Python爬虫入门及实战技巧
发布时间: 2023-12-08 14:11:29 阅读量: 24 订阅数: 21 
# 1. Python爬虫简介
## 1.1 什么是爬虫
爬虫是一种自动化程序,能够模拟人的行为对互联网上的内容进行自动获取和处理。通过发送HTTP请求,爬虫可以获取网页的HTML源代码,并从中提取所需的数据。爬虫通常用于数据采集、信息提取、数据分析等领域。
## 1.2 爬虫的应用领域
爬虫在各个行业都有广泛的应用,包括但不限于以下几个领域:
- 搜索引擎:搜索引擎通过爬虫程序获取互联网上的网页内容,并建立索引,以便用户进行快速搜索。
- 数据采集:爬虫可以帮助用户从大量的网页中抓取所需的数据,例如商品信息、新闻文章等。
- 金融分析:爬虫可以获取金融数据,帮助分析师进行股票走势分析、价格预测等。
- 社交媒体监控:爬虫可以监控社交媒体上的热点话题、用户评论等信息,用于舆情分析和市场调研。
## 1.3 Python在爬虫中的优势
Python是一门易学易用的编程语言,适合初学者入门。在爬虫领域,Python有以下优势:
- 简洁优雅:Python的语法简单明了,代码可读性强,便于维护和扩展。
- 强大的库支持:Python拥有许多强大的爬虫库,如Requests、BeautifulSoup、Scrapy等,能够满足各种爬取需求。
- 多线程/多进程支持:Python提供了多线程和多进程的支持,可以加快爬虫的速度,提高效率。
- 跨平台性:Python可以在多个操作系统上运行,包括Windows、Linux和MacOS,便于开发和部署。
以上是Python爬虫简介的内容,接下来我们将进入第二章节,介绍爬虫的准备工作。
# 2. 准备工作
### 2.1 安装Python环境
在开始之前,首先要确保你的电脑已经安装了Python环境。Python是一种高级动态类型的编程语言,非常适合用来开发爬虫程序。你可以从官方网站[https://www.python.org](https://www.python.org)下载并安装最新的Python版本。根据你的系统是 Windows、Mac 还是 Linux,选择相应的安装包。安装Python的过程非常简单,按照提示一步一步进行即可。
### 2.2 安装必要的爬虫库
在爬取网页数据时,我们需要使用一些第三方库来帮助我们完成任务。以下是一些最常用的爬虫库:
- **Requests**:用于发送HTTP请求和接收响应。
- **Beautiful Soup**:用于解析HTML页面,提取需要的信息。
- **Selenium**:用于模拟浏览器行为,爬取动态网页数据。
你可以使用Python的包管理工具`pip`来安装这些库。打开终端或命令提示符,运行以下命令来安装这些库:
```python
pip install requests
pip install beautifulsoup4
pip install selenium
```
### 2.3 编辑器和IDE选择
在编写爬虫程序时,可以选择适合自己的编辑器或集成开发环境(IDE)。以下是几个常见的选择:
- **VS Code**:一个轻量级的代码编辑器,支持多种编程语言,强大的插件生态系统。
- **PyCharm**:一个专门为Python开发设计的IDE,提供完整的功能和调试工具。
- **Sublime Text**:一个强大的文本编辑器,功能丰富,可扩展性强。
选择适合自己的工具可以提高开发效率和舒适度。无论你选择哪个工具,我们主要关注的是编写代码的质量和逻辑。
现在,我们已经准备好开始学习Python爬虫的基础知识了。在接下来的章节中,我们将逐步深入了解如何使用Python进行网页爬取,并通过实战项目来巩固所学的知识。
# 3. 基础知识
爬虫技术的基础知识是非常重要的,本章将介绍爬虫中常用的基础知识,包括HTTP协议基础、构建URL和请求、解析HTML页面等内容。让我们一起来深入了解。
#### 3.1 HTTP协议基础
HTTP是HyperText Transfer Protocol(超文本传输协议)的缩写,是用于从网络传输超文本数据到本地浏览器的协议。在爬虫中,我们需要了解HTTP协议的基本原理,包括请求方法、状态码、请求头、响应头等内容。
```python
# Python示例代码
import requests
response = requests.get('https://www.example.com')
print(response.status_code) # 打印状态码
print(response.headers) # 打印响应头
```
##### 3.2 构建URL和请求
在爬虫中,我们需要向目标网站发送HTTP请求,获取想要的数据。构建URL和请求是非常关键的一步,包括GET请求和POST请求的使用。
```python
# Python示例代码
import requests
url = 'https://www.example.com/login'
data = {'username': 'user', 'password': '123456'}
response = requests.post(url, dat
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python学生信息管理系统》是一本专注于教授Python编程的专栏。专栏分为多个章节,涵盖了Python的基础知识以及各种应用领域。其中包括Python基础入门、条件语句与循环结构、函数与模块的使用、面向对象编程、异常处理与错误调试技巧等等。此外,专栏还介绍了Python文件操作与数据持久化存储、Python数据结构的应用、常用内置模块的使用、正则表达式与文本处理技巧、网络编程与并发编程、数据分析与可视化库、爬虫、数据库编程、机器学习、深度学习、自然语言处理以及Web开发等。通过该专栏,读者将掌握Python编程的核心概念和技巧,深入了解其广泛的应用领域,为日后实践开发提供强大的工具和知识支持。无论是初学者还是有一定编程经验的人士,该专栏都能提供帮助和指导,带领读者从入门到精通Python编程。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python Excel数据分析:统计建模与预测,揭示数据的未来趋势
# 1. Python Excel数据分析概述**
**1.1 Python Excel数据分析的优势**
Python是一种强大的编程语言,具有丰富的库和工具,使其成为Excel数据分析的理想选择。通过使用Python,数据分析人员可以自动化任务、处理大量数据并创建交互式可视化。
**1.2 Python Excel数据分析库**
OODB数据建模:设计灵活且可扩展的数据库,应对数据变化,游刃有余

# 1. OODB数据建模概述
对象-面向数据库(OODB)数据建模是一种数据建模方法,它将现实世界的实体和关系映射到数据库中。与关系数据建模不同,OODB数据建模将数据表示为对象,这些对象具有属性、方法和引用。这种方法更接近现实世界的表示,从而简化了复杂数据结构的建模。
OODB数据建模提供了几个关键优势,包括:
* **对象标识和引用完整性
【实战演练】综合自动化测试项目:单元测试、功能测试、集成测试、性能测试的综合应用

# 2.1 单元测试框架的选择和使用
单元测试框架是用于编写、执行和报告单元测试的软件库。在选择单元测试框架时,需要考虑以下因素:
* **语言支持:**框架必须支持你正在使用的编程语言。
* **易用性:**框架应该易于学习和使用,以便团队成员可以轻松编写和维护测试用例。
* **功能性:**框架应该提供广泛的功能,包括断言、模拟和存根。
* **报告:**框架应该生成清
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
Python map函数在代码部署中的利器:自动化流程,提升运维效率

# 1. Python map 函数简介**
map 函数是一个内置的高阶函数,用于将一个函数应用于可迭代对象的每个元素,并返回一个包含转换后元素的新可迭代对象。其语法为:
```python
map(function, iterable)
```
其中,`function` 是要应用的函数,`iterable` 是要遍历的可迭代对象。map 函数通
Python脚本调用与区块链:探索脚本调用在区块链技术中的潜力,让区块链技术更强大

# 1. Python脚本与区块链简介**
**1.1 Python脚本简介**
Python是一种高级编程语言,以其简洁、易读和广泛的库而闻名。它广泛用于各种领域,包括数据科学、机器学习和Web开发。
**1.2 区块链简介**
区块链是一种分布式账本技术,用于记录交易并防止篡改。它由一系列称为区块的数据块组成,每个区块都包含一组交易和指向前一个区块的哈希值。区块链的去中心化和不可变性使其
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】自动驾驶中的多任务强化学习
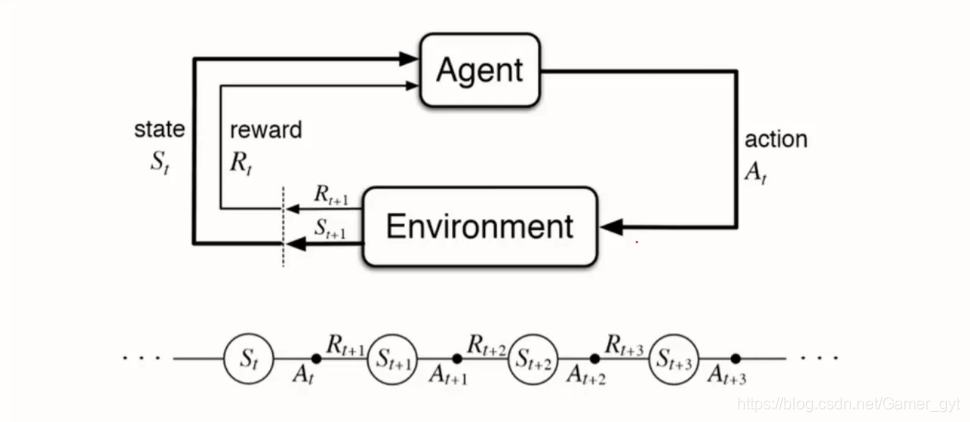
# 2.1 强化学习的基本概念
### 2.1.1 马尔可夫决策过程
马尔可夫决策过程 (MDP) 是强化学习中常用的数学模型,它描述了一个代理在环境中采取行动并接收
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )