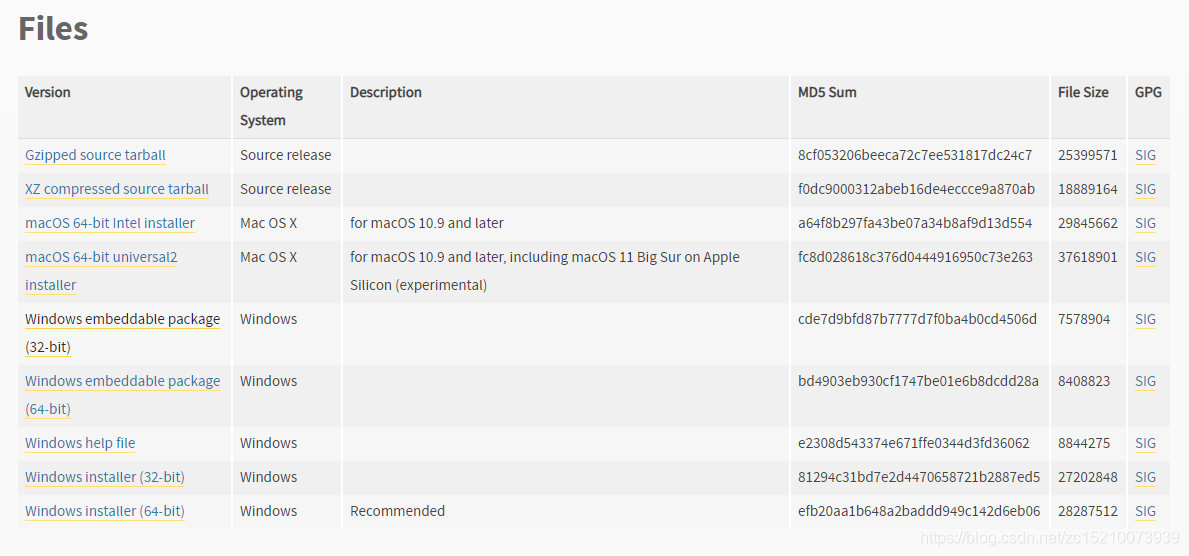
# 摘要
随着编程语言的不断进化,Python 3.9作为最新版本,引入了多项新特性和改进,旨在提升编程效率和代码的可读性。本文首先概述了Python 3.
金蝶K3凭证接口安全机制详解:保障数据传输安全无忧
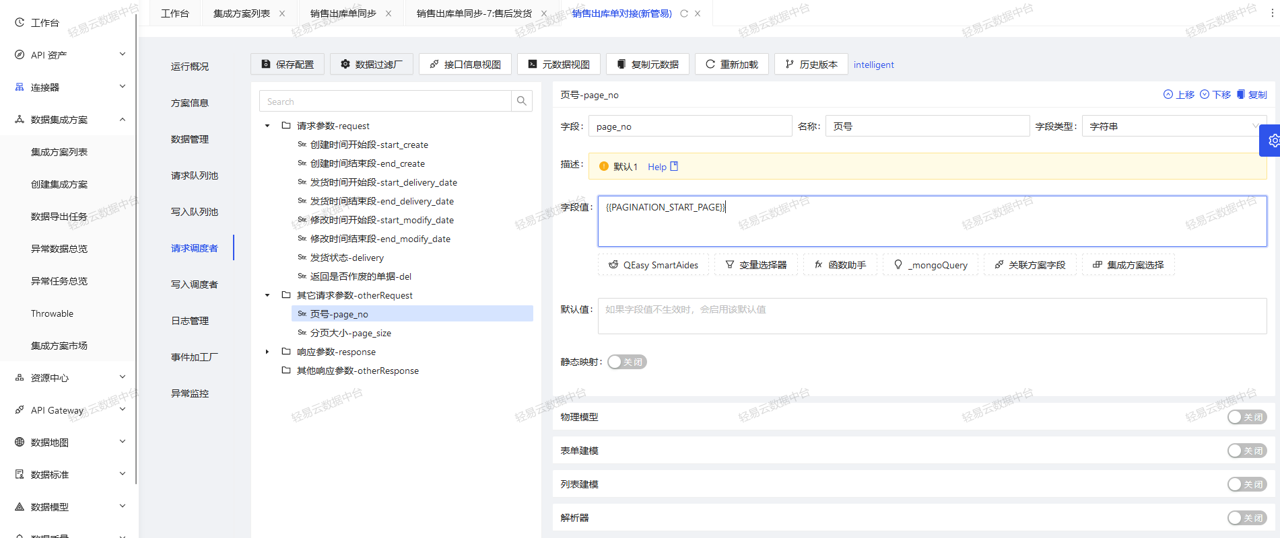
# 摘要
金蝶K3凭证接口作为企业资源规划系统中数据交换的关键组件,其安全性能直接影响到整个系统的数据安全和业务连续性。本文系统阐述了金蝶K3凭证接口的安全理论基础,包括安全需求分析、加密技术原理及其在金蝶K3中的应用。通过实战配置和安全验证的实践介绍,本文进一步阐释了接口安全配置的步骤、用户身份验证和审计日志的实施方法。案例分析突出了在安全加固中的具体威胁识别和解决策略,以及安全优化对业务性能的影响。最后
【C++ Builder 6.0 多线程编程】:性能提升的黄金法则
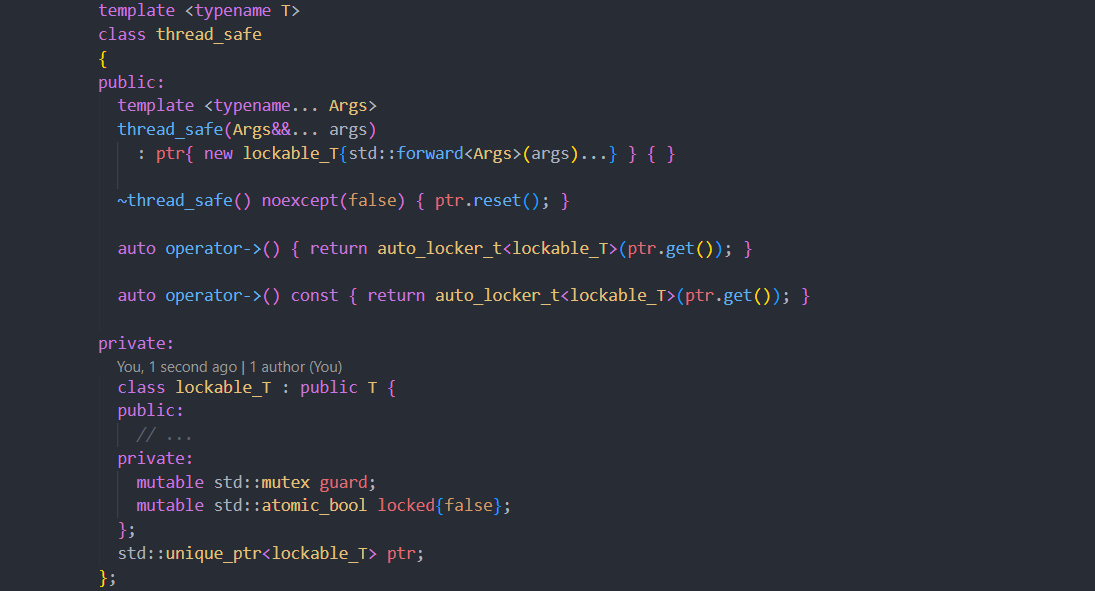
# 摘要
随着计算机技术的进步,多线程编程已成为软件开发中的重要组成部分,尤其是在提高应用程序性能和响应能力方面。C++ Builder 6.0作为开发工具,提供了丰富的多线程编程支持。本文首先概述了多线程编程的基础知识以及C++ Builder 6.0的相关特性,然后深入探讨了该环境下线程的创建、管理、同步机制和异常处理。接着,文章提供了多线程实战技巧,包括数据共享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )