YOLOv5矩形识别算法在环境监测中的应用:数据驱动决策,赋能环境保护
发布时间: 2024-08-14 09:39:47 阅读量: 32 订阅数: 30 

# 1. YOLOv5矩形识别算法概述**
YOLOv5(You Only Look Once, Version 5)是一种最先进的矩形识别算法,它使用单次前向传递来预测图像中的对象。与其他目标检测算法不同,YOLOv5不会生成候选区域,而是直接输出边界框和类概率。这种独特的架构使其具有极高的速度和准确性,使其成为实时应用的理想选择。
YOLOv5的架构基于一个深度卷积神经网络(CNN),该网络将图像分成一个网格。对于网格中的每个单元格,算法预测一个边界框和一个类概率向量。边界框表示对象在图像中的位置和大小,而类概率向量表示对象属于不同类别的概率。
# 2. YOLOv5算法在环境监测中的应用
### 2.1 环境监测数据获取与预处理
**2.1.1 传感器数据采集**
环境监测数据主要通过传感器采集。常见的传感器包括:
- **空气质量传感器:**监测PM2.5、PM10、二氧化氮、臭氧等污染物浓度。
- **水质传感器:**监测pH值、溶解氧、浊度、化学需氧量等水质参数。
- **土壤传感器:**监测土壤湿度、温度、酸碱度、重金属含量等土壤指标。
传感器数据采集频率根据监测需求而定,一般为每小时或每天。
**2.1.2 数据清洗和增强**
采集的传感器数据可能存在缺失、异常或噪声等问题。需要进行数据清洗和增强,以提高模型训练和推理的准确性。
数据清洗步骤包括:
- **缺失值处理:**使用平均值、中位数或插值等方法填充缺失值。
- **异常值处理:**识别和删除明显偏离正常范围的异常值。
- **噪声处理:**使用滤波器或平滑技术去除数据中的噪声。
数据增强技术可以增加训练数据集的多样性,提高模型的泛化能力。常用的数据增强方法包括:
- **旋转:**将图像或点云随机旋转一定角度。
- **翻转:**沿水平或垂直轴翻转图像或点云。
- **裁剪:**从图像或点云中随机裁剪出不同大小和形状的子区域。
- **颜色抖动:**随机改变图像或点云的亮度、对比度和饱和度。
### 2.2 YOLOv5算法的训练和部署
**2.2.1 模型训练流程**
YOLOv5算法训练流程主要包括以下步骤:
1. **数据预处理:**将采集的传感器数据转换为模型可识别的格式,并进行数据清洗和增强。
2. **模型选择:**根据监测任务选择合适的YOLOv5模型,如YOLOv5s、YOLOv5m或YOLOv5l。
3. **超参数优化:**调整模型的超参数,如学习率、批大小和训练轮数,以获得最佳性能。
4. **模型训练:**使用训练数据集训练模型,并使用验证数据集评估模型性能。
5. **模型评估:**使用测试数据集评估模型的精度、召回率和F1值等指标。
**2.2.2 模型部署和优化**
训练好的模型需要部署到实际环境中使用。部署方式主要有:
- **云端部署:**将模型部署到云平台,通过API或Web服务提供预测服务。
- **边缘设备部署:**将模型部署到边缘设备,如树莓派或工业计算机,进行实时预测。
模型部署后,可以根据需要进行优化:
- **量化:**将模型转换为低精度格式,如INT8或FP16,以减少内存占用和推理时间。
- **剪枝:**移除模型中不重要的权重和神经元,以减小模型大小和推理时间。
- **蒸馏:**将大型模型的知识转移到小型模型中,以提高小型模型的性能。
**代码块:**
```python
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 准备训练数据
train_dataset = datasets.ImageFolder(
root="path/to/train_data",
transform=transforms.ToTensor()
)
# 准备验证数据
val_dataset = datasets.ImageFolder(
root="path/to/val_data",
transform=transforms.ToTensor()
)
# 创建YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 设置训练超参数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=5)
# 训练模型
for epoch in range(100):
# 训练一个epoch
model.train()
for batch in train_dataset:
# 正向传播
loss = model(batch["image"].cuda())
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
# 验证模型
model.eval()
with torch.no_grad():
for batch in val_dataset:
# 正向传播
loss = model(batch["image"].cuda())
# 计算指标
accuracy = ...
recall = ...
f1 = ...
# 调整学习率
scheduler.step(loss)
```
**代码逻辑分析:**
该代码段展示了YOLOv5模型的训练过程。首先,准备训练和验证数据集。然后,创建YOLOv5模型并设置训练超参数。接着,使用训练数据训练模型,并使用验证数据评估模型性能。最后,调整学习率以优化训练过程。
**参数说明:**
- `path/to/train_data`:训练数据集的路径。
- `path/to/val_data`:验证数据集的路径。
- `lr`:学习率。
- `patience`:学习率衰减的忍耐度。
- `epoch`:训练的轮数。
# 3.1 空气质量监测
#### 3.1.1 PM2.5和PM10浓度识别
PM2.5和PM10是空气中悬浮颗粒物的重要指标,它们对人体健康和环境质量有重大影响。YOLOv5算法可以应用于空气质量监测中,通过识别图像中的PM2.5和PM10颗粒,实现空气质量的实时监测和评估。
**代码块:**
```python
import cv2
import numpy as np
import pytesseract
# 加载YOLOv5模型
net = cv2.dnn.readNet("yolov5s.weights", "yolov5s.cfg")
# 设置模型输入参数
net.setInput(cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False))
# 执行前向传播
detections = net.forward()
# 遍历检测结果
for detection in detections:
# 获取检测框和置信度
x1, y1, x2, y2, conf = detection[0:5]
# 过
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏以 YOLOv5 算法为核心,全面介绍了其在物体检测领域中的应用和技术细节。专栏涵盖了 YOLOv5 算法的原理、实现、训练技巧、部署实践、性能优化以及在医疗、自动驾驶、工业检测、医疗影像、安防监控、体育分析、零售、农业和环境监测等领域的应用案例。通过深入浅出的讲解和实战项目,专栏旨在帮助读者从入门到精通 YOLOv5 算法,提升物体检测能力,解锁算法优化秘诀,并掌握矩形识别算法的原理和应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
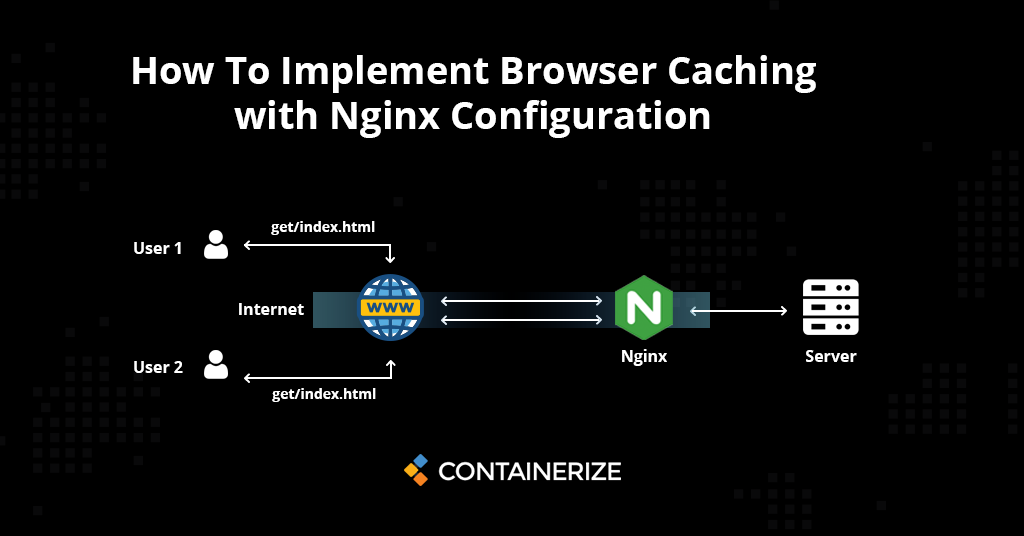
【Nginx终极优化手册】:提升性能与安全性的20个专家技巧
# 摘要
本文详细探讨了Nginx的优化方法,涵盖从理论基础到高级应用和故障诊断的全面内容。通过深入分析Nginx的工作原理、性能调优、安全加固以及高级功能应用,本文旨在提供一套完整的优化方案,以提升Nginx
【云计算入门】:从零开始,选择并部署最适合的云平台

# 摘要
云计算作为一种基于互联网的计算资源共享模式,已在多个行业得到广泛应用。本文首先对云计算的基础概念进行了详细解析,并深入探讨了云服务模型(IaaS、PaaS和SaaS)的特点和适用场景。随后,文章着重分析了选择云服务提供商时所需考虑的因素,包括成本、性能和安全性,并对部署策略进行了讨论,涉及不同云环境(公有云、私有云和混合云)下的实践操作指导。此外,本文还覆盖了云安全和资源管理的实践,包括
【Python新手必学】:20分钟内彻底解决Scripts文件夹缺失的烦恼!
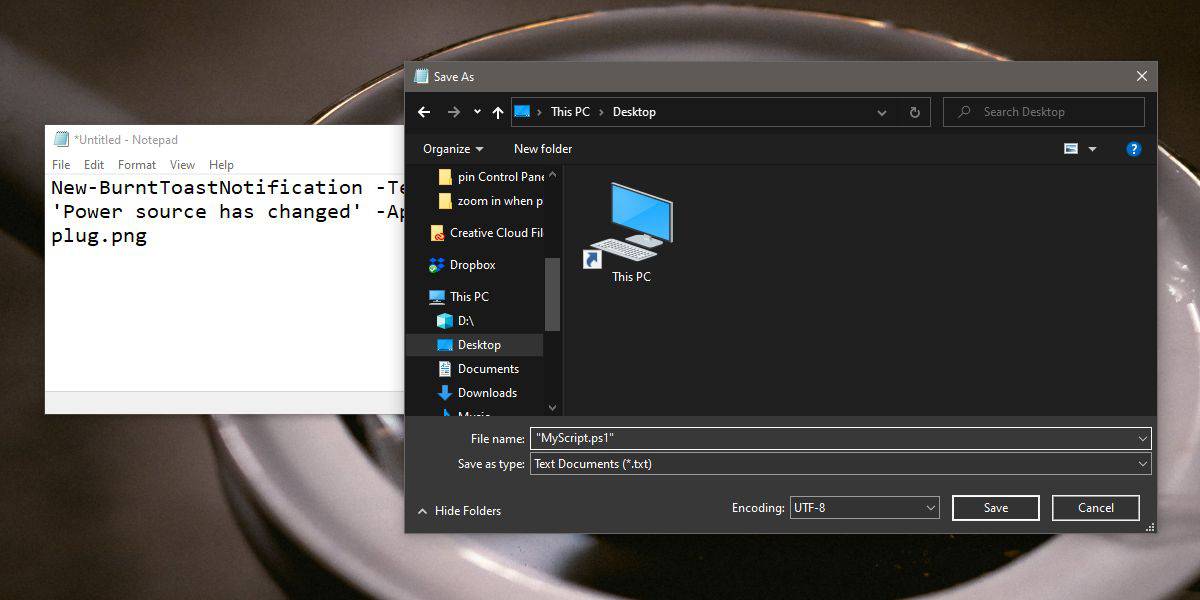
# 摘要
Python作为一种流行的编程语言,其脚本的编写和环境设置对于初学者和专业开发者都至关重要。本文从基础概念出发,详细介绍了Python脚本的基本结构、环境配置、调试与执行技巧,以及进阶实践和项目实战策略。重点讨论了如何通过模块化、包管理、利用外部库和自动化技术来提升脚本的功能性和效率。通过对Python脚本从入门到应用的系统性讲解,本文
【Proteus硬件仿真】:揭秘点阵式LED显示屏设计的高效流程和技巧
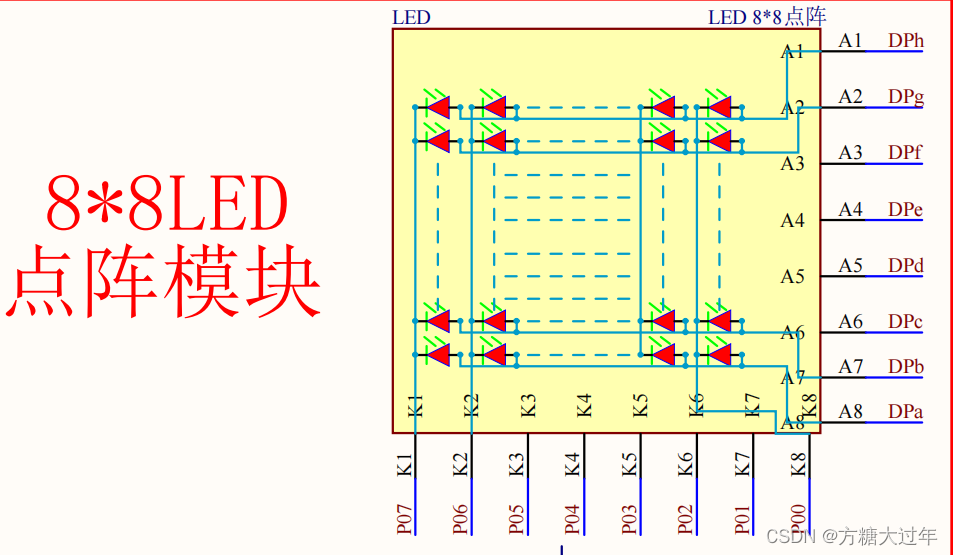
# 摘要
本论文旨在为点阵式LED显示屏的设计与应用提供全面的指导。首先介绍了点阵式LED显示屏的基础知识,并详细阐述了Proteus仿真环境的搭建与配置方法。随后,论文深入探讨了LED显示屏的设计流程,包括硬件设计基础、软件编程思路及系统集成测试,为读者提供了从理论到实践的完整知识链。此外,还分享了一些高级应用技巧,如多彩显示、微控制器接口设计、节能优化与故障预防等,以帮助读者提升产
Nginx配置优化秘籍:根目录更改与权限调整,提升网站性能与安全性

# 摘要
Nginx作为一个高性能的HTTP和反向代理服务器,广泛应用于现代网络架构中。本文旨在深入介绍Nginx的基础配置、权限调整、性能优化、安全性提升以及高级应用。通过探究Nginx配置文件结构、根目录的设置、用户权限管理以及缓存控制,本文为读者提供了系统化的部署和管理Nginx的方法。此外,文章详细阐述了Nginx的安全性增强措施,包括防止安全威胁、配置SSL/TLS
数字滤波器优化大揭秘:提升网络信号效率的3大策略
# 摘要
数字滤波器作为处理网络信号的核心组件,在通信、医疗成像以及物联网等众多领域发挥着关键作用。本文首先介绍了数字滤波器的基础知识和分类,探讨了其在信号数字化过程中的重要性,并深入分析了性能评价的多个指标。随后,针对数字滤波器的优化策略,本文详细讨论了算法效率提升、硬件加速技术、以及软件层面的优化技巧。文章还通过多个实践应用案例,展示了数字滤波器在不同场景下的应用效果和优化实例。最后,本文展望了数字滤波器未来的发展趋势,重点探讨了人工智能与机器学习技术的融合、绿色计算及跨学科技术融合的创新方向。
# 关键字
数字滤波器;信号数字化;性能评价;算法优化;硬件加速;人工智能;绿色计算;跨学科
RJ-CMS模块化设计详解:系统可维护性提升50%的秘密
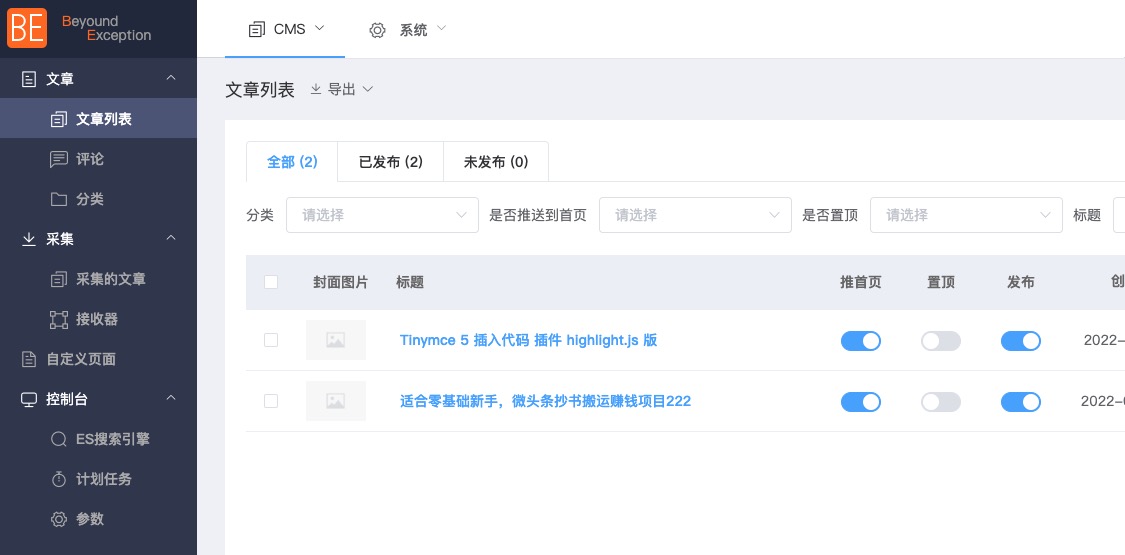
# 摘要
随着互联网技术的快速发展,内容管理系统(CMS)的模块化设计已经成为提升系统可维护性和扩展性的关键技术。本文首先介绍了RJ-CMS的模块化设计概念及其理论基础,详细探讨了模块划分、代码组织、测试与部署等实践方法,并分析了模块化系统在配置、性能优化和安全性方面的高级技术。通过对RJ-CMS模块化设计的深入案例分析,本文旨在揭示模块化设计在实际应用中的成功经验、面临的问题与挑战,并展望其未来发展趋势,以期为CMS的模块化设计提供参考和借鉴。
# 关
AUTOSAR多核实时操作系统的设计要点

# 摘要
随着计算需求的增加,多核实时操作系统在满足确定性和实时性要求方面变得日益重要。本文首先概述了多核实时操作系统及其在AUTOSAR标准中的应用,接着探讨了多核系统架构的设计原则,包括处理多核处理器的挑战、确定性和实时性以及系统可伸缩性。文章重点介绍了多核实时操作系统的关键技术,如任务调度、内存管理、中断处理及服务质量保证。通过分析实际的多核系统案例,评估了性能并提出了优化策略。最后,本文
五个关键步骤:成功实施业务参数配置中心系统案例研究

# 摘要
本文对业务参数配置中心进行了全面的探讨,涵盖了从概念解读到实际开发实践的全过程。首先,文章对业务参数配置中心的概念进行了详细解读,并对其系统需求进行了深入分析与设计。在此基础上,文档深入到开发实践,包括前端界面开发、后端服务开发以及配置管理与动态加载。接着,文中详细介绍了业务参数配置中心的部署与集成过程,包括环境搭建、系统集成测试和持续集成与自动化部署。最后,通过对成功案例的分析,文章总结了在项目实施过程中的经验教训和
Origin坐标轴颜色与图案设计:视觉效果优化的专业策略
# 摘要
本文全面探讨了Origin软件中坐标轴设计的各个方面,包括基本概念、颜色选择、图案与线条设计,以及如何将这些元素综合应用于提升视觉效果。文章首先介绍了坐标轴设计的基础知识,然后深入研究了颜色选择对数据表达的影响,并探讨了图案与线条设计的理论和技巧。随后,本文通过实例分析展示了如何综合运用视觉元素优化坐标轴,并探讨了交互性设计对用户体验的重要性。最后,文章展望了高级技术如机器学习在视觉效果设计中的应用,以及未来趋势对数据可视化学科的影响。整体而言,本文为科研人员和数据分析师提供了一套完整的坐标轴设计指南,以增强数据的可理解性和吸引力。
# 关键字
坐标轴设计;颜色选择;数据可视化;交
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )