【Python EasyOCR库入门教程】:从零开始掌握OCR识别技术
发布时间: 2024-11-14 05:29:35 阅读量: 25 订阅数: 17 
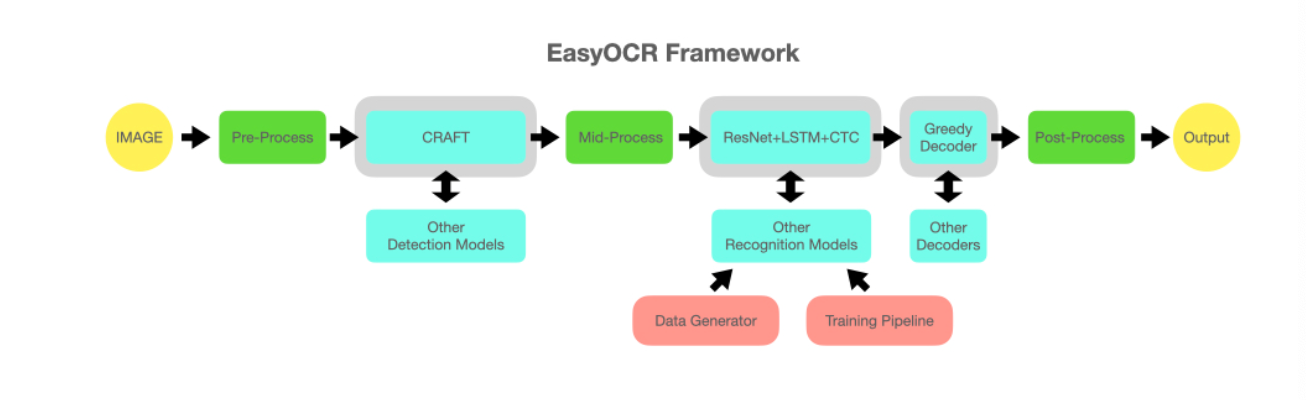
# 1. Python EasyOCR库简介
## 1.1 简介EasyOCR及其应用领域
EasyOCR是一个开源的光学字符识别(Optical Character Recognition, OCR)库,能够识别多种语言的文字,由韩国开发者Jonghwan Mun发起。它的特色是易于集成与使用,而且对中文、韩文等亚洲语言支持较好。该库常应用于自动化文本抽取,例如从图片或扫描文档中提取文字,对于处理多语言文本特别有效。
## 1.2 EasyOCR的构建基础
EasyOCR背后使用了深度学习模型,并且利用了预训练权重,这意味着无需从零开始训练模型。同时,该库采用Python编写,具有良好的跨平台兼容性,可以通过pip轻松安装。它也支持Windows、Linux和macOS操作系统,非常适合那些对OCR技术有即时需求的开发者。
## 1.3 EasyOCR的潜力和市场应用
由于EasyOCR的简单易用和高效处理能力,它非常适合于各种需求,从简单的文字提取到复杂的文档分析都有它的身影。在图像识别领域,EasyOCR已成为一种强大工具,尤其在数据挖掘、自动化办公、在线教育以及内容管理系统(CMS)中,它的应用正日益广泛。由于其轻量级的特性,它甚至可以在没有强大计算资源的设备上运行,如移动设备和嵌入式系统。
# 2. Python EasyOCR库基础应用
## 2.1 安装和配置EasyOCR环境
### 2.1.1 Python环境的搭建
在开始使用EasyOCR之前,需要确保你的系统中安装了Python。EasyOCR支持Python 3.6及以上版本。如果你尚未安装Python,可以从官方网站下载安装程序,并根据操作系统选择相应的安装包。
```bash
# 检查Python版本
python --version
```
在安装过程中,建议选择“Add Python to PATH”选项,这样可以在命令行中直接调用Python解释器。安装完成后,在命令行窗口中运行上述命令,确认Python已正确安装。
### 2.1.2 EasyOCR库的安装和导入
安装完Python环境后,接下来需要安装EasyOCR库。EasyOCR库可以使用pip包管理器进行安装,简单快捷。在命令行中输入以下命令进行安装:
```bash
pip install easyocr
```
安装完成后,可以在Python脚本中导入EasyOCR库,开始进行文字识别操作:
```python
import easyocr
# 创建Reader对象,指定要识别的语言
reader = easyocr.Reader(['en']) # 'en'代表英文
# 使用reader对象识别图片中的文字
result = reader.readtext('path/to/your/image.jpg')
# 打印识别结果
print(result)
```
上述代码创建了一个EasyOCR的Reader对象,并指定识别语言为英文。然后,使用readtext方法读取指定路径图片中的文字,并将识别结果存储在result变量中。
## 2.2 EasyOCR库的基本功能
### 2.2.1 文字识别流程概述
EasyOCR的文字识别流程大体可以分为三个步骤:图像加载、文字识别和结果输出。
首先,需要加载需要识别的图像文件。这个步骤可以通过OpenCV、Pillow库或者直接使用Python的图像IO接口完成。
其次,是调用EasyOCR库的识别函数进行文字识别。这一过程中,EasyOCR会利用其训练有素的OCR模型对图像中的文字进行定位、分割和识别。
最后,EasyOCR会返回一个包含识别结果的列表,每个结果是一个元组,包含识别出的文字、边界框坐标和置信度。
### 2.2.2 支持的语言和字体类型
EasyOCR支持多种语言的文字识别,并且持续更新,支持的语言列表可以在其GitHub仓库的README文件中找到。此外,EasyOCR对字体类型具有一定的适应性,能够处理多种不同风格和类型的字体。
若需要识别非英文文本,如中文或日文,需要在创建Reader对象时指定对应的语言代码:
```python
reader = easyocr.Reader(['ch_sim', 'en']) # 'ch_sim'代表简体中文
```
## 2.3 使用EasyOCR进行简单文字识别
### 2.3.1 图片中文字的识别
使用EasyOCR进行图片中文字识别非常简单。首先,需要准备一张含有文字的图片文件。在Python脚本中,使用Reader对象的readtext方法,将图片路径作为参数传入。
```python
# 使用readtext方法识别图片中的文字
result = reader.readtext('path/to/your/image.jpg')
```
readtext方法返回一个列表,列表中的每一个元素代表一行文字的识别结果。每个元素是一个三元组,包含识别出的文字、该文字的边界框坐标和置信度。
### 2.3.2 结果的获取和格式化
识别出的文字和对应的边界框坐标、置信度存储在result变量中。可以通过遍历result列表,对结果进行进一步的处理和格式化。
```python
# 遍历识别结果并打印
for (bbox, text, prob) in result:
print(f"Detected text: '{text}' with confidence {prob:.4f} at position {bbox}")
```
在上述代码中,对result列表进行遍历,每个元素是一个三元组,分别表示边界框坐标、识别出的文字和置信度。通过格式化字符串的方式,将识别结果以可读的格式输出。
以上是Python EasyOCR库的基础应用章节。对于初学者,上述内容旨在提供一个简明易懂的入门指南,帮助他们了解如何安装和配置EasyOCR,以及如何进行简单的文字识别任务。在接下来的章节中,我们将深入探索EasyOCR库在界面和Web应用中的集成,高级图像处理技巧,以及如何优化识别准确率和性能等进阶应用。
# 3. Python EasyOCR库实战演练
在前一章中,我们探索了Python EasyOCR库的基础知识和基本功能。接下来,我们将进入实战演练环节,深入应用EasyOCR库到实际项目中。这一章节将引导读者通过构建界面、集成到Web应用、图像预处理和性能优化等步骤,来实现更为复杂和高级的文字识别任务。
## 3.1 界面和Web应用集成EasyOCR
### 3.1.1 构建基本GUI界面
为了实现易用性和可视化,我们首先需要构建一个基本的图形用户界面(GUI)。Python中,我们可以利用Tkinter或PyQt等库来创建GUI。在本章节,我们选择Tkinter因为它简单易用,并且是Python标准库的一部分。
下面是一个简单的Tkinter界面,用于加载图片并显示识别结果。
```python
import tkinter as tk
from tkinter import filedialog
from easyocr import Reader
def open_image():
file_path = filedialog.askopenfilename()
if not file_path:
return
reader = Reader(['en']) # 使用英文模型进行识别
result = reader.readtext(file_path)
image = tk.PhotoImage(file=file_path)
tkimage_label.config(image=image)
tkimage_label.image = image
text_label.config(text='\n'.join([str(r) for r in result]))
root = tk.Tk()
root.title("EasyOCR GUI App")
tkimage_label = tk.Label()
tkimage_label.pack()
load_button = tk.Button(text="Load Image", command=open_image)
load_button.pack()
text_label = tk.Label()
text_label.pack()
root.mainloop()
```
在上述代码中,我们创建了一个基本的窗口,其中包含了一个用于显示图片的`tk.Label`组件和一个按钮用于加载图片。点击按钮后,会弹出文件对话框,并使用EasyOCR进行文字识别。识别结果显示在下方的`text_label`标签中。
### 3.1.2 集成EasyOCR实现文字识别
我们将在此节中讨论如何将EasyOCR集成到Web应用中。在Web中集成OCR功能,可以使用Django或Flask等Python Web框架。对于这个示例,我们将使用Flask,因为它轻量级且易于设置。
我们先创建一个基本的Flask应用,并集成EasyOCR来处理上传的图片并返回识别的文字。
```python
from flask import Flask, request, render_template
from easyocr import Reader
app = Flask(__name__)
reader = Reader(['en']) # 初始化EasyOCR读取器
@app.route('/')
def index():
return render_template('index.html')
@app.route('/upload', methods=['POST'])
def upload_file():
f = request.files['file']
if f:
content = f.read()
file_path = 'uploads/' + f.filename
with open(file_path, 'wb') as pic:
pic.write(content)
result = reader.readtext(file_path)
return result
return 'No image uploaded'
if __name__ == '__main__':
app.run(debug=True)
```
在`index.html`中,我们需要一个文件上传的表单:
```html
<!DOCTYPE html>
<html>
<head>
<title>EasyOCR Web App</title>
</head>
<body>
<h1>Upload an image</h1>
<form method="post" action="/upload" enctype="multipart/form-data">
<input type="file" name="file">
<input type="submit" value="Upload">
</form>
</body>
</html>
```
上述代码展示了创建一个简单的Web界面,并能够上传文件到服务器。服务器端将调用EasyOCR对图片进行文字识别,并返回识别结果。
## 3.2 高级图像处理和预处理技巧
### 3.2.1 图像预处理的作用和方法
图像预处理是OCR过程中至关重要的一步。预处理的目的是改善图片质量,使文字更加清晰,从而提高OCR的识别准确率。常见的图像预处理包括灰度化、二值化、去噪、旋转校正和对比度增强等。
在本节中,我们将介绍如何在Python中使用OpenCV库进行图像预处理。
```python
import cv2
import numpy as np
def preprocess_image(image_path):
# 读取图像
img = cv2.imread(image_path)
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊去噪
blur = cv2.GaussianBlur(gray, (3, 3), 0)
# 使用自适应阈值进行二值化
binary = cv2.adaptiveThreshold(
blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
return binary
```
### 3.2.2 针对不同场景的图像预处理实践
不同场景下图像的特征不同,因此预处理的方法也需要进行调整。例如,在处理低分辨率或有重影的文字图像时,可能需要使用不同的滤波器。下面是一个针对文档扫描图像的预处理流程。
```python
def preprocess_scanned_document(image_path):
img = cv2.imread(image_path)
# 去除背景色,例如去除蓝色背景
blue_channel = cv2.split(img)[0]
_, binary = cv2.threshold(blue_channel, 150, 255, cv2.THRESH_BINARY)
# 反转二值化结果
inverse_binary = 255 - binary
# 恢复颜色通道并保存
inverse_binary = np.stack((inverse_binary,) * 3, axis=-1)
cv2.imwrite('processed_image.png', inverse_binary)
return 'processed_image.png'
```
## 3.3 优化识别准确率和性能
### 3.3.1 识别参数的调整和优化
EasyOCR库提供了多种参数来调整识别的过程,从而优化识别的准确性和性能。识别参数包括但不限于,识别器的语言、字符集、方向等。我们可以通过调整这些参数来优化OCR识别的效果。
```python
reader = Reader(['en'], gpu=False, allowedLanguages=['en', 'fr'])
result = reader.readtext(image_path, detail=0)
```
在上述代码中,我们创建了一个支持英语和法语的识别器。我们关闭了GPU加速,因为这可能不是在所有情况下都可用。同时我们指定了仅识别英语和法语。
### 3.3.2 性能提升的策略和技巧
除了直接调整识别参数之外,还有一些通用的性能提升策略。例如,我们可以通过批量处理或异步处理来提高处理效率。这可以通过多线程或多进程来实现,特别是在处理大量的图像识别任务时。
下面展示了如何在Python中使用多线程来提升处理性能。
```python
import threading
from queue import Queue
def worker(input_queue: Queue, output_queue: Queue):
while not input_queue.empty():
img_path = input_queue.get()
result = preprocess_image(img_path)
output_queue.put(result)
input_queue.task_done()
def parallel_processing(image_paths):
input_queue = Queue()
output_queue = Queue()
# 将图片路径加入队列
for img_path in image_paths:
input_queue.put(img_path)
# 启动多个工作线程
num_worker_threads = 4
for _ in range(num_worker_threads):
t = threading.Thread(target=worker, args=(input_queue, output_queue))
t.daemon = True
t.start()
# 等待所有任务完成
input_queue.join()
# 拿到结果
results = []
while not output_queue.empty():
result = output_queue.get()
results.append(result)
return results
```
在上述代码中,我们定义了一个工作函数`worker`,该函数负责从队列中获取图片路径,进行预处理并将其结果放入输出队列。主函数中,我们启动了多个线程来执行这个工作函数,以实现并行处理。
在本章节,我们学习了如何将EasyOCR集成到界面和Web应用中,同时深入探讨了图像预处理的技巧和优化识别准确率的方法。下一章节将带领我们进入EasyOCR的进阶应用,展示如何实现多语言识别与翻译,以及如何结合深度学习进一步提升识别能力。
# 4. Python EasyOCR库进阶应用
进阶应用章节主要探讨如何使用EasyOCR进行更复杂的操作,如多语言文字识别、结合深度学习优化识别等。本章将带领读者从基础应用逐步过渡到高级技术,并提供实际项目构建的全面指导。
## 4.1 多语言文字识别与翻译
在国际化应用中,处理多种语言是常见需求。EasyOCR不仅支持多种语言的文字识别,还能通过集成翻译功能,实现对识别结果的多语言理解。
### 4.1.1 多语言设置与应用
EasyOCR通过一个简单的语言设置,即可支持多种语言的识别。代码示例如下:
```python
import easyocr
# 创建一个识别器实例,同时支持英语(eng)和中文(zho)
reader = easyocr.Reader(['eng', 'zho'])
# 使用识别器实例来识别图像中的文字
result = reader.readtext('example.jpg')
```
语言设置支持几乎所有的ISO语言代码,这意味着你可以为你的应用增加全球语言支持。
### 4.1.2 集成翻译功能实现多语言理解
EasyOCR集成了翻译功能,允许用户在识别出文字后立即进行翻译。以下代码展示了如何实现这一过程:
```python
import easyocr
reader = easyocr.Reader(['eng', 'zho'])
result = reader.readtext('example.jpg')
# 将识别结果中的英文翻译为中文
from googletrans import Translator
translator = Translator()
for (bbox, text, prob) in result:
translated_text = translator.translate(text, src='en', dest='zh-cn').text
print(f"原文: {text}, 翻译: {translated_text}")
```
在实际应用中,翻译模块可以选用任何可用的翻译API进行扩展,从而实现更为灵活的多语言处理。
## 4.2 结合深度学习优化识别
EasyOCR已经内置了对深度学习的支持,但在某些特定的应用场景中,我们可能需要进一步优化识别准确率。
### 4.2.1 深度学习模型的选择和应用
为了优化识别准确率,我们可以选择更强大的深度学习模型。EasyOCR支持多种模型,这里以一个示例展示如何选择模型:
```python
import easyocr
# 选择一个预先训练好的模型
model = 'en'
reader = easyocr.Reader(['en'], model_storage_directory='models/')
result = reader.readtext('example.jpg')
```
模型存储目录需要提前放置好下载好的模型文件。
### 4.2.2 EasyOCR与深度学习框架整合示例
为了实现更深层次的定制化,EasyOCR还可以与深度学习框架,如PyTorch和TensorFlow整合。以下是整合PyTorch的一个示例:
```python
import torch
import easyocr
from easyocr import torchocr
# 加载预训练模型
model = torchocr.PytorchModel(language='en', gpu=False)
# 使用模型进行文字识别
result = model.recognize('example.jpg')
print(result)
```
通过整合不同的深度学习框架,我们可以利用EasyOCR的OCR功能,并结合深度学习模型的力量,进一步提升识别性能和准确性。
## 4.3 创建复杂的OCR应用项目
复杂的OCR应用项目可能需要定制化的流程和处理逻辑。理解如何构建这样的系统是进阶应用中的一项重要技能。
### 4.3.1 项目需求分析和设计
在设计一个OCR系统时,首先要对需求进行分析,确定系统需要处理的文档类型、识别精度、支持的语言、处理速度等关键因素。设计阶段则需要绘制出流程图,并确定使用的技术栈。
下面是一个简单的流程图,描述了一个OCR系统的处理流程:
```mermaid
graph LR
A[开始] --> B[图像输入]
B --> C[图像预处理]
C --> D[文字区域定位]
D --> E[文字识别]
E --> F[结果后处理]
F --> G[输出]
```
### 4.3.2 构建完整的OCR系统流程
构建OCR系统通常涉及多个步骤,下面是一个简化的示例流程,它涵盖了从图像输入到输出处理的各个方面。
```python
import easyocr
from PIL import Image
def ocr_system(image_path):
# 1. 图像预处理
image = Image.open(image_path).convert('RGB')
image = preprocess_image(image) # 假设这是一个预处理函数
# 2. 文字区域定位和识别
reader = easyocr.Reader(['eng'])
result = reader.readtext(image_path)
# 3. 结果后处理
formatted_result = format_result(result) # 假设这是一个格式化函数
return formatted_result
def format_result(results):
# 这里可以根据需求进行结果格式化
return [f"Text: {text}, Confidence: {prob}" for (bbox, text, prob) in results]
if __name__ == "__main__":
ocr_system("example.jpg")
```
构建完整的OCR系统是一个复杂的过程,需要对每个环节进行细化和优化,以确保整个系统的健壮性和效率。
本章为读者介绍了如何使用Python EasyOCR库进行进阶应用,包括多语言文字识别与翻译、结合深度学习优化识别,以及如何创建复杂的OCR应用项目。通过这些内容,读者能够掌握更高级的OCR技术,并能够处理更加复杂的业务场景。
# 5. Python EasyOCR库最佳实践与案例分析
在使用Python EasyOCR库进行光学字符识别(OCR)时,面对实际问题和复杂场景时,一些最佳实践和案例分析能够帮助我们更好地应用这项技术。本章节将介绍两个案例,以帮助读者理解如何解决实际问题,并介绍如何从社区获得支持以及分享个人经验。
## 5.1 解决实际问题的案例分析
### 5.1.1 手写文字识别案例
手写文字识别是一个较为复杂的场景,它不仅涉及到文字的识别,还涉及到书写风格、字迹清晰度等因素的影响。下面是一个使用EasyOCR处理手写文字识别的案例分析:
```python
import easyocr
import cv2
# 加载预训练模型
reader = easyocr.Reader(['ch_sim','en']) # 支持中文简体和英文
# 读取图像文件
image_path = 'handwritten_sample.jpg'
image = cv2.imread(image_path)
# 进行文字识别
result = reader.readtext(image)
# 输出识别结果
for (bbox, text, prob) in result:
print(f"Detected text: {text}, Confidence: {prob:.2f}")
# 可视化识别结果(可选)
for (bbox, text, prob) in result:
top_left = (bbox[0][0], bbox[0][1])
bottom_right = (bbox[2][0], bbox[2][1])
cv2.rectangle(image, top_left, bottom_right, (0,255,0), 2)
cv2.putText(image, text, top_left, cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0,255,0), 2)
cv2.imshow('Image with Text', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
在处理手写文字时,可能需要进行图像预处理,比如二值化、去噪、旋转校正等步骤,以提高识别准确率。
### 5.1.2 文档扫描识别与修正案例
文档扫描识别通常要求高准确率,因为文档中的信息可能涉及重要内容,如合同、证书等。EasyOCR可以处理这样的场景,但在识别前的图像预处理就显得尤为重要了。以下是一个文档扫描识别的案例:
```python
import easyocr
import numpy as np
from PIL import Image
# 加载预训练模型
reader = easyocr.Reader(['en'])
# 加载并预处理图像
image_path = 'scanned_document.jpg'
image = Image.open(image_path)
image = np.array(image)
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh_image = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
# 应用旋转校正等预处理步骤(示例)
# ...
# 识别图像
result = reader.readtext(thresh_image)
# 输出识别结果
for (bbox, text, prob) in result:
print(f"Detected text: {text}, Confidence: {prob:.2f}")
```
文档扫描识别的难点还在于边框和文字的校准,使用一些图像处理技术如透视变换,可以改善结果。
## 5.2 社区支持和资源分享
### 5.2.1 如何获取社区帮助和支持
当遇到难题时,EasyOCR的社区可以成为强大的后盾。社区成员可以提供技术支持和共享经验。加入社区的步骤如下:
- 访问EasyOCR的GitHub仓库页面。
- 浏览Issues区域,查看是否已有类似问题。
- 如果没有,可以创建一个新的Issue并详细描述你的问题。
- 社区成员或库的维护者可能会提供解决方案或建议。
### 5.2.2 分享个人项目和经验
分享个人项目和经验不仅可以帮助他人,也能提升个人在社区中的影响力。分享途径可能包括:
- 在GitHub上创建公开仓库,托管项目代码。
- 编写详细文档或博客,说明项目目的、应用方法及使用案例。
- 在论坛、社交媒体等平台发布项目信息,以获得反馈和建议。
在分享过程中,注重代码的可读性和文档的清晰度,这样有助于他人更好地理解和使用你的项目。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python EasyOCR 库在行程码图片 OCR 识别中的应用。从入门教程到性能优化,再到深度学习和错误处理,专栏涵盖了 OCR 技术的各个方面。此外,还提供了与其他 OCR 库的对比分析、自定义字典的创建、自动化流程的构建、安全性和数据预处理的考量,以及系统监控和技术整合的指南。通过这些内容,读者可以全面了解 Python EasyOCR 库,并掌握 OCR 识别技术的最佳实践,以实现准确、高效和安全的行程码识别。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
【提高图表信息密度】:Seaborn自定义图例与标签技巧
# 1. Seaborn图表的简介和基础应用
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,它提供了一套高级接口,用于绘制吸引人、信息丰富的统计图形。Seaborn 的设计目的是使其易于探索和理解数据集的结构,特别是对于大型数据集。它特别擅长于展示和分析多变量数据集。
## 1.1 Seaborn
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
高级概率分布分析:偏态分布与峰度的实战应用

# 1. 概率分布基础知识回顾
概率分布是统计学中的核心概念之一,它描述了一个随机变量在各种可能取值下的概率。本章将带你回顾概率分布的基础知识,为理解后续章节的偏态分布和峰度概念打下坚实的基础。
## 1.1 随机变量与概率分布
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
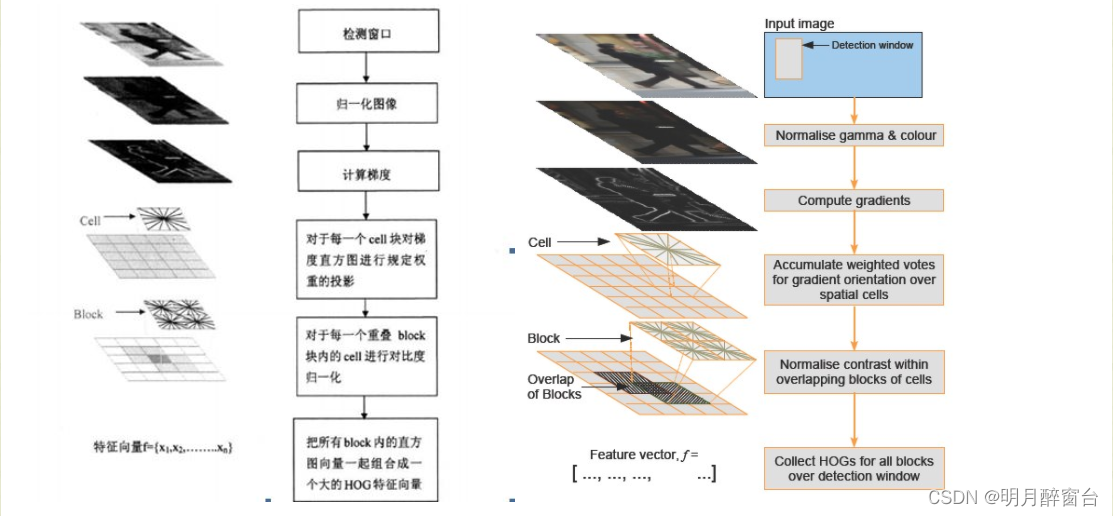
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )