【Java连接MySQL数据库指南】:从零开始建立稳定连接,避免连接问题困扰
发布时间: 2024-07-24 01:12:11 阅读量: 42 订阅数: 23 

java连接mysql数据库及测试是否连接成功的方法

# 1. Java连接MySQL数据库的基本原理**
Java与MySQL数据库的连接建立在JDBC(Java Database Connectivity)的基础之上。JDBC是一套Java API,它提供了与各种数据库进行交互的统一接口。通过JDBC,Java应用程序可以访问MySQL数据库中的数据,执行查询和更新操作。
JDBC连接过程涉及以下步骤:
1. 加载JDBC驱动程序:应用程序需要加载MySQL的JDBC驱动程序,以便与MySQL数据库建立通信。
2. 创建连接对象:使用`DriverManager`类创建`Connection`对象,该对象代表与MySQL数据库的连接。
3. 执行查询或更新:通过`Statement`或`PreparedStatement`对象执行SQL查询或更新操作。
4. 处理结果集:如果执行的是查询操作,则需要处理返回的结果集,从中获取数据。
5. 关闭连接:使用完毕后,必须关闭连接以释放资源。
# 2. 建立Java与MySQL数据库的连接
### 2.1 连接字符串的组成和配置
连接字符串是建立Java与MySQL数据库连接的关键。它包含了连接数据库所需的所有信息,包括:
- **数据库URL:**指定数据库的类型、主机名、端口号和数据库名。
- **用户名:**连接数据库的用户名。
- **密码:**连接数据库的密码。
连接字符串的格式如下:
```java
jdbc:mysql://[主机名]:[端口号]/[数据库名]
```
例如:
```java
jdbc:mysql://localhost:3306/test
```
### 2.2 不同连接方式的优缺点
Java与MySQL数据库的连接方式有多种,每种方式都有其优缺点:
| 连接方式 | 优点 | 缺点 |
|---|---|---|
| DriverManager | 简单易用 | 连接池管理复杂 |
| DataSource | 连接池管理方便 | 依赖于第三方库 |
| JNDI | 统一管理连接池 | 配置复杂 |
### 2.3 连接池的应用和配置
连接池是一种优化数据库连接管理的机制。它通过预先创建和维护一定数量的数据库连接,避免了每次连接数据库都要重新建立连接的开销。
连接池的配置主要包括以下几个方面:
- **最大连接数:**连接池中最大可创建的连接数。
- **最小连接数:**连接池中最小可创建的连接数。
- **空闲连接超时时间:**连接池中空闲连接的超时时间。
- **最大等待时间:**获取连接时最大等待时间。
连接池的配置需要根据实际情况进行调整,以达到最佳性能和资源利用率。
**代码示例:**
```java
// 创建连接池
DataSource dataSource = new BasicDataSource();
// 设置连接池配置
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("password");
dataSource.setMaxActive(10);
dataSource.setMinIdle(5);
dataSource.setMaxWait(1000);
// 获取连接
Connection connection = dataSource.getConnection();
```
**逻辑分析:**
该代码示例创建了一个连接池,并设置了连接池的配置。然后,通过连接池获取了一个数据库连接。
# 3.1 CRUD操作的实现
**创建(Create)**
```java
// 准备 SQL 语句
String sql = "INSERT INTO users (name, email, password) VALUES (?, ?, ?)";
// 创建 PreparedStatement 对象
PreparedStatement statement = connection.prepareStatement(sql);
// 设置参数值
statement.setString(1, "John Doe");
statement.setString(2, "john.doe@example.com");
statement.setString(3, "password123");
// 执行更新操作
int rowCount = statement.executeUpdate();
// 检查是否成功插入数据
if (rowCount > 0) {
System.out.println("数据插入成功!");
} else {
System.out.println("数据插入失败!");
}
```
**逻辑分析:**
* 使用 PreparedStatement 对象来防止 SQL 注入攻击。
* 使用 setString 方法设置参数值,防止类型转换错误。
* 使用 executeUpdate 方法执行更新操作,并返回受影响的行数。
**读取(Read)**
```java
// 准备 SQL 语句
String sql = "SELECT * FROM users WHERE id = ?";
// 创建 PreparedStatement 对象
PreparedStatement statement = connection.prepareStatement(sql);
// 设置参数值
statement.setInt(1, 1);
// 执行查询操作
ResultSet resultSet = statement.executeQuery();
// 遍历结果集
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String email = resultSet.getString("email");
System.out.println(String.format("ID: %d, Name: %s, Email: %s", id, name, email));
}
```
**逻辑分析:**
* 使用 PreparedStatement 对象来防止 SQL 注入攻击。
* 使用 setInt 方法设置参数值,防止类型转换错误。
* 使用 executeQuery 方法执行查询操作,并返回一个 ResultSet 对象。
* 使用 while 循环遍历结果集,并获取每一行的值。
**更新(Update)**
```java
// 准备 SQL 语句
String sql = "UPDATE users SET name = ? WHERE id = ?";
// 创建 PreparedStatement 对象
PreparedStatement statement = connection.prepareStatement(sql);
// 设置参数值
statement.setString(1, "Jane Doe");
statement.setInt(2, 1);
// 执行更新操作
int rowCount = statement.executeUpdate();
// 检查是否成功更新数据
if (rowCount > 0) {
System.out.println("数据更新成功!");
} else {
System.out.println("数据更新失败!");
}
```
**逻辑分析:**
* 使用 PreparedStatement 对象来防止 SQL 注入攻击。
* 使用 setString 和 setInt 方法设置参数值,防止类型转换错误。
* 使用 executeUpdate 方法执行更新操作,并返回受影响的行数。
**删除(Delete)**
```java
// 准备 SQL 语句
String sql = "DELETE FROM users WHERE id = ?";
// 创建 PreparedStatement 对象
PreparedStatement statement = connection.prepareStatement(sql);
// 设置参数值
statement.setInt(1, 1);
// 执行更新操作
int rowCount = statement.executeUpdate();
// 检查是否成功删除数据
if (rowCount > 0) {
System.out.println("数据删除成功!");
} else {
System.out.println("数据删除失败!");
}
```
**逻辑分析:**
* 使用 PreparedStatement 对象来防止 SQL 注入攻击。
* 使用 setInt 方法设置参数值,防止类型转换错误。
* 使用 executeUpdate 方法执行更新操作,并返回受影响的行数。
# 4. Java连接MySQL数据库的常见问题
### 4.1 连接超时和重试机制
在Java连接MySQL数据库时,可能会遇到连接超时的问题。这通常是由于网络延迟、服务器负载过高或防火墙配置不当造成的。为了解决此问题,可以采取以下措施:
- **调整连接超时设置:**在连接字符串中设置connectTimeout和socketTimeout参数,以指定连接和读取操作的超时时间。
- **使用重试机制:**在连接失败时,使用重试机制自动重试连接。可以使用ExponentialBackoffRetry或FixedBackoffRetry等重试策略。
- **优化网络连接:**检查网络连接是否稳定,是否存在延迟或丢包问题。如果可能,使用更快的网络连接或优化路由。
### 4.2 SQL注入攻击的预防和处理
SQL注入攻击是一种常见的安全漏洞,它允许攻击者通过注入恶意SQL语句来访问或修改数据库数据。为了预防SQL注入攻击,可以采取以下措施:
- **使用预编译语句:**使用PreparedStatement或CallableStatement来执行SQL语句,并使用占位符(?)来替换动态参数。这可以防止SQL注入攻击,因为占位符将被正确地转义和执行。
- **对用户输入进行验证:**在执行SQL语句之前,对用户输入进行验证,以确保其不包含恶意字符或SQL关键字。
- **使用安全框架:**使用如OWASP ESAPI或Apache Commons Validator等安全框架,它们提供防止SQL注入攻击的工具和功能。
### 4.3 连接泄露和资源释放
连接泄露是指在不再需要连接时,未正确关闭连接。这会导致数据库连接池耗尽,并可能导致性能问题。为了防止连接泄露,可以采取以下措施:
- **使用try-with-resources语句:**使用try-with-resources语句自动关闭连接。这确保在try块执行完成后,无论是否发生异常,都会关闭连接。
- **使用连接池:**使用连接池管理数据库连接。连接池会自动管理连接,并确保在不再需要时释放连接。
- **定期清理连接:**定期清理未使用的连接,以防止连接泄露。可以使用连接池的清理机制或手动关闭未使用的连接。
# 5. Java连接MySQL数据库的性能优化
### 5.1 连接池的调优和优化
连接池是提高Java应用程序与MySQL数据库连接性能的关键技术。通过使用连接池,可以避免频繁创建和销毁连接的开销,从而显著提升应用程序的响应速度。
**5.1.1 连接池的调优参数**
连接池的调优主要涉及以下参数:
| 参数 | 描述 |
|---|---|
| **最小连接数** | 连接池中始终保持的最小连接数 |
| **最大连接数** | 连接池中允许的最大连接数 |
| **最大空闲时间** | 连接在连接池中空闲的最大时间 |
| **最大生命周期** | 连接在池中存在的最大生命周期 |
| **测试查询** | 用于验证连接是否有效的SQL查询 |
**5.1.2 连接池调优最佳实践**
* **最小连接数:**应设置为应用程序正常运行所需的最小连接数,以避免频繁创建连接的开销。
* **最大连接数:**应设置为应用程序可承受的最大连接数,以防止连接耗尽。
* **最大空闲时间:**应设置为一个合理的时间,以防止连接长时间空闲而浪费资源。
* **最大生命周期:**应设置为一个合理的时间,以防止连接因长时间使用而出现问题。
* **测试查询:**应选择一个简单的SQL查询,用于快速验证连接是否有效。
### 5.2 SQL语句的优化和索引使用
SQL语句的优化和索引的使用是提升Java应用程序与MySQL数据库交互性能的另一个重要方面。
**5.2.1 SQL语句优化**
* **使用参数化查询:**避免在SQL语句中直接嵌入参数,而是使用参数化查询,以防止SQL注入攻击并提高性能。
* **使用适当的数据类型:**确保使用适当的数据类型,以避免不必要的类型转换。
* **避免不必要的连接:**使用连接池可以减少创建和销毁连接的开销,但如果应用程序频繁执行短时查询,则可以考虑使用持久连接。
**5.2.2 索引使用**
索引是MySQL数据库中用于快速查找数据的结构。通过在经常查询的列上创建索引,可以显著提升查询性能。
**5.2.3 索引优化最佳实践**
* **选择正确的索引列:**选择经常查询的列作为索引列。
* **创建复合索引:**对于经常一起查询的多个列,可以创建复合索引。
* **避免过度索引:**创建过多的索引会增加维护开销,并可能降低查询性能。
### 5.3 缓存和持久化的应用
缓存和持久化技术可以进一步提升Java应用程序与MySQL数据库交互的性能。
**5.3.1 缓存**
缓存是将经常访问的数据存储在内存中,以避免从数据库中检索的开销。可以使用缓存框架,例如Ehcache或Caffeine,来实现缓存功能。
**5.3.2 持久化**
持久化是将数据存储在持久性存储介质中,例如文件系统或NoSQL数据库。持久化可以提高应用程序的容错性,并避免数据丢失。
**5.3.3 缓存和持久化的最佳实践**
* **选择合适的缓存策略:**根据应用程序的访问模式选择合适的缓存策略,例如LRU或FIFO。
* **选择合适的持久化技术:**根据应用程序的需求选择合适的持久化技术,例如文件系统或NoSQL数据库。
* **避免过度缓存和持久化:**过度缓存和持久化会增加内存和存储开销,并可能降低应用程序的性能。
# 6.1 设计模式的应用
在 Java 连接 MySQL 数据库的开发中,应用设计模式可以提高代码的可复用性、可维护性和可扩展性。以下是一些常见的适用于此场景的设计模式:
- **单例模式:**确保在整个应用程序中只有一个数据库连接对象,从而避免资源浪费和连接泄露。
- **工厂模式:**提供一个创建数据库连接对象的统一接口,简化连接创建过程并支持不同的连接配置。
- **代理模式:**在数据库连接对象和客户端代码之间增加一个代理层,用于增强连接行为,例如添加日志记录、缓存或事务管理功能。
- **装饰模式:**动态地向数据库连接对象添加额外的功能,例如加密、压缩或负载均衡,而无需修改原始连接类。
### 代码示例:
```java
// 单例模式
public class DatabaseConnection {
private static DatabaseConnection instance;
private DatabaseConnection() {}
public static DatabaseConnection getInstance() {
if (instance == null) {
instance = new DatabaseConnection();
}
return instance;
}
}
// 工厂模式
public interface DatabaseConnectionFactory {
DatabaseConnection createConnection();
}
public class MySQLConnectionFactory implements DatabaseConnectionFactory {
@Override
public DatabaseConnection createConnection() {
return new MySQLConnection();
}
}
// 代理模式
public class DatabaseConnectionProxy implements DatabaseConnection {
private DatabaseConnection connection;
public DatabaseConnectionProxy(DatabaseConnection connection) {
this.connection = connection;
}
@Override
public void connect() {
connection.connect();
// 添加日志记录功能
System.out.println("Connection established.");
}
}
// 装饰模式
public class DatabaseConnectionDecorator implements DatabaseConnection {
private DatabaseConnection connection;
public DatabaseConnectionDecorator(DatabaseConnection connection) {
this.connection = connection;
}
@Override
public void connect() {
connection.connect();
// 添加加密功能
// ...
}
}
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Java 与 MySQL 数据库连接的各个方面,提供全面的指南,帮助开发人员优化连接性能、确保数据一致性、提升安全性、应对并发控制和分库分表挑战。通过对连接池、事务管理、断开重连机制、最佳实践、监控和故障排除等主题的深入分析,本专栏旨在帮助开发人员建立健壮、高效且安全的数据库连接,从而提升应用程序性能和数据完整性。此外,本专栏还涵盖了高级主题,如读写分离、主从复制、集群部署、JDBC 原理、驱动选择和连接池性能调优,为开发人员提供了全面且深入的资源,以掌握 Java 与 MySQL 数据库连接的方方面面。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TSPL2高级打印技巧揭秘:个性化格式与样式定制指南

# 摘要
TSPL2打印语言作为工业打印领域的重要技术标准,具备强大的编程能力和灵活的控制指令,广泛应用于各类打印设备。本文首先对TSPL2打印语言进行概述,详细介绍其基本语法结构、变量与数据类型、控制语句等基础知识。接着,探讨了TSPL2在高级打印技巧方面的应用,包括个性化打印格式设置、样
JFFS2文件系统设计思想:源代码背后的故事
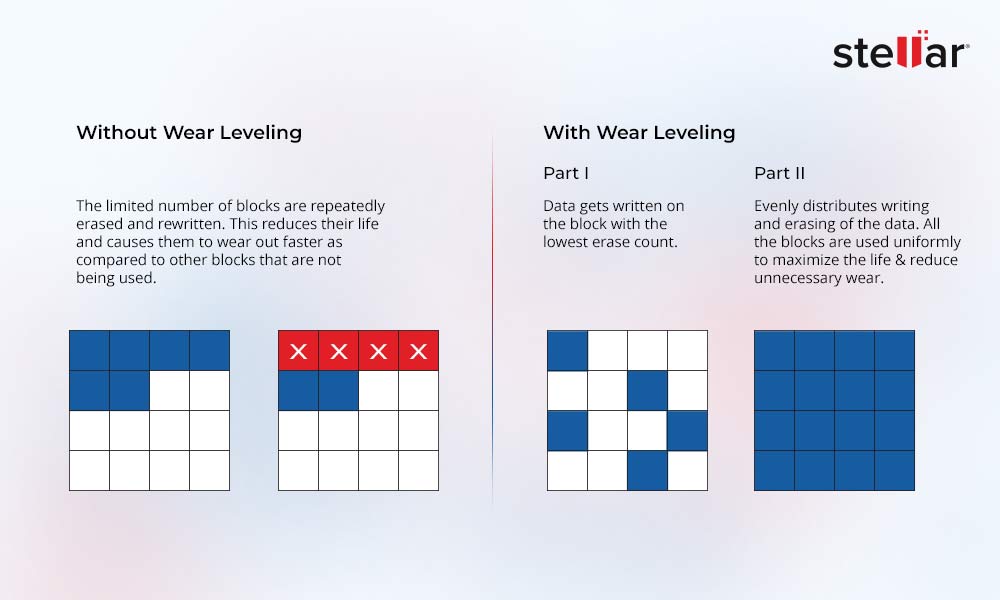
# 摘要
本文对JFFS2文件系统进行了全面的概述和深入的分析。首先介绍了JFFS2文件系统的基本理论,包括文件系统的基础概念和设计理念,以及其核心机制,如红黑树的应用和垃圾回收机制。接着,文章深入剖析了JFFS2的源代码,解释了其结构和挂载过程,以及读写操作的实现原理。此外,针对JFFS2的性能优化进行了探讨,分析了性能瓶颈并提出了优化策略。在此基础上,本文还研究了J
EVCC协议版本兼容性挑战:Gridwiz更新维护攻略

# 摘要
本文对EVCC协议进行了全面的概述,并探讨了其版本间的兼容性问题,这对于电动车充电器与电网之间的有效通信至关重要。文章分析了Gridwiz软件在解决EVCC兼容性问题中的关键作用,并从理论和实践两个角度深入探讨了Gridwiz的更新维护策略。本研究通过具体案例分析了不同EVCC版本下Gridwiz的应用,并提出了高级维护与升级技巧。本文旨在为相关领域的工程师和开发者提供有关EVCC协议及其兼容性维护
计算机组成原理课后答案解析:张功萱版本深入理解

# 摘要
计算机组成原理是理解计算机系统运作的基础。本文首先概述了计算机组成原理的基本概念,接着深入探讨了中央处理器(CPU)的工作原理,包括其基本结构和功能、指令执行过程以及性能指标。然后,本文转向存储系统的工作机制,涵盖了主存与缓存的结构、存储器的扩展与管理,以及高速缓存的优化策略。随后,文章讨论了输入输出系统与总线的技术,阐述了I/O系统的
CMOS传输门故障排查:专家教你识别与快速解决故障
# 摘要
CMOS传输门故障是集成电路设计中的关键问题,影响电子设备的可靠性和性能。本文首先概述了CMOS传输门故障的普遍现象和基本理论,然后详细介绍了故障诊断技术和解决方法,包括硬件更换和软件校正等策略。通过对故障表现、成因和诊断流程的分析,本文旨在提供一套完整的故障排除工具和预防措施。最后,文章展望了CMOS传输门技术的未来挑战和发展方向,特别是在新技术趋势下如何面对小型化、集成化挑战,以及智能故障诊断系统和自愈合技术的发展潜力。
# 关键字
CMOS传输门;故障诊断;故障解决;信号跟踪;预防措施;小型化集成化
参考资源链接:[cmos传输门工作原理及作用_真值表](https://w
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
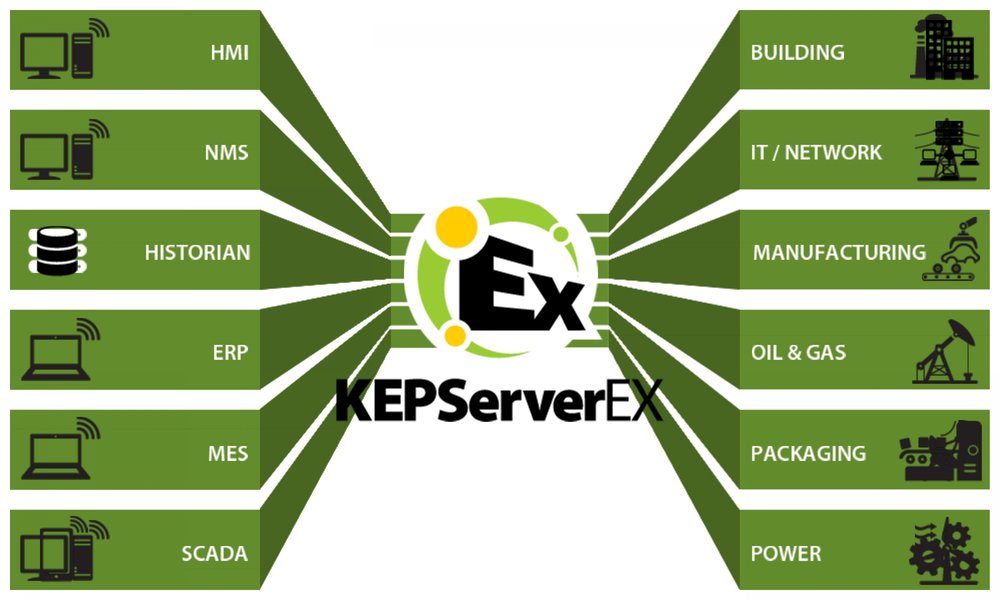
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
【域控制新手起步】:一步步掌握组策略的基本操作与应用
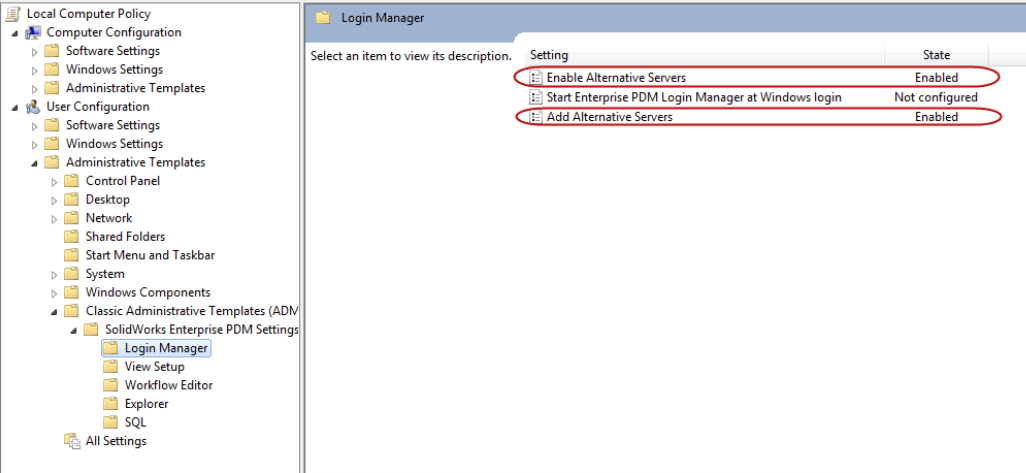
# 摘要
组策略是域控制器中用于配置和管理网络环境的重要工具。本文首先概述了组策略的基本概念和组成部分,并详细解释了其作用域与优先级规则,以及存储与刷新机制。接着,文章介绍了组策略的基本操作,包括通过管理控制台GPEDIT.MSC的使用、组策略对象(GPO)的管理,以及部署和管理技巧。在实践应用方面,本文探讨了用户环境管理、安全策略配置以及系统配置与优化。此
【SolidWorks自动化工具】:提升重复任务效率的最佳实践

# 摘要
本文全面探讨了SolidWorks自动化工具的开发和应用。首先介绍了自动化工具的基本概念和SolidWorks API的基础知识,然后深入讲解了编写基础自动化脚本的技巧,包括模型操作、文件处理和视图管理等。接着,本文阐述了自动化工具的高级应用
Android USB音频设备通信:实现音频流的无缝传输
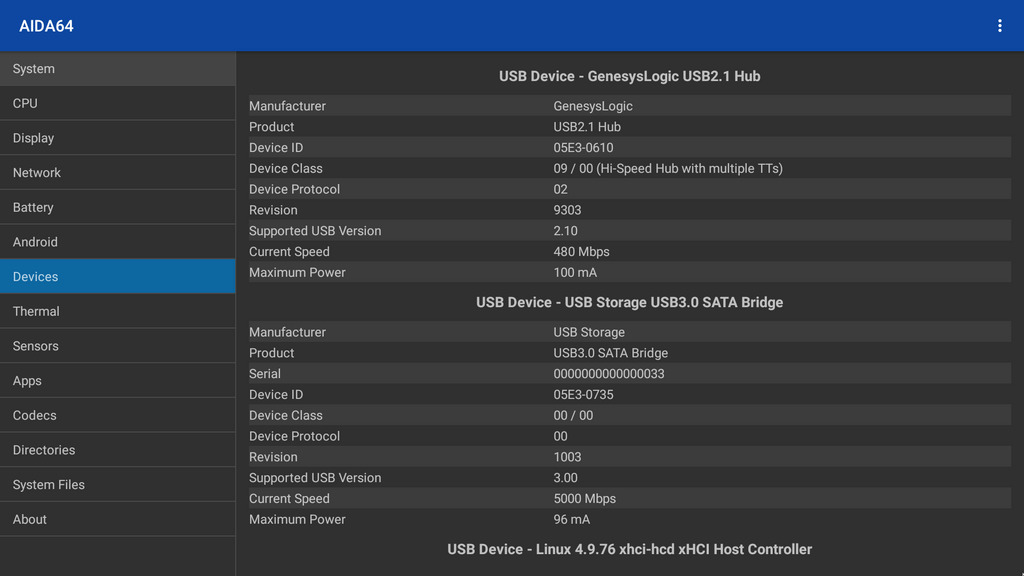
# 摘要
随着移动设备的普及,Android平台上的USB音频设备通信已成为重要话题。本文从基础理论入手,探讨了USB音频设备工作原理及音频通信协议标准,深入分析了Android平台音频架构和数据传输流程。随后,实践操作章节指导读者了解如何设置开发环境,编写与测试USB音频通信程序。文章深入讨论了优化音频同步与延迟,加密传输音频数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )