MATLAB遗传学研究新视角:生物统计工具箱的深入应用
发布时间: 2024-12-09 23:47:08 阅读量: 36 订阅数: 12 

[机械毕业设计方案]HDK640微型客车设计总体、车架、制动系统设计.zip.zip

# 1. MATLAB遗传学研究的重要性与应用
MATLAB作为一种高性能的数学计算和可视化软件,在遗传学研究中扮演着重要的角色。本章将探讨MATLAB在这一领域中的重要性及其应用。随着生物信息学和计算生物学的迅速发展,传统的实验方法已经无法满足当前复杂遗传问题的分析需求,MATLAB以其强大的数值计算能力、丰富的工具箱以及用户友好的开发环境,为遗传学研究提供了一种高效且直观的解决方案。
MATLAB不仅可以处理大量的遗传数据,进行数据统计分析、基因型识别和连锁分析,还可以通过编程实现复杂的算法和模拟实验。在这一章节中,我们将深入探讨MATLAB如何帮助遗传学家进行模式识别、遗传变异的评估以及遗传病风险预测等任务。通过具体的案例分析,我们可以看到MATLAB在遗传学研究中不可替代的作用。
# 2. 生物统计工具箱基础
### 2.1 工具箱的安装与配置
#### 2.1.1 工具箱的获取和安装步骤
为了开始使用MATLAB生物统计工具箱,首先需要确保你有合法的MATLAB安装环境。接下来,我们介绍如何获取和安装生物统计工具箱的详细步骤:
1. **访问MathWorks官网**:登录到MathWorks的官方网站,下载生物统计工具箱的相关文件。通常情况下,这些文件会打包成一个安装包,并且提供一个许可证文件。
2. **下载工具箱文件**:根据MATLAB版本,选择适合的生物统计工具箱版本下载。确保下载的版本与你的MATLAB版本兼容。
3. **安装步骤**:
- 在MATLAB命令窗口输入 `add-ons` 并按回车,打开Add-On Explorer。
- 在搜索栏中输入 "Bioinformatics Toolbox",找到生物统计工具箱。
- 点击安装按钮开始安装过程。系统会提示你输入工具箱的许可证信息。
- 完成安装后,重启MATLAB以确保工具箱能够正确加载。
#### 2.1.2 环境变量和路径设置
安装完成后,通常MATLAB会自动配置好相关的环境变量和路径。不过,有时可能需要手动检查和设置:
1. **环境变量检查**:在MATLAB命令窗口中输入 `ver` 命令来查看已安装的工具箱列表。确认生物统计工具箱已列在其中。
2. **路径设置**:
- 使用 `addpath` 命令添加工具箱路径到当前工作路径。
- `savepath` 命令用于保存当前MATLAB路径配置,这样每次启动MATLAB时都能自动加载生物统计工具箱。
示例代码:
```matlab
addpath('C:\Program Files\MATLAB\R2021a\toolbox\bioinfo\bioinfo');
savepath;
```
3. **验证安装**:通过执行一个简单的示例函数来验证工具箱是否已正确安装。例如,使用 `dnds` 函数来计算序列的非同义和同义替换率。
示例代码:
```matlab
sequence1 = 'ATCGATCG';
sequence2 = 'ATGCATCG';
dnds(sequence1, sequence2);
```
### 2.2 工具箱的主要功能模块
#### 2.2.1 基因型分析模块
基因型分析模块是生物统计工具箱的核心部分之一。它允许用户从遗传数据中识别基因型变异,包括SNPs和插入/缺失(indels)等。为了更好地掌握如何使用这些功能,我们可以按照以下步骤进行:
1. **读取数据**:首先,需要将遗传数据读入MATLAB。常见的数据格式包括VCF(Variant Call Format)文件和PLINK文件。
示例代码:
```matlab
vcfObj = vcfread('example.vcf');
data = readtable('example.ped');
```
2. **分析基因型**:利用 `snpgdsVCF2Geno` 等函数将VCF文件转换为基因型矩阵。
示例代码:
```matlab
[snpid, indid, geno] = snpgdsVCF2Geno(vcfObj);
```
3. **可视化分析结果**:使用 `snpgdsGTwindow` 等工具来可视化基因型数据。
示例代码:
```matlab
snpgdsGTwindow(geno);
```
#### 2.2.2 表型统计模块
表型统计模块帮助研究人员分析和理解表型数据与遗传变异之间的关联。这部分内容包括:
1. **描述统计**:对表型数据进行基本的描述性统计分析。
示例代码:
```matlab
stats = describe(data(:, end));
disp(stats);
```
2. **相关性分析**:探究不同表型之间的相关性。
示例代码:
```matlab
corrMatrix = corr(data(:, :-1));
disp(corrMatrix);
```
3. **方差分析(ANOVA)**:确定表型变量的变异是否可以由一个或多个分类变量解释。
示例代码:
```matlab
anovaRes = anova1(data(:, :-1), data(:, end));
plot(anovaRes);
```
#### 2.2.3 连锁分析模块
连锁分析模块在遗传学研究中用于研究遗传标记间的连锁关系以及定位与疾病相关的基因。主要的步骤包括:
1. **连锁数据准备**:将家族连锁数据整理成适合分析的格式。
示例代码:
```matlab
家族连锁数据 = 阅读家族连锁数据文件;
```
2. **非参数连锁分析**:使用非参数方法评估标记连锁的可能性。
示例代码:
```matlab
[results, map] = nplplot(家族连锁数据, 'model', 'dominant');
```
3. **绘制连锁图**:将分析结果以图形方式展示。
示例代码:
```matlab
figure;
haploplot(results);
```
### 2.3 工具箱与遗传学研究的结合
#### 2.3.1 研究案例介绍
在这一部分,我们将介绍一个实际的遗传学研究案例,使用生物统计工具箱来分析遗传数据,并尝试定位某个遗传疾病的致病基因。案例将包括:
1. **数据获取**:获取与疾病相关的遗传数据集。
2. **数据预处理**:将数据清理并准备用于分析。
3. **初步分析**:执行基本的描述性统计和探索性分析。
#### 2.3.2 工具箱在案例中

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏聚焦 MATLAB 生物统计工具箱在生物统计学领域的广泛应用。文章深入探讨了 MATLAB 如何简化假设检验,为遗传学研究提供新视角,并通过降维和分类技巧处理高维数据。此外,还介绍了 MATLAB 在贝叶斯统计分析中的原理和应用。通过这些文章,读者将了解 MATLAB 生物统计工具箱的强大功能,并掌握其在生物统计学研究中的实际应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【dSPACE RTI 环境搭建全攻略】:开发新手必备的环境配置教程

参考资源链接:[DSpace RTI CAN Multi Message开发配置教程](https://wenku.csdn.net/doc/33wfcned3q?spm=1055.2635.3001.10343)
# 1. dSPACE RTI环境概述
dSPACE Real-Time Interface (RTI) 是一
【Dev C++编译错误快速定位】:Id returned 1 exit status问题的诊断与解决
参考资源链接:[解决Dev C++编译错误:Id returned 1 exit status](https://wenku.csdn.net/doc/6412b470be7fbd1778d3f976?spm=1055.2635.3001.10343)
# 1. Dev C++编译错误概览
## 理解编译过程
在软
【SAP财务处理:移动与评估类型协调全攻略】:财务与物流的完美结合

参考资源链接:[SAP物料评估与移动类型深度解析](https://wenku.csdn.net/doc/6487e1d8619bb054bf57ad44?spm=1055.2635.3001.10343)
# 1. SAP财务处理概述
## SAP财务处理基础
SAP作为先进的企业资源计划(ERP)系统,其核心功能之一是财务处理。财务处理在SAP系统中扮演着关键角色,因为所有的业务交易最终都会反映在财务报表上
实验室安全隐患排查:BUPT试题解析与实战演练的终极指南
参考资源链接:[北邮实验室安全试题与答案解析](https://wenku.csdn.net/doc/12n6v787z3?spm=1055.2635.3001.10343)
# 1. 实验室安全隐患排查的重要性与原则
## 实验室安全隐患排查的重要性
在当今社会,实验室安全已成为全社会关注的焦点。实验室安全隐患排查的重要性不言而喻,它直接关系到实验人员的生命安全和身体健康。对于实验室管理者来说,确保实验室安全运行是其基本职责。忽视安全隐患排查将导致严重后果,包括环境污染、财产损失甚至人员伤亡。因此,必须强调实验室安全隐患排查的重要性,从源头上预防和控制安全事故的发生。
## 实验室安全
【高效网络传输秘诀】:RoCEv2在高性能计算中的应用及优化
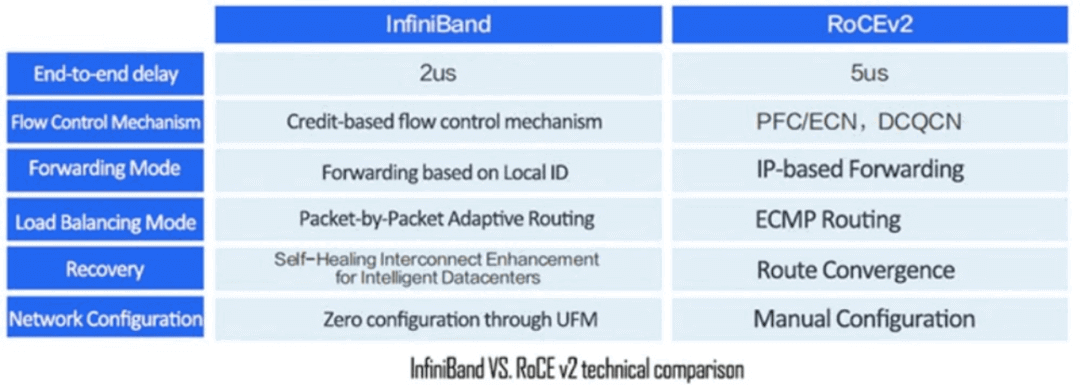
参考资源链接:[InfiniBand Architecture 1.2.1: RoCEv2 IPRoutable Protocol Extension](https://wenku.csdn.net/doc/645f20cb543f8444888a9c3d?spm=1055.2635.3001.10343)
# 1. RoCEv2技术概述
## 1.1 简介
RDMA over Converged Ethernet ver
从入门到精通:V93000 Wave Scale RF训练进阶指南,专家手把手教你
参考资源链接:[Advantest V93000 Wave Scale RF 训练教程](https://wenku.csdn.net/doc/1u2r85x0y8?spm=1055.2635.3001.10343)
# 1. V93000 Wave
【毫米波信道建模】:深入分析与应用,专家指南

参考资源链接:[TI mmWave Studio用户指南:安装与功能详解](https://wenku.csdn.net/doc/3moqmq4ho0?spm=1055.2635.3001.10343)
# 1. 毫米波信道建模的理论基础
毫米波技术,作为无线通信领域的一项突破性进展,其信道建模理论基础是研究该频段信号传播特性的关键。在深入探讨技术原
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )