【马尔可夫链蒙特卡罗方法】:大数据分析中的核心算法与实战
发布时间: 2024-12-19 01:37:44 阅读量: 2 订阅数: 4 

MATLAB算法-马尔可夫链蒙特卡洛算法详解,附代码.pdf
# 摘要
马尔可夫链蒙特卡罗(MCMC)方法是一种强大的随机模拟技术,广泛应用于统计学、机器学习等领域中处理复杂概率模型和大数据分析。本文首先介绍了MCMC方法的基本概念和数学模型,包括马尔可夫链的性质和蒙特卡罗模拟方法。随后,本文探讨了MCMC算法的不同实现方式及其优化策略,如吉布斯采样、Metropolis-Hastings算法和汉密尔顿蒙特卡罗方法,并详细讨论了算法调优技术以及诊断和收敛性检验方法。第四章专注于MCMC在大数据分析中的应用,包括在统计机器学习中的推断和分类分析,以及云计算环境下的算法部署和性能扩展。最后,第五章分析了当前MCMC方法面临的挑战,并对未来的发展趋势和跨学科研究前景进行展望。
# 关键字
马尔可夫链;蒙特卡罗模拟;MCMC算法;吉布斯采样;Metropolis-Hastings算法;大数据分析
参考资源链接:[一阶平稳马尔可夫信源:状态概率与极限熵解析](https://wenku.csdn.net/doc/646f01bd543f844488dc999e?spm=1055.2635.3001.10343)
# 1. 马尔可夫链蒙特卡罗方法简介
马尔可夫链蒙特卡罗(Markov Chain Monte Carlo,简称MCMC)方法是一种用于随机模拟的技术,其在统计物理、机器学习和计算概率等领域有广泛的应用。MCMC方法的核心思想是通过构建一个马尔可夫链,使其平稳分布与目标分布相一致,从而达到对复杂或高维概率分布进行采样的目的。
## 1.1 马尔可夫链基础
马尔可夫链是随机过程的一种,其特点在于系统的未来状态仅依赖于当前状态,而与过去的历史无关,这一性质称为“无后效性”。在MCMC中,利用马尔可夫链的这一特性,通过迭代过程不断接近目标概率分布的采样。
## 1.2 蒙特卡罗模拟方法
蒙特卡罗方法是一种基于随机抽样的计算方法,通过大量随机数的统计分析来求解数学和物理问题。MCMC将蒙特卡罗方法与马尔可夫链结合起来,使得算法能够生成高度相关性的样本序列,提高采样效率,尤其适用于处理多维积分和复杂分布的采样问题。
MCMC方法的实现涉及随机变量的生成、状态转移概率的定义,以及统计推断等步骤。这些步骤的合理设计对于确保算法收敛到正确的分布至关重要。下一章将深入探讨MCMC的理论基础和数学模型,为理解其深层次工作原理和应用奠定基础。
# 2. 理论基础与数学模型
## 2.1 马尔可夫链的概念和性质
### 2.1.1 随机过程和马尔可夫性
在随机过程中,系统的下一个状态仅依赖于当前状态,而与之前的状态无关,这种特性称为马尔可夫性。数学上,如果一个随机过程满足以下条件:
\[ P(X_{n+1} = x_{n+1} | X_n = x_n, X_{n-1} = x_{n-1}, \dots, X_0 = x_0) = P(X_{n+1} = x_{n+1} | X_n = x_n) \]
则称该过程具有马尔可夫性,其中 \(X_n\) 表示第n个状态。这种性质极大地简化了高维随机过程的计算复杂性,因为其动态仅取决于一步转移概率。
### 2.1.2 马尔可夫链的转移矩阵和稳态分布
一个马尔可夫链可以用转移矩阵 \(P\) 来描述,矩阵中的元素 \(p_{ij}\) 表示从状态 \(i\) 转移到状态 \(j\) 的概率。转移矩阵是随机矩阵的一种,满足所有元素非负且每行元素之和为1的条件。
稳态分布(或称平稳分布)是马尔可夫链的长期行为。如果存在一个分布 \(\pi\),使得 \(\pi P = \pi\),那么 \(\pi\) 就是马尔可夫链的一个稳态分布。稳态分布意味着从任何状态出发,马尔可夫链在足够长时间后达到的分布不会改变。
```mathematica
(* 示例:定义一个简单的马尔可夫链转移矩阵 *)
P = {{0.9, 0.1}, {0.2, 0.8}}; (* 这里有两个状态 *)
steadyState = Eigensystem[P, -1][[1, 1]] (* 计算稳态分布 *)
Print["稳态分布为: ", steadyState];
```
在上述的 Mathematica 代码中,我们首先定义了一个简单的 2x2 转移矩阵 `P`,然后计算其稳态分布。结果输出告诉我们系统在长期运行后,每个状态的稳定概率。
## 2.2 蒙特卡罗模拟方法
### 2.2.1 蒙特卡罗方法的原理
蒙特卡罗方法是一种基于随机抽样的数值计算方法,主要用于解决那些难以直接计算的复杂积分和优化问题。基本思想是利用随机数生成过程来模拟物理和数学系统的随机行为,并通过统计分析得到系统行为的近似解。
### 2.2.2 蒙特卡罗方法在统计推断中的应用
在统计推断中,蒙特卡罗方法可以用于估计参数的后验分布、计算边缘概率等。通过大量的随机抽样,我们可以得到分布的数值近似解,从而进行概率计算。尤其是在贝叶斯统计中,蒙特卡罗方法因其灵活性和有效性而被广泛应用。
```python
import numpy as np
# 一个简单的蒙特卡罗积分示例
def monte_carlo_integration(f, a, b, n):
x = np.random.uniform(a, b, n)
y = f(x)
return (b-a) * np.mean(y)
# 定义函数 f(x)
def f(x):
return np.sin(x)
# 计算 ∫(0 to π) sin(x) dx 的近似值
approximation = monte_carlo_integration(f, 0, np.pi, 10000)
print("积分的蒙特卡罗近似值为:", approximation)
```
在这段 Python 代码中,我们定义了一个函数 `monte_carlo_integration` 来近似计算定积分的值。通过在区间 [a, b] 内进行 n 次随机抽样,并计算这些样本点的函数值,我们可以得到积分的一个统计近似值。
## 2.3 马尔可夫链蒙特卡罗(MCMC)算法
### 2.3.1 MCMC算法的工作原理
MCMC算法是一种利用马尔可夫链来生成随机样本序列的蒙特卡罗方法。由于马尔可夫链的特性,我们可以构造一个转移核 \(K(x, y)\),使得通过转移核迭代产生的样本序列具有目标分布的性质。
### 2.3.2 MCMC算法的关键技术点
MCMC算法的核心在于构造一个适当的转移核 \(K\),使得在达到稳态分布后,样本序列中的每一个样本都近似独立同分布地来自目标分布 \(π\)。两个主要的技术点是:
- 如何从当前状态 \(x\) 选择下一个状态 \(y\)。
- 如何决定何时停止抽样,以及如何保证抽样过程的收敛性。
```r
# R语言中的吉布斯采样示例
gibbs_sampling <- function(n, thin) {
mat <- matrix(nrow = n, ncol = 2)
x <- y <- 0
for (i in 1:n) {
for (j in 1:thin) {
x <- rnorm(1, y, 1)
y <- rnorm(1, x, 1)
}
mat[i, ] <- c(x, y)
}
return(mat)
}
# 运行1000次迭代,每次迭代抽样1次
samples <- gibbs_sampling(1000, 1)
```
此段 R 代码展示了一个基本的吉布斯采样的实现。我们通过迭代更新 `x` 和 `y` 的值,并在每一步都基于前一步的值来进行抽样。最终生成的 `samples` 矩阵就是我们想要的样本序列。
在本章节中,我们深入探讨了马尔可夫链和蒙特卡罗方法的理论基础,以及它们在MCMC算法中的应用。理解这些原理对于设计高效、准确的MCMC算法至关重要。在下一章节中,我们将深入分析MCMC算法的实现与优化策略。
# 3. MCMC算法的实现与优化
### 3.1 MCMC算法的常见变体
#### 3.1.1 吉布斯采样(Gibbs Sampling)
吉布斯采样是一种基于条件概率进行采样的MCMC算法变体。其核心思想是针对多变量概率分布的问题,通过迭代地从每个变量的条件分布中采样,来得到整个变量的联合分布的样本。
以一个简单的二元分布为例,其联合概率密度函数为 \( p(x, y) \)。吉布斯采样过程如下:
1. 初始化 \( x_0, y_0 \)。
2. 在第 \( t \) 步,首先根据 \( p(y|x=x_{t-1}) \) 条件分布采样 \( y_t \)。
3. 接着,根据 \( p(x|y=y_t) \) 条件分布采样 \( x_t \)。
4. 重复步骤 2-3。
整个迭代过程中,\( x_t, y_t \) 的联合分布逐渐趋近于目标分布 \( p(x, y) \)。
```python
import numpy as np
def gibbs_sampling(posterior, x0, y0, iterations):
samples = []
x, y = x0, y0
for _ in range(iterations):
x = sample_from_condition(posterior['p(x|y)'], y)
y = sample_from_condition(posterior['p(y|x)'], x)
samples.append((x, y))
return np.array(samples)
# 示例条件分布采样函数
def sample_from_condition(condition, given):
# 这里的条件分布和给定值仅为示例,实际应用中应使用正确的采样方法
return np.random.normal(condition['mean'] + condition['cov'] * given)
posterior = {
'p(x|y)': {'mean': 0, 'cov': 1},
'p(y|x)': {'mean': 0, 'cov': 1}
}
x0, y0 = 0, 0
iterations = 10000
samples = gibbs_sampling(posterior, x0, y0, iterations)
```
在代码中,我们定义了吉布斯采样的函数,并用一个简化的二维正态分布作为示例条件分布。每次迭代,我们根据另一变量的当前值来采样当前变量的值。
#### 3.1.2 Metropolis-Hastings算法
Metropolis-Hastings 算法是一种更为通用的MCMC方法,它允许在任意目标分布中采样。与Gibbs采样相比,Metropolis-Hastings 不要求对所有的条件分布进行采样,只需要能够计算出目标分布的密度函数值即可。
Metropolis-Hastings 算法的基本步骤如下:
1. 初始化参数 \( x_0 \)。
2. 在第 \( t \) 步,从提议分布 \( q(x_t|x_{t-1}) \) 中提出

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CPCI规范中文版避坑指南:解决常见问题,提升实施成功率

# 摘要
CPCI(CompactPCI)规范作为一种国际标准,已被广泛应用于工业和通信领域的系统集成中。本文首先概述了CPCI规范中文版的关键概念、定义及重要性,并比较了其与传统PCI技术的差异。接着,文章深入分析了中文版实施过程中的常见误区、挑战及成功与失败的案例。此外,本文还探讨了如何提升CPCI规范中文版实施成功率的策略,包括规范的深入理解和系统化管理。最后,文章对未来CPCI技术的发展趋势以及在
电池散热技术革新:高效解决方案的最新进展

# 摘要
电池散热技术对于保障电池性能和延长使用寿命至关重要,同时也面临诸多挑战。本文首先探讨了电池散热的理论基础,包括电池热产生的机理以及散热技术的分类和特性。接着,通过多个实践案例分析了创新散热技术的应用,如相变材料、热管技术和热界面材料,以及散热系统集成与优化的策略。最后,本文展望了未来电池散热技术的发展方向,包括可持续与环境友好型散热技术的探索、智能散热管理系统的设计以及跨学科技术融合的
【深入剖析Cadence波形功能】:提升电路设计效率与仿真精度的终极技巧

# 摘要
本文对Cadence波形功能进行了全面介绍,从基础操作到进阶开发,深入探讨了波形查看器的使用、波形信号的分析理论、仿真精度的优化实践、系统级波形分析以及用户定制化波形工具的开发。文中不仅详细解析了波形查看器的主要组件、基本操作方法和波形分析技巧,还着重讲解了仿真精度设置对波形数据精度的影
【数据库系统原理及应用教程第五版习题答案】:权威解读与实践应用指南
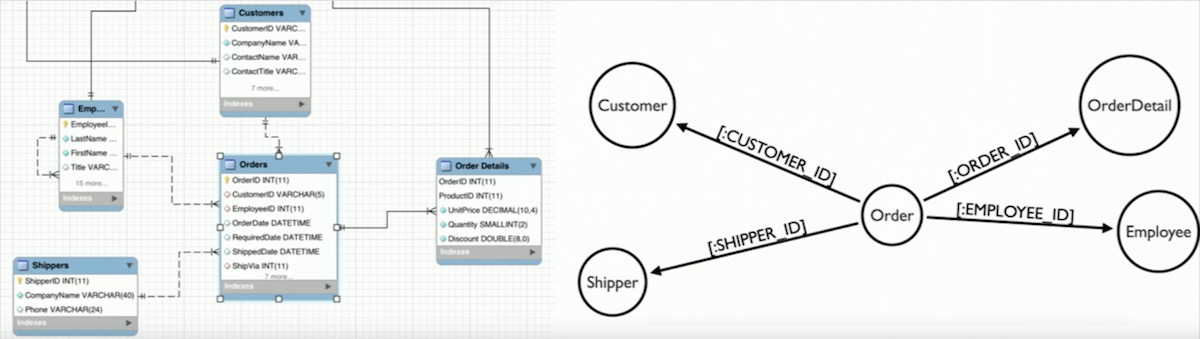
# 摘要
数据库系统是现代信息系统的核心,它在组织、存储、检索和管理数据方面发挥着至关重要的作用。本文首先概述了数据库系统的基本概念,随后深入探讨了关系数据库的理论基础,包括其数据结构、完整性约束、关系代数与演算以及SQL语言的详细解释。接着,文章着重讲述了数据库设计与规范化的过程,涵盖了需求分析、逻辑设计、规范化过程以及物理设计和性能优化。本文进一步分析了数据库管理系统的关键实现技术,例如存储引擎、事务处理、并发控制、备份与恢复技术。实践应用章
系统稳定运行秘诀:CS3000维护与监控指南

# 摘要
本文全面介绍CS3000系统的日常维护操作、性能监控与优化、故障诊断与应急响应以及安全防护与合规性。文章首先概述了CS3000系统的基本架构和功能,随后详述了系统维护的关键环节,包括健康检查、软件升级、备份与灾难恢复计划。在性能监控与优化章节中,讨论了有效监控工具的使用、性能数据的分析以及系统调优的实践案例。故障诊断与应急响应章节
HiGale数据压缩秘籍:如何节省存储成本并提高效率
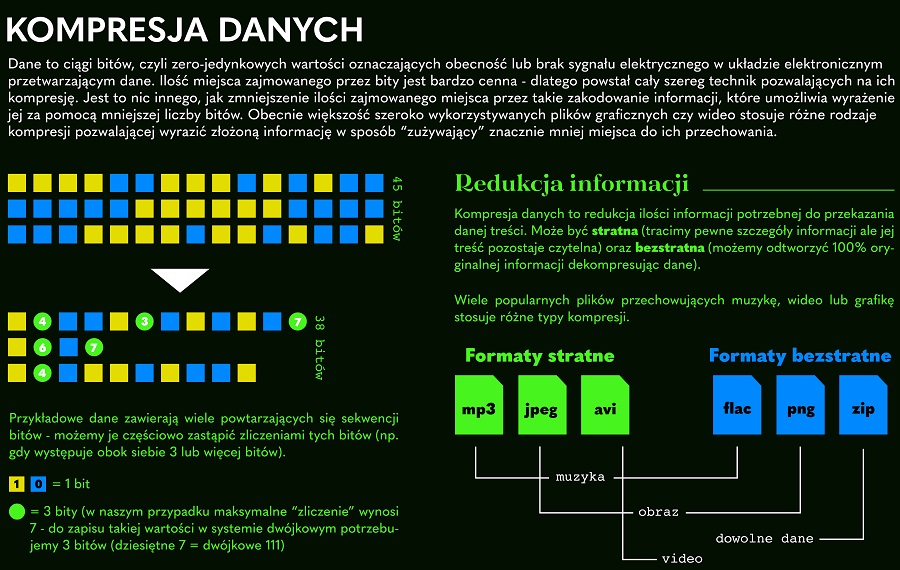
# 摘要
随着数据量的激增,数据压缩技术显得日益重要。HiGale数据压缩技术通过深入探讨数据压缩的理论基础和实践操作,提供了优化数据存储和传输的方法。本论文概述了数据冗余、压缩算法原理、压缩比和存储成本的关系,以及HiGale平台压缩工具的使用和压缩效果评估。文中还分析了数据压缩技术在
WMS功能扩展:适应变化业务需求的必备技能(业务敏捷,系统灵活)
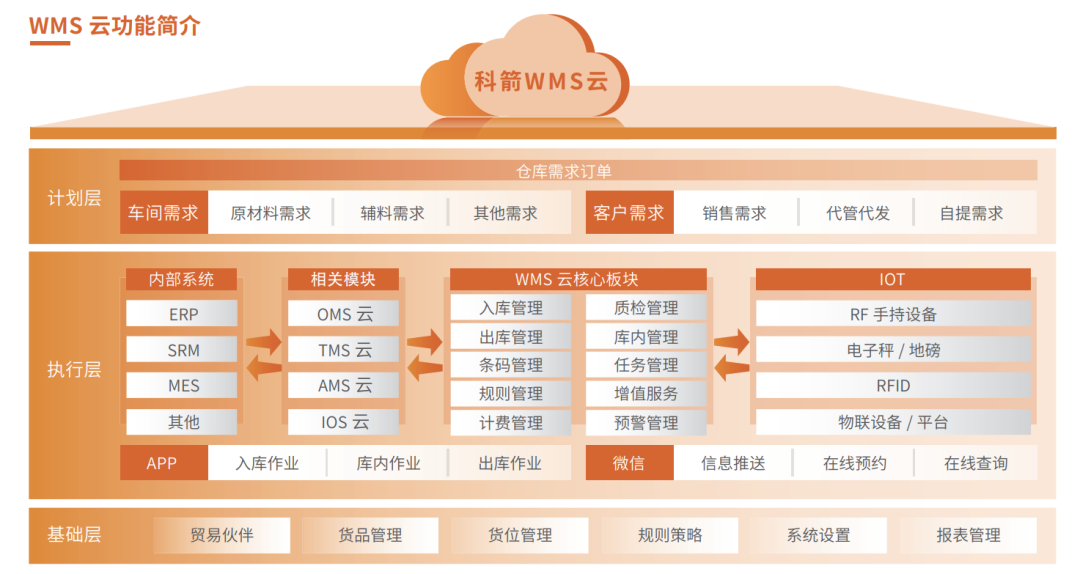
# 摘要
本文详细介绍了WMS系统的业务需求适应性及其对业务敏捷性的理论基础和实践策略。首先概述了WMS系统的基本概念及其与业务需求的匹配度。接着探讨了业务敏捷性的核心理念,并分析了提升敏捷性的方法,如灵活的工作流程设计和适应性管理。进一步,文章深入阐述了系统灵活性的关键技术实现,包括模块化设计、动态配置与扩展以及数据管理和服务化架构。在功能扩展方面,本文提供
【数据结构实例分析】:清华题中的应用案例,你也能成为专家
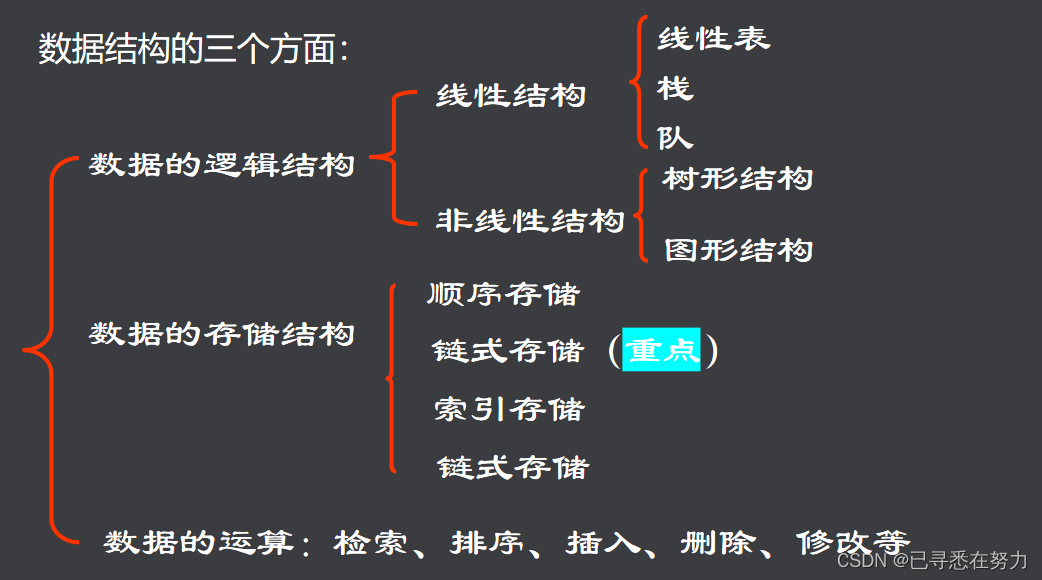
# 摘要
本文全面探讨了数据结构在解决复杂问题中的应用,特别是线性结构、树结构、图结构、散列表和字符串的综合应用。文章首先介绍了数据结构的基础知识,然后分别探讨了线性结构、树结构和图结构在处理特定问题中的理论基础和实战案例。特别地,针对线性结构,文中详细阐述了数组和链表的原理及其在清华题中的应用;树结构的分析深入到二叉树及其变种;图结构则涵盖了图的基本理论、算法和高级应用案例。在散列表和字符串综合应用章节,文章讨论了散列表设计原理、
【精密工程案例】:ASME Y14.5-2018在精密设计中的成功实施
# 摘要
ASME Y14.5-2018标准作为机械设计领域内的重要文件,为几何尺寸与公差(GD&T)提供了详细指导。本文首先概述了ASME Y14.5-2018标准,并从理论上对其进行了深入解析,包括GD&T的基本概念、术语定义及其在设计中的应用。接着,文章讨论了ASME Y14.5-2018在机械设计实际应用中的实施,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )