PARDISO Linux安装秘籍:流程优化与高效技巧
发布时间: 2024-12-04 01:20:44 阅读量: 24 订阅数: 27 

S变换+Sockwell R G , Mansinha L , Lowe R P . Localization of the complex spectrum: the S transformJ

参考资源链接:[PARDISO安装教程:快速获取与部署步骤](https://wenku.csdn.net/doc/6412b6f0be7fbd1778d48860?spm=1055.2635.3001.10343)
# 1. PARDISO算法简介及应用场景
## 1.1 PARDISO算法概述
PARDISO(Parallel Direct Solver)是一个高性能的并行直接求解器,主要用于大规模稀疏线性方程组的求解。它是基于Intel处理器的多线程优化算法,专为数值线性代数计算设计,能在有限元分析、科学工程计算和大规模数据处理等领域中发挥巨大优势。
## 1.2 PARDISO算法特点
PARDISO算法的主要特点是其优秀的并行性能和处理大规模稀疏矩阵的能力。由于采用基于因子分解的直接方法,PARDISO通常在求解精度和稳定性方面优于迭代方法。同时,它提供了高度优化的计算性能,特别是针对Intel架构的CPU进行了特别优化,这使得PARDISO在需要进行密集计算的场景下表现卓越。
## 1.3 应用场景实例
在工程设计与分析方面,PARDISO常用于有限元分析,这包括在结构力学、流体动力学以及电磁场模拟等领域中的应用。例如,它可以解决在建筑结构设计中由于外部负载引起的压力分布问题,或者在汽车工业中进行碰撞模拟。而在数据科学领域,PARDISO可应用于大规模稀疏矩阵的数据分析,比如在机器学习算法中进行矩阵操作以加快算法的计算速度。
# 2. PARDISO在Linux环境下的安装步骤
## 2.1 系统要求和依赖检查
### 2.1.1 确认Linux发行版和版本兼容性
在开始安装PARDISO之前,首先需要确认您的Linux系统发行版及其版本是否与PARDISO兼容。PARDISO通常支持主流的Linux发行版,例如Ubuntu、Fedora、CentOS等。但为了确保顺利安装与使用,建议查阅官方文档或与技术支持联系,获取最新支持的列表。另外,必须确保您的系统是64位的,因为PARDISO作为一个高性能的数学库,在32位系统上可能不支持或者性能受限。
通常,通过在终端执行如下命令,可以检查您的系统版本信息:
```sh
# 查看系统发行版和版本信息
cat /etc/*release
# 确认系统架构
uname -m
```
如果系统不满足安装条件,您可能需要升级或更换操作系统,以确保兼容性。
### 2.1.2 安装必要的依赖库和工具
在安装PARDISO之前,需要确保系统已经安装了所有必要的依赖库和工具。对于基于Debian的系统(如Ubuntu),可以使用以下命令来安装这些依赖:
```sh
sudo apt-get update
sudo apt-get install build-essential cmake libopenblas-base liblapack3 gfortran
```
对于基于RPM的系统(如Fedora或CentOS),则可以使用如下命令:
```sh
sudo yum groupinstall "Development Tools"
sudo yum install gcc-c++ cmake lapack-devel openblas-devel
```
请注意,具体的包可能会随着Linux发行版的不同而有所变化。安装完成之后,可以使用`cmake --version`和`gcc --version`等命令来确认安装情况。
## 2.2 PARDISO安装包的下载与配置
### 2.2.1 从官方渠道获取安装包
PARDISO是由Intel Math Kernel Library (MKL) 提供的,因此您需要从Intel官方网站下载MKL安装包。进入Intel官方网站,查找MKL,然后下载对应的版本。请确保下载与您的操作系统和处理器架构相匹配的版本。
### 2.2.2 配置安装环境和参数
下载安装包之后,需要解压并配置安装环境。通常,MKL的安装包是tar.gz格式,可以使用如下命令进行解压:
```sh
tar -xzf mkl*.tgz
```
随后,您可能需要设置环境变量,如`LD_LIBRARY_PATH`和`PATH`,以确保系统能够找到MKL库和可执行文件。可以通过在`~/.bashrc`文件中添加如下行来实现:
```sh
export LD_LIBRARY_PATH=/path/to/mkl/lib:$LD_LIBRARY_PATH
export PATH=/path/to/mkl/bin:$PATH
```
修改完毕后,执行`source ~/.bashrc`命令使更改生效。
## 2.3 安装过程中的常见问题与解决方案
### 2.3.1 错误代码解析
在安装过程中,可能会遇到各种错误代码。例如,如果系统找不到某些依赖库,通常会返回一个错误代码。这时需要根据错误提示,通过查阅官方文档或社区论坛来找到解决方案。
一个典型的错误可能是:
```
Error: cannot find library 'libmkl_rt.so'
```
遇到此类问题时,可能需要手动指定MKL库文件的位置。可以尝试将MKL库目录添加到`LD_LIBRARY_PATH`环境变量中。
### 2.3.2 安装后验证和测试
安装完成后,需要进行验证以确保PARDISO库安装成功并且可以正常工作。通常,Intel MKL提供了测试工具来进行验证:
```sh
# 进入到MKL的目录
cd /path/to/mkl/bin
# 运行测试程序
./mkl检验程序
```
如果测试通过,将看到相关的测试输出信息,证明PARDISO已经成功安装,并且可以被系统识别。
在本章节中,我们详细介绍了在Linux环境下安装PARDISO的步骤,包括系统的兼容性检查、依赖库的安装、安装包的下载与配置,以及安装过程中常见的问题解决方法。这些内容的详细介绍和操作步骤旨在为IT专业人员提供详尽的指南,确保他们能够顺利地将PARDISO集成到他们的工作环境中。
# 3. PARDISO的使用与调优
## 3.1 PARDISO基本使用方法
PARDISO是一个高性能的稀疏矩阵求解器,它提供了丰富的API接口,使得用户可以方便地在自己的程序中调用。以下内容将详细介绍如何调用PARDISO的API接口,以及如何进行参数设置和性能监控。
### 3.1.1 调用PARDISO的API接口
在调用PARDISO之前,我们首先需要了解

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【瑞美LIS系统第三方接口手册】:10个专业步骤与技巧助您成功集成

# 摘要
本文全面介绍了瑞美LIS系统的概念、第三方接口的功能及集成实践。首先概述了瑞美LIS系统的基本架构,并详细阐述了其第三方接口的定义、通信协议和数据交换格式。接着,文中分析了系统集成前的各项准备工作,包括环境要求、接入规范和功能测试计划。随后,文章着重介绍了第三方接口集成的实际操作,包括认证授权、异常处理机制和性能优化技巧。通过集成案例分析,本文展示了瑞美LIS系统集成的成功经验和故
【r3epthook内部机制】:揭秘其工作原理及效率提升秘诀

# 摘要
本文深入探讨了r3epthook技术,揭示了其定义、组成、工作原理以及核心功能。通过对性能分析、代码优化和系统资源管理的探讨,文章提供了提升r3epthook效率的实用策略。文中进一步分析了r3epthook在安全、性能监控
硬件设计师必备:【PCIe-M.2接口规范V1.0应用指南】

# 摘要
PCIe-M.2接口作为一种广泛应用的高速接口技术,已成为移动设备、服务器和工作站等领域的关键连接方式。本文首先概述了PCIe-M.2接口规范,并深入解析了其技术细节,包括物理特性
安信负载均衡器监控:实时性能跟踪与流量分析
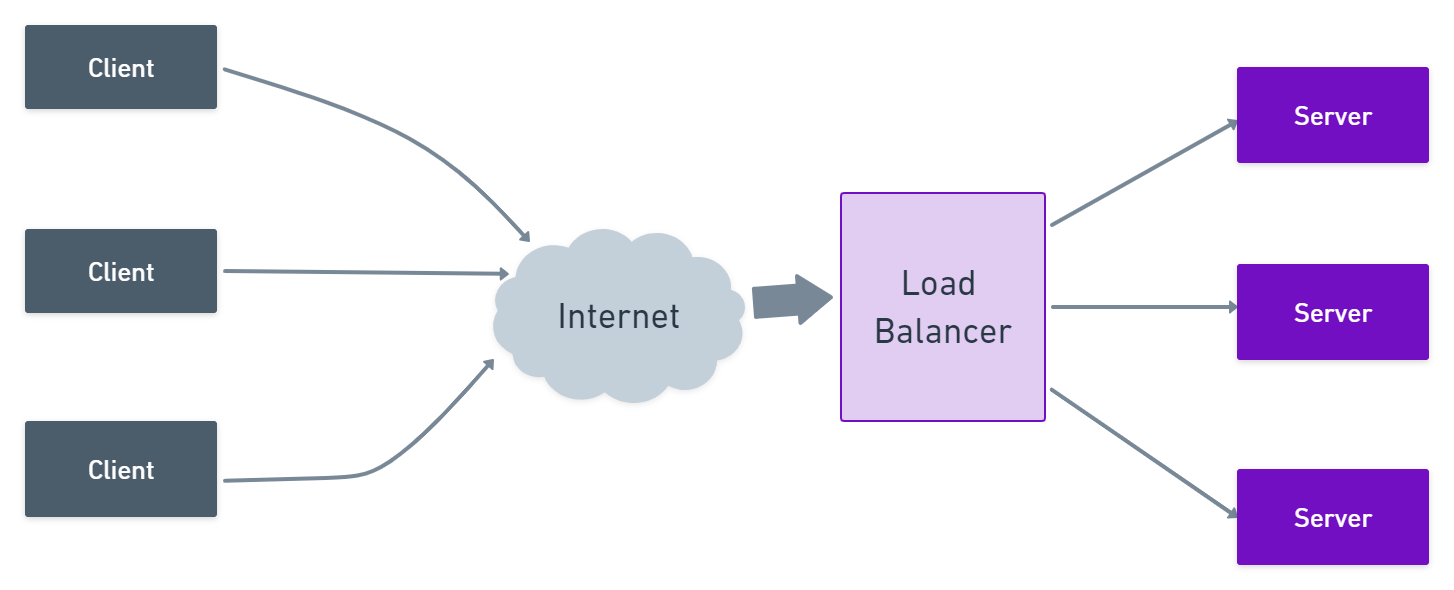
# 摘要
负载均衡器作为现代网络架构的关键组件,其监控和性能优化对于确保网络服务质量至关重要。本文首先概述了负载均衡器的基础知识及其监控的重要性,随后深入分析了负载均衡器的关键性能指标(KPIs)和流量分析技术。文章详细讨论了性能指标的监控、数据收集及实时跟踪与可视化方法,提供了流量分析工具的配置与使用案例研究。进一步,本文探讨了负载均衡器监控系统的高级应用,包括自动化报警、故障预测和负载均衡策
数据库索引优化的终极秘籍:提升性能的黄金法则
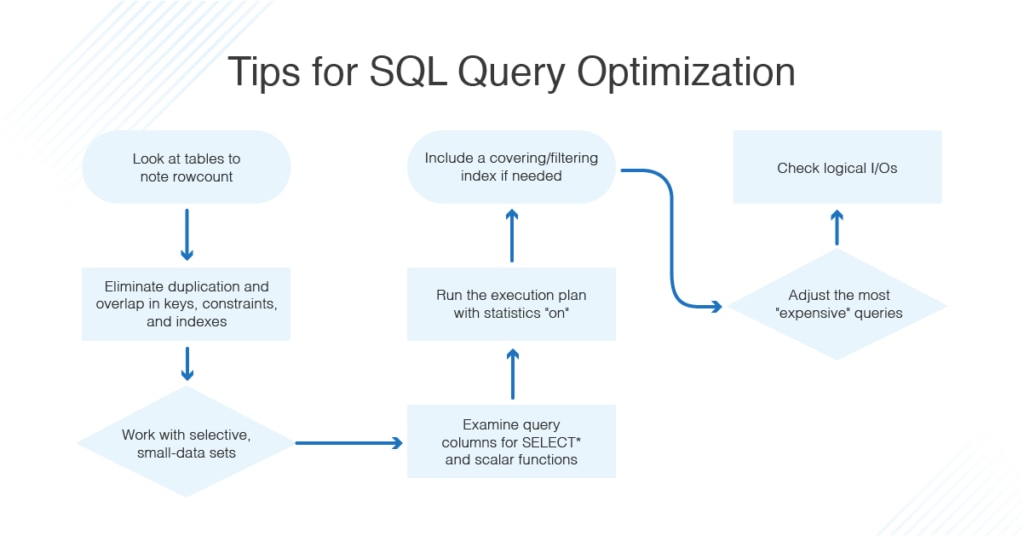
# 摘要
数据库索引是提高查询效率和管理数据的关键技术。本文对数据库索引进行了全面的概述,强调其在提升数据库性能方面的重要性。通过介绍各种索引类型(如B-Tree、哈希和全文索引)及其工作原理,本文揭示了数据检索过程和索引维护的内在机制。进一步,本文探索了索引优化的实践技巧,包括创建与调整、案例分析以及避免常见陷阱,旨在提供实际操作中的有效指导。高
硬件架构揭秘:LY-51S V2.3开发板硬件组成与连接原理详解
# 摘要
本文对LY-51S V2.3开发板进行了全面的介绍和分析,涵盖了硬件组成、连接原理、网络通讯、开发环
CarSim Training2参数扩展实战:外挂模块开发与自定义攻略
# 摘要
本文旨在探讨CarSim软件环境下外挂模块开发和自定义攻略的集成,为开发者提供从基础理论到实际应用的全面指导。首先,介绍了CarSim参数扩展基础和外挂模块开发的关键概念。接着,深入分析了外挂模块的设计、实现与测试流程,以及在CarSim软件架构中参数扩展的方法和工具。文中还阐述了自定义攻略的设计原则、开发工具选择和测试优化策略。最后,通过案例研究,分享了外挂模块与自定义攻略
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )