PARDISO算法性能优化:进阶技巧与专家建议
发布时间: 2024-12-04 01:47:26 阅读量: 61 订阅数: 27 

C++性能优化:编译器优化、代码与算法优化及并行处理

参考资源链接:[PARDISO安装教程:快速获取与部署步骤](https://wenku.csdn.net/doc/6412b6f0be7fbd1778d48860?spm=1055.2635.3001.10343)
# 1. PARDISO算法概述
PARDISO(Parallel Direct Sparse Solver)是一个高效的并行直接求解器,专门用于解决大规模稀疏线性方程组问题。作为一种直接求解器,PARDISO算法被广泛应用于科学计算、工程模拟和数据分析等领域。它的核心优势在于利用现代多核处理器的计算能力,优化内存使用,并缩短求解时间,为复杂系统的数值模拟提供了强大的后端支持。通过对稀疏矩阵的高效处理,PARDISO在保持高精度的同时,大幅提升了计算效率,使其成为求解稀疏线性方程组的优选算法之一。
# 2. PARDISO算法的理论基础
## 2.1 直接求解器与迭代求解器
### 2.1.1 理解直接求解器的工作原理
直接求解器在数值线性代数中是指那些能够通过有限步骤的运算,直接求得线性方程组解的算法。这类求解器的核心在于分解系数矩阵,将其转化为若干更简单的矩阵运算,最终得到结果。
以LU分解为例,当我们要解决一个线性方程组 Ax=b 时,LU分解会将矩阵A分解为一个下三角矩阵L和一个上三角矩阵U,使得A=LU。然后通过前向替换和后向替换求解Ly=b和Ux=y,进而得到原问题的解x。
```math
A = LU
Ly = b
Ux = y
```
LU分解在PARDISO算法中是其核心组成部分之一。PARDISO能够处理大规模的稀疏矩阵,其工作原理是通过高效的符号分解和数值分解,快速获得LU分解的因子,以实现对线性方程组的求解。然而,对于大型稀疏矩阵,直接求解器需要考虑存储空间和计算复杂度,通常需要特别的优化策略。
### 2.1.2 迭代求解器的基本概念及其优缺点
与直接求解器不同,迭代求解器是通过迭代逼近的方法来求解线性方程组。迭代求解器的核心是通过选择合适的迭代格式,不断逼近线性方程组的解,直至满足一定的误差要求。
Krylov子空间方法是迭代求解器中非常流行的一类,包括共轭梯度法(CG)、广义最小残差法(GMRES)等。这些方法特别适合大型稀疏系统,因为它们只利用稀疏矩阵的非零元素进行计算,从而显著降低计算资源的需求。
```math
x^{(k+1)} = x^{(k)} + α_k p_k
```
其中,\( x^{(k)} \) 是第k次迭代的近似解,\( p_k \) 是搜索方向,\( α_k \) 是步长。
迭代求解器的一个主要优势是它可以处理大型问题,且不会对内存有特别高的要求。但这种方法的缺点在于它依赖于初始猜测,且收敛速度可能较慢,需要合适的预处理器来加速收敛过程。此外,对于某些问题,迭代求解器可能不收敛。
## 2.2 PARDISO算法的工作原理
### 2.2.1 PARDISO的数学模型和算法流程
PARDISO算法是基于直接方法的一种稀疏线性方程组求解器。它采用的是因子化方法,具体来说是基于不完全LU分解的技术。该算法的数学模型可以简化为以下形式:
```math
A ≈ L U
```
其中,\( A \) 是给定的系数矩阵,\( L \) 和 \( U \) 是因子矩阵。求解过程中,原矩阵 \( A \) 被分解为 \( L \) 和 \( U \),然后通过前向和后向替换求解方程。
PARDISO算法的流程可以划分为以下几个步骤:
1. 分析(Analyse):这一步骤涉及对矩阵A进行符号分解,以确定填入(fill-in)的数量,这有助于优化存储和计算效率。
2. 因子化(Factorize):在这一步骤,实际的数值分解发生,计算得到矩阵L和U。
3. 前向和后向替换(Solve):利用分解得到的L和U,通过前向替换和后向替换求解Ly=b和Ux=y,从而得到原线性方程组的解x。
PARDISO通过使用多线程和矩阵分块等技术,显著提升了算法的性能,使其特别适合于大规模并行计算环境。
### 2.2.2 核心优化技术与策略
PARDISO算法的核心优化技术主要体现在以下几个方面:
- **多线程并行计算**:PARDISO利用多核处理器的并行计算能力,对算法的不同部分进行并行处理,提升计算效率。
- **矩阵分块技术**:通过将大矩阵分割成较小的块(block),PARDISO可以降低内存使用,并提高缓存的命中率。
- **数值稳定性增强**:PARDISO算法通过引入校正步骤和检查点机制,增强了解决问题的数值稳定性。
- **适应性预处理**:预处理技术在PARDISO中被用于提高迭代求解器的收敛速度和稳定性,尤其是对于某些病态系统。
```mermaid
graph TD;
A[开始] --> B[分析矩阵结构]
B --> C[进行数值分解]
C --> D[前向替换求解Ly=b]
D --> E[后向替换求解Ux=y]
E --> F[得到解x]
F --> G[结束]
```
## 2.3 算法性能评估指标
### 2.3.1 吞吐量与计算速度
在衡量PARDISO算法的性能时,有两个关键指标是吞吐量和计算速度。
- 吞吐量:通常指的是在固定时间内,算法可以解决多少个问题,或者达到特定规模问题的解决数量。在并行计算环境中,这直接关联到核心数和线程数对性能的提升。
- 计算速度:指的是解决单个问题所需的平均时间。这包括了分析、因子化和解算各个步骤的综合耗时。
在实际应用中,算法的吞吐量和计算速度受到诸如处理器速度、内存带宽、系统架构等硬件因素的限制,同时也受到算法本身优化程度的影响。
代码块中的计算逻辑和参数说明:
```python
import pardiso as ps
import numpy as np
# 初始化PARDISO求解器
pt = ps.ProblemType(real=ps.ProblemType.REALSymm)
mtype = ps.Mtype(-2) # 矩阵类型
# 设置矩阵和向量
A = np.array(...) # 系数矩阵
b = np.array(...) # 结果向量
# 创建求解器实例
solver = ps.Solver(pt=pt, mtype=mtype)
# 分析阶段
solver анализ(A=A)
# 因子分解阶段
solver факторизует(A=A)
# 解算阶段
x = solver решить(A=A, b=b)
# 输出结果
print(x)
```
在这段代码中,`pardiso`库被用于执行PARDISO算法。在实际使用中,可以通过调整`mtype`参数(矩阵类型)以及增加诸如`iparm`(整型控制参数)和`dparm`(实型控制参数)来进行性能优化。
### 2.3.2 稳定性与可扩展性分析
稳定性是评价数值算法性能的重要指标之一,特别是在处理病态问题时。PARDISO算法采用预处理技术和不完全LU分解来增强数值稳定性,确保算法的计算结果具有足够的可靠性。
可扩展性则是指算法在不同规模的问题以及不同硬件配置下,其性能是否可以随着硬件资源的增加而提升。PARDISO算法具备良好的水平和垂直扩展性:
- **水平扩展性**:指的是在增加处理器个数的情况下,算法性能如何提升。PARDISO支持多线程并行计算,能够在多核处理器上有效扩展。
- **垂直扩展性**:指在单个处理器核心上,算法性能随硬件性能的提升情况。PARDISO算法在优化内存使用和减少计算步骤方面做出了努力,能在单个处理器上获得更好的性能表现。
在实际应用中,评估PARDISO的稳定性和可扩展性需要进行一系列基准测试和实际问题的求解,通过与已知最优解的比较以及在不同计算资源下的性能对比,来全面了解算法的性能表现。
# 3. PARDISO算法的配置与调优
在高性能计算中,算法的配置与调优是至关重要的一步。适当的配置不仅可以提升算法的执行效率,还能够减少计算资源的浪费。PARDISO作为一款高效的直接求解器,其性能的发挥在很大程度上取决于正确的配置与调优。本章将深入探讨PARDISO算法的系统资源管理、参数详解以及性能监控与故障排查方法,以帮助读者更好地理解和应用PARDISO算法。
## 3.1 系统资源管理
### 3.1.1 CPU亲和性设置
CPU亲和性,也称为处理器亲和性或CPU绑定,是指将进程或线程绑定到特定的CPU核心上执行,以优化性能。对于多核处理器系统,合理设置CPU亲和性可以减少上下文切换,提升缓存的局部性,从而改善计算效率。PARDISO算法通常需要大量的计算资源,因此对CPU亲和性的设置尤为重要。
在Linux系统中,可以使用`taskset`命令或在运行程序时指定CPU亲和性。例如,如果你的程序是`pardiso_example`,并希望将其限制在CPU核心0和1上运行,可以使用以下命令:
```bash
taskset -c 0,1 ./pardiso_example
```
在程序中设置CPU亲和性,可以使用如下代码:
```
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【瑞美LIS系统第三方接口手册】:10个专业步骤与技巧助您成功集成

# 摘要
本文全面介绍了瑞美LIS系统的概念、第三方接口的功能及集成实践。首先概述了瑞美LIS系统的基本架构,并详细阐述了其第三方接口的定义、通信协议和数据交换格式。接着,文中分析了系统集成前的各项准备工作,包括环境要求、接入规范和功能测试计划。随后,文章着重介绍了第三方接口集成的实际操作,包括认证授权、异常处理机制和性能优化技巧。通过集成案例分析,本文展示了瑞美LIS系统集成的成功经验和故
【r3epthook内部机制】:揭秘其工作原理及效率提升秘诀

# 摘要
本文深入探讨了r3epthook技术,揭示了其定义、组成、工作原理以及核心功能。通过对性能分析、代码优化和系统资源管理的探讨,文章提供了提升r3epthook效率的实用策略。文中进一步分析了r3epthook在安全、性能监控
硬件设计师必备:【PCIe-M.2接口规范V1.0应用指南】

# 摘要
PCIe-M.2接口作为一种广泛应用的高速接口技术,已成为移动设备、服务器和工作站等领域的关键连接方式。本文首先概述了PCIe-M.2接口规范,并深入解析了其技术细节,包括物理特性
安信负载均衡器监控:实时性能跟踪与流量分析
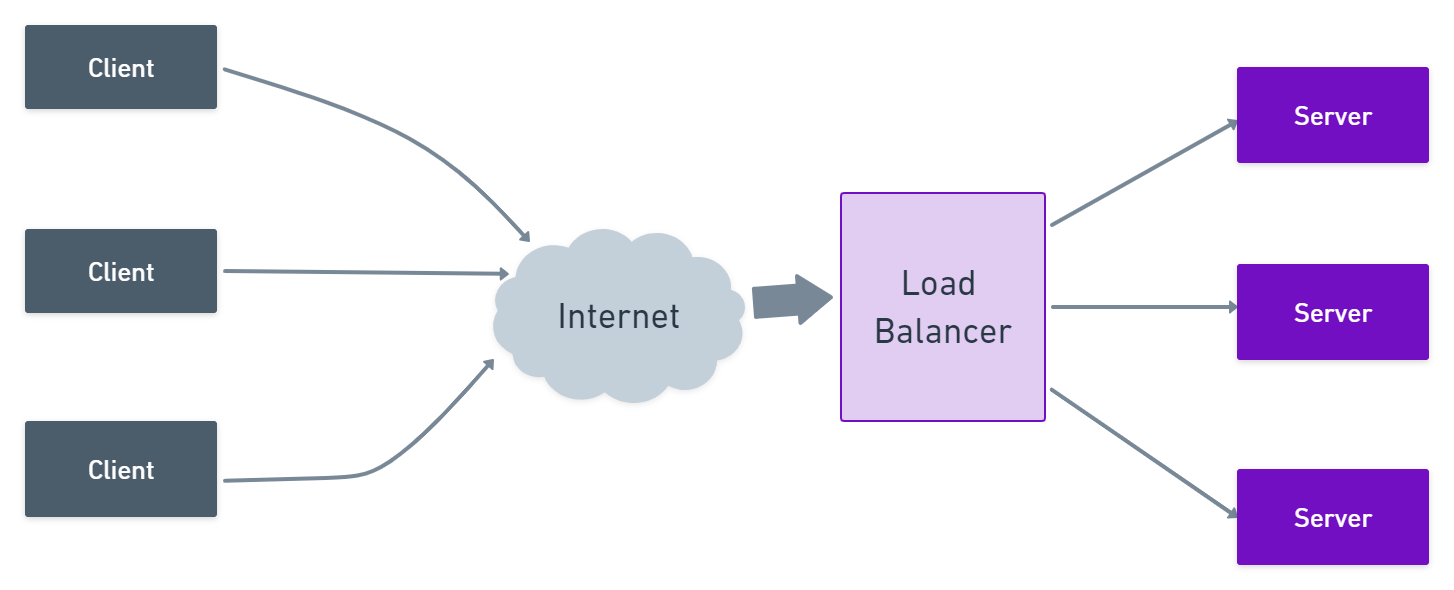
# 摘要
负载均衡器作为现代网络架构的关键组件,其监控和性能优化对于确保网络服务质量至关重要。本文首先概述了负载均衡器的基础知识及其监控的重要性,随后深入分析了负载均衡器的关键性能指标(KPIs)和流量分析技术。文章详细讨论了性能指标的监控、数据收集及实时跟踪与可视化方法,提供了流量分析工具的配置与使用案例研究。进一步,本文探讨了负载均衡器监控系统的高级应用,包括自动化报警、故障预测和负载均衡策
数据库索引优化的终极秘籍:提升性能的黄金法则
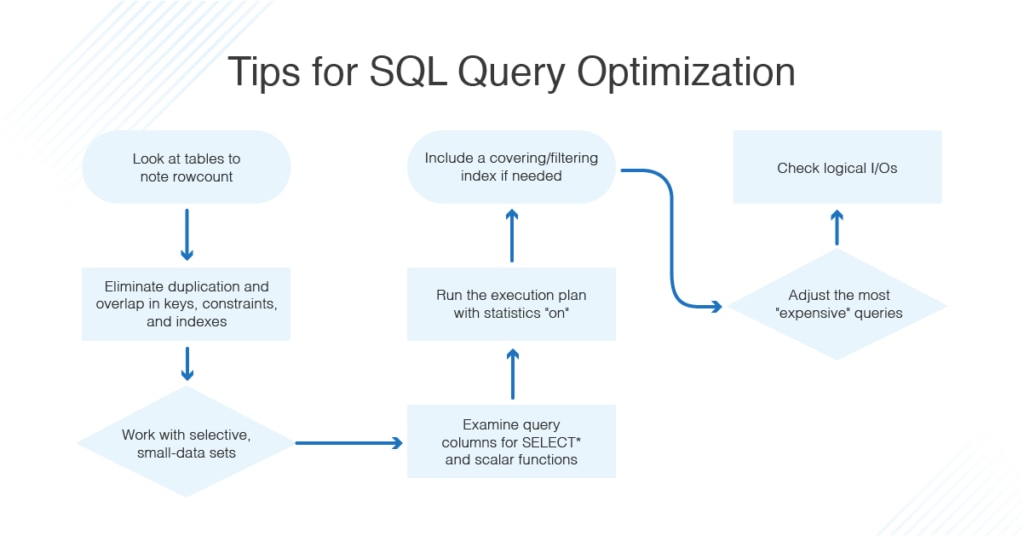
# 摘要
数据库索引是提高查询效率和管理数据的关键技术。本文对数据库索引进行了全面的概述,强调其在提升数据库性能方面的重要性。通过介绍各种索引类型(如B-Tree、哈希和全文索引)及其工作原理,本文揭示了数据检索过程和索引维护的内在机制。进一步,本文探索了索引优化的实践技巧,包括创建与调整、案例分析以及避免常见陷阱,旨在提供实际操作中的有效指导。高
硬件架构揭秘:LY-51S V2.3开发板硬件组成与连接原理详解
# 摘要
本文对LY-51S V2.3开发板进行了全面的介绍和分析,涵盖了硬件组成、连接原理、网络通讯、开发环
CarSim Training2参数扩展实战:外挂模块开发与自定义攻略
# 摘要
本文旨在探讨CarSim软件环境下外挂模块开发和自定义攻略的集成,为开发者提供从基础理论到实际应用的全面指导。首先,介绍了CarSim参数扩展基础和外挂模块开发的关键概念。接着,深入分析了外挂模块的设计、实现与测试流程,以及在CarSim软件架构中参数扩展的方法和工具。文中还阐述了自定义攻略的设计原则、开发工具选择和测试优化策略。最后,通过案例研究,分享了外挂模块与自定义攻略
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )