【Python Coverage库入门指南】:掌握代码覆盖率测试的基础
发布时间: 2024-10-14 20:20:46 阅读量: 47 订阅数: 30 

# 1. 代码覆盖率测试的重要性
在软件开发领域,代码覆盖率测试是一种衡量测试用例执行程度的方法,它有助于开发者了解测试用例对代码库的覆盖情况。覆盖率测试的重要性体现在以下几个方面:
首先,它能够揭示代码中的未测试部分,这对于确保软件质量至关重要。通过分析覆盖率报告,开发者可以识别出未被测试覆盖到的代码行和分支,从而有针对性地编写更多的测试用例。
其次,代码覆盖率测试可以帮助开发者优化测试用例,提高测试的有效性和效率。在保证测试全面性的基础上,避免冗余的测试用例,减少测试成本。
最后,持续的覆盖率监控能够提供软件质量的持续反馈,使得开发者能够在开发过程中及时发现问题,改进代码结构,提升代码质量。
通过本章的深入分析,我们将了解代码覆盖率测试的必要性,并为后续章节中使用Python Coverage库进行覆盖率测试打下坚实的理论基础。
# 2. Python Coverage库的基本使用
## 2.1 安装和配置Coverage库
### 2.1.1 安装Coverage
在本章节中,我们将介绍如何安装和配置Python Coverage库,这是进行代码覆盖率测试的第一步。Coverage是一个流行的Python库,用于测量测试用例覆盖的代码百分比。它支持多种类型的覆盖率分析,包括语句覆盖、分支覆盖等。
首先,你需要确保你的系统上已经安装了Python环境。接下来,安装Coverage库相对简单,可以通过Python的包管理工具pip来完成。打开终端或命令提示符,输入以下命令来安装Coverage:
```bash
pip install coverage
```
安装完成后,你可以通过运行以下命令来验证Coverage是否正确安装:
```bash
coverage --version
```
如果安装成功,这个命令将输出Coverage的版本号。
### 2.1.2 配置Coverage
安装完Coverage后,你需要进行一些基本配置才能开始使用它。Coverage可以通过命令行参数或配置文件来配置。配置文件通常命名为`.coveragerc`,它是一个INI格式的文件,允许你设置各种选项。
一个简单的`.coveragerc`配置文件可能如下所示:
```ini
[run]
omit =
*/tests/*
*/__init__.py
```
在这个例子中,`[run]`是配置节的标题,`omit`是一个配置项,用于指定Coverage应该忽略的文件或目录。在这个例子中,我们指定Coverage忽略所有的测试文件和`__init__.py`文件。
## 2.2 Coverage的基本命令和功能
### 2.2.1 运行测试并收集覆盖率数据
通过本章节的介绍,我们将学习如何使用Coverage运行测试并收集覆盖率数据。Coverage提供了多种方式来运行测试并收集数据,最常用的方法是通过命令行工具。
假设你已经有了一个测试套件,使用`unittest`或`pytest`等测试框架。你可以使用Coverage来运行这些测试,并自动收集覆盖率数据。以下是使用Coverage运行`unittest`测试的示例:
```bash
coverage run -m unittest discover
```
如果你使用的是`pytest`,可以使用以下命令:
```bash
coverage run -m pytest
```
在这两个命令中,`run`命令告诉Coverage运行指定的测试模块或命令。`-m`参数后面跟的是Python模块或命令。
### 2.2.2 查看覆盖率报告
运行测试后,Coverage会生成覆盖率数据。为了查看覆盖率报告,你可以使用`report`命令:
```bash
coverage report
```
这个命令将显示一个简单的覆盖率报告,包括总代码行数、已执行行数和覆盖率百分比。如果需要更详细的报告,可以使用`html`命令生成HTML格式的报告:
```bash
coverage html
```
生成的HTML报告将包含一个详细的文件列表,每个文件都有颜色编码的覆盖率信息,绿色表示已覆盖,红色表示未覆盖。
### 2.2.3 生成覆盖率报告的多种格式
Coverage支持生成多种格式的报告,除了HTML之外,还可以生成XML或CSV格式的报告,以便与其他工具集成或进行进一步分析。例如,要生成XML格式的报告,可以使用以下命令:
```bash
coverage xml
```
生成的XML文件可以被持续集成服务器(如Jenkins)用来展示覆盖率趋势图。
## 2.3 Coverage的高级配置
### 2.3.1 排除特定文件或代码
有时候,你可能想要从覆盖率分析中排除某些文件或代码段,例如第三方库代码或生成的文件。通过本章节的介绍,我们将学习如何在Coverage配置中指定这些排除项。
在`.coveragerc`配置文件中,你可以使用`omit`选项来排除特定的文件或代码模式。例如,要排除所有的`test_*.py`测试文件,可以添加如下配置:
```ini
[run]
omit =
*/tests/*
*/__init__.py
*/test_*.py
```
除了在配置文件中指定排除项,你也可以在运行Coverage命令时临时指定排除项:
```bash
coverage run --omit=example.py,other_example.py -m unittest discover
```
### 2.3.2 集成到测试框架和持续集成系统
为了提高覆盖率测试的效率,你可以将Coverage集成到你的测试框架和持续集成系统中。这样,每次运行测试时,Coverage会自动收集覆盖率数据,无需手动运行额外的命令。
如果你使用的是`pytest`,可以安装`pytest-cov`插件来集成Coverage:
```bash
pip install pytest-cov
```
然后在运行pytest时加上`--cov`选项:
```bash
pytest --cov
```
在持续集成系统(如Travis CI、GitLab CI或Jenkins)中,你可以配置CI任务来自动运行带有Coverage的测试,并生成报告。例如,在Travis CI中,你可以在`.travis.yml`配置文件中添加以下脚本来运行Coverage:
```yaml
script:
- pip install coverage
- coverage run --parallel-mode -m pytest
- coverage report -m
- coverage xml
```
在这里,`--parallel-mode`选项允许Coverage在多进程模式下运行,这对于大型项目来说是非常有用的。
以上就是Python Coverage库的基本使用方法。在本章节中,我们介绍了如何安装和配置Coverage库,运行测试并收集覆盖率数据,以及如何生成不同格式的覆盖率报告。此外,我们还探讨了如何排除特定文件或代码,并将Coverage集成到测试框架和持续集成系统中。这些知识将帮助你在实际项目中有效地使用Coverage进行代码覆盖率测试,从而提高代码质量。
# 3. 代码覆盖率的分析与优化
#### 3.1 识别未覆盖的代码
在本章节中,我们将深入探讨如何通过代码覆盖率报告来识别未覆盖的代码,并进一步分析这些代码行的潜在影响。代码覆盖率报告是评估测试质量的重要工具,它可以帮助我们理解测试用例在代码中的执行范围。通过分析覆盖率报告,我们可以发现测试盲点,即那些未被测试覆盖到的代码区域。
##### 3.1.1 分析覆盖率报告
首先,我们需要了解如何解读覆盖率报告。覆盖率报告通常会显示每一行代码是否被执行,以及执行的频率。以下是覆盖率报告的一个简化示例:
```plaintext
File Stmts Miss Cover Missing
example.py 20 5 75% 10-14
TOTAL 20 5 75%
```
在这个示例中,`example.py` 文件有 20 行可执行语句,其中 5 行未被覆盖,覆盖率为 75%。`Missing` 列显示了未覆盖代码行的具体范围。
##### 3.1.2 定位未覆盖的代码行
接下来,我们需要定位这些未覆盖的代码行。在实际项目中,我们可以通过编写更详细的测试用例来覆盖这些代码。例如,如果我们发现一个条件判断语句未被覆盖,我们可以编写测试用例来模拟各种可能的输入情况。
```python
# example.py
def example_function(condition):
if condition:
# 代码块 A
pass
else:
# 代码块 B
pass
# 测试用例
def test_example_function():
# 测试代码块 A
example_function(True)
# 测试代码块 B
example_function(False)
```
通过上述测试用例,我们可以确保 `example_function` 中的两个代码块都被测试覆盖。
#### 3.2 提高代码覆盖率的策略
为了提高代码覆盖率,我们需要采取有效的策略。这些策略包括编写更全面的测试用例和重构代码结构。
##### 3.2.1 编写更全面的测试用例
编写全面的测试用例是提高代码覆盖率的关键。我们应该尽可能地模拟所有可能的输入情况,并验证预期的输出结果。这包括边界条件、异常情况以及正常流程。
```python
# 测试边界条件
def test_boundary_condition():
assert example_function(0) == "Boundary condition"
# 测试异常情况
def test_exception_case():
try:
example_function(None)
except TypeError:
assert True
else:
assert False
```
##### 3.2.2 重构和优化代码结构
有时候,代码的复杂性会导致难以编写测试用例。在这种情况下,重构代码结构可以帮助我们更好地进行测试。例如,我们可以将复杂的逻辑拆分成多个小函数,每个函数只负责单一的功能。
```python
# 重构前
def complex_function(input):
if input < 0:
return "Negative"
elif input == 0:
return "Zero"
else:
return "Positive"
# 重构后
def is_negative(input):
return input < 0
def is_zero(input):
return input == 0
def is_positive(input):
return input > 0
def simplified_function(input):
if is_negative(input):
return "Negative"
elif is_zero(input):
return "Zero"
else:
return "Positive"
```
通过上述重构,我们可以更容易地为每个小函数编写测试用例。
#### 3.3 覆盖率数据的深入分析
在本章节中,我们将深入分析覆盖率数据,包括复杂度和测试难度,以及如何结合覆盖率与其他质量指标。
##### 3.3.1 分析复杂度和测试难度
代码复杂度是影响测试难度的一个重要因素。我们可以使用如循环复杂度(Cyclomatic Complexity)这样的度量标准来评估代码复杂度。一般来说,循环复杂度越高,测试用例的数量和复杂度也越高。
```python
# 使用第三方库计算循环复杂度
from complexity import cyclomatic_complexity
def complex_function(input):
if input < 0:
return "Negative"
elif input == 0:
return "Zero"
else:
return "Positive"
# 计算复杂度
complexity = cyclomatic_complexity(complex_function)
print(f"Complexity: {complexity}")
```
##### 3.3.2 结合覆盖率与其他质量指标
最后,我们应该将覆盖率数据与其他质量指标结合起来考虑。例如,代码覆盖率虽然重要,但它并不能完全代表代码的质量。我们还需要考虑代码的可维护性、可读性和可重用性等指标。
```mermaid
flowchart LR
A[代码覆盖率] --> B[代码质量评估]
C[可维护性] --> B
D[可读性] --> B
E[可重用性] --> B
```
通过上述分析,我们可以更全面地理解代码的质量,并采取相应的措施进行优化。
# 4. Python Coverage库在实际项目中的应用
在本章节中,我们将深入探讨Python Coverage库在实际项目中的应用,包括单元测试、集成测试以及持续集成/持续部署(CI/CD)中的具体应用方式。我们将通过具体的操作步骤,代码示例,以及性能优化的讨论,为读者提供一个全面的视角,以便更好地理解和应用代码覆盖率测试。
## 4.1 Coverage在单元测试中的应用
在本章节介绍中,我们将探讨Coverage工具如何在单元测试中发挥作用。通过监控单元测试覆盖率,我们可以识别出哪些代码还未被测试覆盖,进而优化测试用例和提升代码质量。
### 4.1.* 单元测试覆盖率的监控
Coverage库可以在单元测试执行时,监控代码的覆盖率。这意味着,它不仅可以告诉你哪些代码被测试覆盖了,哪些没有,还可以帮助你理解测试用例的全面性。
#### *.*.*.* 配置Coverage监控单元测试
首先,确保你已经安装了Coverage库,并且你的项目中有单元测试。接下来,你可以通过以下命令来运行你的单元测试,并监控覆盖率:
```bash
coverage run --source=your_module -m unittest discover
```
在这个命令中:
- `--source=your_module` 指定了需要监控覆盖率的模块。
- `-m unittest discover` 使用`unittest`模块来发现并运行所有单元测试。
#### *.*.*.* 查看单元测试覆盖率报告
运行上述命令后,Coverage会生成一个默认的HTML格式的覆盖率报告。你可以通过以下命令来查看这个报告:
```bash
coverage html
```
然后,打开生成的`htmlcov/index.html`文件,你将看到一个详细的覆盖率报告,如下图所示:
中的应用
在现代的软件开发流程中,CI/CD是一种常见的实践,它要求代码提交后自动运行测试并提供反馈。Coverage可以在这一流程中发挥重要作用,确保代码质量的同时,还能够自动监控覆盖率。
### 4.3.1 在CI/CD流程中集成Coverage
在CI/CD流程中,Coverage可以与各种CI工具(如Jenkins、Travis CI、GitLab CI等)集成,以自动监控代码覆盖率。
#### *.*.*.* 集成Coverage到CI工具
以Jenkins为例,你可以在Jenkins的流水线中添加Coverage的步骤。例如,使用Coverage的命令行工具来生成覆盖率报告,并将这些报告上传到Jenkins服务器。
### 4.3.2 自动化测试覆盖率监控和报告
通过将Coverage集成到CI/CD流程中,每次代码提交后都会自动运行测试并生成覆盖率报告。这样,团队可以持续监控代码覆盖率,并及时了解代码质量的变化。
#### *.*.*.* 设置自动化监控和报告
设置自动化监控和报告的步骤可能包括:
1. 在CI/CD配置中添加Coverage的步骤。
2. 配置Coverage生成报告。
3. 将覆盖率报告上传到一个可以访问的服务器或报告平台。
通过这些步骤,每次代码提交都会触发覆盖率监控和报告生成,帮助团队保持高代码质量。
以上就是对Python Coverage库在实际项目中应用的详细介绍。通过对单元测试、集成测试以及CI/CD流程中的应用分析,我们可以看到Coverage在确保代码质量方面的强大作用。希望这些信息能帮助你在自己的项目中更好地应用Coverage工具。
# 5. 深入学习和高级用法
在本章中,我们将深入探讨Python Coverage库的高级功能,以及如何将覆盖率数据存储和追踪历史记录。此外,我们还将对比Coverage与其他覆盖率测试工具,帮助你选择最适合自己项目的工具。
## 5.1 Coverage库的高级功能
### 5.1.1 覆盖率数据的导出和合并
Coverage库不仅可以生成HTML格式的覆盖率报告,还可以导出数据为多种格式,例如CSV或XML。这允许你将数据整合到其他报告工具或自定义分析脚本中。例如,以下命令将覆盖率数据导出为CSV格式:
```bash
coverage combine
coverage run --rcfile=.coveragerc
coverage report -m --format=csv > coverage.csv
```
在这里,`coverage combine`命令用于合并多个数据源的覆盖率数据,`--rcfile`参数指定配置文件。`coverage report`命令生成CSV格式的报告,其中`-m`参数表示包含缺失的行号。
### 5.1.2 自定义覆盖率报告格式
除了使用Coverage提供的标准报告格式,你还可以使用Python模板引擎自定义报告。例如,使用Jinja2模板引擎创建一个简单的HTML报告模板:
```python
# coverage_report_template.html
<html>
<head>
<title>Coverage Report</title>
</head>
<body>
<h1>Coverage Report for {{ project_name }}</h1>
<table>
{% for file in report.files %}
<tr><td>{{ file.filename }}</td><td>{{ file.coverage }}%</td></tr>
{% for line in file.lines %}
<tr>
<td>{{ line.number }}</td>
<td>{{ line.lineno }}</td>
<td>{{ line.content }}</td>
<td class="{{ 'covered' if line.covered else 'not-covered' }}">{{ line.covered }}</td>
</tr>
{% endfor %}
{% endfor %}
</table>
</body>
</html>
```
然后使用以下命令生成报告:
```bash
coverage report --rcfile=.coveragerc --format=html -o coverage_report.html coverage_report_template.html
```
在这里,`--format=html`参数指定报告格式,`-o`参数指定输出文件,`coverage_report_template.html`是模板文件。
## 5.2 覆盖率数据的存储和历史追踪
### 5.2.1 使用数据库存储覆盖率数据
Coverage库支持将数据存储到数据库中,这样可以方便地进行数据追踪和历史分析。例如,使用MySQL数据库存储覆盖率数据,你可以在`.coveragerc`配置文件中指定数据库连接:
```ini
[coverage:run]
data_file = sql://user:password@host/dbname/coverage.db
```
### 5.2.2 覆盖率历史数据的分析和追踪
使用数据库存储覆盖率数据后,你可以编写SQL查询或使用数据分析工具(如Python的Pandas库)来分析历史数据。例如,以下SQL查询可以获取最近10次构建的覆盖率总览:
```sql
SELECT timestamp, total_lines, covered_lines, coverage
FROM coverage_data
ORDER BY timestamp DESC
LIMIT 10;
```
## 5.3 探索其他覆盖率测试工具
### 5.3.1 对比Coverage与其他覆盖率工具
Coverage是Python中最流行的覆盖率工具之一,但还有其他工具如PyTest Coverage插件或Nose Coverage等。这些工具可能提供额外的功能,如并行测试覆盖率收集、更详细的报告等。下表总结了这些工具的主要特点:
| 特性/工具 | Coverage | PyTest Coverage | Nose Coverage |
|-------------------|----------|-----------------|---------------|
| 支持语言 | Python | Python | Python |
| 并行测试支持 | 否 | 是 | 是 |
| HTML报告 | 是 | 是 | 是 |
| 数据存储 | 文件/数据库 | 文件/数据库 | 文件/数据库 |
| 集成到CI系统 | 是 | 是 | 是 |
| 配置复杂度 | 中等 | 低 | 低 |
### 5.3.2 如何选择合适的覆盖率测试工具
选择合适的覆盖率工具时,应考虑以下因素:
- **项目需求**:是否需要并行测试、特定格式的报告等。
- **团队熟悉度**:团队成员是否熟悉某些工具。
- **集成与扩展性**:工具是否能轻松集成到现有的测试和CI/CD流程中。
- **文档和社区支持**:是否有详细的文档和活跃的社区支持。
通过上述分析,你可以根据项目的具体需求选择最适合的覆盖率测试工具。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Python Coverage库专栏是一个全面的指南,涵盖了使用Python Coverage库进行代码覆盖率测试的所有方面。专栏从入门指南开始,介绍了代码覆盖率测试的基础知识,并逐步深入探讨了Coverage库的特性和功能。它提供了案例研究和高级技巧,展示了如何使用Coverage库解决常见的覆盖率问题并优化开发流程。专栏还涵盖了Coverage库在性能优化、可视化、CI/CD集成和安全测试中的应用。通过深入理解代码分支覆盖和扩展性分析,专栏提供了全面了解Coverage库及其在代码质量保证中的作用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
大规模深度学习系统:Dropout的实施与优化策略
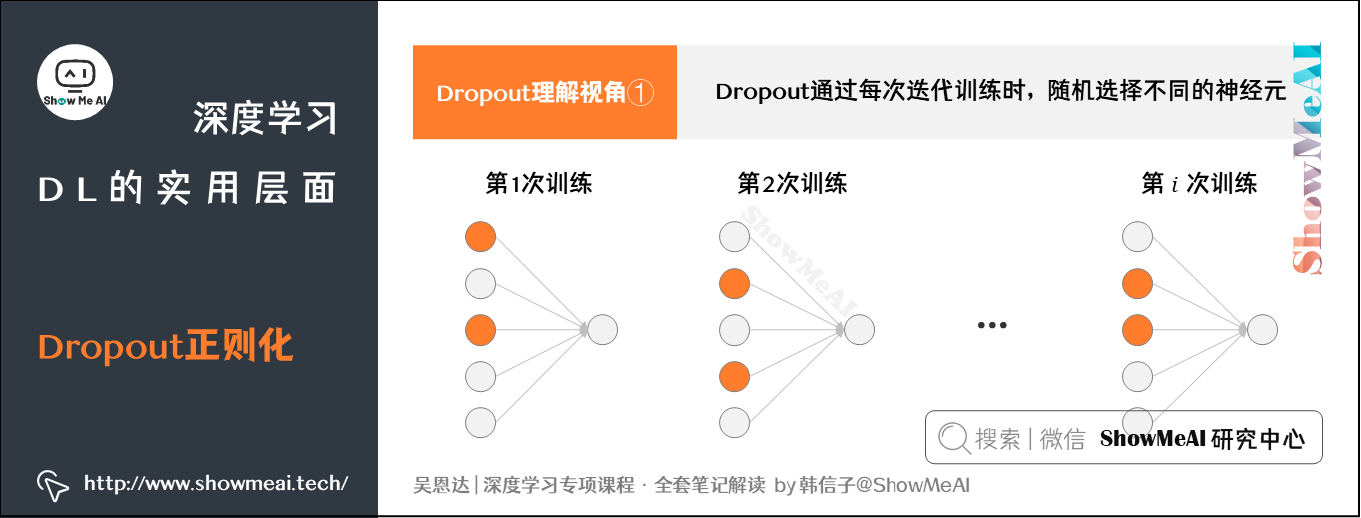
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
自然语言处理中的过拟合与欠拟合:特殊问题的深度解读
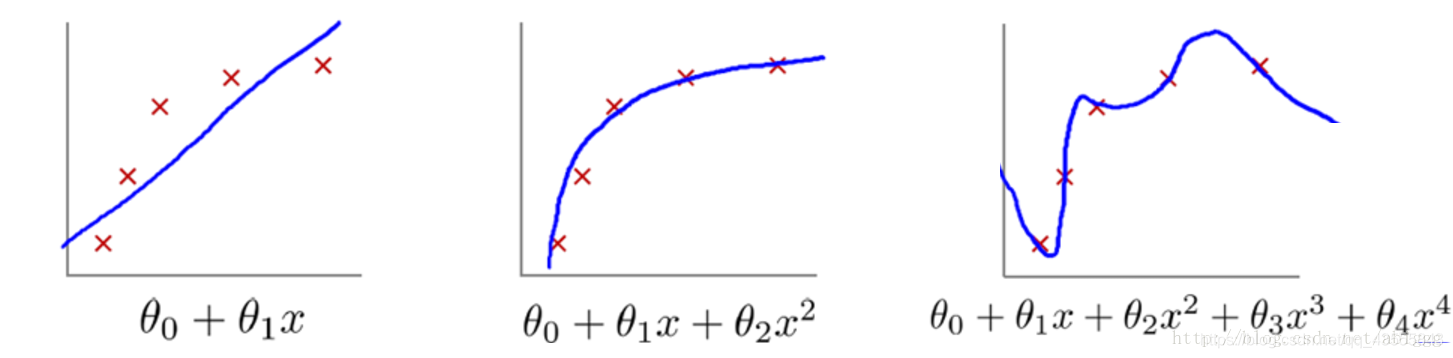
# 1. 自然语言处理中的过拟合与欠拟合现象
在自然语言处理(NLP)中,过拟合和欠拟合是模型训练过程中经常遇到的两个问题。过拟合是指模型在训练数据上表现良好
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
【Lasso回归与岭回归的集成策略】:提升模型性能的组合方案(集成技术+效果评估)
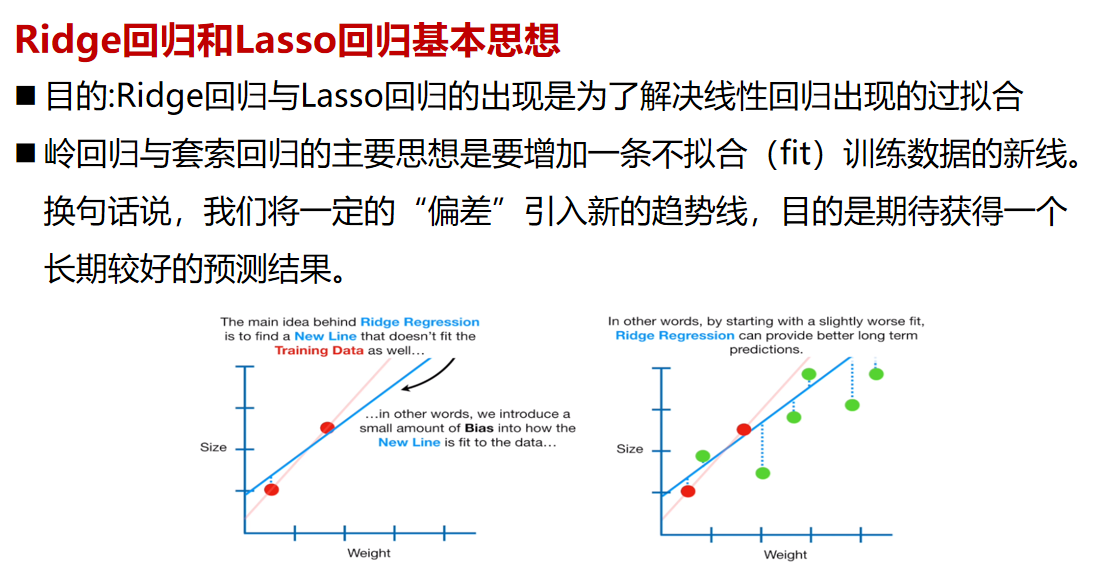
# 1. Lasso回归与岭回归基础
## 1.1 回归分析简介
回归分析是统计学中用来预测或分析变量之间关系的方法,广泛应用于数据挖掘和机器学习领域。在多元线性回归中,数据点拟合到一条线上以预测目标值。这种方法在有多个解释变量时可能会遇到多重共线性的问题,导致模型解释能力下降和过度拟合。
## 1.2 Lasso回归与岭回归的定义
Lasso(Least
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
【过拟合克星】:网格搜索提升模型泛化能力的秘诀

# 1. 网格搜索在机器学习中的作用
在机器学习领域,模型的选择和参数调整是优化性能的关键步骤。网格搜索作为一种广泛使用的参数优化方法,能够帮助数据科学家系统地探索参数空间,从而找到最佳的模型配置。
## 1.1 网格搜索的优势
网格搜索通过遍历定义的参数网格,可以全面评估参数组合对模型性能的影响。它简单直观,易于实现,并且能够生成可重复的实验结果。尽管它在某些
推荐系统中的L2正则化:案例与实践深度解析
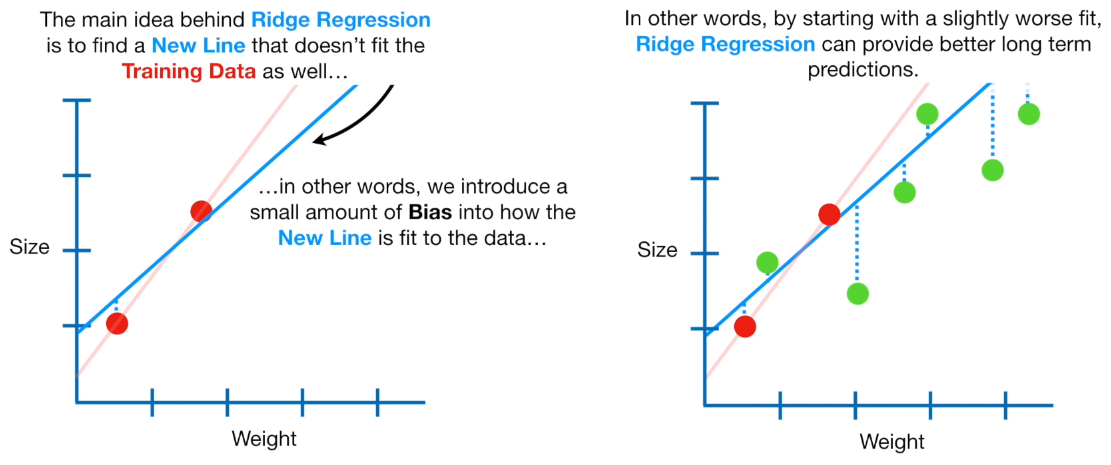
# 1. L2正则化的理论基础
在机器学习与深度学习模型中,正则化技术是避免过拟合、提升泛化能力的重要手段。L2正则化,也称为岭回归(Ridge Regression)或权重衰减(Weight Decay),是正则化技术中最常用的方法之一。其基本原理是在损失函数中引入一个附加项,通常为模型权重的平方和乘以一个正则化系数λ(lambda)。这个附加项对大权重进行惩罚,促使模型在训练过程中减小权重值,从而达到平滑模型的目的。L2正则化能够有效地限制模型复
预测建模精准度提升:贝叶斯优化的应用技巧与案例

# 1. 贝叶斯优化概述
贝叶斯优化是一种强大的全局优化策略,用于在黑盒参数空间中寻找最优解。它基于贝叶斯推理,通过建立一个目标函数的代理模型来预测目标函数的性能,并据此选择新的参数配置进行评估。本章将简要介绍贝叶斯优化的基本概念、工作流程以及其在现实世界
机器学习中的变量转换:改善数据分布与模型性能,实用指南
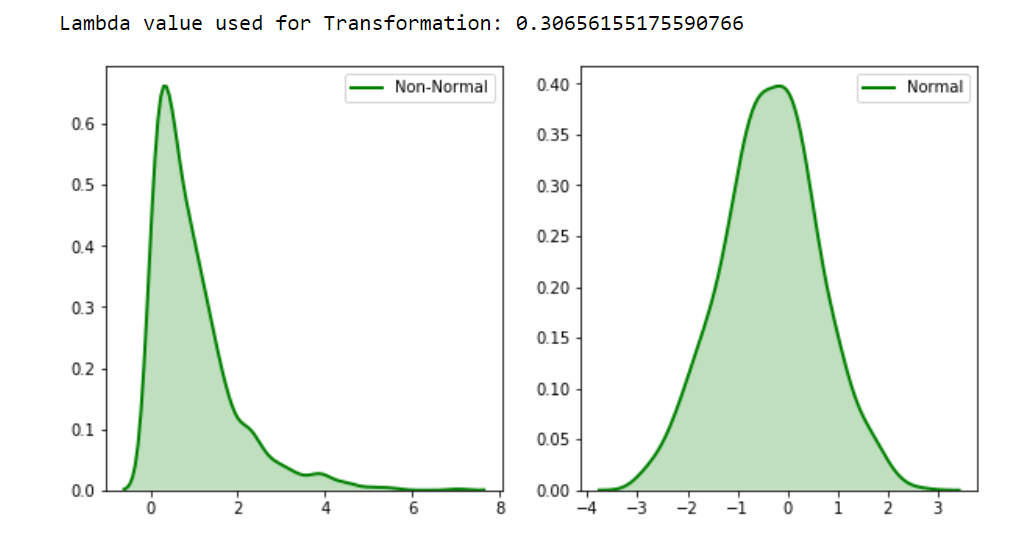
# 1. 机器学习与变量转换概述
## 1.1 机器学习的变量转换必要性
在机器学习领域,变量转换是优化数据以提升模型性能的关键步骤。它涉及将原始数据转换成更适合算法处理的形式,以增强模型的预测能力和稳定性。通过这种方式,可以克服数据的某些缺陷,比如非线性关系、不均匀分布、不同量纲和尺度的特征,以及处理缺失值和异常值等问题。
## 1.2 变量转换在数据预处理中的作用
神经网络训练中的ANOVA应用:数据驱动的模型调优(深度学习进阶)

# 1. ANOVA在神经网络中的作用和原理
## 1.1 ANOVA概念简介
方差分析(ANOVA)是一种统计方法,用于检测三个或更多个样本均值之间是否存在显著差异。在神经网络领域,ANOVA不仅帮助理解输入变量对输出的影响程度,还能指导特征工程和模型优化。通过对输入特征的方差进行分解和比较,ANOVA提供了一种量化各特征对输出贡献
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )