【YOLO图像标注宝典】:一步步打造高精度目标检测模型
发布时间: 2024-08-18 23:31:12 阅读量: 67 订阅数: 43 

DiffYOLO:通过YOLO和扩散模型进行抗噪声目标检测
# 1. YOLO图像标注基础**
图像标注是计算机视觉领域的一项关键任务,为训练机器学习模型提供高质量的数据。YOLO(You Only Look Once)是一种流行的实时目标检测算法,需要大量标注良好的图像数据才能实现最佳性能。
本节将介绍YOLO图像标注的基础知识,包括:
* **图像标注的目的:**为机器学习模型提供训练数据,以识别和定位图像中的对象。
* **YOLO标注的独特之处:**与其他目标检测算法不同,YOLO使用单次神经网络预测图像中的所有对象,从而实现实时处理。
* **标注数据格式:**YOLO使用文本文件存储标注数据,其中包含对象边界框的坐标和类标签。
# 2. 图像标注理论与实践
### 2.1 图像标注原则和标准
#### 2.1.1 标注目标的类型和属性
图像标注的目标类型主要包括:
- **目标类别:**识别图像中不同类别的物体,如行人、车辆、建筑物等。
- **目标位置:**标注目标在图像中的位置,通常使用矩形框或多边形。
- **目标属性:**描述目标的额外信息,如大小、颜色、方向等。
#### 2.1.2 标注的精度和一致性
标注的精度和一致性对于训练高质量的机器学习模型至关重要:
- **精度:**标注的边界框或多边形应准确地覆盖目标,避免漏检或误检。
- **一致性:**不同标注人员标注相同目标时,应保持一致的标准和方法,以确保标注质量的稳定性。
### 2.2 图像标注工具和技巧
#### 2.2.1 常用图像标注软件
常用的图像标注软件包括:
- **LabelImg:**开源工具,支持矩形框和多边形标注。
- **VGG Image Annotator:**功能丰富的工具,支持多种标注类型和属性。
- **COCO Annotator:**用于COCO数据集的标注工具,提供丰富的标注功能。
#### 2.2.2 标注技巧和最佳实践
图像标注的技巧和最佳实践包括:
- **使用合适的标注工具:**选择适合标注任务的软件,并熟悉其功能和操作。
- **遵循标注原则:**严格遵守标注原则和标准,确保标注的精度和一致性。
- **标注足够数量的数据:**收集和标注足够数量的数据,以训练鲁棒且准确的模型。
- **进行质量控制:**定期检查标注质量,并对标注人员进行培训和校准。
**代码块:**
```python
import cv2
import numpy as np
# 使用 cv2 标注矩形框
image = cv2.imread('image.jpg')
x, y, w, h = cv2.selectROI(image, False)
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**逻辑分析:**
此代码使用 OpenCV 的 `cv2.selectROI()` 函数交互式地标注图像中的矩形框。函数返回矩形框的左上角坐标 `(x, y)` 和宽高 `(w, h)`。然后使用 `cv2.rectangle()` 函数在图像上绘制矩形框,并显示图像。
**参数说明:**
- `image`:要标注的图像。
- `False`:是否允许用户调整矩形框。
- `(x, y)`:矩形框的左上角坐标。
- `(w, h)`:矩形框的宽高。
- `(0, 255, 0)`:矩形框的颜色(绿色)。
- `2`:矩形框的线宽。
# 3. YOLO标注实践
### 3.1 YOLO标注流程和规范
#### 3.1.1 数据集准备和划分
YOLO标注流程的第一步是准备和划分数据集。数据集应包含大量高质量的图像,这些图像代表目标检测任务的各种场景和对象。
1. **收集图像:**从各种来源收集图像,例如网络、公开数据集和内部数据源。确保图像具有多样性,涵盖目标检测任务中可能遇到的各种情况。
2. **划分数据集:**将数据集划分为训练集、验证集和测试集。训练集用于训练YOLO模型,验证集用于调整模型参数,测试集用于评估模型的最终性能。通常使用80/10/10的划分比例。
#### 3.1.2 标注工具和设置
选择合适的图像标注工具对于高效和准确的标注至关重要。以下是一些常用的工具:
- **LabelImg:**一个开源的图像标注工具,提供基本的标注功能,例如矩形框和多边形。
- **CVAT:**一个功能更丰富的图像标注工具,支持各种标注类型,包括矩形框、多边形、关键点和分割。
- **VGG Image Annotator:**一个基于网络的图像标注工具,提供协作标注和质量控制功能。
在设置标注工具时,需要考虑以下参数:
- **标注类型:**选择与目标检测任务相关的标注类型,例如矩形框或多边形。
- **标注属性:**定义要标注的对象的属性,例如类别、大小和位置。
- **标注指南:**创建清晰的标注指南,以确保标注人员遵循一致的标准。
### 3.2 常见标注问题和解决方法
在YOLO标注过程中,可能会遇到一些常见问题。以下是一些常见问题及其解决方法:
#### 3.2.1 目标遮挡和重叠
**问题:**当目标被其他对象遮挡或重叠时,标注变得具有挑战性。
**解决方法:**
- **使用多边形标注:**使用多边形标注工具可以更准确地勾勒出被遮挡或重叠目标的形状。
- **标记遮挡部分:**对于被遮挡的部分,可以创建额外的标注,以指示遮挡的区域。
- **使用深度学习模型:**可以训练深度学习模型来预测被遮挡目标的形状和位置。
#### 3.2.2 异常目标和背景噪声
**问题:**异常目标和背景噪声会干扰YOLO模型的训练。
**解决方法:**
- **过滤异常目标:**可以手动或使用算法过滤掉异常目标,这些目标不代表目标检测任务中的典型情况。
- **消除背景噪声:**可以使用图像处理技术,例如高斯模糊或中值滤波,来消除背景噪声。
- **使用数据增强:**数据增强技术,例如随机裁剪、旋转和翻转,可以创建更多样化的训练集,从而减少异常目标和背景噪声的影响。
# 4. 标注质量评估与优化
### 4.1 标注质量评估指标
标注质量评估对于确保标注数据集的准确性和一致性至关重要。常用的标注质量评估指标包括:
**4.1.1 精度、召回率和 F1 值**
* **精度(Precision):**标注为正例的样本中,真正正例所占的比例。
* **召回率(Recall):**所有真实正例中,被标注为正例的样本所占的比例。
* **F1 值:**精度和召回率的调和平均值,综合考虑了精度和召回率。
**4.1.2 IoU 和 mAP**
* **IoU(Intersection over Union):**预测框和真实框的交集面积与并集面积之比,用于衡量标注框的定位准确性。
* **mAP(Mean Average Precision):**在不同 IoU 阈值下计算的平均精度,用于综合评估目标检测模型的性能。
### 4.2 标注质量优化方法
为了提高标注质量,可以采取以下优化方法:
**4.2.1 标注人员培训和校准**
* 对标注人员进行严格的培训,确保他们理解标注原则和标准。
* 定期进行标注校准,通过比较不同标注人员的标注结果来识别和纠正偏差。
**4.2.2 数据增强和标注修正**
* **数据增强:**通过旋转、翻转、裁剪等方式增强数据集,增加模型训练的数据多样性。
* **标注修正:**使用自动或半自动工具识别和纠正标注错误,如遮挡目标的修复、异常目标的删除。
### 代码示例
**标注质量评估代码:**
```python
import numpy as np
def calculate_iou(pred_box, gt_box):
"""计算预测框和真实框的 IoU。
Args:
pred_box (np.array): 预测框坐标 [xmin, ymin, xmax, ymax]
gt_box (np.array): 真实框坐标 [xmin, ymin, xmax, ymax]
Returns:
float: IoU 值
"""
# 计算交集面积
inter_xmin = np.maximum(pred_box[0], gt_box[0])
inter_ymin = np.maximum(pred_box[1], gt_box[1])
inter_xmax = np.minimum(pred_box[2], gt_box[2])
inter_ymax = np.minimum(pred_box[3], gt_box[3])
inter_area = np.maximum(0, inter_xmax - inter_xmin) * np.maximum(0, inter_ymax - inter_ymin)
# 计算并集面积
pred_area = (pred_box[2] - pred_box[0]) * (pred_box[3] - pred_box[1])
gt_area = (gt_box[2] - gt_box[0]) * (gt_box[3] - gt_box[1])
union_area = pred_area + gt_area - inter_area
# 计算 IoU
iou = inter_area / union_area
return iou
def calculate_mAP(pred_boxes, gt_boxes, iou_threshold=0.5):
"""计算平均精度(mAP)。
Args:
pred_boxes (np.array): 预测框坐标 [num_boxes, 4]
gt_boxes (np.array): 真实框坐标 [num_boxes, 4]
iou_threshold (float): IoU 阈值
Returns:
float: mAP 值
"""
# 计算每个预测框与所有真实框的 IoU
ious = np.zeros((pred_boxes.shape[0], gt_boxes.shape[0]))
for i in range(pred_boxes.shape[0]):
for j in range(gt_boxes.shape[0]):
ious[i, j] = calculate_iou(pred_boxes[i], gt_boxes[j])
# 计算每个真实框的最高 IoU
max_ious = np.max(ious, axis=0)
# 计算每个真实框的平均精度
aps = []
for i in range(gt_boxes.shape[0]):
# 计算该真实框的预测框的 IoU
ious_for_gt = ious[:, i]
# 根据 IoU 阈值过滤预测框
filtered_ious = ious_for_gt[ious_for_gt >= iou_threshold]
# 计算该真实框的平均精度
ap = np.mean(filtered_ious)
aps.append(ap)
# 计算 mAP
mAP = np.mean(aps)
return mAP
```
### 流程图示例
**标注质量优化流程图:**
```mermaid
graph LR
subgraph 标注质量优化
A[标注人员培训] --> B[标注校准]
B --> C[数据增强]
C --> D[标注修正]
D --> E[标注质量评估]
E --> F[优化完成]
end
```
# 5.1 YOLO模型训练和评估
### 5.1.1 训练数据集和参数设置
**训练数据集准备:**
1. 收集高质量、多样化的图像数据集,包含丰富的目标类别和场景。
2. 对数据集进行预处理,包括图像缩放、归一化和数据增强。
3. 将数据集划分为训练集、验证集和测试集。
**参数设置:**
1. **学习率:**控制模型更新权重的速度,通常设置在0.001到0.0001之间。
2. **批量大小:**一次输入到模型的图像数量,影响模型的训练速度和收敛性。
3. **迭代次数:**训练模型的轮数,影响模型的最终性能。
4. **优化器:**优化模型权重的算法,如Adam或SGD。
5. **损失函数:**衡量模型预测与真实标签之间的差异,如交叉熵损失或IoU损失。
### 5.1.2 模型评估和性能优化
**模型评估:**
1. **精度:**预测正确的目标数量与总目标数量的比值。
2. **召回率:**预测正确的目标数量与真实目标数量的比值。
3. **F1值:**精度和召回率的调和平均值。
4. **IoU(交并比):**预测边界框与真实边界框重叠区域与并集区域的比值。
5. **mAP(平均精度):**在不同IoU阈值下计算的平均精度。
**性能优化:**
1. **数据增强:**通过旋转、裁剪、翻转等方式增强训练数据,提高模型泛化能力。
2. **超参数调整:**通过网格搜索或贝叶斯优化等方法优化学习率、批量大小等超参数。
3. **模型架构调整:**调整模型层数、卷积核大小、激活函数等参数,以提高模型性能。
4. **迁移学习:**使用预训练的模型作为基础,微调特定任务,提高训练效率和性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
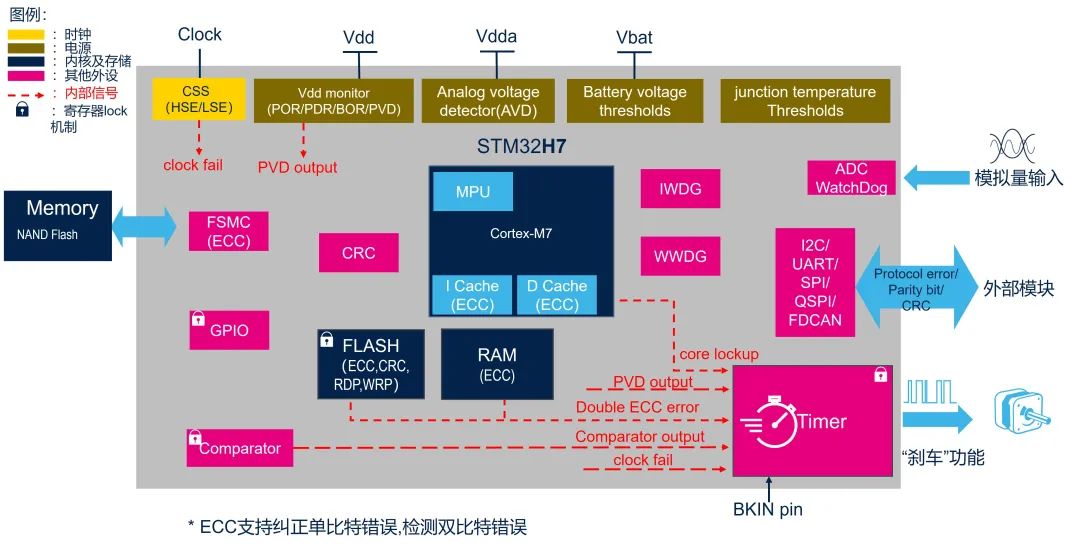
STM32H7双核性能调优:7个实用技巧,轻松提升系统效率
# 摘要
本文系统介绍了STM32H7双核处理器及其性能调优的理论与实践技巧。首先,概述了双核处理器的基本情况和性能调优的重要性。随后,详细探讨了性能瓶颈的识别、性能指标的评估,以及双核处理器工作原理中的核心间通信和多核处理机制。理论基础章节深入分析了优化算法、数据结构、缓存策略和内存管理的策略。实践技巧章节着重于代码层面优化、系统资源管理以及外设接口调优的
【华为OLT MA5800故障排除】:快速解决网络问题的20个技巧

# 摘要
本文详细探讨了华为OLT MA5800的故障排除方法,涵盖了从故障诊断的理论基础到软硬件故障处理的实用技巧。通过对设备的工作原理、故障排除的流程和方法论的介绍,以及常规检查和高级故障排除技巧的阐述,本文旨在为技术人员提供全面的故障处理指南。此外,通过实践案例的分析,本文展示了如何应用故障排除技巧
揭秘MCC与MNC的国际标准:全球运营商编码规则大揭秘

# 摘要
本文全面探讨了移动国家代码(MCC)与移动网络代码(MNC)的基础概念、编码原理、技术实现,以及它们在移动通信中的监管和管理问题。通过对国际标准组织的作用和标准化编码规则的分析,深入理解了MCC与MNC的结构及其在国际频谱分配和数据库管理中的应用。同时,本文还讨论了MCC与MNC在全球监管框架下的分配现状、面临的挑战以及未来发展趋势,并通过案例研究,展示了MCC与MNC在
特斯拉Model 3通信网络解析:CAN总线技术与车辆通信

# 摘要
本文首先介绍了特斯拉Model 3与车辆通信的基础知识,随后深入探讨了CAN总线技术的历史、原理、关键技术和在Model 3中的实际应用。通过对CAN网络架构的分析,本文详细阐述了Model 3的CAN网络功能及其在车辆控制和智能辅助系统中的作用。此外,本文还探讨了CAN总线在网络安全性和车辆功能方面的相关议题,以及CAN总线技术的未来发展趋势,包括其与车联网技术的融合,以及CAN FD和以太网等
Swiper插件开发速成课:打造个性化分页器的全流程
# 摘要
Swiper插件是实现触摸滑动功能的强大工具,广泛应用于网页设计和移动应用开发。本文首先概述Swiper插件的开发,随后详细探讨其基础理论、配置方法、自定义开发以及高级应用。通过对分页器、初始化参数、样式定制和兼容性处理的深入分析,本文揭示了Swiper插件在不同场景下的应用技巧和性能优化策略。实战案例分析了Swiper与流行前端框架的集成以及在复杂布局中的应用,为开发者提供实用参考。最后,本文探讨了Swiper插件的维护更新策略,并展望其
SSD1309 OLED显示效果提升:调试技巧大揭秘
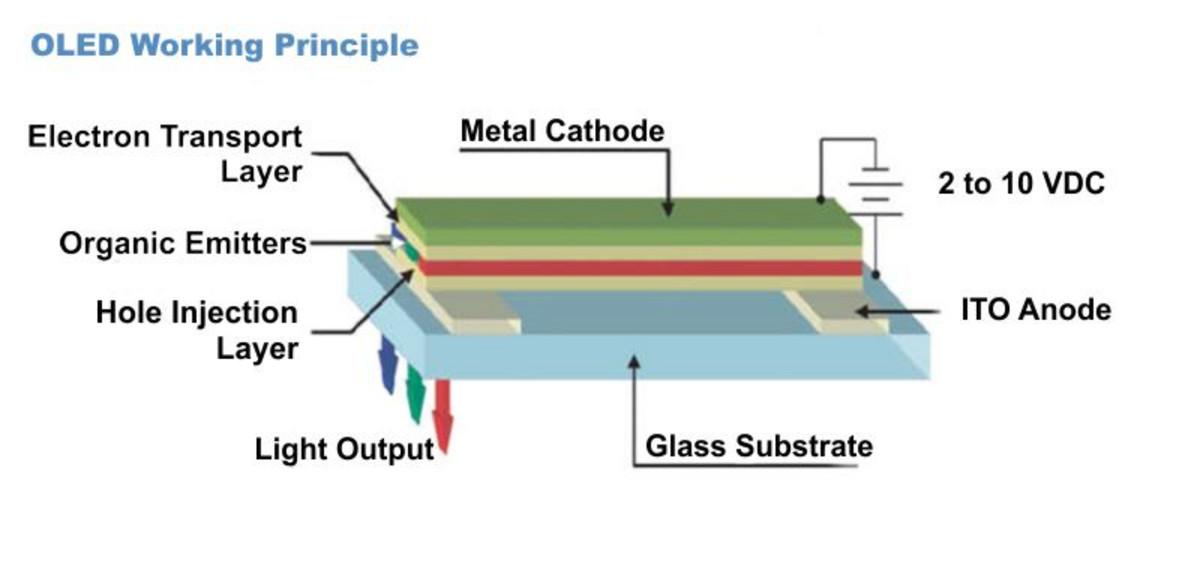
# 摘要
本文全面介绍了SSD1309 OLED技术,涵盖其基本构造、显示原理、硬件接口以及初始化和配置过程。通过对显示效果评估指标的探讨,提出了软件优化策略,包括色彩管理、字体渲染、抗锯齿、闪烁控制等。进一步的,本文提供了SSD1309 OLED显示效果调试的实践方法,包括调试工具的选择、显示参数调整、图像
【测试效率和稳定性双重提升】:'Mario'框架性能优化全攻略

# 摘要
本文针对'Mario'框架的性能优化进行全面概述,从理论基础到实际应用进行了深入探讨。首先介绍了'Mario'框架的架构理念及其在性能优化中的作用,并阐述了性能测试的理论基础和关键指标。随后,文章详细阐述了代码层面的优化策略,包括代码重构、数据库交互优化以及并发和异步处理的高效实现。在系统层面,探讨了资源
【数据同步大揭秘】:KingSCADA3.8与ERP无缝对接指南
# 摘要
本论文深入探讨了数据同步的概念及其在现代信息系统中的重要性,特别是KingSCADA3.8平台与ERP系统的集成要点。通过对KingSCADA3.8的基础架构、核心特性和数据管理等关键技术的解析,本文揭示了ERP系统数据管理的核心功能及其在企业中的作用。此外,本文详细阐述了KingSCADA3.8与ERP系统实现数据同步的策略、技术、配置与部署方法,并通过案例研究
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )