【C语言高级字符串技巧】:正则表达式的高效应用
发布时间: 2024-10-01 19:47:16 阅读量: 28 订阅数: 47 
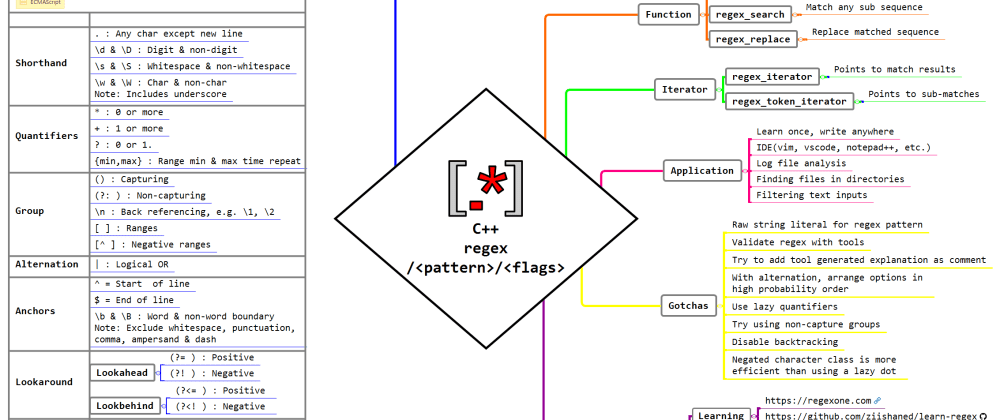
# 1. C语言字符串处理基础
在现代编程中,处理字符串是日常任务之一。C语言作为编程语言的经典之作,为字符串处理提供了丰富的函数集合。本章将带您回顾C语言字符串处理的基础知识,包括字符数组的使用、字符串常用函数如`strcpy`、`strlen`、`strcmp`等的介绍,以及如何使用指针操作字符串,从而为后面章节中更复杂的正则表达式操作打下坚实的基础。
## 字符串和字符数组
在C语言中,字符串通常通过字符数组来实现,其结尾以空字符`\0`标识。处理字符串时,经常需要对数组进行操作,包括遍历、复制、比较和连接。
### 示例代码:
```c
#include <stdio.h>
int main() {
char str1[] = "Hello";
char str2[] = "World";
// 字符串复制示例
strcpy(str1, str2);
// 输出复制后的字符串
printf("%s\n", str1); // 输出 "World"
return 0;
}
```
通过上述代码,我们可以简单演示如何在C语言中复制一个字符串。这只是字符串处理的冰山一角,但它是构建更高级字符串操作技巧的重要基石。在后续章节中,我们将探索如何将正则表达式这一强大的工具融入C语言,用于处理更加复杂的字符串问题。
# 2. 正则表达式在C语言中的实现
### 正则表达式基础
正则表达式是字符串处理的强大工具,它以简洁的语法描述复杂的文本模式。在C语言中,虽然标准库不直接支持正则表达式,但我们可以利用POSIX标准定义的函数或者第三方库来实现相应的功能。
#### 正则表达式概念解析
正则表达式,简称为regex,是一种特殊的字符串模式,用于匹配一系列符合某个句法规则的字符串。它由普通字符(例如,字母和数字)以及特殊字符(称为"元字符")组成。元字符在正则表达式中有特殊含义,例如点号`.`匹配任何单个字符,而星号`*`表示前一个字符可以出现零次或多次。
#### 正则表达式语法指南
正则表达式的语法由一系列的字符和操作符构成,最基本的构成单位是字符。此外,正则表达式还包含一些特殊字符和元字符,它们具有特殊的意义。例如,字符类(如`[a-zA-Z]`表示所有小写和大写字母)和量词(如`+`表示一个或多个,`?`表示零个或一个)。
### C语言中正则表达式的库函数
POSIX标准定义了一系列与正则表达式相关的函数,这些函数包含在`regex.h`头文件中,并提供了对正则表达式操作的支持。
#### POSIX正则表达式库函数介绍
`regex.h`头文件中的函数可以分为几个主要部分:编译和执行正则表达式模式的函数(如`regcomp`和`regexec`),以及处理正则表达式模式和匹配子串的函数(如`regerror`和`regfree`)。这些函数允许C程序执行复杂的文本匹配任务。
#### 正则表达式函数实例使用
下面是一个使用POSIX正则表达式函数的简单例子,演示如何使用`regcomp`编译一个正则表达式,再用`regexec`执行匹配:
```c
#include <regex.h>
#include <stdio.h>
#include <string.h>
int main() {
regex_t regex;
int reti;
char msgbuf[100];
// 编译正则表达式
reti = regcomp(®ex, "^A.*B$", 0);
if (reti) {
fprintf(stderr, "Could not compile regex\n");
exit(1);
}
// 执行匹配
reti = regexec(®ex, "ABC", 0, NULL, 0);
if (!reti) {
puts("Match");
} else if (reti == REG_NOMATCH) {
puts("No match");
} else {
regerror(reti, ®ex, msgbuf, sizeof(msgbuf));
fprintf(stderr, "Regex match failed: %s\n", msgbuf);
}
// 释放正则表达式
regfree(®ex);
return 0;
}
```
### 编译和执行正则表达式
了解正则表达式的基础知识和库函数之后,我们需要进一步了解编译和执行正则表达式的详细步骤。
#### 正则表达式的编译过程
在执行匹配之前,必须先编译正则表达式。`regcomp`函数用于编译正则表达式。该函数的第一个参数是一个指向`regex_t`类型的指针,用来存储编译后的正则表达式;第二个参数是需要编译的正则表达式字符串;第三个参数包含编译选项,如`REG_EXTENDED`用于启用扩展正则表达式语法。
```c
regex_t regex;
int reti = regcomp(®ex, "正则表达式字符串", REG_EXTENDED);
if (reti) {
fprintf(stderr, "Could not compile regex\n");
exit(1);
}
```
#### 正则表达式的匹配过程
编译后的正则表达式可以使用`regexec`函数进行匹配操作。该函数的参数包括一个编译好的正则表达式`regex_t`,一个要匹配的字符串,以及匹配选项等。
```c
char *str = "待匹配的字符串";
reti = regexec(®ex, str, 0, NULL, 0);
if (!reti) {
puts("匹配成功");
} else if (reti == REG_NOMATCH) {
puts("未匹配到结果");
} else {
regerror(reti, ®ex, msgbuf, sizeof(msgbuf));
fprintf(stderr, "Regex match failed: %s\n", msgbuf);
}
```
#### 错误处理和优化技巧
在编译和执行正则表达式的过程中,可能会遇到各种错误。例如,正则表达式语法错误、编译失败或匹配失败等。`regerror`函数将错误码转换为可读的错误信息。此外,优化技巧包括避免复杂的正则表达式、合理使用编译标志等。
```c
if (reti) {
regerror(reti, ®ex, msgbuf, sizeof(msgbuf));
fprintf(stderr, "Regex error detected: %s\n", msgbuf);
}
```
正则表达式在C语言中的应用不仅仅是编译和匹配,它还涉及编译后执行的效率、错误处理及优化,这些内容将在后续章节中进一步深入探讨。
# 3. 正则表达式的高效应用技巧
在处理字符串数据时,正则表达式是一种功能强大的工具,它允许我们使用特定的模式来匹配字符串中的特定部分。然而,正则表达式也存在性能问题,特别是在处理大型数据集或需要高度优化的场景中。本章节将介绍提高正则表达式匹配效率的方法、缓存与性能优化技巧以及有效的错误处理和调试方法。
## 提高匹配效率的方法
### 优化正则表达式模式
为了提高正则表达式的匹配效率,首先应当从优化模式入手。正则表达式中的一些复杂构造可能会导致匹配效率显著下降。以下是一些优化建议:
- **使用贪婪匹配**:默认情况下,正则表达式引擎会尽可能多地匹配字符。在不需要的情况下减少懒惰量词(如`*?`、`+?`等)的使用。
- **避免不必要的回溯**:复杂的嵌套分组和过多的备用选项会增加回溯的次数,尽量简化正则表达式。
- **限制选择符的范围**:在使用选择符(如`|`)时,将其限制在特定的字符集中,例如`[a-z]`而不是`[a-zA-Z0-9]`。
### 使用编译后的正则表达式对象
许多正则表达式函数允许将正则表达式编译成一个对象,该对象可以被多次重复使用,从而提高效率。使用编译后的正则表达式对象通常涉及以下步骤:
- **编译正则表达式**:将正则表达式字符串转换为编译后的对象。
- **执行匹配**:使用

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 C 语言字符串处理的方方面面,从入门到精通,提供实用技巧和深入分析。涵盖字符编码、错误防范、内存管理、动态内存操作、字符串库设计、内存安全、高级字符串技巧、国际化处理、安全编程、分割与连接、数组与指针、自定义函数、性能测试、字符处理、文件操作、字符串流程解析和动态字符串池等主题。通过案例分析、代码示例和最佳实践,本专栏旨在帮助 C 程序员提升字符串处理能力,编写更安全、高效和可维护的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【TSPL与TSPL2:技术高手的对比解析】:4大基础到进阶的对比让你快速晋升

# 摘要
本文系统介绍了TSPL与TSPL2编程语言的各个方面,从核心语法结构到进阶特性,再到性能优化技术和实际应用案例。在核心语法对比章节,文章详细分析了基础语法结构和进阶编程特性,如变量、数据类型、控制流语句、函数、模块化编程、异常处理等。性能与优化技术章节专注于性能基准测试、代
故障诊断Copley伺服驱动器:常见问题排查与解决策略

# 摘要
本文旨在详细介绍Copley伺服驱动器的故障诊断、性能优化及维护策略。首先概述了Copley伺服驱动器的理论基础,包括其工作原理、关键性能参数和控制策略。随后深入分析了伺服驱动器的常见故障类型、原因以及硬件和软件层面的故障诊断方法。本文还提出了故障解决策略,涵盖预防措施、现场处理方法和案例分析,强调了系统优化和维护对于减少故障发生的重要性。最后,探讨了
ABB510性能调优:提升效率与可靠性的策略
# 摘要
ABB510性能调优是一个综合性的课题,涉及硬件优化、软件调优实践、系统稳定性和容错机制等多个方面。本文首先概述了ABB510性能调优的基本概念和目标,随后详细介绍了硬件升级、存储系统优化、网络性能调整等硬件层面的优化策略。接着,文章深入探讨了操作系统和应用程序的软件性能调优方法,包括内存管理优化和负载测试分析。在系统稳定性与容错机制方面,故障诊断、数据备份与恢复策略以及高可用性配置也被重点讨论。最后
【STC15F2K60S2电源设计要点】:打造稳定动力源泉

# 摘要
本文全面探讨了STC15F2K60S2微控制器的电源系统设计,涵盖了微控制器电源的基本要求、设计理论基础、设计实践、常见问题及解决方案以及案例分析。首先,我们介绍STC15F2K60S2的基本特性和电源系统要求,包括电源电压规格和稳定性标准。随后,深入探讨了电源设计的理论,比如线性稳压与开关稳压的差异、电源电路组成以及
【数据库设计核心要点】:为你的Python学生管理系统选择最佳存储方案
# 摘要
本文主要探讨了数据库设计的基础知识、关系型数据库与Python的交互、数据库设计理论与实践,以及数据库设计的高级应用。首先,介绍了数据库设计的基础知识,包括数据库规范化、性能优化和安全性策略。然后,深入探讨了关系型数据库与Python的交互,包括数据库连接、SQL基础以及ORM工具的使用。接下来,对数据库设计理论与实践进行了全
PL_0编译器代码生成速成:一步到位从AST到机器码

# 摘要
本文详细介绍了PL_0编译器的设计与实现,从编译器的前端解析到后端代码生成,再到实际应用中的性能调优和问题诊断。首先,文中概述了PL_0编译器的背景,并深入探讨了其前端解析阶段的PL_0语言语法规则、抽象语法树(AST)的构建以及符号表的管理。接着,本文分析了后端生成过程中的中间代码生成、代码优化技术以及目标代码的生成策略。通过案例分析,展示了PL_0编译器的构建、运行环境
【Vivado配置大揭秘】:一步到位掌握Xilinx FPGA开发环境搭建

# 摘要
本文系统地介绍了Vivado的设计环境及其在现代FPGA设计中的应用。首先,概述了Vivado的基本概念和安装流程,包括系统需求评
从零开始掌握ISE Text Editor中文显示:编码设置完全攻略

# 摘要
本论文旨在介绍ISE Text Editor的功能和解决其在中文显示上遇到的问题。首先对ISE Text Editor进行基础设
热传导方程的Crank-Nicolson格式详解:MATLAB实现与优化(专业技能提升)

# 摘要
本文对热传导方程的基础理论进行了详细介绍,并深入分析了Crank-Nicolson格式的数值分析。通过对热传导方程的数学模型定义及其物理意义进行阐述,文中进一步探讨了初始条件和边界条件的作用。文章详细推导了Crank-Nicolson格式,并对其在时间和空间离散化过程中的稳定性进行了分析。接着,文中展示了如何在M
【STM32烧录常见问题】:故障诊断与解决策略的实用手册

# 摘要
本论文全面介绍了STM32烧录过程中的基础与环境准备工作,并详细探讨了烧录过程中可能遇到的各类故障类型及其诊断方法。通过对电源、通信接口和软件问题的分析,提供了解决烧录过程中常见故障的策略。此外,本文还着重讲述了硬件故障的诊断与维修方法,包括最小系统板的检测
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )