DFA最小化实践:构建高效且可读的C++代码,一步到位
发布时间: 2024-12-15 10:13:45 阅读量: 2 订阅数: 4 

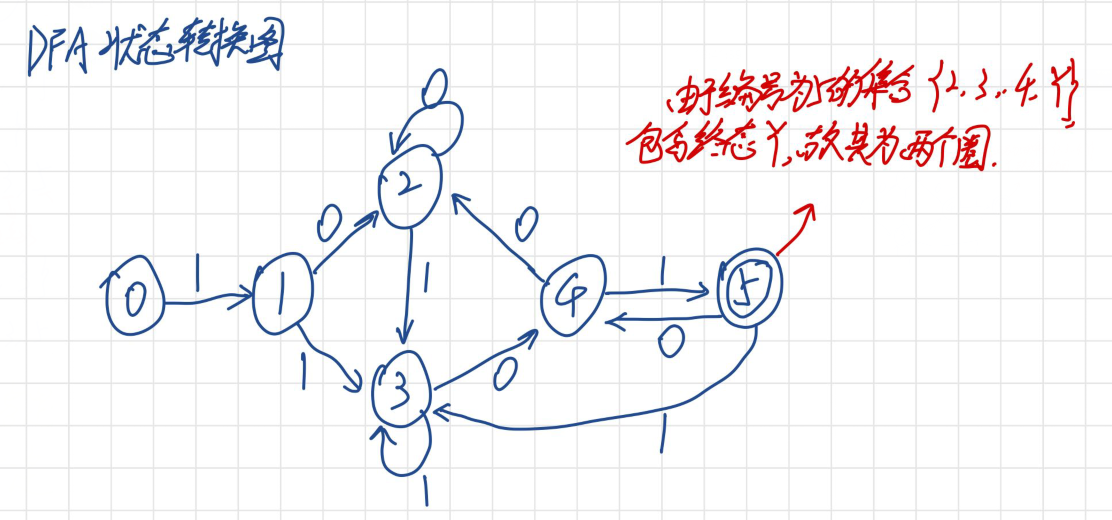
编译原理-DFA最小化-C++
参考资源链接:[C++实现DFA最小化的编译原理实验代码](https://wenku.csdn.net/doc/2jxuncpikn?spm=1055.2635.3001.10343)
# 1. DFA最小化的理论基础
## 1.1 确定有限自动机(DFA)简介
DFA是计算理论中的一个核心概念,它是一种识别模式和字符串的数学模型。在DFA模型中,每个状态都对应一个唯一的转移,输入字符串之后的状态由当前状态和输入符号共同决定。DFA在编译原理、自然语言处理和字符串搜索等领域有着广泛的应用。
## 1.2 DFA最小化的目的
DFA最小化的主要目的是减少状态数量,降低自动机的复杂度。它通过合并那些在所有可能的输入下表现相同的状态来实现,从而得到一个等价的、更简洁的自动机。最小化的DFA不仅占用更少的存储空间,而且提高了运行效率。
## 1.3 等价类与DFA最小化
在DFA最小化过程中,等价类的划分是核心步骤之一。等价类指的是那些从任何一个状态出发,对于任何输入字符串,都会得到相同结果的状态集合。将这些状态合并,可以得到一个更简洁的等价DFA。
DFA最小化过程涉及到的理论知识和方法,为实现高效的DFA处理提供了坚实的基础。在后续章节中,我们将探讨如何在C++中实现这一理论,并通过实例演示其应用。
# 2. C++中实现DFA最小化的方法
## 2.1 数据结构的选择与定义
### 2.1.1 状态和转移函数的设计
在DFA(确定有限自动机)最小化的过程中,状态和转移函数的设计是基础。DFA由状态集合、字母表、转移函数、初始状态和接受状态组成。在C++中,我们通常使用结构体或类来定义状态,并使用映射来表示转移函数。
**代码示例(状态和转移函数):**
```cpp
#include <iostream>
#include <map>
#include <string>
#include <vector>
// 定义状态
struct State {
int id;
bool is_accepting; // 是否为接受状态
};
// 定义DFA
class DFA {
private:
std::vector<State> states; // 所有状态集合
std::map<State, std::map<char, State>> transition_function; // 转移函数
State start_state; // 初始状态
State accept_state; // 接受状态
public:
// 状态和转移函数的相关操作,例如添加状态、设置转移等
// ...
};
```
### 2.1.2 等价类的划分策略
等价类是DFA最小化中的关键概念。两个状态是等价的,如果它们在相同输入下都会转移到相同的接受状态集合。等价类的划分是通过可区分性关系(区分性)来实现的。
**表格:区分性关系表**
| 状态 \ 输入 | 'a' | 'b' | ... |
|-------------|-----|-----|-----|
| s1 | s2 | s3 | ... |
| s2 | s1 | s4 | ... |
| ... | ... | ... | ... |
等价类的划分策略通常从可区分性关系表出发,使用等价类合并法逐步简化状态集合。
## 2.2 算法逻辑与实现步骤
### 2.2.1 构建等价类的算法细节
构建等价类是DFA最小化的第一个步骤。这个过程涉及到对所有状态进行可区分性检查,并据此划分类别。算法从两个状态是否可区分开始,通过递归或迭代的方式实现。
**代码示例(构建等价类):**
```cpp
void build_equivalence_classes(DFA& dfa) {
// 初始化等价类映射,每个状态最初自成一个等价类
std::map<State, std::set<State>> equivalence_classes;
for (const auto& state : dfa.states) {
equivalence_classes[state] = {state};
}
// 迭代地划分等价类,直到没有新的等价类产生
bool changed;
do {
changed = false;
for (const auto& pair : equivalence_classes) {
for (const auto& state : pair.second) {
for (char symbol : dfa.alphabet()) {
State next_state = dfa.transition(state, symbol);
for (const auto& other_pair : equivalence_classes) {
if (other_pair.second.find(next_state) != other_pair.second.end()) {
changed = true;
equivalence_classes[state].insert(other_pair.first.begin(), other_pair.first.end());
equivalence_classes[other_pair.first].insert(state);
}
}
}
}
}
} while (changed);
// 构建最小DFA所需的等价类集合
// ...
}
```
### 2.2.2 状态合并的策略与优化
在得到等价类之后,下一步是合并每个等价类中的状态,得到一个新的更小的DFA。这一过程需要对原DFA中的每个状态进行检查,以确定它们是否属于同一个等价类,并相应地更新转移函数。
**代码示例(状态合并):**
```cpp
void merge_states(DFA& dfa, const std::map<State, std::set<State>>& equivalence_classes) {
// 将等价类中所有状态合并为一个新的状态
for (const auto& pair : equivalence_classes) {
State new_state = pair.first;
new_state.id = generate_new_state_id(); // 分配新的状态ID
dfa.states.push_back(new_state);
// 更新转移函数、初始状态、接受状态
// ...
}
}
```
## 2.3 性能优化与测试
### 2.3.1 代码的性能分析
在实现DFA最小化的过程中,代码性能分析是不可或缺的。使用性能分析工具(如gprof、Valgrind等)可以帮助我们找到性能瓶颈,从而针对性地优化代码。
**代码示例(性能分析):**
```cpp
// 示例代码,假设dfaminimize()是进行DFA最小化的主要函数
int main() {
DFA dfa;
// 初始化DFA
// ...
// 使用性能分析工具,例如:gprof -b ./dfaminimize
dfaminimize(dfa);
// ...
}
```
### 2.3.2 单元测试与边界条件覆盖
单元测试是确保代码质量的重要步骤,对DFA最小化的每个函数都应进行单元测试。同时,边界条件的测试能够确保代码在极端情况下的正确性和健壮性。
**示例表格:单元测试用例**
| 测试用例 | 输入数据 | 期望输出 | 实际输出 | 测试结果 |
|-----------|----------|----------|----------|----------|
| 等价类划分 | DFA实例 | 等价类列表 | 等价类列表 | 通过/失败 |
| 状态合并 | 等价类列表 | 最小DFA实例 | 最小DFA实例 | 通过/失败 |
| ... | ... | ... | ... | ... |
在编写单元测试时,要特别注意覆盖所有的边界条件,例如空DFA、单个状态的DFA、以及特殊字符集的DFA等。
通过上述方法,我们可以确保C++中实现的DFA最小化算法不仅逻辑正确,而且在性能上也是优化的。
# 3. 实践案例:构建一个最小化DFA引擎
## 3.1 环境准备与框架搭建
### 3.1.1 开发环境配置
在开始构建最小化DFA(Deterministic Finite Automaton)引擎之前,首先需要准备一个适合的开发环境。对于C++项目,我们通常需要一个支持C++11或更高版本的编译器,如GCC、Clang或MSVC。在配置开发环境时,推荐使用诸如CMake这样的跨平台构建工具,它可以帮助我们管理项目依赖、配置编译选项,并且可以轻松地适应不同的操作系统和IDE(集成开发环境)。
接下来,我们可以创建一个基础项目结构,包含源文件(`

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到编译原理实验 DFA 最小化 C++ 代码专栏。本专栏深入探讨 DFA 最小化技术,揭示其在编译原理中代码优化的强大作用。通过一系列深入的文章,您将掌握 DFA 最小化的原理、算法和 C++ 实现。专栏还提供了实验指南、案例研究、误区探讨和教学演示,帮助您构建高效且可读的 DFA 最小化代码。通过学习本专栏,您将提升算法效率,优化代码性能,并深入理解编译原理中代码优化的秘密武器。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入理解海明码:实践中的错误更正机制完全手册

参考资源链接:[海明码与码距:概念、例子及纠错能力分析](https://wenku.csdn.net/doc/5qhk39kpxi?spm=1055.2635.3001.10343)
【工业自动化中的应用】:冲压与送料机构在自动化生产线中的关键角色

参考资源链接:[板料冲制机冲压与送料机构设计解析](https://wenku.csdn.net/doc/5hfp00n04s?spm=1055.2635.3001.10343)
# 1. 工业自动化基础与关键组件
工业自动化是一个涉及多学科的复杂领域,它通过自动
高效PCB板边设计:Cadence Allegro Outline绘制的5大高级技巧

参考资源链接:[cadence allegro里如何绘制板边outline](https://wenku.csdn.net/doc/6412b621be7fbd1778d459e4?spm=1055.2635.3001.10343)
# 1. Cadence Allegro概述及其在PCB设计中的地位
## 1.1 电子设计自动化与
ARINC664 Part 7技术深度剖析:揭秘航空通信协议的高效应用(全解析)

参考资源链接:[ARINC664第7部分:中文版航空电子全双工交换式以太网规范](https://wenku.csdn.net/doc/6412b79ebe7fbd1778d4af0c?spm=1055.2635.3001.10343)
# 1. ARINC664 Part 7技术概述
ARINC664 Part 7技术作为航空电子通信的国际标
【FIBOCOM FM150-AE 系列硬件优化技巧】:设备性能飞跃的秘诀
参考资源链接:[FIBOCOM FM150-AE系列硬件指南:5G通信模组详解](https://wenku.csdn.net/doc/5a6i74w47q?spm=1055.2635.3001.10343)
# 1. FIBOCOM FM150-AE系列硬件概述
FIBOCOM作为业界领先的通信模块提供商,其FM150-AE系列凭借优秀的性能与稳定性,在物联网和无线通信领域备受瞩目。本章将带领读者走进FM150-AE系列的世界,深入探讨其硬件构成、设计理念以及应用场景。
## 1.1 硬件设计与应用范围
FIBOCOM FM150-AE系列的设计初衷是为了满足工业级无线通信的需求。该系
【.NET Framework 3.5 SP1终极指南】:全面提升你的安装、配置与故障排除技能
参考资源链接:[离线安装 .NET Framework 3.5 SP1 完整包及语言包教程](https://wenku.csdn.net/doc/4z3yuygoyi?spm=1055.2635.3001.10343)
# 1. .NET Framework 3.5 SP1概述
.NET Framework 3.5 SP1是微软推出的一个重要版本,它在
西门子PLC编程比较:STL与梯形图的优势及应用分析

参考资源链接:[西门子STL编程手册:语句表指令详解](https://wenku.csdn.net/doc/1dgcsrqbai?spm=1055.2635.3001.10343)
# 1. 西门子PLC编程概述
在自动化工业领域,可编程逻辑控制器(PLC)是核心控制设备之一,而西门子作为该领域的佼佼者,其PLC产品广泛应用于各种复杂的控制系统中。在本章中,我们将简要介绍PLC的概念,以及西门子PLC编程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )