dmp文件导入Oracle数据库自动化脚本:提升导入效率,解放人力
发布时间: 2024-08-03 13:40:32 阅读量: 40 订阅数: 38 

oracle 数据库导入导出脚本文件

# 1. Oracle数据库DMP文件导入概述
Oracle数据库的数据泵导出(Data Pump Export)功能可以将数据库中的数据和结构导出为一个二进制格式的文件,称为DMP文件。DMP文件可以用来在不同的数据库实例之间传输数据,或者作为数据备份和恢复的手段。
DMP文件导入过程涉及使用SQL*Loader工具,它是一个功能强大的数据加载工具,可以将数据从各种格式的文件加载到Oracle数据库中。SQL*Loader提供了丰富的参数和选项,允许用户控制导入过程的各个方面,包括数据转换、错误处理和性能优化。
# 2. DMP文件导入自动化脚本的理论基础
### 2.1 DMP文件格式及导入原理
DMP文件是Oracle数据库数据泵导出工具(expdp)生成的二进制文件,它包含了数据库中指定对象的元数据和数据。DMP文件格式由以下部分组成:
- **文件头:**包含文件版本、导出时间和数据库信息。
- **元数据部分:**包含导出对象的表结构、约束、索引和触发器等元数据信息。
- **数据部分:**包含导出对象的数据记录。
DMP文件导入原理是使用Oracle数据库数据泵导入工具(impdp)将DMP文件中的数据和元数据导入到目标数据库中。impdp工具会根据DMP文件中的元数据信息创建或更新目标数据库中的对象,并导入数据记录。
### 2.2 SQL*Loader工具的使用
SQL*Loader是Oracle数据库中用于快速加载大批量数据的工具。它可以从各种数据源(如文件、管道、数据库表)加载数据到目标表中。SQL*Loader通过解析控制文件(CTL文件)来确定加载数据的规则,包括源数据格式、目标表结构和加载选项。
在DMP文件导入自动化脚本中,SQL*Loader工具通常用于将DMP文件中的数据导入到目标表中。通过配置CTL文件,可以指定数据加载的各种选项,例如:
- **数据格式:**指定DMP文件中的数据格式,如字段分隔符、行终止符等。
- **目标表:**指定要导入数据的目标表。
- **加载选项:**指定加载数据的选项,如是否忽略错误、是否截断目标表等。
**代码块:**
```sql
LOAD DATA
INFILE 'path/to/dmp_file.dmp'
APPEND
INTO TABLE target_table
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
```
**逻辑分析:**
此代码块使用SQL*Loader工具将DMP文件中的数据导入到目标表`target_table`中。
* `LOAD DATA`:开始加载数据操作。
* `INFILE`:指定要加载的数据文件路径。
* `APPEND`:将数据追加到目标表中,而不是截断表。
* `INTO TABLE`:指定要导入数据的目标表。
* `FIELDS TERMINATED BY ','`:指定数据字段的分隔符为逗号。
* `OPTIONALLY ENCLOSED BY '"'`: 指定数据字段可以被双引号包围。
* `TRAILING NULLCOLS`:指定忽略尾随的空列。
**参数说明:**
- `path/to/dmp_file.dmp`:DMP文件路径。
- `target_table`:目标表名。
# 3.1 脚本框架设计与流程控制
自动化脚本的框架设计至关重要,它决定了脚本的可读性、可维

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面探讨了 dmp 文件导入 Oracle 数据库的方方面面,提供了一系列技巧、指南和最佳实践,帮助您掌握导入秘诀,提升效率。从性能优化到常见问题解答,从表空间管理到索引利用,再到数据一致性保障和事务处理详解,本专栏涵盖了导入过程中的各个关键环节。此外,还提供了并发控制策略、监控与管理技巧、自动化脚本、跨平台迁移最佳实践、大数据处理挑战、云端实践指南、容器化部署方案、DevOps 实践和人工智能应用探索等内容,帮助您应对各种导入场景,提升导入效率,确保数据完整性,并满足现代化需求。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘QPSK:从基础到性能优化的全指南(附案例分析)
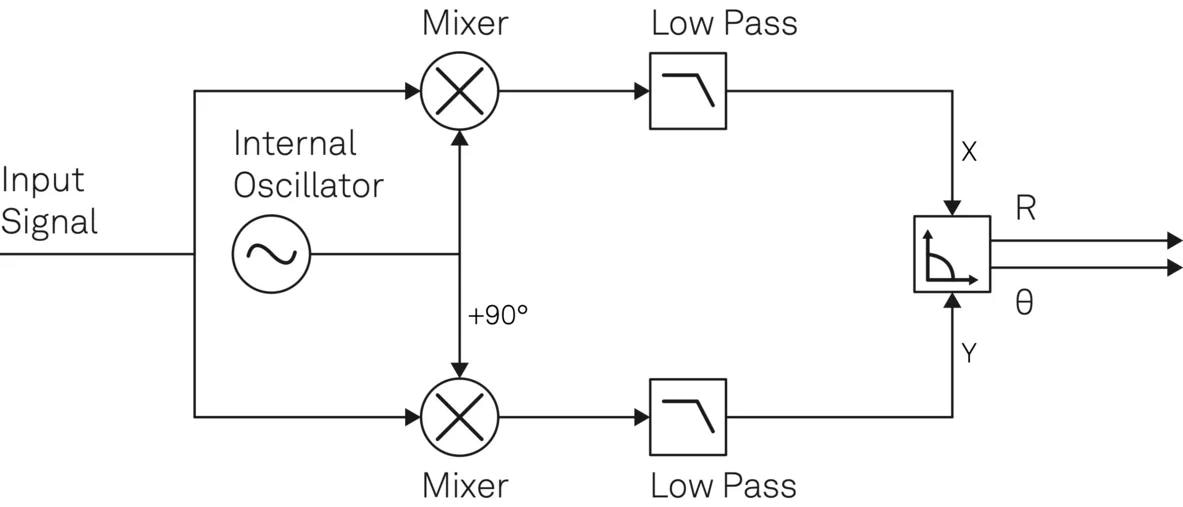
# 摘要
QPSK(Quadrature Phase Shift Keying)调制是一种广泛应用于数字通信系统中的调制技术,它通过改变载波的相位来传输数字信息,具备较高的频谱效率和传输速率。本文从基本原理入手,深入分析了QPSK信号的构成、特点及与其它调制技术的比较,并探讨了其数学模型和在不同通信系统中的实现方法。通过理论性能分
剪映中的音频处理
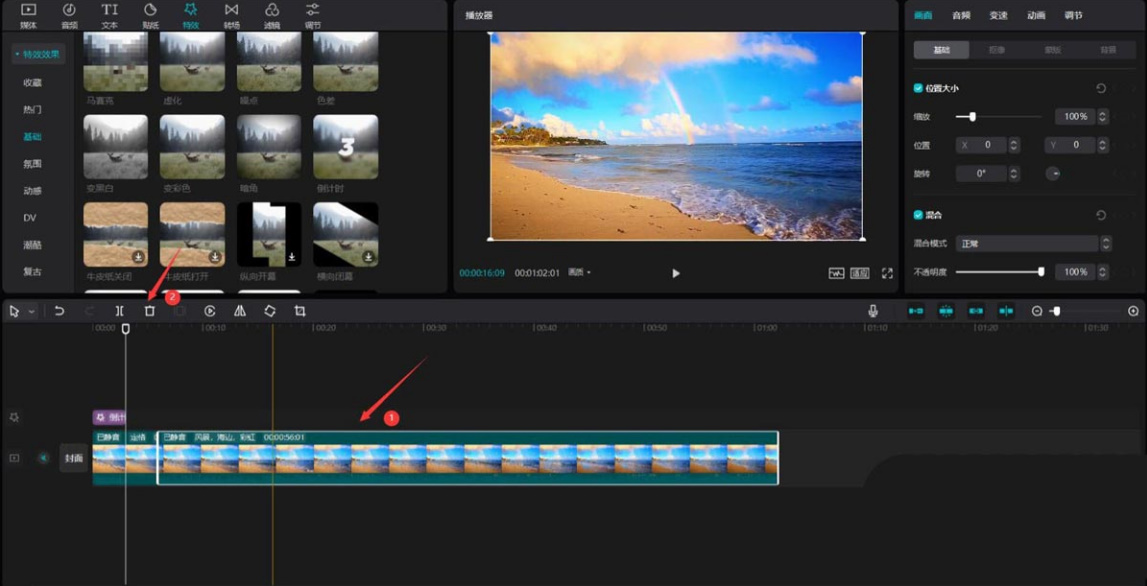
# 摘要
本文详细探讨了剪映软件中音频处理的理论与实践技巧。首先介绍了剪映中音频处理的基础知识和理论基础,包括音频的数字信号处理、音频文件格式以及音频处理的术语如采样率、位深度、频率响应和动态范围。接着,文章深入讲解了剪映音频编辑中的基本剪辑操作、音效应用、降噪与回声消除等技巧。进阶技巧部分,探讨了音频自动化的应用、创意音频设计以及音频问题的诊断与修复。最后,通过具体的应用案例分析了如何在剪映中创建声音背景、处理人声配音以
【ABAP与JSON交互的优化策略】:提高数据处理效率的字段名映射方法
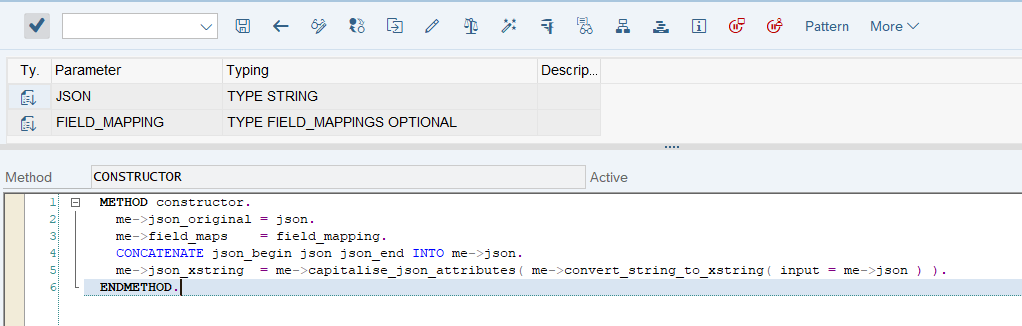
# 摘要
本文旨在介绍ABAP与JSON之间的交互机制,探讨JSON数据结构与ABAP数据类型之间的映射方法,并提供字段名映射的实现技术与应用策略。文章深入分析了基础数据结构,阐述了字段名映射的理论基础、实现原理以及性能优化策略。此外,本文还探讨了高级数据处理技术、交互性能提升和自动化集成的策略,通过案例分析分享最佳实践,为ABAP开发者提供了一个全面的JSON交互指南。
# 关键字
ABAP;J
中控标Access3.5新手必读:一步步带你安装及配置门禁系统

# 摘要
本文全面介绍了门禁系统的基础知识、中控标Access3.5的安装与配置流程,以及日常管理与维护的方法。首先,概述了门禁系统的基础知识,为读者提供了必要的背景信息。接着,详细阐述了中控标Access3.5的安装步骤,包括系统需求分析、安装前准备以及安装过程中的关键操作和常见问题解决方案。之后,文章深入讲解了系统配置指南,涵盖了数据库配置、
【rockusb.inf解码】:10个常见错误及其解决方案

# 摘要
本文围绕rockusb.inf文件的概述、错误诊断、检测与修复、案例剖析以及预防与维护进行了系统性的探讨。首先介绍了rockusb.inf文件的基本功能和结构,然后深入分析了语法错误、配置错误和系统兼容性问题等常见错误类型。通过详细阐述错误
Rsoft仿真网格划分技术:理论+操作=专家级指南
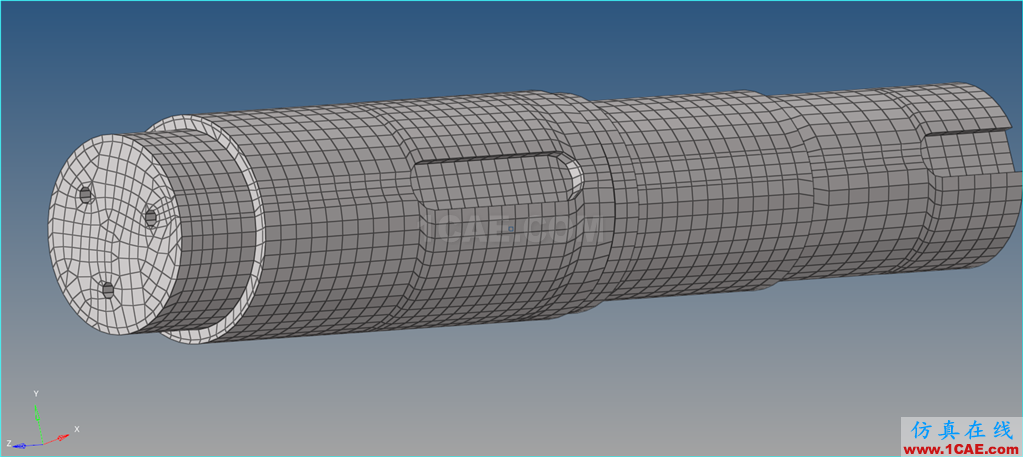
# 摘要
随着计算仿真的发展,网格划分技术作为其中的关键环节,其准确性和效率直接影响仿真结果的质量和应用范围。本文对Rsoft仿真软件中的网格划分技术进行了全面概述,从基础理论到操作实践,再到高级应用和优化技巧,进行了系统的探讨。通过对网格划分的数学基础、技术原理及质量评估进行深入分析,文章进一步展示了如何在Rsoft软件中进行有效的网格划分操作,并结合行业案例,探讨了网格划分在半导体和生物医疗行业中的实
电力系统继电保护仿真深度剖析:ETAP软件应用全攻略
# 摘要
本文旨在详细介绍电力系统继电保护的基础知识、ETAP软件的操作与仿真分析实践,以及继电保护的优化和高级仿真案例研究。首先,概述了电力系统继电保护的基本原理和重要性。接着,对ETAP软件的界面布局、设备建模和仿真功能进行了详细介绍,强调了其在电力系统设计与分析中的实用性和灵活性。在继电保护仿真分析实践章节中,本文阐述了设置仿真、运行分析以及系统优化
高级数据结构深度解析:和积算法的现代应用
# 摘要
本文系统介绍了和积算法的基本概念、理论框架以及其在数据分析和机器学习中的应用。首先,概述了和积算法的起源和核心数学原理,随后探讨了该算法的优化策略,包括时间和空间复杂度的分析,并举例展示了优化实践。接着,文章详细阐述了和积算法在数据预处理、复杂数据集处理和模式识别中的具体应用。在机器学习领域,本文对比了和积算法与传统算法,探讨了它与深度学习的结合
台湾新代数控API接口初探:0基础快速掌握数控数据采集要点

# 摘要
本文旨在深入解析台湾新代数控API接口的理论与实践应用。首先介绍了数控API接口的基本概念、作用以及其在数控系统中的重要性。接着,文章详细阐述了数控API接口的通信协议、数据采集与处理的相关理论知识,为实践操作打下坚实的理论基础。随后,文章通过实践前的准备、数据采集代码实现以及数据处理与存储三个方面,分享了数据采集实践的具体步骤与技巧。进一步地,文章探讨了数
FANUC外部轴性能优化:揭秘配置技巧,提升加工精度

# 摘要
本文系统介绍了FANUC外部轴的基础知识、配置理论、性能优化实践、编程应用以及加工效率提升方法,并展望了外部轴技术的发展趋势。通过对外部轴的类型与功能进行阐述,详细分析了其在加工中心的应用及控制系统。进一步,本文探讨了同步控制机制以及性能优化的技巧,包括精度提升、动态性能调优和故障诊断策略。文章还针对外部轴编程进行了深入
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )