DFA最小化:揭秘编译原理中代码优化的4大策略
发布时间: 2024-12-15 08:51:17 阅读量: 4 订阅数: 4 
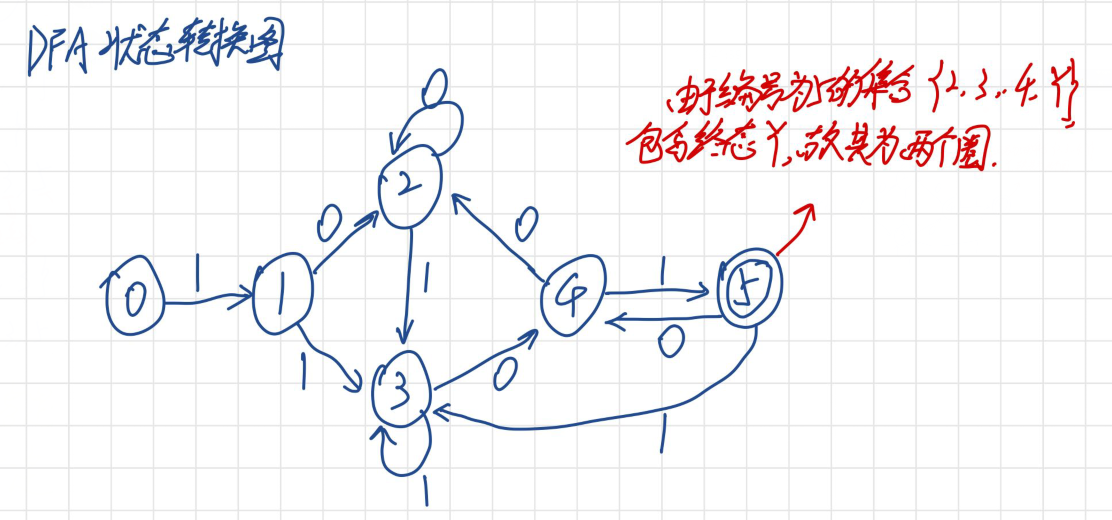
参考资源链接:[C++实现DFA最小化的编译原理实验代码](https://wenku.csdn.net/doc/2jxuncpikn?spm=1055.2635.3001.10343)
# 1. DFA最小化的理论基础
## 确定有限自动机(DFA)的定义
确定有限自动机(DFA)是一类计算模型,它由有限状态、有限输入符号集合、一个起始状态、一组接受状态以及一个转移函数组成。DFA可以被视作定义了特定语言识别规则的模型,即对于给定的输入序列,DFA能够根据转移函数确定地从一个状态转移到另一个状态,并最终判定输入序列是否被接受。
## DFA的状态和转换函数
DFA的状态是模型的内存部分,代表了在处理输入时的内部状态。转换函数定义了在给定当前状态和输入符号时,如何转移到下一个状态。每个输入符号对应一个唯一的转换动作,这是DFA确定性的核心特征。DFA的所有状态和转换函数共同定义了其动态行为,对于理解DFA的最小化至关重要。
DFA最小化的目标是减小DFA的规模而不改变其识别的语言,即在保持语言识别功能不变的前提下,减少不必要的状态和转换,这将使得DFA更加高效并降低实现成本。在实际应用中,最小化的DFA能有效减少存储空间的使用和加速识别过程,这对于设计高效的编译器和词法分析器等程序尤为重要。
# 2. DFA最小化的算法原理
## 2.1 DFA的概念和结构
### 2.1.1 确定有限自动机(DFA)的定义
DFA(确定有限自动机)是计算理论中的一个基本概念,它由一组有限的状态组成,每个状态都通过特定的转移函数定义了在输入字母表上的转换。DFA用于识别模式,例如编程语言中的关键字,或者用于解析数据格式。形式上,一个DFA可以定义为五元组(M, Σ, δ, q0, F),其中:
- M 是一个有限的状态集合。
- Σ 是输入符号的有限集合,也称为字母表。
- δ 是转移函数,δ: M × Σ → M。
- q0 是初始状态,属于状态集合M。
- F 是接受状态的集合,F ⊆ M。
### 2.1.2 DFA的状态和转换函数
DFA的状态可以被看作是机器在处理输入字符串时的内部“记忆”。每一个状态都预设了在接收到某个输入时应该转移到的新状态。转换函数 δ 则描述了状态之间的转移逻辑。在编程语言的词法分析器中,这些状态可能对应于不同的“状态”,例如等待数字、等待字母或者等待特殊字符等。
转换函数 δ 通常用状态转换图来表示,这是一个有向图,图中的节点是状态,边上的标签是输入符号,并且边指向另一个状态,表示在读取到对应的输入符号时,自动机应该转移到的新状态。
## 2.2 DFA最小化的过程
### 2.2.1 等价状态的合并原理
DFA最小化是将DFA转换成等价的最小DFA的过程,即找到一个状态数尽可能少的等价DFA。最小化DFA的过程基于等价状态的合并原理,即两个状态如果无法在任何输入字符串下区分,它们就是等价的,可以合并为一个状态。
为了判断两个状态是否等价,可以使用两个状态区分算法(区分算法)。如果两个状态对于字母表中的每一个输入符号,都有相同的转移行为,并且它们都属于接受状态或都不是接受状态,那么这两个状态是不可区分的。
### 2.2.2 最小化算法的步骤和条件
最小化DFA的步骤通常包括:
1. 标记区分状态。
2. 创建一个等价类的初始划分,将所有接受状态分为一类,所有非接受状态分为另一类。
3. 在每个等价类中,根据输入符号进一步细分状态,直到没有新的划分可以进行。
4. 合并无法区分的状态,构建出新的DFA。
最小化过程中要注意以下条件:
- 接受状态和非接受状态在最小化过程中不能合并。
- 如果两个状态对于某个输入符号的转移到达了不同的等价类,则这两个状态是区分的。
## 2.3 DFA最小化的复杂度分析
### 2.3.1 时间复杂度的探讨
DFA最小化的算法复杂度主要取决于状态的总数和字母表的大小。对于每一个状态,算法需要检查所有可能的输入符号对应的转移状态,因此时间复杂度至少是O(|M|^2 * |Σ|),其中|M|是状态的总数,|Σ|是字母表的大小。
### 2.3.2 空间复杂度的优化
为了优化空间复杂度,可以只存储必要的信息,例如状态转移表。如果使用邻接矩阵来表示状态转移关系,空间复杂度为O(|M|^2),因为它需要一个矩阵来记录所有可能的状态转移。如果使用邻接表或者其他稀疏数据结构,可以在不牺牲算法性能的前提下减少空间占用。
最小化算法的空间复杂度还可以通过延迟计算等策略来进一步优化。例如,只有在确定两个状态是否等价时才进行它们之间的比较。这样,算法可以避免不必要的计算,从而减少内存消耗。
## 2.4 示例代码块
```python
# 示例代码展示DFA的表示方法
class DFA:
def __init__(self, states, alphabet, transition, start_state, accept_states):
self.states = states
self.alphabet = alphabet
self.transition = transition
self.start_state = start_state
self.accept_states = accept_states
def get_next_state(self, current_state, input_symbol):
if current_state in self.states and input_symbol in self.alphabet:
return self.transition[(current_state, input_symbol)]
else:
return None
```
### 代码逻辑的逐行解读分析
```python
class DFA: # 定义DFA类
def __init__(self, states, alphabet, transition, start_state, accept_states):
self.states = states
self.alphabet = alphabet
self.transition = transition
self.start_state = start_state
self.accept_states = accept_states
```
- 初始化DFA对象时,需要定义状态集合、字母表、转移函数、初始状态和接受状态。
```python
def get_next_state(self, current_state, input_symbol):
if current_state in self.states and input_symbol in self.alphabet:
return self.transition[(current_state, input_symbol)]
else:
return None
```
- `get_next_state`方法用于获取在给定状态和输入符号下的下一个状态。如果输入的状态或符号不在定义范围内,则返回`None`。
通过上述代码,我们可以定义一个DFA并进行状态转移操作。这仅仅是DFA的表示方法之一,实际应用中可以根据需要进行扩展和优化。
# 3. 代码优化策略一:基于DFA的编译器优化
编译器优化是编程领域中对代码性能提升的关键技术之一,DFA(确定有限自动机)在其中扮演着重要角色。通过将源代码转换为机器语言的过程中,编译器能够进行多轮分析和转换,改善最终生成代码的执行效率。本章将深入探讨基于DFA的编译器优化策略,不仅介绍理论知识,而且会结合实际案例进行详细分析。
## 3.1 编译器优化的概述
### 3.1.1 优化的目标和分类
编译器优化的目的是提高程序的运行效率,降低程序的资源消耗。它主要分为两个层面:
1. **运行时效率**:减少程序运行时的时间和空间消耗,提升程序的性能。
2. **编译时效率**:减少编译过程的时间,缩短编译器的响应时间。
按照优化作用的范围,可分为:
- **局部优化**:仅对程序的某个基本块进行优化,不考虑全局影响。
- **全局优化**:涉及多个基本块或整个程序,考虑变量的全局属性和程序的全局结构。
### 3.1.2 优化阶段的作用和影响
优化通常在编译的不同阶段进行,包括:
- **前端优化**:主要关注源代码级别的优化,如死代码删除、公共子表达式消除等。
- **后端优化**:关注目标代码级别的优化,如指令调度、寄存器分配等。
优化阶段的设置对于编译器性能至关重要,合理的优化策略能够有效提升程序的运行效率。
## 3.2 DFA优化技术的应用
### 3.2.1 DFA在词法分析中的应用
词法分析是编译过程中的第一个阶段,负责将源代码文本分解成一个个有意义的符号。DFA是实现高效词法分析的理想选择,因为它能够将有限数量的模式匹配问题转化为状态机的遍历问题。
```mermaid
graph LR
A[开始分析] --> B[读取字符]
B --> C{匹配状态}
C -->|是| D[生成符号]
C -->|否| E[错误处理]
D --> F[返回开始]
E --> F
```
### 3.2.2 DFA在语法分析中的应用
在语法分析阶段,DFA可以被用来验证源代码的结构是否正确。例如,使用DFA检查括号是否正确匹配,引号是否成对出现等。这不仅提高了分析的准确性,也降低了错误代码通过的可能性。
```python
def check_parentheses(input_string):
stack = []
table = {'(': ')', '{': '}', '[': ']'}
for character in input_string:
if character in table:
stack.append(character)
elif character in table.values():
if not stack or table[stack.pop()] != character:
return False
return not stack
# 示例代码逻辑:
# - 遍历输入字符串中的每个字符。
# - 如果字符是开括号('(', '{', '['),则将其推入栈中。
# - 如果字符是闭括号,检查栈顶元素是否与之匹配。
# - 如果不匹配或栈为空,返回False。
# - 在字符串遍历结束后,如果栈不为空,则表示存在未匹配的开括号,返回False。
# - 如果以上条件均满足,则说明括号正确匹配,返回True。
```
## 3.3 案例分析:DFA最小化在编译器中的实践
### 3.3.1 典型编译器优化案例
以GCC(GNU Compiler Collection)为例,它在多个层面实现了DFA的优化策略。例如,在词法分析阶段,GCC使用了DFA来识别不同的词法单元(tokens),通过最小化状态机来减少编译时的计算量,提高了编译速度。
### 3.3.2 DFA最小化的实践效果评估
DFA最小化在实践中显著提升了编译器的运行效率。例如,在处理大型项目时,通过减少状态机的复杂度,DFA最小化能够降低内存使用并加快词法分析阶段的速度,从而缩短整个编译过程所需的时间。
```bash
# 使用GCC编译一个大型项目,观察优化前后的差异
gcc -O0 source_file.c -o output_without_opt
gcc -O3 source_file.c -o output_with_opt
# 记录编译时间
time ./output_without_opt
time ./output_with_opt
```
以上命令展示了如何在GCC编译器中使用不同的优化级别(`-O0` 为无优化,`-O3` 为最高优化级别),并记录编译和运行时间来评估优化效果。
# 4. 代码优化策略二:基于DFA的数据流分析
## 4.1 数据流分析的基础
### 4.1.1 数据流分析的定义和目的
数据流分析是编译器优化中的一项核心技术,其目的是在程序的不同执行点上,收集和传播程序变量的值信息。通过对程序中数据的流动和使用情况的分析,编译器能够进行各种优化决策,比如消除冗余计算、改进寄存器分配、进行常数传播等。数据流分析专注于程序数据的属性,而非控制流的结构,它关注的是数据在程序中是如何被使用和处理的。
在高级层面,数据流分析可以用于优化代码,以提高程序的性能、减少资源消耗。在代码层面,数据流分析有助于发现程序中的潜在错误,例如未初始化变量的使用、死代码等。其最终目的是提高程序的执行效率和可靠性。
### 4.1.2 数据流分析的类型和方法
数据流分析主要分为两大类:静态数据流分析和动态数据流分析。静态分析是在编译时完成的,而动态分析则在程序运行时进行。
静态分析主要包括以下几种方法:
- **局部数据流分析**:这种分析只考虑单个基本块(一段没有跳转指令的连续代码)内的数据流。
- **全局数据流分析**:分析整个程序或程序中的一个函数的所有基本块,以得到更全面的数据流信息。
动态数据流分析则依赖于程序运行时的具体路径,其主要包括:
- **路径敏感分析**:跟踪程序中每条可能执行路径的数据流信息。
- **路径不敏感分析**:忽略具体的执行路径,而是在程序的整个执行过程中进行分析。
### 4.1.3 数据流分析的实现方式
实现数据流分析的一种常见方式是构建数据流方程。数据流方程基于以下两个要素:
- **定义-使用链**:定义是程序中一个变量被赋予值的地方,而使用是指变量值被引用的地方。
- **数据流方程**:为每个基本块定义一组方程,描述数据是如何通过基本块的边界流动的。
这些方程通常采用前向分析或后向分析的方法来求解。前向分析从程序的入口开始,向后分析每个基本块;后向分析则从程序出口开始向前进行分析。
## 4.2 DFA在数据流分析中的角色
### 4.2.1 DFA状态与数据流信息的对应关系
在数据流分析中,DFA的状态可以对应于程序中变量的不同属性集合。比如,在活跃变量分析中,DFA的状态可以表示在特定程序点上活跃的变量集合。
### 4.2.2 DFA最小化对数据流分析的影响
通过DFA最小化技术,我们可以减少数据流分析中所需的内部状态数量,从而降低空间复杂度。DFA最小化可以移除不必要的状态,合并等价的状态,这样可以提高数据流分析的效率,特别是在全局分析中,可以显著减少分析所需的时间和内存资源。
## 4.3 实现数据流优化的DFA策略
### 4.3.1 算法实例:活跃变量分析
活跃变量分析是编译器中的一个经典数据流问题。它的目的是确定在程序的每个点上,哪些变量是“活跃”的,即这些变量的值将会被后续引用。
使用DFA进行活跃变量分析的步骤如下:
1. **定义DFA状态**:DFA状态为一组变量名的集合,表示在程序执行到某个点时活跃的变量。
2. **构建转换函数**:转换函数定义了在程序执行路径上状态之间的转移,通常是通过分析控制流图中的边来实现。
3. **初始化和迭代求解**:初始状态通常为空集合或包含入口点的变量,然后通过迭代地应用转换函数直到状态不再变化,即可求得最终的活跃变量集合。
### 4.3.2 优化效果的分析与比较
使用DFA进行数据流分析的优化效果主要体现在以下几点:
- **精确度提高**:通过DFA状态的精确表示,可以进行更精确的分析,避免因过度悲观导致的优化不足。
- **性能提升**:通过最小化状态数量,分析过程中内存占用减少,分析速度提升。
- **维护简化**:DFA状态的结构化特性使得算法的维护和理解更为简单。
数据流优化是编译器优化中的重要组成部分,通过DFA的引入和最小化技术,数据流分析的效率和效果都有了显著的提升,为编译器优化提供了新的思路和方法。
# 5. 代码优化策略三:基于DFA的控制流优化
在软件开发中,代码的执行流可以被抽象为控制流图(CFG),它有助于理解程序的逻辑结构,并且是进行程序分析和优化的关键。控制流优化是提高程序执行效率的重要手段之一。本章将探讨DFA在控制流优化中的应用,包括状态压缩、控制流简化、循环优化、分支预测等,并通过案例研究展示这些策略的实施与效果。
## 5.1 控制流图与代码优化
### 5.1.1 控制流图的基本概念
控制流图(CFG)是程序控制流的图形化表示,它描绘了程序中可能的执行路径。在CFG中,节点表示程序中的语句或基本块(一系列无跳转的指令序列),而边代表控制流的转移关系。理解CFG对于执行各种代码优化至关重要。
CFG能够清晰地展示程序中的循环结构、条件分支和函数调用等,这有助于开发者识别程序中的热点路径(频繁执行的路径)和潜在的性能瓶颈。通过分析CFG,我们可以发现代码中不合理的结构,进而进行重构以提高性能。
### 5.1.2 控制流优化的目标和方法
控制流优化的目标是降低程序的执行开销,提高执行效率,同时保持程序的正确性和可读性。优化方法主要包括:
- 循环展开(Loop Unrolling):减少循环控制开销,提升指令级并行。
- 循环融合(Loop Fusion):合并相邻的循环,减少循环开销和提高缓存命中率。
- 强度减弱(Strength Reduction):用低代价操作替换高代价操作,例如用位移操作替换乘法操作。
- 预计算(Pre-computation):将重复计算的结果预先存储起来,避免重复计算。
控制流优化中通常会涉及DFA的使用,尤其是在状态压缩和循环优化方面。状态压缩涉及将多个状态合并为一个,以减少程序状态的总数,而循环优化则利用DFA对循环结构的识别,简化控制流结构。
## 5.2 DFA在控制流优化中的应用
### 5.2.1 状态压缩与控制流简化
状态压缩是DFA最小化的一个直接应用,在控制流优化中,它有助于减少CFG中的状态数量。在CFG中,状态可以看作是程序中的执行点。通过识别并合并那些在程序的生命周期内执行逻辑相同的节点,我们可以降低程序的复杂性,减少需要处理的状态数量。
例如,如果在CFG中有多个节点代表了相同的条件判断逻辑,并且这些条件总是导致相同的路径被选择,那么这些节点就可以合并为一个节点。这样做不仅减少了节点的数量,也简化了控制流,降低了程序的状态空间复杂度。
### 5.2.2 循环优化和分支预测
循环优化在控制流优化中占据核心地位。DFA可以帮助开发者识别循环结构中的重复模式,以及循环迭代中的不变条件,从而实现循环展开等优化。例如,对于一个简单的`for`循环,如果循环次数是已知的,那么可以将循环展开成一系列顺序执行的语句,以减少循环控制的开销。
分支预测是一种利用DFA分析循环行为的技术,它通过分析循环中的条件分支历史来预测循环中的分支行为。这可以用于编译时优化或运行时预测,通过预测减少分支延迟,提高程序的并行度和吞吐量。
## 5.3 DFA控制流优化的案例研究
### 5.3.1 案例选择与实施
在本案例研究中,我们将选择一个具有复杂控制流的程序段进行优化。这个程序段包含多个嵌套循环和条件分支,是典型的性能热点区域。我们的目标是通过应用DFA最小化技术来识别并合并状态,简化控制流图,减少程序的执行时间。
优化的实施步骤如下:
1. 构建程序的CFG,标记出所有的节点和边。
2. 应用DFA最小化算法识别和合并等效节点。
3. 重构CFG,移除不必要的循环和分支。
4. 将优化后的CFG重新映射到源代码,生成优化后的程序代码。
### 5.3.2 案例结果分析和讨论
通过实施DFA最小化的控制流优化,我们观察到了以下结果和趋势:
- 执行时间显著下降,特别是对于那些包含大量循环和条件分支的程序。
- 代码体积有所减少,因为合并了重复的代码块。
- 程序的可读性和可维护性得到了提升,因为冗余的代码被移除,结构更加清晰。
此外,我们也注意到,控制流优化不是万能的。在某些情况下,例如当优化导致分支预测失败率增加时,程序的性能可能会受到影响。因此,进行控制流优化时,必须综合考虑程序的上下文,权衡利弊。
最终,通过本案例研究,我们验证了DFA在控制流优化中的有效性和重要性,并且为未来的研究和实践提供了宝贵的经验。
在本章节中,我们详细探讨了基于DFA的控制流优化策略,从控制流图的基本概念出发,深入到状态压缩、循环优化等具体技术。通过案例研究,我们不仅展示了这些策略的实施过程,还对其效果进行了客观的分析和讨论。通过这样的研究,我们可以更好地理解如何利用DFA来优化程序的控制流,提高程序的执行效率。
# 6. 代码优化策略四:DFA最小化与其他技术的融合
在现代编译器设计中,DFA最小化不仅仅是一个独立的优化手段,它与其他优化技术的融合更是成为提高代码执行效率的关键。在本章节中,我们将探讨DFA如何与其他技术相结合,以及这些融合在跨技术领域的优化策略中所面临的挑战和机遇。
## 6.1 DFA与其他优化技术的结合
DFA最小化技术在与其他优化技术结合时,可以产生协同效应,进一步提高程序的性能。
### 6.1.1 与指令级并行技术的结合
在现代处理器设计中,指令级并行技术(Instruction-Level Parallelism, ILP)是提高执行速度的重要手段。将DFA最小化与ILP技术结合,可以在保持状态清晰和最小化的基础上,进一步提高程序的并行度。
```mermaid
graph LR
A[DFA 最小化] -->|状态减少| B[并行指令调度]
B --> C[程序执行效率提升]
```
在上述流程图中,DFA最小化通过减少不必要的状态,简化了控制流图,这为并行指令调度创造了条件。编译器可以在更简化的控制流基础上进行指令调度,从而在保证正确性的前提下,提高指令的并行执行。
### 6.1.2 与内存管理优化的结合
内存管理优化对于现代应用程序的性能至关重要。通过将DFA最小化技术应用于内存分配和回收过程中,可以减少内存碎片,提高内存使用效率。
```mermaid
graph LR
A[DFA 最小化] -->|状态空间压缩| B[减少内存碎片]
B --> C[提高内存管理效率]
```
在该流程中,通过压缩状态空间,DFA最小化有助于减少内存碎片的产生。这是因为DFA状态的减少意味着需要更少的内存块来存储相关信息,从而降低了内存碎片化程度。
## 6.2 跨技术领域的优化策略
在更广的视角下,DFA最小化技术可以与编译器设计的其他方面相结合,形成一个多层次的优化框架。
### 6.2.1 多层次优化框架的构建
一个多层次优化框架包括前端优化、中端优化以及后端优化,DFA最小化可以在这三个层次中发挥重要作用。
```mermaid
graph TD
A[多层次优化框架] -->|前端| B[词法分析]
A -->|中端| C[数据流分析]
A -->|后端| D[指令调度]
B --> E[DFA最小化]
C --> E
D --> E
```
在这个框架中,DFA最小化不仅在前端的词法分析中有应用,在中端的数据流分析和后端的指令调度中也有重要作用。通过在不同层次应用DFA最小化,编译器可以全面地提升程序性能。
### 6.2.2 跨技术优化的挑战和机遇
尽管DFA最小化与其他技术的结合带来了诸多优势,但也面临挑战。如正确处理不同层次优化间的依赖关系,以及优化策略之间的冲突等。然而,这也带来了机遇,例如在保证程序性能的同时,进一步降低资源消耗。
## 6.3 未来展望:DFA最小化的潜力与发展方向
DFA最小化技术的未来发展方向,无论是在理论研究还是实际应用中,都具有广阔前景。
### 6.3.1 理论上的进一步研究方向
未来的研究可以针对DFA最小化的算法进行优化,例如通过机器学习技术来预测最优状态合并策略。此外,研究DFA最小化与其他编译器优化技术之间的相互作用,也将是理论研究的重要方向。
### 6.3.2 实践中的技术发展趋势
在实际应用中,DFA最小化的发展趋势可能会更加注重与硬件架构的协同优化,以及在不同编程模型下的适用性研究。此外,自动化工具的发展也将是推动DFA最小化技术广泛应用于实践的关键因素之一。
在以上章节中,我们详细探讨了DFA最小化与其他技术的融合,并展望了其在理论研究与实际应用中的潜力与发展。DFA最小化作为一种有效的编译器优化手段,其与其他技术的结合将有助于构建更为高效、智能的编译器优化框架。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到编译原理实验 DFA 最小化 C++ 代码专栏。本专栏深入探讨 DFA 最小化技术,揭示其在编译原理中代码优化的强大作用。通过一系列深入的文章,您将掌握 DFA 最小化的原理、算法和 C++ 实现。专栏还提供了实验指南、案例研究、误区探讨和教学演示,帮助您构建高效且可读的 DFA 最小化代码。通过学习本专栏,您将提升算法效率,优化代码性能,并深入理解编译原理中代码优化的秘密武器。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32G431开发板初体验:新手必看的10个实用入门技巧
参考资源链接:[STM32G431开发板详解:接口与芯片原理图指南](https://wenku.csdn.net/doc/6462d47e543f844488995d9c?spm=1055.2635.3001.10343)
# 1. STM32G431开发板概述
## 1.1 STM32G431开发板简介
STM
【HC6800-MS内存管理】:原理图解读与内存优化实践

参考资源链接:[HC6800-MS开发板详细电路图与组件解析](https://wenku.csdn.net/doc/6461c98e543f84448895221c?spm=1055.2635.3001.10343)
# 1. HC6800-MS内存管理基础
## 1.1 内存管理的重要性
内存作为计算机系统中最基本的资源之一,其有效管理直
【立即行动】西门子PLC程序块加解锁:安全加锁的紧急措施

参考资源链接:[西门子PLC S7-300/400程序块加锁解锁方法](https://wenku.csdn.net/doc/6412b56bbe7fbd1778d43144?spm=1055.2635.3001.10343)
# 1. 西门子PLC程序块加解锁概述
在自动化控制系统领域,西门子PLC(可编程逻辑控制器)是一个重要的组成
.NET Framework 3.5 SP1问题全解析:专家教你如何一网打尽安装难题
参考资源链接:[离线安装 .NET Framework 3.5 SP1 完整包及语言包教程](https://wenku.csdn.net/doc/4z3yuygoyi?spm=1055.2635.3001.10343)
# 1. .NET Framework 3.5 SP1概述
## .NET Framework 3.5 SP1简介
.NET Framework 3.5 SP1
ARINC664 Part 7实践秘籍:理论到实施的无缝转换(操作手册)
参考资源链接:[ARINC664第7部分:中文版航空电子全双工交换式以太网规范](https://wenku.csdn.net/doc/6412b79ebe7fbd1778d4af0c?spm=1055.2635.3001.10343)
# 1. ARINC664 Part 7标准概述
## 1.1 标准的起源和应用背景
ARINC664 Part 7是一种航空电子数据网络通信标准
Cadence Allegro高级优化:板边Outline设计的8个高级技巧
参考资源链接:[cadence allegro里如何绘制板边outline](https://wenku.csdn.net/doc/6412b621be7fbd1778d459e4?spm=1055.2635.3001.10343)
# 1. Cadence Allegro概述与板边设计基础
## 简介
Cadence Allegro是电子设计自动化(EDA)领域内广受欢迎的PCB设计工具
【Honeywell OH4502二次开发全能教程】:接口编程与应用拓展

参考资源链接:[honeywell OH4502二维2.4G说明书(最终版)中文.pdf](https://wenku.csdn.net/doc/6412b45fbe7fbd1778d3f60e?spm=1055.2635.3001.10343)
# 1. Honeywell OH4502设备概述
## 设备简介
Honeywell OH4
提高数据传输可靠性:海明码的扩展与优化策略

参考资源链接:[海明码与码距:概念、例子及纠错能力分析](https://wenku.csdn.net/doc/5qhk39kpxi?spm=1055.26
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )