【PARDISO快速提示】:避开安装陷阱,安全高效配置
发布时间: 2024-12-04 02:04:58 阅读量: 12 订阅数: 27 

参考资源链接:[PARDISO安装教程:快速获取与部署步骤](https://wenku.csdn.net/doc/6412b6f0be7fbd1778d48860?spm=1055.2635.3001.10343)
# 1. PARDISO简介与基本概念
## 简介
PARDISO(Parallel Direct Solver)是一款高性能、多线程的直接求解器,专注于解决稀疏线性系统问题。它由Intel公司开发,适用于科学计算与工程领域中遇到的复杂数值问题。PARDISO利用多核处理器的并行计算能力,显著缩短了求解过程所需的时间,特别是对大型稀疏矩阵的处理具有显著优势。
## 基本概念
在深入了解PARDISO之前,需要先熟悉几个基本概念:
- **稀疏矩阵**:在数值计算中,只有少数元素非零的矩阵称为稀疏矩阵。对这些矩阵进行求解时,直接求解器比迭代求解器更高效。
- **并行计算**:利用多个计算单元同时执行计算任务以加速计算过程的方法。PARDISO将问题分解,分配给多个线程并行处理,从而加速求解过程。
- **直接求解器**:与迭代求解器不同,直接求解器在有限步骤内提供精确解,适用于需要高精度结果的场合。
PARDISO作为直接求解器,通过采用高效的数学算法和并行计算技术,能够快速且准确地解决大规模科学和工程问题中的线性系统。
# 2. PARDISO的安装与配置
### 2.1 安装PARDISO前的准备工作
PARDISO是一个用于解决稀疏线性系统的高性能数值解法库。在安装之前,用户需要确保其计算机满足PARDISO的系统兼容性要求,并且已经配置了必要的依赖项和环境变量。
#### 2.1.1 系统兼容性检查
确保您的操作系统满足PARDISO的最低要求。一般来说,PARDISO可以运行在支持C++的多种操作系统上,如Linux、Windows及macOS。检查您的系统是否安装了满足库版本要求的编译器,比如gcc或Microsoft Visual Studio。此外,您的系统至少需要一定容量的RAM和足够的磁盘空间来存储库文件和编译后的文件。
#### 2.1.2 必要依赖与环境变量配置
PARDISO通常会依赖于一些基础的数学库,比如BLAS和LAPACK。在某些操作系统上,这些库可能已经预装,但在其他情况下,您可能需要手动安装它们。同时,环境变量如`LD_LIBRARY_PATH`(Linux)或`PATH`(Windows)需要配置以包含库文件的搜索路径,确保在运行时能够找到PARDISO库文件。
### 2.2 PARDISO的安装步骤详解
在准备好系统环境之后,可以开始安装PARDISO库。通常情况下,PARDISO会提供预编译的二进制文件,适用于大多数用户。以下是具体的安装步骤。
#### 2.2.1 下载与安装PARDISO库文件
1. 访问PARDISO官方网站或者获取发行包。
2. 根据您的系统环境下载合适的版本。
3. 解压下载的文件到一个您希望安装的目录。
4. 遵循安装目录中提供的安装文档指导进行安装。
#### 2.2.2 验证安装的有效性
安装完成后,您需要验证PARDISO是否能够正确加载和执行。可以通过编写一个简单的测试程序,调用PARDISO提供的API,来检查安装是否成功。
```cpp
#include <stdio.h>
#include "mkl_pardiso.h"
int main() {
// 示例代码,用于调用PARDISO进行矩阵求解
// 这里只是一个框架,具体代码需要根据实际情况填充
// ...
return 0;
}
```
编译并运行上述测试代码。如果PARDISO库文件被正确加载,则程序应该能够无误运行并输出预期的结果。
### 2.3 高效配置PARDISO的实践技巧
高效配置PARDISO不仅包括安装步骤的正确执行,还包括对其配置文件的编辑以及性能调优。
#### 2.3.1 配置文件的编辑与调试
PARDISO可以通过配置文件来设置不同的运行参数。配置文件通常具有清晰的注释来指导用户设置参数。例如,您可以设置矩阵求解的算法选择、线程数等。
```ini
# Example PARDISO configuration file snippet
maxfct = 1 # Maximum number of factors with identical sparsity structure
mnum = 1 # Which factorization to use
mtype = -2 # Matrix type: Real unsymmetric
iparm[0] = 1 # No solver default
iparm[1] = 2 # Fill-in reordering from METIS
iparm[2] = 1 # Conjugate gradient iterative solver
iparm[3] = 0 # No iterative-direct algorithm
iparm[5] = 0 # Write solution into x
iparm[6] = 0 # Not in use
iparm[7] = 2 # Preconditioned CG, compute only R
iparm[8] = 0 # Numbers of iterative refinement steps
iparm[9] = 13 # Perturbe the pivot elements with 1E-13
iparm[10] = 1 # Use nonsymmetric permutation and scaling MPS
iparm[11] = 0 # Not in use
iparm[12] = 1 # Maximum weighted matching algorithm is switched-off (default for symmetric)
iparm[13] = 0 # Output: number of perturbed pivots
iparm[14] = 0 # Not in use
iparm[15] = 0 # Report number of nonzeros in the factors
iparm[16] = 0 # Not in use
iparm[17] = -1 # Output: number of CG Iterations
iparm[18] = -1 # Not in use
iparm[19] = 0 # Not in use
iparm[20] = 0 # Not in use
iparm[21] = 0 # Not in use
iparm[22] = 0 # Not in use
iparm[23] = 0 # Not in use
iparm[24] = 0 # Not in use
iparm[25] = 0 # Not in use
iparm[26] = 0 # Not in use
iparm[27] = 0 # Check matrix validity
iparm[28] =
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
《建筑术语标准》实施指南:一步到位地掌握实践操作要点

# 摘要
《建筑术语标准》为建筑行业提供了一套明确且统一的术语框架,旨在确保沟通的准确性和设计施工的质量。本文概述了标准的背景和核心内容,详细解析了关键建筑术语,并探讨了其在建筑设计、项目管理和施工验收中的具体应用。同时,分析了实施标准过程中出现
【orCAD精确高效】:BOM导出错误减少与准确度提升技巧

# 摘要
本文系统地介绍了orCAD BOM导出的过程及其挑战,并探讨了如何精确控制BOM数据,以提高导出的准确度和效率。文章首先概述了BOM导出的基本流程和重要性,随后分析了在数据导出中常见的错误类型,如数据不一致性和格式兼容性问题,并提供了有效的数据精确度基础设置策略。接着,本文探讨了提高BOM导出效率的实践技巧,包括优化orCAD项目设置和实现自动
AdvanTrol-Pro性能优化必修课:新手也能轻松驾驭的首次调优手册
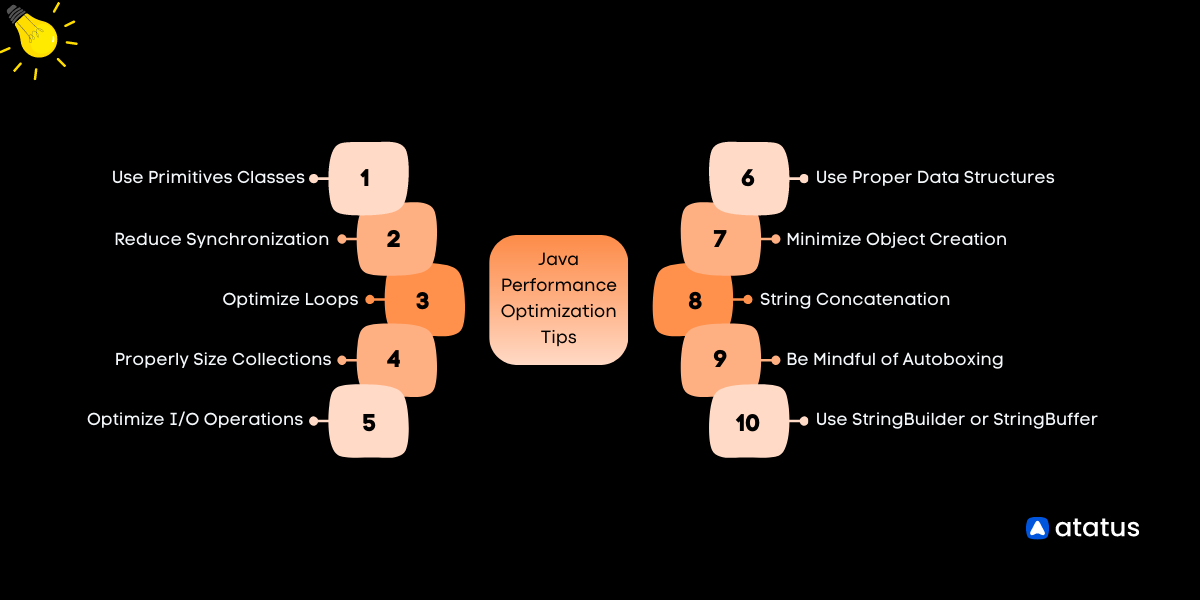
# 摘要
本文全面探讨了AdvanTrol-Pro在性能监控和调优方面的基础和高级应用。文章首先介绍了AdvanTrol-Pro的基础知识和性能优化的概要,随后深入讨论了性能监控工具的使用和配置,包括实时数据的分析和自动化监控策略。在系统调优实践中,本文详细阐述了内存、CPU、磁盘I/O和网络性能的优化技巧,并通过
【源码解构】:深入r3epthook架构设计,专家级理解

# 摘要
r3epthook是一个复杂的架构,设计用于高效的数据处理和系统集成。本文从架构设计、核心组件、高级功能、实战应用以及源码分析等多个维度深入解析了r3epthook的架构和功能。文章详细介绍了基础组件、模块化设计的优势、数据流处理方法,以及如何通过高级数据处理
【并发处理】:电子图书馆网站响应速度提升的5大秘诀

# 摘要
并发处理在现代软件系统中至关重要,它通过允许多个计算任务同时进行来提高系统性能。本文从理论基础开始,详细介绍了并发控制机制的实现,包括多线程编程基础、高级并发编程技术和无阻塞I/O与异步编程模型。随后,将理论应用于实践,探讨了电子图书馆系统中并发处理的优化策略,包括网站架构
【Psycopg2 Binary安全指南】:保护你的数据库免受攻击
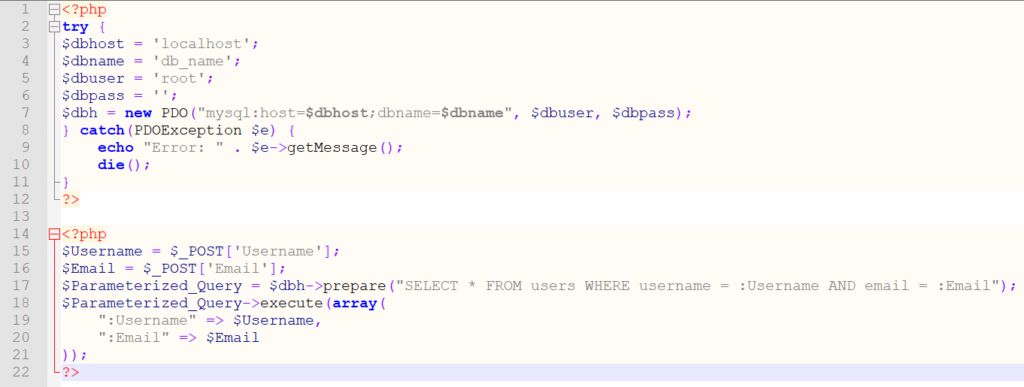
# 摘要
Psycopg2 Binary作为PostgreSQL数据库的Python适配器,其安全机制对数据库管理至关重要。本文旨在介绍Psycopg2 Binary的基本安全特性及其实施细节,着重分析其加密机制和认证机制。通过探讨加密基础,包括对称与非对称加密、哈希函数及数字签名,以及Psycopg2 Binary的加密实现,如连接和数据传输加密,本
I2C总线应用指南:LY-51S V2.3开发板设备互联与数据交换
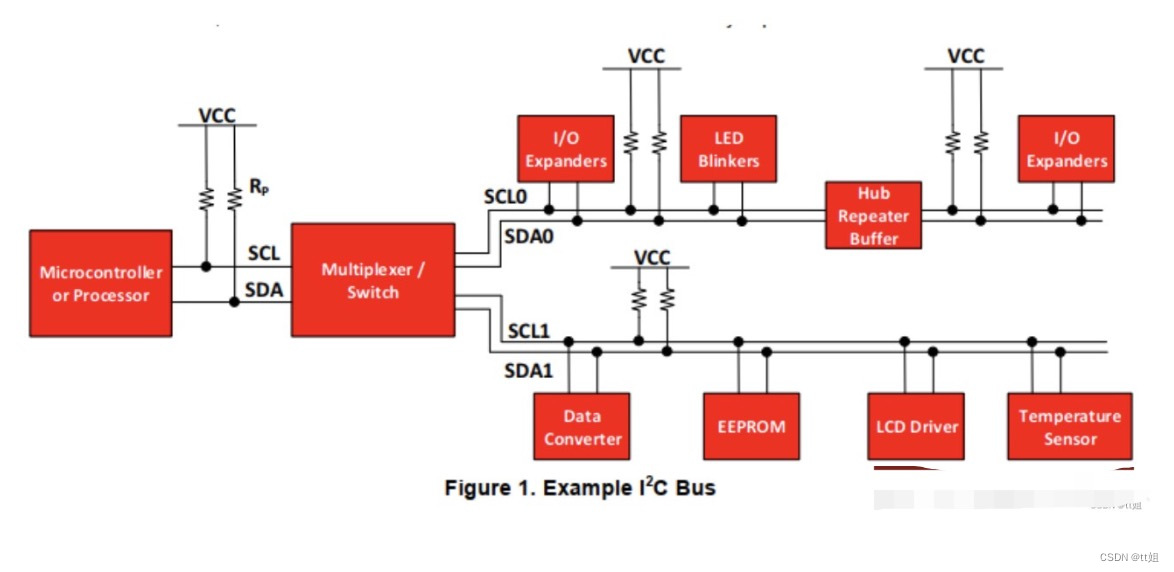
# 摘要
本文综合论述了I2C总线技术及其在LY-51S V2.3开发板上的实现细节。首先概述了I2C总线技术的基础知识,并针对LY-51S V2.3开发板介绍了硬件连接和软件配置的具体方法。接着,深入探讨了I2C总线的数据交换原理,包括通信协议、错误检测机制和设备编程实践。在讨论了I2C设备初始化与配置后,文章聚焦于嵌入式系统中I2C的高级应用技巧。最后,以LY-51S V2.3项目案例分析为结,展示了I2C在实际应用中的硬件连接、软件配置和
热管理专家:【M.2接口的热管理】在V1.0规范中的策略

# 摘要
M.2接口作为高速数据传输的硬件标准,在个人电脑和移动设备中扮演着关键角色。随着数据处理需求的不断增长,热管理成为确保M.2接口稳定运行的关键因素。本文首先概述了M.2接口的特点及其热管理的必要性,随后详细分析了M.2接口V1.0规范中的热管理策略,包括热设计原则和技术指标,以及实际应用中遇到的挑战和优化经验。进一步探讨了散热解决方案,
数据库性能监控工具精选:如何选择最适合的监控工具
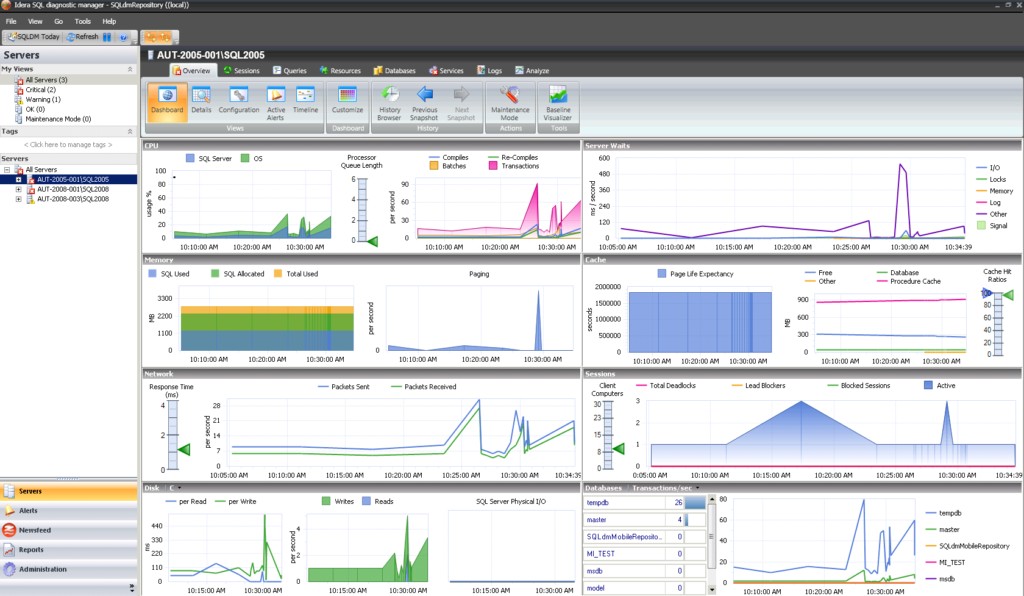
# 摘要
数据库性能监控是确保企业数据库稳定运行的关键环节。本文深入分析了数据库性能监控的重要性与需求,探讨了不同监控工具的基本理论,包括关键性能指标、工具分类、功能对比以及选择标准。通过对开源和商业监控工具案例的实践研究,本文展示了如何在不同环境中部署和应用这些工具。此外,文章还介绍了数据库性能监控工具的高级应用,如自定义监
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )